Building a text dictionary using the example of the AIF NLP library
It just so happened that every release of the AIF linguistic-independent library of natural text processing is accompanied by a note on what was done and how it works. Similar texts about the previous two releases of Alpha1 and Alpha2 can be found here and here . Not an exception to this rule was the current release of Alpha3, in which the opportunity appeared to build a dictionary of tokens for the input text. About how everything works under the hood and how it can be used in your project and will be discussed today.
Some terms
The terms are introduced not entirely in accordance with their canonical meaning, but in accordance with the meaning that they carry in this text (and on the project website). A full list of terms can be found here.
')
Today we will speak of a “simple” word, not a semantic one. Building semantic links in the text and vocabulary of semantic words of the text is the task of the next release.
“Similarity” tokens
It is easy to notice that some terms are incomplete and require some clarifications for their practical use. For example, the term “word” requires an explanation of what tokens are like. In our article, we will calculate the similarity of two tokens using the formula [1]. This formula shows the probability that two tokens are part of a single word. Accordingly, we assume that two tokens are part of a single word if the inequality [2] holds.
[one]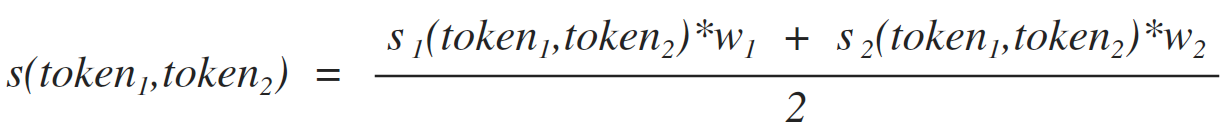
Where:
The formula for the similarity of tokens on the basis of counting common symbols
This formula has a proud name ... sorry, I forgot, but there is no candidate candidate with all the links at hand. But I am just sure that the valiant Habrayuzer will stick my nose in the correct answer, not being too lazy to write something poignant about this paragraph in particular, and the text in general)
[1.1]
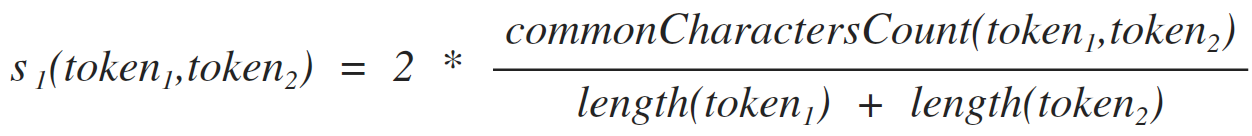
Where:
the formula is very simple - we only count the characters that are included in both tokens without taking into account the position of these characters in the tokens.
token-likeness formula based on recursive counting of the longest common strings
There is already more fun, the formula is recursive and also named after its author)
[1.2]
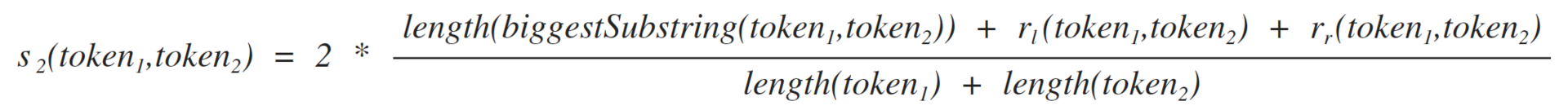
Where:
[1.2.1]

Where:
[1.2.2]

Where:
[2]
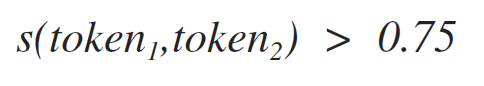
The threshold that is used in this inequality was chosen empirically: 0.75. In this release of AIF Alpha3, this parameter is brazenly “stitched with a dowel” in the code here . So, to change this value, you need to go through the entire project (
The fix for this ridiculousness is already planned in Alpha4 .
Comparison of words between themselves
In fact, a word is nothing more than a set of tokens interconnected according to a certain rule. We have already designated the rule (satisfying the condition of inequality 2). So the comparison of two words between themselves is solved quite simply ([3]).
[3]
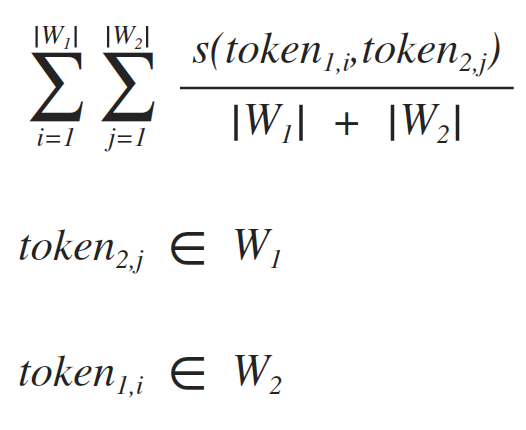
Little about practical application
The practice of building a dictionary is described on the page here . The process is very simple and takes no more than a few lines of code:
IDict interface:
Well, the IWord interface itself:
By the way, all the documentation for the Alpha3 release is right here.
there you can find a description of the API for working with tokens
and with suggestions
but back to the task of building a dictionary. An example of using this function can be found in the code of the console utility client of this library .
How to start using AIF in your project
Everything is quite simple, you need to connect our repository to your project like this:
and add one dependency:
An example of using the console utility AIF-CLI 1.2
The real work of the algorithm is considered on the example of a console utility that uses the AIF Alpha3 engine. You can read about the use of the utility here on this page . If you try to build a dictionary on a whole book, then be patient. Unfortunately, the current implementation is rather slow, on this occasion we have an issue , but it’s not at all clear when it comes to fixing it.
And here is an example of the work of the program which was set on the text of this article (only part of the output of the program is shown)
A bit about what to expect in the next release.
If everything goes as planned, then at the end of January we will release the 4th release of AIF, in which we will present the following features:
Other functions are possible if we have time;)
And again, you want to help the project - write to us. There are interesting tasks in the field of NLP - write to us. You do not want to help and there is no task, but there is something to say - write. We will be happy)
our team
Kovalevskyi Viacheslav - algorithm, design team, algorithm, team lead (viacheslav b0noi .com / b0noi )
Ifthikhan Nazeem - algorithm designer, architecture designer, developer
Sviatoslav Glushchenko - REST design and implementation, developer
Oleg Kozlovskyi QA (integration and qaulity testing), developer.
Balenko Aleksey (podorozhnick@gmail.com) - added stammer support to CLI, junior developer
Evgeniy Dolgikh - QA assistance, junior developer
Project links and details
Some terms
The terms are introduced not entirely in accordance with their canonical meaning, but in accordance with the meaning that they carry in this text (and on the project website). A full list of terms can be found here.
- Token is a sequence of alphabet characters bounded on two sides by separator characters.
- Language - all many unique tokens.
- Text language is the set of all possible unique tokens present in the text.
- A word is a subset of a language into which tokens belong, similar to each other.
- A semantic word is a subset of a language that includes tokens that have a similar context of use.
- Text dictionary is a set of all possible words based on the text language.
')
Today we will speak of a “simple” word, not a semantic one. Building semantic links in the text and vocabulary of semantic words of the text is the task of the next release.
“Similarity” tokens
It is easy to notice that some terms are incomplete and require some clarifications for their practical use. For example, the term “word” requires an explanation of what tokens are like. In our article, we will calculate the similarity of two tokens using the formula [1]. This formula shows the probability that two tokens are part of a single word. Accordingly, we assume that two tokens are part of a single word if the inequality [2] holds.
[one]
Where:
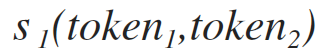
formula of similarity of tokens on the basis of counting common symbols (see formula 1.1)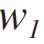
weight of the formula for the similarity of tokens on the basis of counting common characters (can take a value from 0. to 1.). This parameter is embedded in the code and has a value of 0.8 . Unfortunately, changing this situation is not yet included in Alpha4 release plans, but if you want to play around and don’t want to go through the project at all, then you can open us a task here and we will do everything.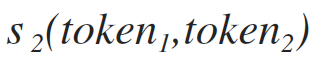
a formula for the similarity of tokens based on a recursive calculation of the longest common strings (see formula 1.2).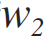
weight of the formula of similarity of tokens based on recursive counting of the longest common lines. With this weight, the same crap as with the past - no configuration through the config, the value 1 is hard wired.
The formula for the similarity of tokens on the basis of counting common symbols
This formula has a proud name ... sorry, I forgot, but there is no candidate candidate with all the links at hand. But I am just sure that the valiant Habrayuzer will stick my nose in the correct answer, not being too lazy to write something poignant about this paragraph in particular, and the text in general)
[1.1]
Where:
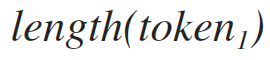
Token length,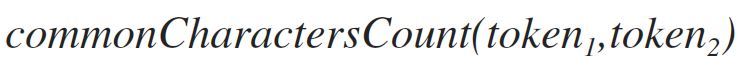
the number of characters that enter the first and second token at the same time. For example, for input tokens: “aabbvv”, “aaeeev”, the result will be 3, since there are 3 characters [a, a, in], which simultaneously belong to both tokens.
the formula is very simple - we only count the characters that are included in both tokens without taking into account the position of these characters in the tokens.
token-likeness formula based on recursive counting of the longest common strings
There is already more fun, the formula is recursive and also named after its author)
[1.2]
Where:
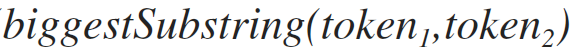
The maximum string that is simultaneously included in both tokens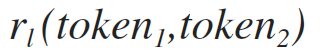
recursive call of formula 1.2 for the left substring, see formula 1.2.1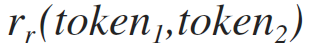
recursive call of formula 1.2 for the right substring, see formula 1.2.2
[1.2.1]
Where:
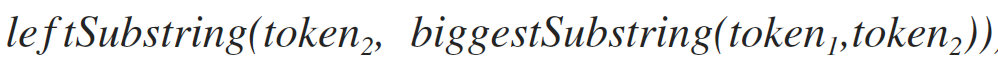
This method returns the substring of the first parameter in the range from the first character to the string that is passed in the second parameter. For example, for the strings “hello” and “ve” the result of the work will be “at”
[1.2.2]
Where:
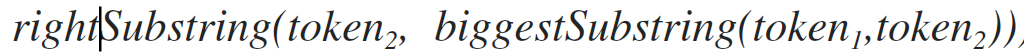
This method returns the substring of the first parameter in the range from the end of the string of the second argument in the first argument to the last character of the string. For example, for the strings “hello” and “ve” the result of the work would be “t”.
[2]
The threshold that is used in this inequality was chosen empirically: 0.75. In this release of AIF Alpha3, this parameter is brazenly “stitched with a dowel” in the code here . So, to change this value, you need to go through the entire project (
The fix for this ridiculousness is already planned in Alpha4 .
Comparison of words between themselves
In fact, a word is nothing more than a set of tokens interconnected according to a certain rule. We have already designated the rule (satisfying the condition of inequality 2). So the comparison of two words between themselves is solved quite simply ([3]).
[3]
Little about practical application
The practice of building a dictionary is described on the page here . The process is very simple and takes no more than a few lines of code:
final List<String> tokens = ... final IDictBuilder dictBuilder = new DictBuilder(); final IDict dict = dictBuilder.build(tokens); IDict interface:
public interface IDict { public Set<IWord> getWords(); } Well, the IWord interface itself:
public interface IWord { public String getRootToken(); public Set<String> getAllTokens(); public Long getCount(); public static interface IWordPlaceholder { public IWord getWord(); public String getToken(); } } By the way, all the documentation for the Alpha3 release is right here.
there you can find a description of the API for working with tokens
and with suggestions
but back to the task of building a dictionary. An example of using this function can be found in the code of the console utility client of this library .
public Void apply(String... args) { final String text; try { text = FileHelper.readAllTextFromFile(args[0]); } catch (IOException e) { e.printStackTrace(); return null; } final TokenSplitter tokenSplitter = new TokenSplitter(); final IDictBuilder<Collection<String>> stemmer = new DictBuilder(); final Set<IWord> result = stemmer.build(tokenSplitter.split(text)).getWords(); ResultPrinter.PrintStammerExtrctResult(result); return null; } How to start using AIF in your project
Everything is quite simple, you need to connect our repository to your project like this:
<project ...> <repositories> <repository> <id>aif.com</id> <url>http://192.241.238.122:8081/artifactory/libs-release-local/</url> </repository> </repositories> </project> and add one dependency:
<dependency> <groupId>io.aif</groupId> <artifactId>aif</artifactId> <version>1.1.0-Alpha3</version> </dependency> An example of using the console utility AIF-CLI 1.2
The real work of the algorithm is considered on the example of a console utility that uses the AIF Alpha3 engine. You can read about the use of the utility here on this page . If you try to build a dictionary on a whole book, then be patient. Unfortunately, the current implementation is rather slow, on this occasion we have an issue , but it’s not at all clear when it comes to fixing it.
And here is an example of the work of the program which was set on the text of this article (only part of the output of the program is shown)
java -jar aif-cli-1.2-jar-with-dependencies.jar -dbuild ~ / tmp / text1.txt
Basic token: explanations tokens: [[clarifications]]
Basic token: of tokens: [[of]]
Basic token: dowel ”tokens: [[dowel”]]
Basic token: public tokens: [[public]]
Basic token: words, tokens: [[words, words, word,]]
Basic token: volume, tokens: [[volume,]]
Basic token: perfect tokens: [[perfect]]
Basic token: code: tokens: [[code:]]
Basic token: [2]. tokens: [[[2]., [1]., [1.1]]]
Basic token: Interface tokens: [[Interface]]
Basic token: developer. tokens: [[developer., developer, developer,]]
Basic token: Sorry, change tokens: [[Sorry, change]]
Basic token: simultaneously tokens: [[simultaneously, simultaneously.]]
Basic token: testing), tokens: [[testing),]]
Basic token: (integration tokens: [[(integration]]
Basic token: characters tokens: [[characters]]
Basic token: language: tokens: [[[language:]]
Basic token: result tokens: [[result, result]]
Basic token: what tokens: [[what, something]]
Basic token: term tokens: [[term, terms]]
Basic token: done tokens: [[done]]
Basic token: Respectively tokens: [[Respectively]]
Basic token: Terms tokens: [[Terms]]
Basic token: long tokens: [[long]]
Basic token: tokens, tokens: [[tokens, tokens.]]
Basic token: book tokens: [[book]]
Basic token: exists tokens: [[exists]]
Press 'Enter' to continue or 'q' command to quit. There are -51 entities to show
A bit about what to expect in the next release.
If everything goes as planned, then at the end of January we will release the 4th release of AIF, in which we will present the following features:
- building vocabulary of semantic words
- search for synonyms in the text
- construction of the connection graph of semantic words in the text
Other functions are possible if we have time;)
And again, you want to help the project - write to us. There are interesting tasks in the field of NLP - write to us. You do not want to help and there is no task, but there is something to say - write. We will be happy)
our team
Kovalevskyi Viacheslav - algorithm, design team, algorithm, team lead (viacheslav b0noi .com / b0noi )
Ifthikhan Nazeem - algorithm designer, architecture designer, developer
Sviatoslav Glushchenko - REST design and implementation, developer
Oleg Kozlovskyi QA (integration and qaulity testing), developer.
Balenko Aleksey (podorozhnick@gmail.com) - added stammer support to CLI, junior developer
Evgeniy Dolgikh - QA assistance, junior developer
Project links and details
- project language: Java 8
- license: MIT license
- issue tracker: github.com/b0noI/AIF2/issues
- wiki: github.com/b0noI/AIF2/wiki
- source code: github.com/b0noI/AIF2
- developers mail list: aif2-dev@yahoogroups.com (subscribe: aif2-dev-subscribe@yahoogroups.com)
Source: https://habr.com/ru/post/246383/
All Articles