JSOC: how to prepare incidents
Colleagues, good afternoon.
We slightly delayed with the release of our next article. Nevertheless, she is ready and I want to submit an article by our new analyst and author - Alexey Pavlov - avpavlov .
In this article, we will look at the most important aspect of the “livelihoods” of any Security Operation Center — the identification and operational analysis of emerging threats to information security. We will describe how the rules are set up, as well as the detection and recording of incidents in our outsourced monitoring and response center JSOC.
')
About how JSOC works, we talked in our previous articles:
JSOC: the experience of the young Russian MSSP
JSOC: how to measure availability of the Security Operation Center?
Among them, it was mentioned that the core of the JSOC is the HP ArcSight ESM SIEM system. In this article we will focus on the description of its settings and improvements that were implemented to reduce the number of false-positive-events, operational connection of new systems and GIS, as well as increasing the speed and transparency of the process of analyzing potential incidents for our customers.
Any SIEM has a “out of the box” set of predefined correlation rules, which, by comparing events from sources, can alert the client about the threat. Why, then, need an expensive configuration of this system, as well as its support by the integrator and its own analyst?
To answer this question, it is necessary to tell how the life cycle of events that fall into the JSOC from sources is arranged, what is the path from triggering the rule to creating an incident.
Primary event handling occurs on the connectors of the SIEM system. Processing includes filtering, categorization, prioritization, aggregation, and normalization. The event in CEF (Common Event Format) format is then sent to the core of the HP ArcSight system, where its correlation and visualization occurs. These are standard mechanisms for handling any SIEM event. As part of the JSOC, we have refined them to enhance our ability to monitor incidents and obtain information about end systems.
One of the main functions of the SIEM are filtering and categorizing the events that occur on the connectors. In an average SIEM system, 6000–8000 EPS (Event per Second) is considered a normal flow of events, while the number of event types from 50–80 sources is in the thousands. For the convenience of processing such a volume of information, event categories were invented.
Note that on the equipment and in the systems of different vendors, the same events are often called differently. For example, the start of a session as part of a TCP connection for Cisco has the name “Built inbound TCP connection”, for Juniper - “session created”, and for Checkpoint these are two events: depending on the success of the connection - “accept” or “block”. In order to avoid modifying the correlation rules "under the new vendor" when devices appeared, event categories were introduced that determine the action to be performed.
Example: event from Juniper firewall - “session start”
Category Significance: / Informational - message type - informational
Category Device Type: Firewall - firewall event
Category Behavior: / Access / Start - open session
Category Outcome: / Success - Successful
Thus, if we need to track successful access events from all devices in the correlation rule, we simply specify Category Behavior: / Access / Start, Category Device Type: Firewall, Category Outcome: / Success.
In addition to the standard categorization within the JSOC framework, we implemented an additional one to minimize possible changes in the rules that generate incidents. These rules work for different customers, and changing the parameters under one of them can lead to a temporary and / or complete inoperability of the solution for all.

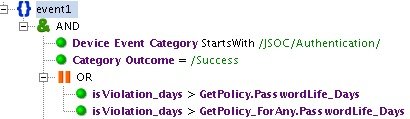
Fig. 1. Event categorization by the example of the “INC_Password Change Needed” rule
As an example, we give the rule "INC_Password Change Needed". Its main task is to notify if authentication has occurred in the system under an account with an expired password. The period is calculated according to corporate rules and varies depending on the customer. This rule uses the JSOC “Device Event Category starts with / JSOC / Authentication /” categorization, which includes all authentication events from various sources, and the standard categorization “HP Arcsight - Category Outcome = / Success” - a successful connection event.
To handle certain types of events that fall into the core of the system, special profiling and basic rules have been introduced in JSOC. Mapping rules for a wide variety of activities play one of the most important roles. They form the primary data recorded in the active list and later used in the calculations of average, maximum and fluctuation indicators. Such rules include data on authentication, access to resources, daily traffic, white lists of IP addresses for access to key systems, etc. After typical activity profiles are filled, we can create rules that will fix the deviation from normal activity.
Basic rules I would like to highlight a separate item. Adding missing information to events — username to events from firewalls, account owner information from the personnel system, additional description of hosts from the CMDB — is implemented in JSOC to speed up the incident resolution process and get all the necessary information in one event.
A striking example of the use of basic rules is the "CISCO_VPN_User Session Started". This rule allows you to associate the IP address of the employee connecting via VPN with his username (this information is in different events coming from the Cisco ASA).
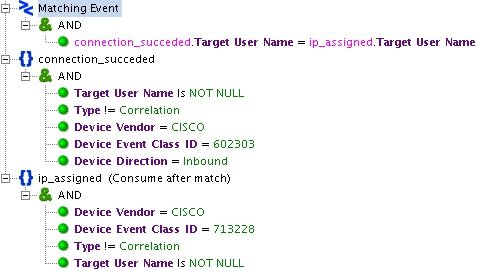
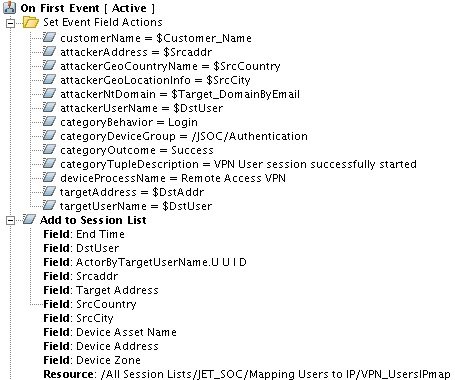
Fig. 2. Example of basic rule settings
There are several options for registering anomalous activities:
Let's look at each option in more detail.
The easiest way to use correlation rules is to trigger when a single event from a source occurs. This works great if the SIEM system is used in conjunction with customized GIS.
When stopping a critical service on a monitored server, the INC_Critical Service Stopped rule is triggered. This event may indicate malicious user behavior or malware. But the majority of directed attacks on the company, as well as internal incidents, cannot be identified by a single event.
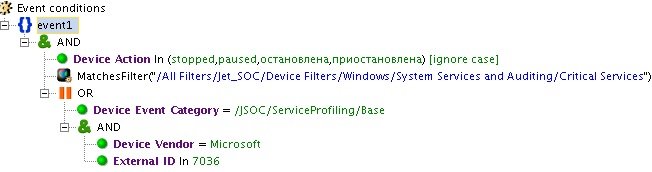
Fig. 3. Example of triggering a rule on a single event from a source
The second way - triggering correlation rules for several consecutive events over a period - ideally falls into infrastructure security.
Logging in under one account to the workstation and further logging into the target system under another (or the same scenario with VPN and information system) indicates the possibility of theft of these accounts. Such a potential threat is common, especially in the day-to-day work of administrators (domain: a.andronov, Database: oracle_admin), and causes a large number of false positives, so the creation of white lists and additional profiling are required.

Fig. 4. An example of triggering a rule on a sequence of events from several sources
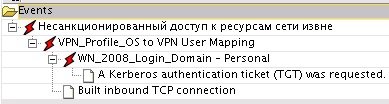
Fig. 5. Example of comparison of events on the incident "unauthorized access to resources from outside"
The third way to set up rules is great for detecting various scans, brute force, epidemics, and also DDoS.
A large number of unsuccessful attempts to log in may indicate a brute force attack. The “BF_INC_SSH_Dictionary Attack” rule is configured to track 20 unsuccessful login attempts on Unix systems.
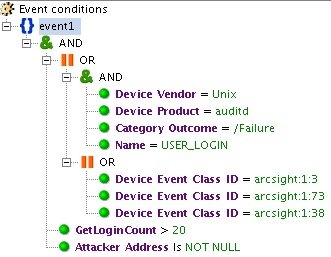
Fig. 6. An example of triggering a rule for a certain number of events of the same type
The most difficult, at the same time effective and universal way of registering anomalous activities is the use of profiles.
An example is the INC_AV_Virus Anomaly Activity correlation rule, which tracks the excess of the average antivirus response rate (calculated on the basis of the profile) for a certain period.
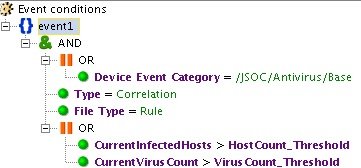
Fig. 7. Example of rule triggering on exceeding the average
Developing JSOC, we drew certain lessons that became the basis for the following recommendations for creating correlation rules:
At the same time, I would like to note: no matter how well the SIEM system is configured, False Positive events will always be present. If not, then SIEM is dead. That is why it is important to have qualified monitoring engineers who can identify the real incident. The specialist should have a set of knowledge on information security, profiles of possible attacks and know the final systems for analyzing events.
As a final word, I would like to summarize the recommendations for organizing my own SOC in a company:
We slightly delayed with the release of our next article. Nevertheless, she is ready and I want to submit an article by our new analyst and author - Alexey Pavlov - avpavlov .
In this article, we will look at the most important aspect of the “livelihoods” of any Security Operation Center — the identification and operational analysis of emerging threats to information security. We will describe how the rules are set up, as well as the detection and recording of incidents in our outsourced monitoring and response center JSOC.
')
About how JSOC works, we talked in our previous articles:
JSOC: the experience of the young Russian MSSP
JSOC: how to measure availability of the Security Operation Center?
Among them, it was mentioned that the core of the JSOC is the HP ArcSight ESM SIEM system. In this article we will focus on the description of its settings and improvements that were implemented to reduce the number of false-positive-events, operational connection of new systems and GIS, as well as increasing the speed and transparency of the process of analyzing potential incidents for our customers.
Any SIEM has a “out of the box” set of predefined correlation rules, which, by comparing events from sources, can alert the client about the threat. Why, then, need an expensive configuration of this system, as well as its support by the integrator and its own analyst?
To answer this question, it is necessary to tell how the life cycle of events that fall into the JSOC from sources is arranged, what is the path from triggering the rule to creating an incident.
Primary event handling occurs on the connectors of the SIEM system. Processing includes filtering, categorization, prioritization, aggregation, and normalization. The event in CEF (Common Event Format) format is then sent to the core of the HP ArcSight system, where its correlation and visualization occurs. These are standard mechanisms for handling any SIEM event. As part of the JSOC, we have refined them to enhance our ability to monitor incidents and obtain information about end systems.
Filtering and categorization
One of the main functions of the SIEM are filtering and categorizing the events that occur on the connectors. In an average SIEM system, 6000–8000 EPS (Event per Second) is considered a normal flow of events, while the number of event types from 50–80 sources is in the thousands. For the convenience of processing such a volume of information, event categories were invented.
Note that on the equipment and in the systems of different vendors, the same events are often called differently. For example, the start of a session as part of a TCP connection for Cisco has the name “Built inbound TCP connection”, for Juniper - “session created”, and for Checkpoint these are two events: depending on the success of the connection - “accept” or “block”. In order to avoid modifying the correlation rules "under the new vendor" when devices appeared, event categories were introduced that determine the action to be performed.
Example: event from Juniper firewall - “session start”
Category Significance: / Informational - message type - informational
Category Device Type: Firewall - firewall event
Category Behavior: / Access / Start - open session
Category Outcome: / Success - Successful
Thus, if we need to track successful access events from all devices in the correlation rule, we simply specify Category Behavior: / Access / Start, Category Device Type: Firewall, Category Outcome: / Success.
In addition to the standard categorization within the JSOC framework, we implemented an additional one to minimize possible changes in the rules that generate incidents. These rules work for different customers, and changing the parameters under one of them can lead to a temporary and / or complete inoperability of the solution for all.
Fig. 1. Event categorization by the example of the “INC_Password Change Needed” rule
As an example, we give the rule "INC_Password Change Needed". Its main task is to notify if authentication has occurred in the system under an account with an expired password. The period is calculated according to corporate rules and varies depending on the customer. This rule uses the JSOC “Device Event Category starts with / JSOC / Authentication /” categorization, which includes all authentication events from various sources, and the standard categorization “HP Arcsight - Category Outcome = / Success” - a successful connection event.
Basic and profiling rules
To handle certain types of events that fall into the core of the system, special profiling and basic rules have been introduced in JSOC. Mapping rules for a wide variety of activities play one of the most important roles. They form the primary data recorded in the active list and later used in the calculations of average, maximum and fluctuation indicators. Such rules include data on authentication, access to resources, daily traffic, white lists of IP addresses for access to key systems, etc. After typical activity profiles are filled, we can create rules that will fix the deviation from normal activity.
Basic rules I would like to highlight a separate item. Adding missing information to events — username to events from firewalls, account owner information from the personnel system, additional description of hosts from the CMDB — is implemented in JSOC to speed up the incident resolution process and get all the necessary information in one event.
A striking example of the use of basic rules is the "CISCO_VPN_User Session Started". This rule allows you to associate the IP address of the employee connecting via VPN with his username (this information is in different events coming from the Cisco ASA).
Fig. 2. Example of basic rule settings
Creating and configuring correlation rules
There are several options for registering anomalous activities:
- On a specific event from the source
- On several consecutive events from sources for a certain period;
- Upon reaching the threshold number of events of the same type for a certain period;
- By the deviation of any indicators from the reference (or average) value.
Let's look at each option in more detail.
The easiest way to use correlation rules is to trigger when a single event from a source occurs. This works great if the SIEM system is used in conjunction with customized GIS.
When stopping a critical service on a monitored server, the INC_Critical Service Stopped rule is triggered. This event may indicate malicious user behavior or malware. But the majority of directed attacks on the company, as well as internal incidents, cannot be identified by a single event.
Fig. 3. Example of triggering a rule on a single event from a source
The second way - triggering correlation rules for several consecutive events over a period - ideally falls into infrastructure security.
Logging in under one account to the workstation and further logging into the target system under another (or the same scenario with VPN and information system) indicates the possibility of theft of these accounts. Such a potential threat is common, especially in the day-to-day work of administrators (domain: a.andronov, Database: oracle_admin), and causes a large number of false positives, so the creation of white lists and additional profiling are required.
Fig. 4. An example of triggering a rule on a sequence of events from several sources
Fig. 5. Example of comparison of events on the incident "unauthorized access to resources from outside"
The third way to set up rules is great for detecting various scans, brute force, epidemics, and also DDoS.
A large number of unsuccessful attempts to log in may indicate a brute force attack. The “BF_INC_SSH_Dictionary Attack” rule is configured to track 20 unsuccessful login attempts on Unix systems.
Fig. 6. An example of triggering a rule for a certain number of events of the same type
The most difficult, at the same time effective and universal way of registering anomalous activities is the use of profiles.
An example is the INC_AV_Virus Anomaly Activity correlation rule, which tracks the excess of the average antivirus response rate (calculated on the basis of the profile) for a certain period.
Fig. 7. Example of rule triggering on exceeding the average
Developing JSOC, we drew certain lessons that became the basis for the following recommendations for creating correlation rules:
- You must use profiling. For one client, it can be absolutely normal to use TOR on a host, and for another, it is a direct way to dismiss an employee. Some VPN-access has only trusted administrators who can work with the entire infrastructure, others have access to half of the employees, but they only work with their station. But at the same time, the overwhelming majority of the company's employees work according to the same scenario on a daily basis, it is easy to profile it, therefore, it is easy to register anomalies. Therefore, in JSOC we use the same rules, but the parameters, lists, filters in them are individual for each client;
- Difficult rules do not work: if you pile up a dozen conditions for triggering rules to minimize the number of False Positive, the chance of their triggering is low, and the risk of missing something important is high;
- SIEM should solve only its own tasks. No need to try to drop everything on it, if for these purposes there are specialized solutions. For example, you need to configure a rule that should work if an external IP address attempts to make more than 1000 connections to an external resource in 1 minute. It is much easier to configure this rule on IPS, which is intended for this without loading SIEM with extra work.
At the same time, I would like to note: no matter how well the SIEM system is configured, False Positive events will always be present. If not, then SIEM is dead. That is why it is important to have qualified monitoring engineers who can identify the real incident. The specialist should have a set of knowledge on information security, profiles of possible attacks and know the final systems for analyzing events.
Conclusion
As a final word, I would like to summarize the recommendations for organizing my own SOC in a company:
- The most important element of SOC is the SIEM-system, the issues of its selection were discussed in the first article of the cycle, but the most important point is its adjustment to the requirements of the business and infrastructure features;
- Creating correlation rules to detect various attack scenarios and the activities of intruders is a huge layer of work that never ends due to the constant development of threats. That is why you need to have your own qualified analyst;
- The first line of monitoring engineers should be formed on the basis of the information security department. The specialist should be able to distinguish False Positive responses from real incidents and conduct a basic analysis of events. This requires skills in the field of information security and an understanding of possible attack vectors.
Source: https://habr.com/ru/post/246205/
All Articles