How the developers sat in St. Petersburg and quietly ate mushrooms, and then they wrote the OS for data storage systems

At the end of 2008, at that time a small St. Petersburg company came out of a Western media holding, like this:
- Did you put up a hardcore there and adapted the SSE instructions to implement the Reed-Solomon code?
- Yes, only we do not ...
- I do not care. Want an order?
The problem was that video editing required hellish performance, and then RAID-5 arrays were used. The more disks in a RAID-5, the higher the probability of failure right during installation (for 12 disks - 6%, and for 36 disks - already 17-18%). Drop disk during installation is not allowed : even if the disk falls in the high-end storage system, the speed dramatically degrades. The media holder got tired of screaming to bang his head against the wall every time, and therefore someone advised them of the gloomy Russian genius.
')
Much later, when our compatriots grew older, a second interesting problem arose - Silent Data Corruption . This is a type of storage error, when both the bit in the main data and the check bit are simultaneously changed on the pancake. If we are talking about videos or photos - in general, no one will even notice. And if we are talking about medical data, then this becomes a diagnostic problem. So there was a special product for this market.
Below is the history of what they did, a bit of math and the result is the OS for highload storage . Seriously, the first Russian OS, brought to mind and released. Although for storage systems.
Media holding
The story began in 2008-2009 as a project for an American customer. It was necessary to develop a data storage system that would provide high performance and at the same time cost less than a cluster of ready-made high-end storage systems. The holding had a lot of standard iron on the type of Amazon-farms - x86-architecture, typical shelves with disks. It was assumed that "these Russian" will be able to write such a management software that will cluster the devices and thereby ensure reliability.
The problem, of course, is that RAID-6 required a lot of processing power to work with polynomials, which was not an easy task for the x86 CPU. That is why the storage vendors used and used their options and delivered the rack as a kind of “black box” as a result.
But back in 2009. The main task at the beginning of the project was fast data decoding . In general, the company RAIDIX (this is how our heroes began to call much later) always dealt with high decoding performance.
The second task is to ensure that when the disk fails, the read-write speed does not subside . The third task is a bit like the second - to deal with the problems of errors on the HDD , which occur unknown when and on what media. In fact, a new field of work has opened up - the detection of hidden data defects for reading and their correction.
These problems were relevant then only for large, very large storage and really fast data. By and large, the architecture of “ordinary” storage systems suited everyone, except those who constantly used really large amounts of data for reading-writing (and did not work 80% of the time with a “hot” data set that made up 5-10% of the DBMS).
At that time, there was no end-to-end data protection standard per se (more precisely, there was no sane implementation), and even now they are far from being supported by all disks and controllers.
The solution of the first problems
The project has begun. Andrei Ryurikovich Fedorov, a mathematician and founder of the company, began by optimizing data recovery using the typical architecture of Intel processors. Just then, the first project team found a simple but really effective approach to vectoring multiplication by the primitive element of the Galu field. When using SSE registers, 128 field elements are multiplied by x simultaneously for several XORs. And as you know, the multiplication of any polynomials in finite fields can be reduced to multiplication by a primitive element due to the factorization of multiplication. In general, there were many ideas using the advanced features of Intel processors.
When it became clear that the ideas were generally successful, but it was necessary to write an OS-level product to work at the lowest level, a department was first allocated, and then a separate RAIDIX company was founded.
There were a lot of ideas, for study and verification employees of the University of St. Petersburg State University were found. Work began at the intersection of science and technology - attempts to create new algorithms. For example, a lot of work with the inversion of matrices (this is an algorithmically difficult task, but very important for decoding). Picked Reed-Solomon, tried to increase the dimension of the field of two in the sixteenth, two in two hundred and fifty-sixth degree, looking for quick ways to detect Silent Data Corruption. Conducted experiments to prototypes in assembler, evaluated the algorithmic complexity of each option. Most of the experiments gave a negative result, but for about 30-40 attempts one was positive in performance. For example, the same increase in the dimension of the field had to be removed - in theory, this was great, but in practice it caused a deterioration in decoding, because the cache miss increased significantly (misses in the cache).
Then there was a systematic work on the expansion of RAID 7.N. We checked what would happen with the increase in the number of disks, disk splits, and so on. Intel added an AES instruction set for security, among which a very convenient instruction for multiplying polynomials (pclmulqdq) was found. We thought that it could be used for code - but after checking the advantages in comparison with the existing performance, we did not find it.
The company has grown to 60 people dedicated exclusively to data storage.
In parallel, we began to work on a fault-tolerant configuration. At first it was assumed that the failover cluster would be based on open source software. Faced with the fact that the quality of the code and its universality were insufficient for solving specific practical problems. At this time, new problems began to appear: for example, when the interface crashed, the re-election and switching of the wizard were traditionally held on the controller. This together took astronomical time - up to a minute or two. It took a new system of hosts: they started assigning points for each session (the more open sessions, the more points), and the new hosts made discover. In the third generation, it was found that even with synchronous replication due to the peculiarities of software and hardware implementation, the session on one controller could appear earlier than on the other - and an unwanted handover with switching occurred. It took the fourth generation - its own cluster manager specifically for the storage system, in which the failures of the host interfaces and backend interfaces were handled correctly, taking into account all the features of the hardware. It took very much to complete the software at a low level, but the result was worth it - now a couple of seconds to switch the maximum, plus Active-Active has become much more correct. Added autoconfiguration of baskets with disks.
In the end, they made a very good optimization of SATA with the transition to RAID 7.3 - support for data recovery without loss of performance.
Implementation
This solution is used by storage vendors, as well as owners of large repositories from the United States, China and Korea. The second category is the non-current tasks of integrators, most often media, supercomputers, and healthcare. During the Olympic Games, the end-user was Panorama sports broadcasting studio, they just made a picture from the Olympiad. There are users of RAIDIX in Germany, India, Egypt, Russia, USA.
It turned out this:
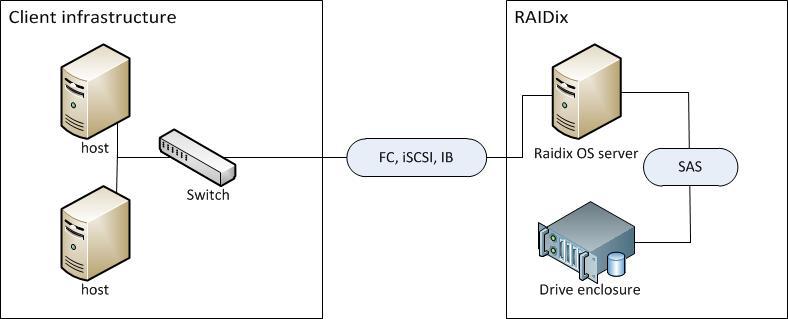
On one controller: regular x86 hardware + OS = fast and very, very cheap storage.
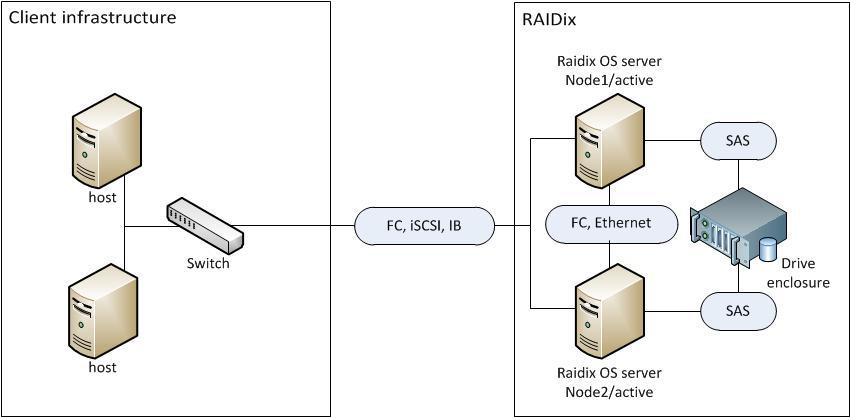
Two controllers: a redundant system is obtained (but more expensive).
An important feature is the partial recovery of the volume. There are three checksums for each stripe:

Thanks to our own algorithm for calculating a RAID array, it is possible to recover only a separate disk area containing damaged data, reducing the array recovery time. This is very effective for large volumes of arrays.
The second thing is that a proactive reconstruction mechanism is implemented, excluding up to two (RAID 6) or up to three (RAID 7.3) drives from the process, the reading speed of which is lower than that of the others. When recovering is faster than reading, naturally, the first option is used.
It works like this: from K strips, you get the KN needed to assemble the data section. If the data is integer, the reading of the remaining strips stops.
This means that in RAID 7.3, having 24 disks with 3 failures - 12 Gb / s per core (4 cores) - the recovery speed exceeds the read speed of the backup and even the access to RAM - despite the loss of the disk, the read remains.
The next low-level problem is an attempt to read a broken section. Even on the enterprise systems, the delay can be 8 seconds - surely you have seen such “hang-ups” of the HDD-DSS. Given this algorithm, the failure to send data from three disks out of 24 simply means a slowdown in reading for a few milliseconds.
Moreover, the system remembers the discs with the longest response time and stops sending requests to them within one second. This reduces the load on system resources. The discs with the longest response time are assigned the status of “slow” and a notification is made that they should be replaced.
Interface Screenshots
Considering the advantages of RAIDIX OS, many customers decided to migrate to it. This was due to the lack of company size - it’s difficult for a Petersburg developer to take into account all the features of database mirroring and other specific data. The latest version has made great strides towards a smooth migration, but it’s still smooth and smooth, like Active-Active high-end storage systems with Active-Active mirror connections will not work, most likely you will need a shutdown.
Details
In Russia, I personally see the opportunity to receive for minimal money quite interesting storage options. We will build on a normal stable hardware solutions that will be put ready for customers. The main advantage, of course, is the ruble per Gb / s . Very cheap.
For example, here is the configuration:
- HP DL 380p gen8 server (Intel Xeon E5-2660v2, 24 GB of memory + LSI SAS HBA 9207-8i controllers).
- Spread RAIDIX 4.2 on 2 disks, the remaining 10 - 2TB SATA.
- External interface - 10 Gbit / s Ethernet.
- 20 TB of space that can be used.
- + Licenses for 1 year (including TP and updates).
- The price of the sale at the price: $ 30,000.
An expansion shelf connected via SAS with 12 disks of 2 TB on price is $ 20,000. The price includes OS preinstallation. Under data on disks with data 97% of a place leaves. LUN unlimited size. Fiber Channel supported; InfiniBand (FDR, QDR, DDR); iSCSI. There are SMB, NFS, FTP, AFP, Hot Spare, UPS, 64 disks in a RAID 0/6/10 / 7.3 array (with triple parity). 8 Gb / s on RAID 6. There is QoS. As a result, the optimal solution for post-production, in particular, color correction and editing, for TV broadcasting, and folding data from HD cameras. With a family of nodes, you can get 150 Gb / s without a significant decrease in reliability and even under Luster - this is a highload area.
Here is a link for specs and more details (PDF).
Tests
1. Single-controller configuration. Server SuperMicro SSG-6027R-E1R12L 2 units. 12 disks of 4 TB Sata 3.5 ". External interface 8Gbit / s FC. 48 TB of unallocated space for $ 12,000
2. Dual-controller configuration. SuperServer 6027TR-DTRF server, it has 2 boards (like blades). Add a shelf with 45 disks of 4 TB. External interface 8Gbit / s FC. 180 TB of unallocated space for $ 30,000.
Configuration a - RAID 7.3 on 12 disks. 36 TB of usable capacity, $ 0.33 / Gb.
Configuration b - three RAID 7.3 with 15 drives. 0.166 $ / GB
FC 8G Performance | ||||
Sequential Read / Write | ||||
Operation type | Block size | |||
Iops | MBps | |||
read | 4K | 80360.8 | 329.1 | 55,8 |
128K | 11946.7 | 1565.8 | 54.3 | |
1M | 1553.5 | 1628.9 | 98.3 | |
write | 4K | 18910.8 | 77.4 | 44.8 |
128K | 9552.2 | 1252.0 | 54.9 | |
1M | 1555.7 | 1631.2 | 100.4 | |
Here are the remaining results .
Generally
I am very pleased that we suddenly found such a manufacturer, who solved very specific tasks. The company does not release its components, and they do not have other business services, they also do not plan to integrate systems, as we agreed to cooperate. As a result, my department is now engaged, in particular, with solutions based on the RAIDIX OS. The first implementations in Russia, of course, will go strictly together with the manufacturers.
We run in some configurations on the demo stand, and, in general, we are satisfied, even though we found a couple of pitfalls (which is normal for new software versions). If you are interested in details on implementation - write to atishchenko@croc.ru, I will tell you in more detail whether it is worth it or not.
Source: https://habr.com/ru/post/246155/
All Articles