Mobile client-server application architecture

To add an external server sooner or later comes any complex project. The reasons, however, are quite different. Some download additional information from the network, others synchronize data between client devices, and others transfer the logic of the application execution to the server side. As a rule, most of the "business" applications belong to the latter. As we move away from the sandbox paradigm, in which all actions are performed only within the framework of the original system, the logic of the processes is intertwined, intertwined, tied with nodes so that it becomes difficult to understand what is the starting point for entering the application process. At this moment, not the functional properties of the application itself come to the first place, but its architecture, and, as a result, the opportunities for scaling.
The foundation laid allows either to create a majestic architectural ensemble, or “nakrednozh” - a hut on chicken legs, which crumbles from one push of the “good fellow” of which, apparently, invisibly during its existence, because, looking at multiple building defects, the customer is inclined to change not the original project, but the construction team.
Planning is the key to the success of the project, but it is the customer who is given the minimum amount of time. Building patterns are the ace in the sleeve of a developer who covers unfavorable combinations where time is the decisive factor. Taken as a basis, working solutions allow you to make a quick start to go to the tasks that seem to be most relevant to the customer (such as painting a chimney on a roof that has not yet been built).
In this article I will try to set forth the principle of building a scalable system for mobile devices, covering 90-95% of client-server applications, and ensuring the maximum distance from the sacramental "nooknuru".
While doing the revision of this article, a similar article was published on Habré ( http://habrahabr.ru/company/redmadrobot/blog/246551/ ). I do not agree with all the accents of the author, but in general, my vision does not contradict and does not overlap with the material presented there. The reader will be able to determine which of the approaches is more flexible and more relevant.
')
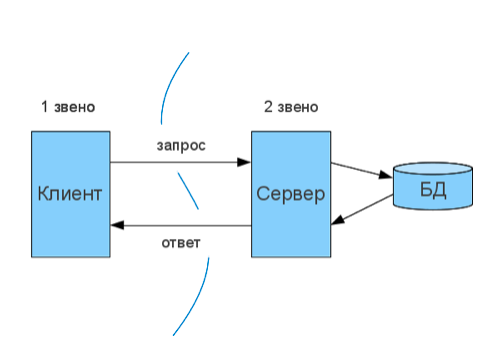
The general structure of client-server interaction from the server is presented here: www.4stud.info/networking/lecture5.html However, we are more interested in the same view from the client, and in this regard, there is no difference between dvzvennoy and sober architecture:
It is important to understand two things:
- There may be many customers using one account to communicate with the north.
- Each client usually has its own local storage. *
* In some cases, local storage can be synchronized with the cloud, and, accordingly, with each of the clients. Since this is a special case and, for the most part, does not affect the architecture of the application, we omit it.
It should be noted that since, some developers seek to get rid of the "server side", some applications are built around the synchronization of their storages in the "cloud". That is, in fact, they have the same two-link system, but with the transfer of its deployment architecture to the level of the operating system. In some cases, such a structure is justified, but such a system is not so easily scaled, and its capabilities are very limited.
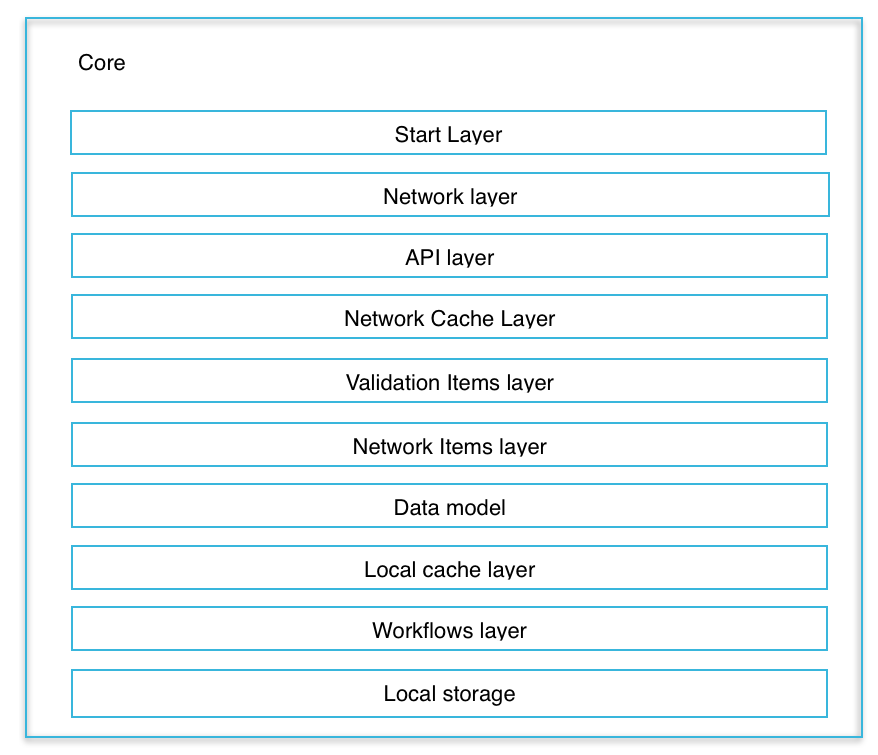
General structure of the application
At the most primitive level of abstraction, a server-oriented application consists of the following architectural layers:
- The core of the application, which includes system components that are not available for user interaction.
- Graphical user interface
- Reusable components: libraries, visual components and more.
- Environment files: AppDelegate, .plist, etc.
- Application resources: graphic files, sounds, necessary binary files.
The most important condition for building a stress-resistant architecture is to separate the system core from the GUI, so that one could successfully function without the other. Meanwhile, the majority of RAD systems come from the opposite direction - the molds form the skeleton of the system, and its muscles build up functions. As a rule, this means that the application does not become limited by its interface. And, the interface acquires an unambiguous interpretation both from the point of view of the user and from the point of view of the class hierarchy.

Core
The core of the application consists of the following layers:
- (Start layer) The start layer, which defines the workflow, starts program execution.
- (Network layer) A network layer that provides a mechanism for transport interaction.
- (API layer) An API layer that provides a unified system of commands for interaction between the client and the server.
- (Network Cache Layer) A network caching layer that accelerates client and server network interactions.
- (Validation Items Layer) Validation layer of data received from the network
- (Network Items Layer) Network Entry Layer
- (Data Model) A data model that provides interaction between data entities.
- (Local cache layer) A local cache layer that provides local access to already acquired network resources.
- (Workflow layer) A workflow layer that includes classes and algorithms specific to this application.
- (Local storage) Local storage
One of the main tasks facing the developers of the system is to ensure the mutually independent functioning of these layers. Each layer should only ensure the performance of its functions. As a rule, a layer located at a higher level of the hierarchy should not be aware of the specifics of the implementation of other layers.
Consider the process of solving the problem with the currents of Junior and Senior developers.
Objective: to write a program "currency calculator" that would receive data from the network, and build a graph of rate changes.
Junior:
1) Based on the formulation of the problem, we know that the application will consist of the following parts:
- Form for mathematical operations (addition, subtraction)
- Form for displaying graphics
- Additional forms: splash screen, about.
2) We do the following form dependency: the form of calculations is the main one in our application. It starts up a splash form that hides after a certain period of time, the form of graphs and about by clicking on a certain button.
3) The display time of splashscreen is equivalent to the time for downloading data from the network.
4) Since the download from the network is performed only during the display of the splash form, the data loading code is placed inside the form, and upon completion of the form, is removed from memory along with the form.
How efficient is this application? I think that no one has any doubt that using Delphi or Visual Studio can at the moment solve this problem. Using Xcode to make it a little more difficult, but you can also not straining too much. However, after the advent of the prototype, scalability issues begin to appear. It becomes obvious that to display the graph it is necessary to store data for the previous period. Not a problem, you can add data storage inside the form of graphs. However, data can come from different providers and in different formats. In addition, arithmetic operations can be carried out with different currencies, which means that it is necessary to ensure their choice. To make such a choice on the form of graphs is somewhat illogical, although it is possible, however, it depends on such settings what we will display on the graph. This means that if we add additional parameters to the settings window, we will have to somehow pass them through the main form to the graphs window. In this case, it will be logical to make a local variable in which to store the passed parameters, and to provide access from one form to another form through the main form. Well, and so on. The chain of reasoning can be built for a very long time, and the complexity of interactions will increase.
Senior:
Task setting allows you to select several subtasks that can be described by separate classes:
1) Download data from the network.
- Verification of the data
- Saving data in permanent storage.
- Calculation of data.
- addition operation
- subtraction operation
- Filtering data by specified criteria (application settings)
- Application start class.
2) Provide an interface related operation that consists of the following main forms:
- Main controller (may be invisible)
- Calculation form
- Graph form
- Splash and About
- Optionally form settings.
3) After the application is launched at runtime, the object responsible for loading the data is created (instantiated) (in the overwhelming majority of cases asynchronous) and starts the process. The main controller of the application displays a splash screen, and at this time, forms a form that will take its place on hiding the splash form.
4) After the data loading is completed, a validator object and a local storage provider object are created. If the data has been validated, it can be transferred to the local storage provider.
5) To display the graph, a local storage object and a data settings object are created. Data settings are transferred to a local storage provider to retrieve data with installed filters.
6) For carrying out calculations, a calculator object is created, and operation objects. The data received from the form is transferred to the calculator object, and one of the two operation objects that know how to exactly perform the calculations.
Of course, this approach requires more programming efforts, and, accordingly, initially requires more time. However, based on the subtask, it is clear that firstly, it is easy to parallelize the work on it — while one developer is busy building the core — the other creates and debugs the UI. The kernel can safely work within the framework of the console, the UI can be clicked on the device and, among other things, independent unit tests can be bolted to both parts. Another undoubted advantage is that the second approach is much more scalable. In the case of revising the functionality of the project, any changes will be made many times faster, because there is simply no restrictive framework for visual representations. The visual forms themselves (GUI) display the necessary minimum based on the tasks existing in the core.
Start layer:
In iOS, the application starts functioning by running the delegate class object. Its purpose is to accept and transfer system calls to the application, as well as to carry out the initial configuration of the application's GUI. All algorithms and mechanisms that are not related to the start of the application, or receiving messages from the system should be placed in separate classes. Immediately after completing the initial configuration, control should be transferred to the class that performs the remaining operations of the application setup: authorization, interface reconfiguration depending on conditions, initial data loading, obtaining necessary tokens, and so on. A typical developer error is a monstrous controlnet code hosted in AppDelegate. It is understandable, almost all examples of external frameworks for ease of understanding, this is where your code is located. Unlucky programmers do not spend time on refactoring, and simply copy "as there". The situation is quite typical for those who use the coreData creation template.
Often there you can see the implementation of the following functions:
- Setting up and maintaining Facebook sessions
- Set up a tab manager if the application supports UITabbarController.
- Clearing CoreData and saving data when entering the Background.
- Check and initialize updates
- Notification of external statistics servers
- Synchronization Data Models
Network Layer:
Provides basic transport-level algorithms for transferring messages from the client to the server, and getting the necessary information from it. As a rule, messages can be transmitted in JSON and Multipart formats, although in some exotic cases it may be XML or a binary stream in general. In addition, each message may have a header with service information. For example, there can be described the duration of the storage of the request / response in the application cache.
Network Layer has no idea about the servers used by the application, or its command system. Error handling network connection is carried out by virtual methods at the following levels of the application. The task of this layer is to make a call to the processing method and transfer the information received from the network to it.
In addition, before directly requesting information from the network, the network layer polls the local cache, and if there is an answer there, it immediately returns it to the user.
The content of this layer largely depends on which transport technology is closest to you. In the developer’s arsenal, the following options are most in demand:
- Socket is the lowest-level approach, which includes synchronous and asynchronous requests, and has the ability to work with both TCP and UDP connections. It allows you to do almost anything, but it requires a high degree of concentration on the task, not a lot of plodding, and a large amount of code.
- WebSocket is an approach based on using headers on top of TCP. Details can be read here: habrahabr.ru/post/79038 In mobile development, it is used infrequently, since it is not flexible enough and still requires a fairly large amount of code for its support.
- WCF is probably the most perfect mechanism, but having such a serious minus, which outweighs all the advantages. The approach invented in the depths of Microsoft relies on the creation of a proxy class that mediates the relationship between application logic and the remote north. It works "with a bang" in the event that it is possible to generate a proxy class based on WSDL schemes ( en.wikipedia.org/wiki/Web_Services_Description_Language ), which is a task, to put it mildly, not trivial. In addition, this class must be regenerated after each update of the server API. And if for developers of Visual Studio this is done with the ease of Marshmallow, then for iOS developers it is an extremely heavy task, even those who use MonoTouch in development.
- REST is a reliable, time-tested compromise of all the above approaches ( ru.wikipedia.org/wiki/REST ). Of course, some of the capabilities of each approach must be abandoned, but this is done quickly and extremely efficiently with a minimum of effort.
GitHub contains many libraries that allow you to use REST connections for iOS, AFNetworking is the most popular.
REST relies on using GET, POST, PUT, HEAD, PATCH and DELETE requests. Such a zoo is called RESTFul ( habrahabr.ru/post/144011 ) and, as a rule, it is used only when a universal API is written for the operation of mobile applications, websites, desktops and space stations in the same bundle.
The vast majority of applications limit the command system to two types, GET and POST, although only one is enough - POST.
The GET request is transmitted as a string that you use in the browser, and the parameters for the request are transferred separated by '&' characters. The POST request also uses the “browser string” but hides the parameters inside the invisible message body. The last two statements discourage those who have not previously encountered requests, in fact, the technology has been developed to such an extent that it is completely transparent to the developer, and one does not have to go into such nuances.
Above, it has been described what is sent to the server. But what comes from the server is much more interesting. If you use AFNetworking, then from the server side you will receive. As a rule, iOS developers call the JSON serialized dictionary, but this is not quite so. True JSON has a slightly more complex format, but in its pure form it is almost never used. However, the fact that there is a difference need to know - there are nuances.
If you are working with a service installed on a Microsoft Windows Server, then most likely WCF will be used there. However, starting with the Windows Framework 4, there is an opportunity for clients supporting only the REST protocol to make access completely transparent, in a declarative way. You can even spend no time getting explanations about the API - the documentation about the command system is generated automatically by IIS (Microsoft Web server).
Below is the minimum code to implement Network Layer with Objective-C using AFNetworking 2.
Listing 1
ClientBase.h
ClientBase.m
#import "AFHTTPRequestOperationManager.h" NS_ENUM(NSInteger, REQUEST_METHOD) { GET, HEAD, POST, PUT, PATCH, DELETE }; @interface ClientBase : AFHTTPRequestOperationManager @property (nonatomic, strong) NSString *shortEndpoint; - (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail; @end ClientBase.m
#import "ClientBase.h" @implementation ClientBase - (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail { self.requestSerializer = [AFJSONRequestSerializer serializer]; if(data == nil) data = @{}; AFHTTPRequestOperation *operation = [self requestWithMethod:method path:endpoint parameters:data success:success fail:fail]; [operation start]; } - (AFHTTPRequestOperation *)requestWithMethod:(enum REQUEST_METHOD)method path:endpoint parameters:data success:(void(^)(id response))success fail:(void(^)(id response))fail{ switch (method) { case GET: return [self requestGETMethod:data andEndpoint:endpoint success:success fail:fail]; case POST: return [self requestPOSTMethod:data andEndpoint:endpoint success:success fail:fail]; default: return nil; } } - (AFHTTPRequestOperation *)requestGETMethod:(NSDictionary *)data andEndpoint:(NSString *)endpoint success:(void(^)(id response))success fail:(void(^)(id response))fail { return [self GET:endpoint parameters:data success:^(AFHTTPRequestOperation *operation, id responseObject) { [self callingSuccesses:GET withResponse:responseObject endpoint:endpoint data:data success:success fail:fail]; [KNZHttpCache cacheResponse:responseObject httpResponse:operation.response]; } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"\n\n--- ERROR: %@", operation); NSLog(@"\n--- DATA: %@", data); [self callingFail:fail error:error]; }]; } - (AFHTTPRequestOperation *)requestPOSTMethod:(NSDictionary *)data andEndpoint:(NSString *)endpoint success:(void(^)(id response))success fail:(void(^)(id response))fail { return [self POST:endpoint parameters:data success:^(AFHTTPRequestOperation *operation, id responseObject) { [self callingSuccesses:POST withResponse:responseObject endpoint:endpoint data:data success:success fail:fail]; } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"\n\n--- ERROR: %@", operation); NSLog(@"\n--- DATA: %@", data); [self callingFail:fail error:error]; }]; } - (void)callingSuccesses:(enum REQUEST_METHOD)requestMethod withResponse:(id)responseObject endpoint:(NSString *)endpoint data:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { if(success!=nil) success(responseObject); } - (void)callingFail:(void(^)(id response))fail error:(NSError *)error { if(fail!=nil) fail(error); } @end This is quite enough to transmit network GET and POST messages. For the most part, you will not need to adjust these files anymore.
API Layer:
Describes REST commands and selects a host. API Layer is completely separated from knowledge of the implementation of network protocols and any other features of the application. Technically, it can be completely replaced, without any changes in the rest of the application.
The class is inherited from ClientBase. Class code is so simple that there is no need to even give it entirely - it consists of a uniform description of the API:
Listing 2
#define LOGIN_FACEBOOK_ENDPOINT @"/api/v1/member/login/facebook/" #define LOGIN_EMAIL_ENDPOINT @"/api/v1/member/login/email/" - (void)loginFacebook:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { [self request:data andEndpoint:LOGIN_FACEBOOK_ENDPOINT andMethod:POST success:success fail:fail]; } - (void)loginEmail:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { [self request:data andEndpoint:LOGIN_EMAIL_ENDPOINT andMethod:POST success:success fail:fail]; } As the saying goes: "Nothing superfluous."
Network Cache Layer:
This caching layer is used to speed up network communication between the client and the server at the iOS SDK level. The choice of answers is carried out by the party beyond the control of the system, and does not guarantee a reduction in network traffic, but speeds it up. There is no access to data or implementation mechanisms either from the application or from the system. This uses SQLite repository.
The code required for this is too simple not to use it in any project that has access to the network:
Listing 3
#define memoCache 4 * 1024 * 1024 #define diskCache 20 * 1024 * 1024 #define DISK_CACHES_FILEPATH @"%@/Library/Caches/httpCache" - (void)start { NSURLCache *URLCache = [[NSURLCache alloc] initWithMemoryCapacity:memoCache diskCapacity:diskCache diskPath:nil]; [NSURLCache setSharedURLCache:URLCache]; } You need to call from anywhere in the application once. For example from the starting layer.
Validation Items layer:
The format of the data received from the network is more dependent on the server developers. An application cannot physically control the use of the initially specified format. For difficult-structured data, error correction is comparable in complexity to the development of the application itself. The presence of errors, in turn, is fraught with the crash of the application. Using the data validation mechanism significantly reduces the risk of misbehavior. The validation layer consists of JSON schemes for most requests to the server, and a class that checks the received data for compliance with the loaded scheme. If the received packet does not match the scheme, it is rejected by the application. The calling code will receive an error notification. A similar notification will be recorded in the console log. In addition, a server command can be called to transfer to the server side of the report about the error that occurred. The main thing is to provide a way out of recursion, if the command to send such a message also causes some kind of error (4xx or 5xx).
It makes sense to send the following data to the server:
- For which account an error occurred.
- Which team caused the error.
- What data was transferred to the server.
- What response was received from the server.
- UTC time *
- Status code of the team. For validation errors, it is always 200.
- A scheme that the server response does not satisfy.
* UTC time is the time when the command was called, not when the response was returned to the server. As a rule, they coincide, but since the application may have a request queue mechanism, then theoretically, months can pass between the invocation of the failed command and the registration of the record by the server.
It is assumed that JSON request schemes are provided by server developers after implementing new API commands.
Each scheme, like each team, must meet certain previously agreed criteria. In the above example, the server response should contain two primary and one optional fields.
“Status” is required. It contains an OK or ERROR identifier (or an HTTP code of type “200”).
“Reason” mandatory Contains a text description of the reason for the error, if it occurred. Otherwise, this field is empty.
"Data" is optional. Contains the result of the command. In case of error is absent.
Example schema:
Listing 4
{ "title": "updateconfig", "description": "/api/v1/member/updateconfig/", "type":"object", "properties": { "reason": { "type":"string", "required": true }, "status": { "type":"string", "required": true }, "data": { "type":"object" } }, "required": ["reason", "status"] } Thanks to the library developed by Maxim Lunin, it became very easy to do this. ( habrahabr.ru/post/180923 )
Validation class code is provided below
Listing 5
ResponseValidator.h
#import "ResponseValidator.h" #import "SVJsonSchema.h" @implementation ResponseValidator + (instancetype)sharedInstance { static ResponseValidator *sharedInstance; static dispatch_once_t onceToken; dispatch_once(&onceToken, ^{ sharedInstance = [[ResponseValidator alloc] init]; }); return sharedInstance; } #pragma mark - Methods of class + (void)validate:(id)response endpoint:(NSString *)endpoint success:(void(^)())success fail:(void(^)(NSString *error))fail { [[ sharedInstance] validate:response endpoint:endpoint success:success fail:fail]; } + (NSDictionary *)schemeForEndpoint:(NSString *)endpoint { NSString *cmd = [[ResponseValidator sharedInstance] extractCommand:endpoint]; return [[ResponseValidator sharedInstance] validatorByName:cmd]; } #pragma mark - Methods of instance - (void)validate:(id)response endpoint:(NSString *)endpoint success:(void(^)())success fail:(void(^)(NSString *error))fail { NSString *cmd = [self extractCommand:endpoint]; NSDictionary *schema = [self validatorByName:cmd]; SVType *validator = [SVType schemaWithDictionary:schema]; NSError *error; [validator validateJson:response error:&error]; if(error==nil) { if(success!=nil) success(); } else { NSString *result = [NSString stringWithFormat:@"%@ : %@", cmd, error.description]; if(fail!=nil) fail(result); } } - (NSString *)extractCommand:(NSString *)endpoint { NSString *cmd = [endpoint.stringByDeletingLastPathComponent lastPathComponent]; return cmd; } - (NSDictionary *)validatorByName:(NSString *)name { static NSString *ext = @"json"; NSString *filePath = [[NSBundle mainBundle] pathForResource:name ofType:ext]; NSString *schema = [NSString stringWithContentsOfFile:filePath encoding:NSUTF8StringEncoding error:nil]; if(schema == nil) return nil; NSData *data = [schema dataUsingEncoding:NSUTF8StringEncoding]; NSError *error; NSDictionary *result = [NSJSONSerialization JSONObjectWithData:data options:0 error:&error]; return result; } @end The challenge of validation is quite simple:
Listing 6
[ResponseValidator validate:responseObject endpoint:endpoint success:^{ /* , */ } fail:^(NSString *error) { /* . - , . . */ }]; Network Items layer:
It is on this layer that the responsibility for mapping data from JSON to the deserialized representation lies. This layer is used to describe the classes that perform object or object-relational transformation. In the network there are a large number of libraries that carry out object-relational transformations. For example, JSON Model ( github.com/icanzilb/JSONModel ) or the same Maxim Lunin library. However, not everything is so rosy. They do not relieve the problems of mapping.
Let us explain what mapping is:
Suppose there are two queries that return the same data structure. For example, users of the application and friends of the user who possess such fields as "identifier" and "user name". The trouble is that server developers in one request can transfer the fields: “id”, “username”, and in the second “ident”, “user_name”. Such a discrepancy can have a whole set of troubles:
- A de-serialized data object in Objective-C cannot have an “id” field when using CoreData
- Serialized data in the “id” and “ident” fields can contain both a string and NSNumber. When outputting them to the console, the difference between the two numbers will not, but. their hashcode will be different, and the dictionary will perceive the meaning of these fields in different ways.
- Differences between field names are the responsibility of the server, and server developers can simply not make contact, to replace their names with uniform, convenient client developers.
There is no universal solution to these problems, but they are not so complex as to require significant intellectual effort.
Local cache layer:

The tasks of this layer include:
- Caching images uploaded from the network.
- Caching server requests / responses
- Queuing requests in the case of a lack of a network and user work offlan.
- Monitor cached data and clean up data that has expired.
- Notification of the application about the inability to obtain information about a given object from the network.
In general, this layer is the subject of a separate large article. But there are a certain number of nuances that developers should consider.
For query caching, you can slightly modernize the procedures in Listing 1. I strongly recommend using virtual methods to do this, but for simplicity, a direct call to the class method will be demonstrated:
Listing 7
- (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail queueAvailable:(BOOL)queueAvailable { self.requestSerializer = [AFJSONRequestSerializer serializer]; if(data == nil) data = @{}; // Returning cache response. NSDictionary *cachedResponse = [HttpCache request:endpoint]; if(cachedResponse !=nil) { [self callingSuccesses:method withResponse:cachedResponse endpoint:endpoint data:data success:success fail:fail]; return; } AFHTTPRequestOperation *operation = [self requestWithMethod:method path:endpoint parameters:data success:success fail:fail]; [self consoleLogRequest:data operation:operation]; [operation start]; } - (AFHTTPRequestOperation *)requestPOSTMethod:(NSDictionary *)data andEndpoint:(NSString *)endpoint success:(void(^)(id response))success fail:(void(^)(id response))fail { return [self POST:endpoint parameters:data success:^(AFHTTPRequestOperation *operation, id responseObject) { [self callingSuccesses:POST withResponse:responseObject endpoint:endpoint data:data success:success fail:fail]; [HttpCache cacheResponse:responseObject httpResponse:operation.response]; } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"\n\n--- ERROR: %@", operation); NSLog(@"\n--- DATA: %@", data); [self callingFail:fail error:error]; }]; } In the HttpCache class, along with methods for storing query results, there is another interesting method:
Listing 8
#define CacheControlParam @"Cache-Control" #define kMaxAge @"max-age=" - (NSInteger)timeLife:(NSHTTPURLResponse *)httpResponse { NSString *cacheControl = httpResponse.allHeaderFields[CacheControlParam]; if(cacheControl.length > 0) { NSRange range = [cacheControl rangeOfString:kMaxAge]; if(range.location!=NSNotFound) { cacheControl = [cacheControl substringFromIndex:range.location + range.length]; return cacheControl.integerValue; } } return 0; } It allows you to extract key information from the server response header about how many seconds the life of the received packet will expire (the date will expire). Using this information, you can write data to the local storage, and when you repeat a similar request, just read the previously obtained data. If the method returns 0, then such data can be omitted.
Thus, on the server it is possible to regulate what exactly should be cached on the client. It is worth noting that standard header fields are used. So, in terms of the standard, the bicycle is not invented.
By another small modification of Listing 1, the queue issue is easily resolved:
Listing 9
- (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail queueAvailable:(BOOL)queueAvailable { self.requestSerializer = [AFJSONRequestSerializer serializer]; if(data == nil) data = @{}; if(queueAvailable) { [HttpQueue request:data endpoint:endpoint method:method]; } AFHTTPRequestOperation *operation = [self requestWithMethod:method path:endpoint parameters:data success:success fail:fail]; [operation start]; } The HttpQueue class checks whether there is currently a connection to the network and, if it does not exist, writes a request to the repository indicating the time of the request made to the nearest millisecond. When the connection is resumed, data is read from the storage and transferred from to the server, while simultaneously clearing the request queue. This makes it possible to provide a certain client-server operation without direct connection to the network.
Network connectivity is verified using Apple’s AFNetworkReachabilityManager or Reachability classes ( developer.apple.com/library/ios/samplecode/Reachability/Introduction/Intro.html ) together with the observer pattern. His device is too primitive to describe in the framework of the article.
However, not all requests must be sent to the queue. Some of them may not be relevant at the time of the appearance of the network. Deciding which teams should be written to the cache queue, and how to be relevant at the time of the call can be both at the level of the cache layer and at the level of the API layer.
In the first case, in Listing 9, instead of calling the save method in the queue, you need to insert a virtual method, and inherit the LocalCacheLayerWithQueue and LocalCacheLayerWithoutQueue classes from the ApiLayer class. Then in the specified virtual method of the LocalCacheLayerWithQueue class make a call [HttpQueue request: endpoint: method:]
In the second case, the call request from the ApiLayer class will change slightly.
Listing 10
- (void)trackNotification:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { [self request:data andEndpoint:TRACKNOTIFICATION_ENDPOINT andMethod:POST success:success fail:fail queueAvailable:YES]; } Listing 9 provides the if (queueAvailable) condition for this particular case.
Also, a separate issue is the issue of caching images. In general, the question is not complicated, and therefore, it has an infinite number of realizations. For example, the SDWebImage library does this quite successfully: ( github.com/rs/SDWebImage ).
Meanwhile, there are some things that she does not know how to do. For example, it cannot clear the cache of images according to specified criteria (the number of images, the date they were created, etc.), logging or correction of specific errors, that is, the developer still has to reinvent his bikes for caching.
I will give an example of an asynchronous download of an image from the network, with correction of a MIME error (for example, Amazon often gives the wrong MIME type, with the result that their web server sends the image, not as a binary file with a picture, but as a data stream).
Listing 11
#define LOCAL_CACHES_IMAGES_FILEPATH @"%@/Library/Caches/picture%ld.jpg" - (void)loadImage:(NSString*)link success:(void(^)(UIImage *image))success fail:(void(^)(NSError *error))fail { UIImage *image = [ImagesCache imageFromCache:link.hash]; if(image == nil) { dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ __block NSData *data; __block UIImage *remoteImage; __block NSData *dataImage; __block NSString *imgFilePath = [NSString stringWithFormat:LOCAL_CACHES_IMAGES_FILEPATH, NSHomeDirectory(), (unsigned long)link.hash]; data = [NSData dataWithContentsOfURL: [NSURL URLWithString:link]]; // Reading DATA if(data.length > 0) { remoteImage = [[UIImage alloc] initWithData: data]; // TRANSFORM DATA TO IMAGE if(remoteImage!=nil) { dataImage = [NSData dataWithData:UIImageJPEGRepresentation(remoteImage, 1.0)]; // TRANSFORM IMAGE TO JPEG DATA if(dataImage!=nil && dataImage.length > 0) [dataImage writeToFile:imgFilePath atomically:YES]; // Writing JPEG file } else // try to fix BINARY image type (first method) { [dataImage writeToFile:imgFilePath atomically:YES]; remoteImage = [UIImage imageWithContentsOfFile:imgFilePath]; } } else // try to fix BINARY image type (second method) { NSURLRequest *urlRequest = [NSURLRequest requestWithURL:[NSURL URLWithString:link]]; NSURLResponse *response = nil; NSError *error = nil; data = [NSURLConnection sendSynchronousRequest:urlRequest returningResponse:&response error:&error]; if (error == nil) { remoteImage = [[UIImage alloc] initWithData: data]; // TRANSFORM DATA TO IMAGE if(remoteImage!=nil) { dataImage = [NSData dataWithData:UIImageJPEGRepresentation(remoteImage, 1.0)]; // TRANSFORM IMAGE TO JPEG DATA if(dataImage!=nil && dataImage.length > 0) [dataImage writeToFile:imgFilePath atomically:YES]; // Writing JPEG file } NSLog(@"USED SECONDARY METHOD FOR LOAD OF IMAGE"); } else NSLog(@"DATA WASN'T LOAD %@\nLINK %@", error, link); } dispatch_async(dispatch_get_main_queue(), ^{ if(remoteImage!=nil && success!=nil) { success(remoteImage); [ImagesCache update:link.hash]; } else { if(data.length == 0) NSLog(@"%@", @"\n============================\nDETECTED ERRROR OF DOWNLOAD IMAGE\nFILE CAN'T LOAD\nUSED PLACEHOLDER\n============================\n"); else NSLog(@"%@", @"\n============================\nDETECTED ERRROR OF DOWNLOAD IMAGE\nUSED PLACEHOLDER\n============================\n"); NSLog(@"LINK %@", link); UIImage *placeholder = [LoadImage userPlaceholder]; if (success) success(placeholder); // if(fail!=nil) // fail([NSError errorWithDomain:[NSString stringWithFormat:@"%@ not accessible", link] code:-1 userInfo:nil]); } }); }); } else { success(image); } } The method may seem very redundant, but easily modified to the specific needs of the developer. From the important points, it should be noted that the image URL hash is used as the key for caching. It is almost impossible for such an approach to have a collision within the device file system.
Each time the file is read from the cache, the access date is modified. Files that are not reread for a long time, you can safely delete even at the start of the application.
When it comes to reading the file from the application bundle, there is a nuance that developers forget: the iOS SDK provides us with methods such as [UIImage imageNamed:] and [UIImage imageWithContentsOfFile:]. It is simpler to use the first one, but it significantly affects the memory load - the fact is that the file loaded with it remains in the device’s memory until the application is completed. If it is a file that has a large amount, then this can be a problem. It is recommended to use the second method as often as possible. It is also helpful to make a slight improvement in the boot method:
Listing 12
+ (UIImage *)fromBundlePng:(NSString *)name { return [[LoadImage sharedInstance] fromBundlePng:name]; } - (UIImage *)fromBundle:(NSString *)name { return [self downloadFromBundle:name.stringByDeletingPathExtension ext:name.pathExtension]; } - (UIImage *)downloadFromBundle:(NSString *)name ext:(NSString *)ext { NSString *filePath = [[NSBundle mainBundle] pathForResource:name ofType:ext]; if(filePath == nil) { NSString *filename = [NSString stringWithFormat:@"%@@2x", name]; filePath = [[NSBundle mainBundle] pathForResource:filename ofType:ext]; } return [UIImage imageWithContentsOfFile:filePath]; } Now you don’t have to wonder what resolution the file is in.
Workflows layer:
All implemented algorithms that do not belong to the kernel layers and do not constitute a GUI should be placed in classes of specific workflow sequences. Each of these processes is designed in its own style, and is connected to the main part of the application by adding references to an instance of the corresponding class in the GUI. In most cases, all these processes are not visual. However, there are some exceptions, for example, when it is necessary to carry out a long sequence of predefined animation frames, with specified display algorithms
The calling code must have minimal knowledge of this functionality.All flow settings must be encapsulated. Google gives as an example the code for notification from the analytics server, and suggests including it in the place where the event occurs.
Listing 13
// Analytics [Analytics passedEvent:ANALYTICS_EVENT_PEOPLE_SELECT ForCategory:ANALYTICS_CATEGORY_PEOPLE WithProperties:nil]; Obviously, if there is a need to notify another server, next to this code you will need to add the same code with your own settings. Such an approach is unjustified and unacceptable. Instead, you need to create a class that has a class method to call analytical servers with the specified functionality.
There are quite advanced workflows, the functioning logic of which depends on the internal state. Such processes should be implemented using the Strategy or State Machine patterns. As a rule, the “mediator” pattern is used in conjunction with the “strategy” pattern, which mediates a call to one or another algorithm.
— — « ». , flow «» , (Network Layer, Validation Items).
(callback), . , .
, , - . , . , , , , . , — , . . . , , .
Local storage:
, , , , . CoreData. , , , Apple , .
. CoreData , . , , CoreData . , , , , , , .
CoreData ( habrahabr.ru/post/191334), in addition, it also requires compliance with certain procedures, algorithms and architectural solutions, which limits us in choosing the development strategy, and also significantly complicates the debugging mechanisms of our application.
As a rule, the use of permanent storage is designed to ensure a significant reduction in network traffic, due to the use of information already received from the network. However, in some cases this does not happen because the source of this information is the server, which makes decisions about the relevance of this information.
Local storage based on the file system
Using NSDictionary as the format of the received data allows you to automatically solve a number of architectural problems:
- , .
- , POST (. . , , , POST ).
- .
- .
- ACID : en.wikipedia.org/wiki/ACID
- .
- .
- .
- (1 ).
/ iOS SDK NSDictionary , .
, . , .
, , , , 5, , , , , , , ViewController . () SQL ( ), , , . , , . , .
CoreData.
CoreData . - , . API profile, copyDataFromRemoteJSON, , ( NSManagedObject).
, :
14
[[Client client] profile:@{} success:^(id response) { [[Member getCurrentMember] copyDataFromRemoteJSON:[response valueForKey:@"data"]]; } fail:^(id response) { }]; , callback API , , , .
:
- .
- , . .
- , , .
- ( ) . .
- . (. . , , , , /, , ).
- ,
:
, NSFetchController , . , . . - . . , , , .
:
- , ( ):
- , , SQLite , «» . , - , , CoreData SQLite.
- , .
- . , , . , .
- Database , , , .
- ACID SQLite CoreData. . MagicRecords.
- . , , , , .
- CoreData . , CoreData .
- Since the relevance of the data is determined by the server, and not by the application, the data that was not received from the network still has to be deleted. Thus, the use of CoreData does not affect the network traffic in this scheme.
- The amount of code is many times greater than that needed to maintain storage based on the file system. Also, the use of CoreData imposes certain restrictions on the user interface.
Secondly, the shortcomings of the approach should also include the fact that:
- CoreData requires a certain discipline for working from various application threads, and choosing the actual context.
- Data synchronization can reduce the performance of the device so much that the issue of using 4S devices will be very relevant.
- . , MagicalRecords (https://github.com/magicalpanda/MagicalRecord) .
CoreData, , , . — CoreData , , , , NoSQL XML.
When using the MagicalRecords library, a situation arises when the table view must be part of the UITableViewController for the application to function properly, otherwise it becomes difficult to use the NSFetchController underlying CoreData data loading. Thus, there is a dependency in the use of the user interface, on local storage. That is, CoreData implementation limits the development of the UI.
Alternative view
Despite objections, using CoreData can, indeed, potentially increase performance with increasing data volume, if you use the following alternatives:
Alternative 1
API . , , , .
In this case:
, .
, , .
.
2
: CoreData JSON , . , , , .
:
- « » JSON .
- , . . .
- .
- , .
- SQLite .
- .
Conclusion: The
article was quite long, and I doubt that most readers will master it to the end. For this reason, the part related to the GUI I decided to throw out from here. Firstly, it related to building the user interface via UITabbar, and secondly, in one of the Skype groups, a very interesting discussion took place regarding the use of the well-known MVC and MVVM patterns. To state the principles of building an interface does not make sense without a rigorous presentation of existing practices and approaches that lead developers to a dead end. But this is a big topic for another multi-page article. Here, I tried to consider only issues related to the operation of the application core.
, , .
Source: https://habr.com/ru/post/246877/
All Articles