Onto engineer: work on concepts
 Hi, Habr! My name is Danya, and I work in a knowledge extraction group. Guess WhatCompanies. In two posts I will tell
Hi, Habr! My name is Danya, and I work in a knowledge extraction group. Guess WhatCompanies. In two posts I will tell- how we extract facts and entities from texts
- who are the engineers,
- why are they separating corpses from bones,
- and here is Leo Tolstoy.
On Habré, there have already been several publications devoted to extracting information from unstructured text (many of which are searched for by the tags Text Mining , Information Extraction ). Here, for example, is a brief gentlemen's set of what is desirable to do with the text before it is convenient to extract something from it (spoiler: we do all this too). And here, colleagues from Yandex describe their approach using KS grammars (by the way, Tolstoy was also involved there). In general, the topic for Habr is not new, but one cannot say that it is sufficiently disclosed. That's why we decided to share our experience.
We at ABBYY love to approach problems fundamentally and come up with universal, long-term, scalable solutions. And here, when the task arose to extract information from the text, we did not sculpt anything on the knee of scripts and regexps, but used heavy linguistic artillery - ABBYY Compreno technology .
Farther into the forest: bad programmers and good traditions
The ABBYY Compreno parser turns the text into a forest of trees that combine the properties of dependency grammar ( dependency grammar , it is used by Stanford parser familiar to many) and component grammar (constituency grammar). I will not go into details and go into the wilds of the theory of syntax - here it is enough to understand that the nodes in the trees correspond approximately to the words of the sentence, and the arcs reflect the dependencies between them. In this case, the nodes are equipped with a huge amount of related linguistic information. This is how the tree looks for a phrase. The programmer has written bad code .

')
Now compare it with the tree for the phrase. The programmer entered the wrong code.

Green text caps are semantic classes that are selected for each word in our universal semantic hierarchy. The semantic hierarchy is a huge tree of concepts, organized according to the principle of inheritance of linguistic information and covering all parts of speech; besides, it contains our syntactic model. The semantic classes in the hierarchy are traditionally called in English and correspond to one particular word meaning, to some not related to a specific language concept. Thus, at the moment of choosing the semantic class, the lexical ambiguity is resolved. An example of such a choice is visible on the word code, for which in the first sentence the code “CODE_OF_PROGRAM” was chosen (the code as part of a computer program), and in the second - the code “CODE” (code as a cipher, password). The solution of the system in such cases is influenced by both the statistics and the limitations of the linguistic structure specified within our semantic hierarchy.

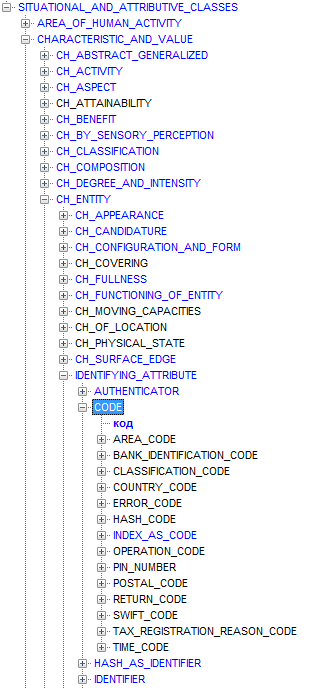
This is how the fragments of the hierarchy in which the mentioned classes are located
And here is another example of the resolution of ambiguity - the programmer introduced the tradition of coding without bugs . Here, as we see, a completely different semantic class has been chosen for the word form introduced , since the word is used in a completely different meaning.

Blue in the trees shows the position of the nodes in the surface syntax - this is the formal structure of the sentence, which has no direct relation to its meaning. It is very close to the school model with subject, predicate, addition, etc. The deep positions are shown in red - they already show what role the element plays in the situation being described. Therefore, if we translate the first example about a programmer into a passive — the bad code is written by the programmer — the surface Subject will change in the tree (because the subject there is no longer a programmer , but the code ), but not the deep Agent (because in reality, which the the phrase, the action is still performed by the programmer):

In addition to the semantic-syntactic trees, the ABBYY Compreno parser returns information about non-wood connections between their nodes. For example, for the phrase Vasya was sitting at the computer and the kodil for the verb “cod” would be restored to a null subject that would be associated with a non-wood link with the node “Vasya”:

The same will happen in the sentence Vasya left to write the code - from the point of view of the grammatical structure Vasya actively performs only the action indicated by the verb “left”, but we know who writes the code:

Vasya will not succeed in concealing his dark deeds, hiding behind a pronoun. In examples like " Vasya left. ", " He went to code " or " Vasya likes his code " Compreno will restore the anaphoric connection and replace the pronouns (" He ", " him ") with Vasya:



world creation
You can read more about how the ABBYY Compreno parser works here . I will go directly to the topic of the post and begin to tell how the extraction of facts and entities based on this linguistic platform is organized. It is here that the onto-engineers, specialists in the creation of formal models of the world ( ontologies ) and the extraction of information corresponding to these models, come into play. The task of the engineer is to first come up with a formal representation of some information objects that need to be extracted, and then develop a system of rules according to which they will be extracted from the forest of Compreno-trees.
The first stage of the work - the development of an ontological model - can be compared with the creation of classes in the PLO. For example, if an onto-engineer is tasked with extracting from person text, it is necessary to create an appropriate concept (this word is used in ontological modeling as an equivalent of a class), embed it in an ontology, i.e. set inheritance with other concepts, and create the necessary attributes - first name, last name, etc. To do this, we use the OWL language , the ontology description standard supported by the W3C consortium. A person in our ontology will look like this:
<owl:Class rdf:about="http://www.abbyy.com/ns/BasicEntity#Person"> <rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#HumanLikeSubject"/> <rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#BasicEntity"/> <rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#IdentifiableThing"/> <rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#EntityLikeSubject"/> <Aux:LeadingParent rdf:resource="http://www.abbyy.com/ns/Basic#BasicEntity"/> <rdfs:label xml:lang="En">Person</rdfs:label> <rdfs:label xml:lang="Ru"></rdfs:label> <rdfs:comment xml:lang="En">For example: Mikhail Yuryevich Lermontov was born on October 15, 1814 in Moscow.</rdfs:comment> <rdfs:comment xml:lang="Ru">: 15 1814 .</rdfs:comment> </owl:Class> And so - her attribute "Last Name":
<owl:DataProperty rdf:about="http://www.abbyy.com/ns/BasicEntity#surname"> <rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#string"/> <rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicEntity#Person"/> <rdfs:label xml:lang="En">Surname</rdfs:label> <rdfs:label xml:lang="Ru"></rdfs:label> <rdfs:comment xml:lang="En">Mikhail Yuryevich Lermontov: Surname - Lermontov</rdfs:comment> <rdfs:comment xml:lang="Ru"> : - </rdfs:comment> </owl:DataProperty> The concept for which the attribute is specified is called the domain of this attribute. In this case, the scope is objects that belong to the Person concept. The type of data that can fill an attribute is specified in the range. In this case, it is a string.
For the convenience of the work of engineering engineers, a special graphical ontology development environment has been created:

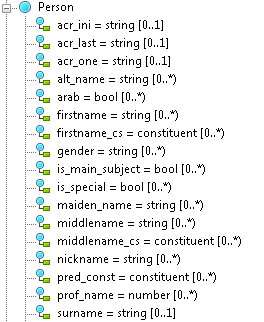
Circles represent concepts; circles connected by lines - attributes / relations of concepts,
Depending on the concept, the placeholders of its attributes can be either simple data types (string, number, boolean value), or objects related to other concepts. This is especially true for facts in which participants are entities extracted by other rules. Almost all the facts with several possible participants are not modeled as relationships recorded inside entities, but as separate information objects similar to entities (by the way, this is also a recommendation of the W3C). This is what our purchase and sale fact (Purchase And Sale) looks like in the OWL records:
<owl:Class rdf:about="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale"> <rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/BasicFact#OperationWithProperty"/> <rdfs:label xml:lang="En">Purchase And Sale</rdfs:label> <rdfs:label xml:lang="Ru">-</rdfs:label> </owl:Class> And so - his relationship:
<owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#seller"> <rdfs:range rdf:resource="http://www.abbyy.com/ns/Basic#Subject"/> <rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale"/> <rdfs:label xml:lang="En">Seller</rdfs:label> <rdfs:label xml:lang="Ru"></rdfs:label> </owl:ObjectProperty> <owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#customer"> <rdfs:range rdf:resource="http://www.abbyy.com/ns/Basic#Subject"/> <rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale"/> <rdfs:label xml:lang="En">Customer</rdfs:label> <rdfs:label xml:lang="Ru"></rdfs:label> </owl:ObjectProperty> <owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#price"> <rdfs:range rdf:resource="http://www.abbyy.com/ns/BasicEntity#Money"/> <rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale"/> <rdfs:label xml:lang="En">Price</rdfs:label> <rdfs:label xml:lang="Ru"></rdfs:label> </owl:ObjectProperty> <owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#property"> <rdfs:range rdf:resource="http://www.abbyy.com/ns/Basic#ExtendedProfit"/> <rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#OperationWithProperty"/> <rdfs:label xml:lang="En">Property</rdfs:label> <rdfs:label xml:lang="Ru"></rdfs:label> </owl:ObjectProperty> As can be seen from the range of values, all these relationships are filled not with simple data types, but with references to objects of other concepts. For example, the price relation can be filled only with “monetary” entities, i.e. objects of the concept BasicEntity # Money or its descendants.
How it works and how some objects fall into relationship with others, read the next article.
Source: https://habr.com/ru/post/245509/
All Articles