Onto-engineer: from the creation of the world to the generation of entities
 In this post I will continue the story about the part of Compreno, which is related to the profession of engineer. Well, or about the work of an engineer who is associated with the above-mentioned technology - this is someone who is more comfortable to perceive.
In this post I will continue the story about the part of Compreno, which is related to the profession of engineer. Well, or about the work of an engineer who is associated with the above-mentioned technology - this is someone who is more comfortable to perceive.Let me remind you that the first part has led us to the fact that onto-engineers build ontologies so that the technology can work (without them, nowhere, everything is so arranged).
A little more complete description of the first part:
- Our system of information extraction is based on the presentation of the text in the form of syntactic-semantic trees Compreno.
- The tree nodes correspond approximately to the words in the sentence, and the arcs reflect the dependencies between them (from the point of view of the dependency grammar ).
- Trees are a formal representation of the “meaning” of a statement, therefore language ambiguities are already resolved in them.
- Having received these trees at the input, at the output the system issues information objects - entities (persons, organizations, locations, etc.) or facts (arrests, deaths, purchases, relatives, education, etc.).
- The formal models of reality, within which all these facts and entities exist, are called ontologies. Automotive engineers develop ontologies using the OWL standard .
About what else, and, of course, why the on-engineers are doing, I propose to find out right now.
Seven battles - one subtree
The main engineer devotes the bulk of his work time not to “modeling the world” (although this sounds very proudly), but to creating an extraction system. And although we are increasingly experimenting with statistics, machine learning and automatic pattern extraction, for now our products and projects use rules written by hand. However, these rules are not some kind of rigid patterns based on the linear order of words in a sentence, but descriptions of fragments of ABBYY Compreno semantic-syntactic trees. This allows us to bypass the variability and ambiguity of a language relatively easily by briefly specifying the many options used to express the same meaning.
')
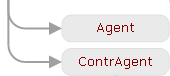
A simple example: if we ask you to find such a subtree in which there is a node node with the semantic class “CONFLICT_INTERACTION” (a high enough class of our hierarchy, from which all concepts related to confrontation, conflicts, confrontations and competitive activity are inherited), under which there is the child node with the Agent deep position (actively acting participant in the situation) and the ContrAgent (special “counterparty” deep position), various examples of confrontations will be found:
656 BC e. - The Battle of Tullise - The Battle of the Elamites with the Assyrians
474 BC e. - Battle of Cumas - victory of the Syracusans under the leadership of Hieron I over the Etruscans
February 2 - Day of the defeat of nazi troops by the Soviet troops in the Battle of Stalingrad
On October 1, the battle of Povetkin and American Tommy Connelly was originally scheduled
A series of regicides marked the beginning of the struggle of the nobility with kings
The artist V.P. Vereshchagin painted the painting “ The Battle of Dobrynya with the Serpent Gorynych” for the palace of Grand Duke Vladimir Alexandrovich
For almost three decades, a small detachment of archers fought with foreigners
How Ivan Ivanovich fell out with Ivan Nikiforovich
French ambassador to Turkey began to make every effort to embroil Russia with Turkey
In 1983, it came to street punks clashes with police
in Medvedev’s conflict with Kudrin, Putin “non-publicly, apparently, sided with the Minister of Finance
Twice they broke the Siberian Tatars , on the Tour and at the mouth of the Tavda
Courageously, like thousands of other citizens, Shostkins fought with the Nazi invaders on the fronts of the Great Patriotic War, in partisan detachments
Since 1989, the Count begins uncompromising rivalry with the Yugoslav tennis player Monica Seles
Other feline cats, especially long-tailed cats and ocelots, are food competitors of the jaguarundi, however this cat avoids direct competition with them due to its daytime lifestyle; they also compete with foxes , coyotes, ginger lynxes and pumas

Then we can introduce many other conditions. For example, it is easy to limit the semantic classes of participants and demand that the class “HUMAN” be there - then only examples like Ivan Ivanovich with Ivan Nikiforovich will remain, and the quarrel between Russia and Turkey will not be found. In addition, you can enter conditions for different grammatical characteristics (time, number, pledge), positions in the surface syntax, semantic properties - thousands of them. And now more about how we are looking for such subtrees and what else can you ask from Compreno.
Templates for subtrees are set using production rules. These rules consist of classic “if - then” products, in which the left and right sides are separated using the => operator. On the left, we write a condition that defines a set of subtrees. In the right - statements about the existence of information objects (ie, entities and facts), their relationship and binding to the text (ie, to some nodes of the trees). In the tree patterns of the left, standard logical connectives are used (conjunction, disjunction, negation), as well as conditions for the mutual arrangement of nodes in the tree. In particular, it is possible to check whether a node is directly a child or whether it enters into the subtree of another node at all.
We give an example - one of the rules for the extraction of persons. It deals with the case when a person is mentioned with a generic prefix (“von Bismarck”, etc.). Square brackets indicate a transition to a child node. In the left part of the rule, two variables are entered: von and this. In the right part, logical statements are formulated that use the variables entered:
//, . ~<Lex_NameBracketed> [ // – , . . von "PART_OF_SURNAME_PREFIX" [ // : , // . , , // ( // , // ) this ( <!InitialCore!> ~<Lex_NameBracketed> ~"FOREIGN_WORD" ~"ACRONYM_") | "PERSON_BY_LASTNAME" ] ] => // Person, , // von. P // ( ). Person P( von ), // : // , von, // – , this. // core , // (), . annotation( P, von.core, this.core ), // , P , // this. c Coreferential , // , // , . anchor( P, this, Coreferential ), // , middlename , // , // middlename_cs. // : // middlename_cs middlename. P.middlename == Norm( P.middlename_cs ), // , surname , // // , von this. P.surname == Norm( von.core, this.core ); When developing the system, it quickly became clear that we want to be able to refer to already extracted objects from other rules, rely on them in conditions, modify them after extraction, etc. For this, a functional was implemented that allows you to search in a subtree not only for nodes with some linguistic properties, but also for objects attached to these nodes created by other rules. Thus, object conditions appeared in our products. Here is a fragment of the rule in which such an object condition is used. In this rule, we are looking for an already extracted person to add the necessary attributes to it.
// – , this "PERSON_BY_FIRSTNAME" [ // , // P. // – , // - ( // ). P // . // , , // P // Classifier_Name. , , // middle. // , P // Person, surname , // firstname . ...( Classifier_Name: middle "PERSON_BY_FIRSTNAME" ) !P ( "PERSON_BY_LASTNAME" | "PART_OF_SURNAME_PREFIX" ) <% Person, surname ~= null, firstname == null %> ] => // , , middle, // middlename_cs. Pomiddlename_cs == middle, ... In the examples above, we relied either on a name we know (part of the name) or on an explicit name pointer (noble prefix). However, it is clear that all persons (as well as all organizations) cannot be included in our hierarchy. Often, company names and people's names are recognized as unknown words.
In this case, ABBYY Compreno allows us to rely on numerous indirect signs. For example, if an unknown word (and even with a capital letter) turns out to be “registered in California,” conducts an IPO, or, for example, “gets married” or “has a cold”, everything becomes clear to us. Using the ABBYY Compreno trees, indicating the necessary semantic classes, deep positions and other signs, we can minimize erroneous extracts and catch such nontrivial organizations and persons.
In addition, thanks to the object conditions, we can improve the extraction of some entities based on others. For example, a person with an unknown surname “Pyschysch” stood out in our text for some signs. And below the phrase Pyschspish sells assets. At the same time, the engineer who creates the rules for extracting organizations knows that the assets of the organization are most often sold, and would like to extract them in such cases. Then he can put in his condition a negative object condition ~ <% Person%> (= there is no Person object on the node) - and in this particular case the rule will not work, because there will already be a person on the Pimple.
Now about how we extract events and facts, and all these people and organizations become their participants. For example, let's experiment with the extraction of the fact of buying or selling something. Create a new rule with a single product and write the following condition:
"TO_ACQUIRE" => PurchaseAndSale P (this), // PurchaseAndSale annotation (P, this.core); // Here we ask to find in the tree a node with the semantic class TO_ACQUIRE or its descendant. This is the semantic class in the hierarchy for Russian and English:
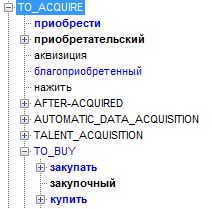
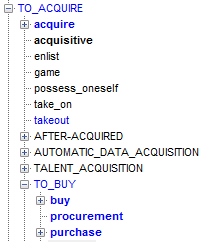
Products will be triggered in all cases when someone buys something, and it doesn’t even matter whether the participants are in the text.
Now create a new rule:
<%PurchaseAndSale%> [Possessor: !customer] => CustomerRole CR (customer), // PurchaseAndSale annotation (CR, customer.core), // this.o.customer == CR; // customer () PurchaseAndSale This rule searches under the node with the fact that PurchaseAndSale has already been retrieved a child node in the Possessor deep position (possessor). For example, Vasya gets into the position of Possessor in statements like Vasya bought, Vasya purchased, etc.
In the right part, we create a special role object CustomerRole, which we then place in relation to the customer (buyer) of the found fact. If on the same node some full-fledged entity is extracted (for example, the person “Vasya”), then the special rule will replace the role object with this entity. In the end, we will have the fact of PurchaseAndSale, in which Vasya’s person is in relation to the customer.
Similarly arranged rules for the extraction of the buyer, product and price. The only difference is that the product in this case falls into the deep Object position (the object undergoing action), the price goes to the special position Ch_Parameter_Price (price parameter), the buyer goes to the Source position (source role):
<%PurchaseAndSale%> [Object: !sold_property] => … <%PurchaseAndSale%> [Ch_Parameter_Price: !price] => … <%PurchaseAndSale%> [Source: !seller] => … These rules will work for examples like " Vasya bought a toy from Masha ", " Petya bought a car ", " Nikolai goes to buy a pink elephant ", " Auto.ru was bought by Yandex for $ 175 million ", " Pavel Durov acquired the telegram.me domain " etc. First, the fact of PurchaseAndSale will be extracted, and then the correct participants will be allocated to it: the buyer Vasya, the seller Masha and the object of sale and purchase “toys”, etc. for all examples. At the same time, neither the word order (“I bought a toy Vasya ,” “I bought a toy Vasya ,” “I bought a toy Vasya ”), neither specific names, nor the verb tense is important to us. Moreover, since all elements of the trees on which we relied (deep positions and semantic classes) are universal in our system, that is, common to all supported languages, the rule will work not only for Russian, but also for English. There are much more synonyms for an action that means a purchase (to put it in our terms, the semantic class “TO_ACQUIRE” has many more lexical classes). Therefore, these simple products will find the fact of sale and correctly extract the participants in all the examples below:
Lenovo buys Motorola from Google.
Lenovo purchased Motorola.
Lenovo has just acquired Motorola.
Motorola has been acquired by Lenovo.
Lenovo's purchase of Motorola.
Lenovo's acquisition of Motorola.
Motorola's acquisition by Lenovo.
This will work precisely because in all cases there is a subtree in the analysis in which there is a vertex with the semantic class “TO_ACQUIRE” (or its descendant) and its children in the deep positions Possessor (Lenovo), Object (Motorola), Source (Google in the first example ).
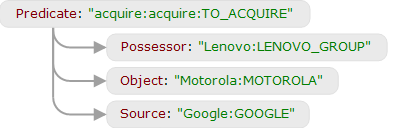
In addition to the extraction rules, there is another type of rules - local identification rules. They allow you to collect all references to the same entity or fact within the same text. For example, in one part of the text the name of the person is found, and in the other - the pronoun “he” (how ABBYY Compreno copes with the pronominal anaphor can be read here , and even more - here ). Or the same person is mentioned several times (once - by full name, and then - only by last name). Identification rules work within the same text and do not apply to trees, but operate only on objects, their attributes and the distance between them. For example, we can write a rule that connects two facts of purchase and sale into one if they have a buyer and a seller, and they are close to each other. They work in this (completely real) example:
Google is selling Motorola to Lenovo , giving it a share in the US market. Lenovo will buy Motorola for $ 2.91 billion in a mixture of cash and stock. (The Verge)
That is, here the system truly understands that the two sentences are about the same fact. As a result, all information about the transaction (price, buyer, seller, product), scattered across two separate statements, is combined in ONE information object.
It is clear that the problem of identification arises on a more general level - when analyzing text collections. Often the same information objects are transferred from text to text. To do this, separate global identification mechanisms are implemented, based on special patterns and machine learning methods, but for a meaningful story about them, you will need a separate large article.
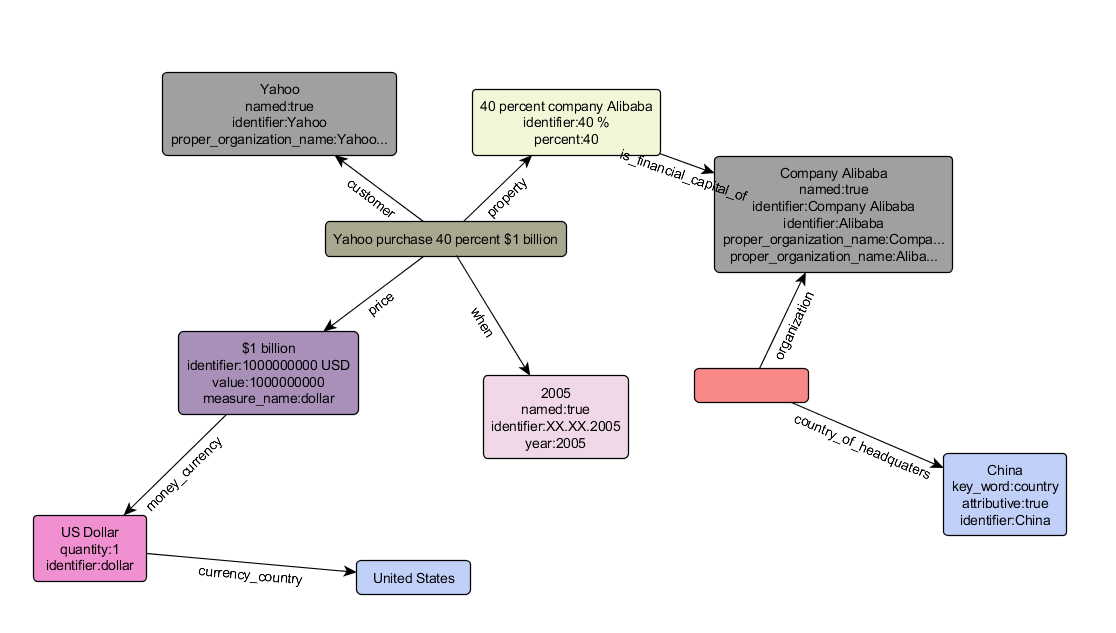
After all the rules are triggered, the extracted facts and entities are written into an XML document, in accordance with the RDF data description format. This document defines an RDF graph, in which the connections of objects and their association with text fragments are visible (= their annotations). The resulting information graph is the end result of the extraction system. Then you can use it as you like - fill the information in the database, visualize, etc. So, for example, visualization of the graph of facts and entities extracted from the offer from TechCranch looks like: In 2005, Yahoo purchased Alibaba for $ 1 billion
Why is all this necessary?
The system described above is essentially a factory for creating various ontologies and corresponding models for extracting facts and entities. What exactly will be “produced” in this factory depends already on the diverse needs of specific customers. And I must say that in many cases, the “semantic depth” of the analysis and the ability to remove ambiguity turn out to be simply irreplaceable for us - for example, the ABBYY Compreno parser is able to distinguish the grass that is on the lawn (the semantic class “GRASS”) from the one you thought (semantic class “MARIJUANA”) ...
In the course of the work, not only technical difficulties arise, but also problems of a philosophical and ideological nature. Therefore, in the engineering department it is often possible to hear disputes about whether Santa Claus and Batman are personas, whether the essence of the “drug” must be extracted on “heroin addicts”, whether murder is always a crime and what fact to isolate if dogs have been bitten off by someone. In the course of these discussions, you can hear a lot of funny phrases, and in my free time I even started collecting a collection called “So they say ontonenergy.” Here is a little bit from there:
- And you can ask how I should separate the corpse from the bones?
- She needs a concept in which not immediately full depravity!
- And the gods stand out as people? - These are not people, but these are personalities!
- Please kill this person!
- The engineer_1: This came to us like his ...
Ontoinzhener_2: (obscene word, meaning the end of everything)?
Onto engineer_1: No, advance! - Who broke the Bank account?
In addition to purely commercial ventures, there are those that are not about profit, but about eternal values. Many have probably heard about the project ABBYY and the Museum of Tolstoy " All Tolstoy in one click ", which Guardian and New Yorker wrote about as an impressive crowdsourcing breakthrough. The objectives of this project - digitization and reading (by indifferent volunteers) 90 volumes of the complete works of the writer - were achieved ahead of all plans, and now a new task has appeared - Tolstoy's semantic edition . This project aims to set the standards for publishing a classic heritage in the digital age — with semantic markup, extraction and identification of fictional and real entities, links to publicly available knowledge bases like dbpedia or freebase. We hope that the use of an information extraction system based on ABBYY Compreno will help reduce the amount of manual labor in this project as significantly as the use of ABBYY FineReader when digitizing a 90-volume book.
In parallel with the work to order, we are creating on the basis of our technologies a more universal product of “common use” - InfoExtractor. It extracts all traditional entities (persons, organizations, locations) and facts (buying and selling, employment, education, family ties, and much more) appearing in news and journalistic texts. Now InfoExtractor exists in the form of search and analytical SDK IntelligentTagger , in the future we plan to release several new "smart" products with an eye to extracting information.
Source: https://habr.com/ru/post/246039/
All Articles