.NET / Mono in Java? Easy!
Hello. I want to introduce my project - the .NET / Mono compiler in Java. The goal of the project is to create a compiler, and a set of standard libraries allowing to transfer written applications and libraries to the Java platform, version 1.6 and higher. From similar projects I know only the dot42 project. But it is sharpened for Android and has its own standard library not quite compatible with .NET / Mono.
So far there is only an alpha version, and therefore the compiler is not yet suitable for real use, but it is already partially functional, generates valid Java code and supports part of the ECMA-335 standard.
Source code on github.com: https://github.com/zebraxxl/CIL2Java
')
The compiler is a console application that, when run without parameters, displays help. So with the use of problems should not arise.
I also want to note that when working, the compiler proceeds from the assumption that all code submitted to it at the input is valid.
Just want to stipulate that at the moment is not supported:
The last three points are planned to be implemented in the near future, at the expense of the others - these are long-term plans, if at all, they really will be implemented.
The compilation is divided into three major stages. At the first stage, the compiler loads and converts all the types used to the internal representation. The second is preparing for the third stage. The third step converts the meta-information and compiles the code.
Type conversion to internal representation occurs on the fly at the time of loading. That is, a type is taken, converted to an internal representation, then added to the compilation list. Then, all fields and methods are taken from the original type and are also converted into an internal representation. Thus, all types are added to the compilation list, their fields and methods from those explicitly specified as input assemblies.
But also, during the conversion of any type, field or method (hereinafter referred to as a member), it is also loaded, converted into an internal representation and added to the compilation list, all members on which the original member depends. Only the really used members are added. Thus, after the first stage in the compilation list there will be only those types that are in the original assemblies, plus those types and their members that are necessary. Thanks to this, we get compiled source assemblies and the necessary pieces of the rest. For example, take the code:
After the first stage, the compilation list will look like this:
Here it is also necessary to note the mechanism for replacing assemblies. When a link to a type that is in an external assembly (not specified as an input) is detected, this assembly will be automatically loaded. However, what if the loadable assembly has an implementation incompatible with Java? For example, the standard mscorlib? For this, you need a mechanism for replacing assemblies. By default, at the moment, mscorlib is replaced by a special implementation that uses Java mechanisms to work. You can also specify other assemblies, for substitution using the –r compilation key. Briefly, it works as follows: when Mono.Cecil begins to look for where to load the assembly, he addresses this issue to the AssemblyResolver, which was passed to him as a parameter when reading the original assembly. The AssemblyResolver compiler first looks for an assembly with that name in the previously loaded ones, if it does not find it, then it looks to see whether it is in the lists for substitution. If it is, it loads and returns the assembly specified in the list for substitution. If it is not in the lists for substitution, then the standard assembly is loaded by standard means.
Before the second compilation stage, a precompilation stage takes place, in which the compiler performs additional type processing to prepare them for direct compilation. For example, it is at this stage that methods are added that are not explicitly invoked anywhere, but are overloaded with virtual methods of explicitly used methods.
And actually the third stage is the most basic. The transformation of meta-information process is fairly simple and straightforward. The only thing I would like to note is that all types are declared as a result of public access due to incompatibility of the levels of visibility of Java and CIL. Global types in Java can have either public access or access only from a package (namespace). And nested types in Java, having for example a closed level of visibility, cannot be used at all outside of the type in which they are declared. If any member of this type is addressed from an external class, an exception will be generated. So all types automatically become open.
But the compilation of code is a more complex and voluminous process, which is also divided into several stages. The first step is to build a code graph. This is the work of the ICSarpCode.Decompiler library from ILSpy. In general, we get an almost ready to compile graph, but still some additional transformations are performed. For example, the pseudo CompoundAssignment instructions that ICSharpCode.Decompiler generates are converted backwards. Well, after that, the compilation into Java bytecode actually takes place.
This is how the compiler itself works. Now I will talk in more detail about some aspects of the work and how the support of certain things is realized.
From the point of view of JVM, generics do not exist. Generics in Java is only an extension of the compiler and generic from the point of view of the JVM - this is a common object of type java.lang.Object. CLI generics are compiled at runtime. This means that when the compiler encounters a generic, it substitutes a real type instead of it and, in fact, creates a new type or method based on the original one. CIL2Java acts in the same way, passing methods and types that have jerk parameters and creates them only when it encounters a link indicating which types to replace these parameters with.
This is probably one of the main reasons why .NET / Mono is better than Java in disputes, which is better. Yes, there is no support for such types in Java. Therefore, all significant types are compiled as index. But so that there would be no problems due to the difference in the behavior of the significant and indicative types, the behavior of the significant types is emulated. First, a constructor without parameters is generated, and three internal methods are added:
Using these three methods, the behavior of significant types is fully emulated. For example, the code “Foo (valType);” will be converted to “Foo (valType.c2j __ $ __ GetCopy ());” and a copy of valType will be passed to the Foo method.
Also, for proper operation, all significant types are automatically initialized by the default constructor in constructors and at the very beginning of the methods (prologue).
Thus, the main advantage of these types is that if used correctly, they increase the speed of the application, not only is lost, but on the contrary, their use will slow down the operation of the application.
In .NET / Mono, enumerations are inherently significant types, but with additional restrictions. They cannot have any methods, just one non-static field of a primitive type (int, short, etc.) having the name "value __" and static fields having the type of the enumeration itself.
When compiling instead of an enumeration type, its base type is substituted. That is, the method "void Foo (EnumType val);" after compilation will become "void Foo (int val);".
The packaging of significant types is divided into three categories: packaging of primitive types, packaging of significant types and packaging of listings.
The packaging of primitive types is implemented in two ways: packaging in CIL types or packaging in Java types. In the first case, the standard for CIL types from the System namespace (System.Int32, System.Single, etc.) are used as types for packaging. In the second, the standard types for Java (java.lang.Integer, java.lang.Float, etc.)
In the case of packing into CIL types, we save information about unsigned types and the code like "uintType.ToString ()" will have the correct result. However, when passing such parameters to Java, to methods where you need to pass a packaged primitive type (for example, java.lang.reflect.Method.invoke), the compiler will need to generate repackaging code (though there is no this function in the compiler), and thus performance drop.
In the case of packing into Java types, all is accordingly vice versa. The “uintType.ToString ()” code will give an incorrect result if the uintType value is greater than 2,147,483,647, but there will be no extra repacking from CIL to Java and back. What method to use is up to you. The compilation parameter box is responsible for this. By default, packaging is done in CIL types.
With packing of significant types everything is simpler. We take a copy of the type and just pass it. It is after the fact, after compilation, becomes a pointer type.
But transfers are packaged in their real type. That is, if there is an enum of the EnumType type, which has the basic int type, then, as mentioned above, when compiling, the int type will be substituted for EnumType. But in the case of packaging, an object of the EnumType type will be created, and the value__ of this enumeration will be put in its value__ field. Thus, type information will be saved.
As already mentioned, the compiler does not support unsafe pointers. But the transfer of the link works quite well. If a value is passed to the method by reference, then the type of this parameter will be CIL2Java.VES.ByRef [type], where [type] is the type to which the link is being created (possible values: Byte, Short, Int, Long, Float, Double, Bool, Char, Ref). Separate types for primitive types are necessary in order not to pack / unpack them with each call. The type of the link itself is an abstract class with two abstract methods: get_Value and set_Value for getting and setting the value by reference, respectively. This is how it looks like:
When creating a reference to a value, an object is created that implements the corresponding abstract class. And it implements depending on where the value is stored to which we create the link:
LocalByRef [type] - a link to a local variable or method parameter. It simply stores the value until it leaves the called place, after which the value of the variable or parameter is restored.
Take this code:
After compilation, the code will look like this:
FieldByRef [type] - reference to the field of the object. It is realized by the forces of reflection. This is what this type looks like after compilation:
ArrayByRef [type] - a link to an array element. Everything is simple - we save the array itself (which is a pointer type) and the index in this array. This is how it looks after compilation:
This is what I miss most in Java. One way to implement pointers to methods is reflection. But I did not like this option because it requires the packaging of parameters, which reduces performance. Thus the second method was used.
In the following description, I will use this example:
The method is that if we meet the ldftn or ldvirtftn instruction, then the interface is first generated in the CIL2Java.VES.MethodPointers namespace with a name depending on the method signature and with a single invoke method that has almost the same signature as the method we we receive the pointer, having added the first parameter the link to object in which it is necessary to call a method. In our example, this interface will look like this:
Then, each ldftn or ldvirtftn instruction generates a nested type that implements the pointer interface to the method. The invoke method simply calls the method to which the instruction receives the pointer. In the example above, it looks like this:
And already in the delegate constructor, as a pointer to a method, an instance of this class is passed.
The delegate itself after compilation takes the following form:
This is the default behavior of the compiler. As you can see, the delegate constructor signature has been changed - the last parameter has the interface type of the method pointer, not the native int as necessary by the standard. This is done again for optimization. However, you can tell the compiler that it is necessary to compile the pointers to the method according to the standard using the "-method_pointers standart" parameter. In this case, the creation of the delegate in our example takes the form:
And the delegate himself becomes like this:
As you can see, in this case, the pointer to the method is of type int, but in reality, this is just an index in the global list of pointers to methods. In this way, we comply with the standard, but lose in performance.
Here, to be honest there is nothing to tell. It just works.
Here, too, especially nothing to tell. Code using async / await compiles, but does not work. It does not work because there is no implementation of the types required for operation (System.Threading.Tasks.Task, System.Runtime.CompilerServices.AsyncTaskMethodBuilder and so on)
Support for unsigned numbers in the compiler is available, but is included separately with the "-unsigned" parameter. The article http://habrahabr.ru/post/225901/ for the authorship of elw00d really helped with the implementation . In general, in this article, everything is described and all operations with unsigned numbers were made for this article.
In general, exceptions in Java and in CIL are very similar. So far, exception filters are not supported (ICSharpCode.Decompiler does not support them).
Additionally, a mechanism for tying Java and CIL exception types has been added. For example, in CIL there is an exception System.ArithmeticException. Java has its own java.lang.ArithmeticException type. How to make so that intercepting System. ArithmeticException intercepted as well java.lang. ArithmeticException? For this, a JavaExceptionMapAttribute attribute was introduced which indicates to the compiler a similar exception in Java. And when the compiler encounters a System.ArithmeticException intercept, it also adds interception and similar Java exceptions. The only condition that is added is that an additional constructor must be entered into System.ArithmeticException, which takes only one parameter of type java.lang.ArithmeticException so that an instance of the exception of one type is passed to the interceptor.
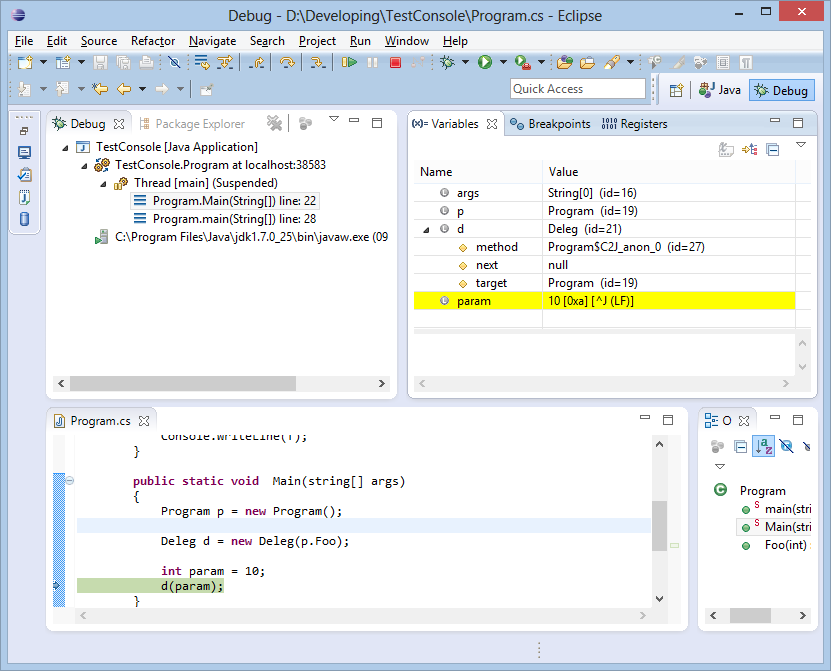
The compiler supports the generation of debugging information (if it is in the original builds) by specifying the compile key "-debug". Here is an example of how a test application is debugged in Eclipse:
This mechanism was created so that the types that are similar in Java could be turned into these analogs when compiled. An example of this type is System.String. In the mscorlib implementation, this type is marked with the TypeMapAttribute attribute, and when compiled it becomes java.lang.String. The substitution of individual methods is also possible. To do this, they must be marked with the attribute MethodMapAttribute.
Here in general, that's all. This is only the alpha version of the project, and so far the stability of work leaves much to be desired. So the further vector of work is the improvement of work stability and the implementation of the standard library. Thank you for reading to the end.
So far there is only an alpha version, and therefore the compiler is not yet suitable for real use, but it is already partially functional, generates valid Java code and supports part of the ECMA-335 standard.
Source code on github.com: https://github.com/zebraxxl/CIL2Java
')
The compiler is a console application that, when run without parameters, displays help. So with the use of problems should not arise.
I also want to note that when working, the compiler proceeds from the assumption that all code submitted to it at the input is valid.
What is not supported
Just want to stipulate that at the moment is not supported:
- Unmanaged pointers
- Math over pointers (both managed and unmanaged)
- P / Invoke
- Non-vector arrays (arrays with lower bound not equal to 0)
- The switch statement on the long type
- Opcode calli
- Exception filters
The last three points are planned to be implemented in the near future, at the expense of the others - these are long-term plans, if at all, they really will be implemented.
How it works
The compilation is divided into three major stages. At the first stage, the compiler loads and converts all the types used to the internal representation. The second is preparing for the third stage. The third step converts the meta-information and compiles the code.
Type conversion to internal representation occurs on the fly at the time of loading. That is, a type is taken, converted to an internal representation, then added to the compilation list. Then, all fields and methods are taken from the original type and are also converted into an internal representation. Thus, all types are added to the compilation list, their fields and methods from those explicitly specified as input assemblies.
But also, during the conversion of any type, field or method (hereinafter referred to as a member), it is also loaded, converted into an internal representation and added to the compilation list, all members on which the original member depends. Only the really used members are added. Thus, after the first stage in the compilation list there will be only those types that are in the original assemblies, plus those types and their members that are necessary. Thanks to this, we get compiled source assemblies and the necessary pieces of the rest. For example, take the code:
using System; namespace TestConsole { public class Program { public static void Main(string[] args) { Console.WriteLine("Hello world"); } // Java public static void main(string[] args) { Main(args); } } } After the first stage, the compilation list will look like this:
0: type Foo.Program
methods:
Main
main
1: type System.Console
methods:
WriteLine
2: type System.String
Here it is also necessary to note the mechanism for replacing assemblies. When a link to a type that is in an external assembly (not specified as an input) is detected, this assembly will be automatically loaded. However, what if the loadable assembly has an implementation incompatible with Java? For example, the standard mscorlib? For this, you need a mechanism for replacing assemblies. By default, at the moment, mscorlib is replaced by a special implementation that uses Java mechanisms to work. You can also specify other assemblies, for substitution using the –r compilation key. Briefly, it works as follows: when Mono.Cecil begins to look for where to load the assembly, he addresses this issue to the AssemblyResolver, which was passed to him as a parameter when reading the original assembly. The AssemblyResolver compiler first looks for an assembly with that name in the previously loaded ones, if it does not find it, then it looks to see whether it is in the lists for substitution. If it is, it loads and returns the assembly specified in the list for substitution. If it is not in the lists for substitution, then the standard assembly is loaded by standard means.
Before the second compilation stage, a precompilation stage takes place, in which the compiler performs additional type processing to prepare them for direct compilation. For example, it is at this stage that methods are added that are not explicitly invoked anywhere, but are overloaded with virtual methods of explicitly used methods.
And actually the third stage is the most basic. The transformation of meta-information process is fairly simple and straightforward. The only thing I would like to note is that all types are declared as a result of public access due to incompatibility of the levels of visibility of Java and CIL. Global types in Java can have either public access or access only from a package (namespace). And nested types in Java, having for example a closed level of visibility, cannot be used at all outside of the type in which they are declared. If any member of this type is addressed from an external class, an exception will be generated. So all types automatically become open.
But the compilation of code is a more complex and voluminous process, which is also divided into several stages. The first step is to build a code graph. This is the work of the ICSarpCode.Decompiler library from ILSpy. In general, we get an almost ready to compile graph, but still some additional transformations are performed. For example, the pseudo CompoundAssignment instructions that ICSharpCode.Decompiler generates are converted backwards. Well, after that, the compilation into Java bytecode actually takes place.
This is how the compiler itself works. Now I will talk in more detail about some aspects of the work and how the support of certain things is realized.
Generics
From the point of view of JVM, generics do not exist. Generics in Java is only an extension of the compiler and generic from the point of view of the JVM - this is a common object of type java.lang.Object. CLI generics are compiled at runtime. This means that when the compiler encounters a generic, it substitutes a real type instead of it and, in fact, creates a new type or method based on the original one. CIL2Java acts in the same way, passing methods and types that have jerk parameters and creates them only when it encounters a link indicating which types to replace these parameters with.
Significant types
This is probably one of the main reasons why .NET / Mono is better than Java in disputes, which is better. Yes, there is no support for such types in Java. Therefore, all significant types are compiled as index. But so that there would be no problems due to the difference in the behavior of the significant and indicative types, the behavior of the significant types is emulated. First, a constructor without parameters is generated, and three internal methods are added:
- c2j __ $ __ ZeroFill () - fills the contents of the type with zeros
- c2j __ $ __ CopyTo (ValueType) - copies the contents of the source type to the specified
- c2j __ $ __ GetCopy () - creates a new instance of the type, and copies into it the data from the source
Using these three methods, the behavior of significant types is fully emulated. For example, the code “Foo (valType);” will be converted to “Foo (valType.c2j __ $ __ GetCopy ());” and a copy of valType will be passed to the Foo method.
Also, for proper operation, all significant types are automatically initialized by the default constructor in constructors and at the very beginning of the methods (prologue).
Thus, the main advantage of these types is that if used correctly, they increase the speed of the application, not only is lost, but on the contrary, their use will slow down the operation of the application.
Transfers
In .NET / Mono, enumerations are inherently significant types, but with additional restrictions. They cannot have any methods, just one non-static field of a primitive type (int, short, etc.) having the name "value __" and static fields having the type of the enumeration itself.
When compiling instead of an enumeration type, its base type is substituted. That is, the method "void Foo (EnumType val);" after compilation will become "void Foo (int val);".
Packaging
The packaging of significant types is divided into three categories: packaging of primitive types, packaging of significant types and packaging of listings.
The packaging of primitive types is implemented in two ways: packaging in CIL types or packaging in Java types. In the first case, the standard for CIL types from the System namespace (System.Int32, System.Single, etc.) are used as types for packaging. In the second, the standard types for Java (java.lang.Integer, java.lang.Float, etc.)
In the case of packing into CIL types, we save information about unsigned types and the code like "uintType.ToString ()" will have the correct result. However, when passing such parameters to Java, to methods where you need to pass a packaged primitive type (for example, java.lang.reflect.Method.invoke), the compiler will need to generate repackaging code (though there is no this function in the compiler), and thus performance drop.
In the case of packing into Java types, all is accordingly vice versa. The “uintType.ToString ()” code will give an incorrect result if the uintType value is greater than 2,147,483,647, but there will be no extra repacking from CIL to Java and back. What method to use is up to you. The compilation parameter box is responsible for this. By default, packaging is done in CIL types.
With packing of significant types everything is simpler. We take a copy of the type and just pass it. It is after the fact, after compilation, becomes a pointer type.
But transfers are packaged in their real type. That is, if there is an enum of the EnumType type, which has the basic int type, then, as mentioned above, when compiling, the int type will be substituted for EnumType. But in the case of packaging, an object of the EnumType type will be created, and the value__ of this enumeration will be put in its value__ field. Thus, type information will be saved.
Pointers
As already mentioned, the compiler does not support unsafe pointers. But the transfer of the link works quite well. If a value is passed to the method by reference, then the type of this parameter will be CIL2Java.VES.ByRef [type], where [type] is the type to which the link is being created (possible values: Byte, Short, Int, Long, Float, Double, Bool, Char, Ref). Separate types for primitive types are necessary in order not to pack / unpack them with each call. The type of the link itself is an abstract class with two abstract methods: get_Value and set_Value for getting and setting the value by reference, respectively. This is how it looks like:
public abstract class ByRef[type] { public abstract [type] get_Value(); public abstract void set_Value([type] newValue); } When creating a reference to a value, an object is created that implements the corresponding abstract class. And it implements depending on where the value is stored to which we create the link:
LocalByRef [type] - a link to a local variable or method parameter. It simply stores the value until it leaves the called place, after which the value of the variable or parameter is restored.
Take this code:
public class Program { public static void Foo(ref int refValue) { refValue = 10; } public static void Main(string[] args) { int localVar = 0; Foo(ref localVar); } // Java public static void main(string[] args) { Main(args); } } After compilation, the code will look like this:
public class LocalByRefInt : ByRefInt { private int value; public LocalByRefInt(int initialValue) { value = initialValue; } public override int get_Value() { return value; } public override void set_Value(int newValue) { value = newValue; } } public class Program { public static void Foo(ByRefInt refValue) { refValue.set_Value(10); } public static void Main(string[] args) { int localVar = 0; LocalByRefInt tmpByRef = new LocalByRefInt(localVar); Foo(tmpByRef); localVar = tmpByRef.get_Value(); } // Java public static void main(string[] args) { Main(args); } } FieldByRef [type] - reference to the field of the object. It is realized by the forces of reflection. This is what this type looks like after compilation:
public class FieldByRef[type] : ByRef[type] { private object target; private java.lang.reflect.Field field; private [type] value; public FieldByRefInt(object target, Field targetField) { this.target = target; this.field = targetField; paramField.setAccessible(true); this.value = targetField.get[type](target); } public [type] get_Value() { return this.value; } public void set_Value([type] newValue) { this.field.set[type](this.target, newValue); this.value = newValue; } } ArrayByRef [type] - a link to an array element. Everything is simple - we save the array itself (which is a pointer type) and the index in this array. This is how it looks after compilation:
public class ArrayByRef[type] : ByRef[type] { private [type][] array; private int index; private int value; public ArrayByRefInt([type][] paramArray, int index) { this.array = paramArray; this.index = index; this.value = paramArray[index]; } public int get_Value() { return this.value; } public void set_Value(int newValue) { this.array[this.index] = newValue; this.value = newValue; } } Pointers to methods and delegates
This is what I miss most in Java. One way to implement pointers to methods is reflection. But I did not like this option because it requires the packaging of parameters, which reduces performance. Thus the second method was used.
In the following description, I will use this example:
using System; namespace TestConsole { public delegate void Deleg(int f); public class Program { public void Foo(int f) { Console.WriteLine(f); } public static void Main(string[] args) { Program p = new Program(); Deleg d = new Deleg(p.Foo); d(10); } // Java public static void main(string[] args) { Main(args); } } } The method is that if we meet the ldftn or ldvirtftn instruction, then the interface is first generated in the CIL2Java.VES.MethodPointers namespace with a name depending on the method signature and with a single invoke method that has almost the same signature as the method we we receive the pointer, having added the first parameter the link to object in which it is necessary to call a method. In our example, this interface will look like this:
public interface __void_int { void invoke(object target, int param); } Then, each ldftn or ldvirtftn instruction generates a nested type that implements the pointer interface to the method. The invoke method simply calls the method to which the instruction receives the pointer. In the example above, it looks like this:
public class C2J_anon_0 : __void_int { public void invoke(object target, int paramInt) { ((Program)target).Foo(paramInt); } } And already in the delegate constructor, as a pointer to a method, an instance of this class is passed.
The delegate itself after compilation takes the following form:
public sealed class Deleg : MulticastDelegate { public Deleg(object target, __void_int method_pointer) : super(paramObject, method_pointer) { } public sealed void Invoke(int paramInt) { ((__void_int)this.method).invoke(this.target, paramInt); if (this.next != null) ((Deleg)this.next).Invoke(paramInt); } } This is the default behavior of the compiler. As you can see, the delegate constructor signature has been changed - the last parameter has the interface type of the method pointer, not the native int as necessary by the standard. This is done again for optimization. However, you can tell the compiler that it is necessary to compile the pointers to the method according to the standard using the "-method_pointers standart" parameter. In this case, the creation of the delegate in our example takes the form:
Deleg d = new Deleg(p, Global.AddMethodPointer("TestConsole.Program$C2J_anon_0")); And the delegate himself becomes like this:
public sealed class Deleg : MulticastDelegate { public Deleg(object target, int paramInt) : base(target, Integer.valueOf(paramInt)); { } public sealed void Invoke(int paramInt) { ((__void_int)Global.GetMethodPointer(((Integer)this.method).intValue())).invoke(this.target, paramInt); if (this.next != null) ((Deleg)this.next).Invoke(paramInt); } } As you can see, in this case, the pointer to the method is of type int, but in reality, this is just an index in the global list of pointers to methods. In this way, we comply with the standard, but lose in performance.
yield return / break
Here, to be honest there is nothing to tell. It just works.
Async / await
Here, too, especially nothing to tell. Code using async / await compiles, but does not work. It does not work because there is no implementation of the types required for operation (System.Threading.Tasks.Task, System.Runtime.CompilerServices.AsyncTaskMethodBuilder and so on)
Unsigned numbers
Support for unsigned numbers in the compiler is available, but is included separately with the "-unsigned" parameter. The article http://habrahabr.ru/post/225901/ for the authorship of elw00d really helped with the implementation . In general, in this article, everything is described and all operations with unsigned numbers were made for this article.
Exceptions
In general, exceptions in Java and in CIL are very similar. So far, exception filters are not supported (ICSharpCode.Decompiler does not support them).
Additionally, a mechanism for tying Java and CIL exception types has been added. For example, in CIL there is an exception System.ArithmeticException. Java has its own java.lang.ArithmeticException type. How to make so that intercepting System. ArithmeticException intercepted as well java.lang. ArithmeticException? For this, a JavaExceptionMapAttribute attribute was introduced which indicates to the compiler a similar exception in Java. And when the compiler encounters a System.ArithmeticException intercept, it also adds interception and similar Java exceptions. The only condition that is added is that an additional constructor must be entered into System.ArithmeticException, which takes only one parameter of type java.lang.ArithmeticException so that an instance of the exception of one type is passed to the interceptor.
Debugging
The compiler supports the generation of debugging information (if it is in the original builds) by specifying the compile key "-debug". Here is an example of how a test application is debugged in Eclipse:
Type substitution
This mechanism was created so that the types that are similar in Java could be turned into these analogs when compiled. An example of this type is System.String. In the mscorlib implementation, this type is marked with the TypeMapAttribute attribute, and when compiled it becomes java.lang.String. The substitution of individual methods is also possible. To do this, they must be marked with the attribute MethodMapAttribute.
Conclusion
Here in general, that's all. This is only the alpha version of the project, and so far the stability of work leaves much to be desired. So the further vector of work is the improvement of work stability and the implementation of the standard library. Thank you for reading to the end.
Source: https://habr.com/ru/post/245449/
All Articles