The simpler the better, or when ELB is not needed
 Most likely, the advanced cloud provider Amazon Web Services is primarily associated with EC2 (virtual instances) and ELB (balancer). A typical web service deployment scheme is EC2 instances for a balancer (Elastic Load Balancer). There are a lot of advantages to this approach, in particular, we have out of the box status checks, monitoring (the number of requests, logs), easy to set up scaling etc. But ELB is not always the best choice for load distribution, and sometimes not at all a suitable tool.
Most likely, the advanced cloud provider Amazon Web Services is primarily associated with EC2 (virtual instances) and ELB (balancer). A typical web service deployment scheme is EC2 instances for a balancer (Elastic Load Balancer). There are a lot of advantages to this approach, in particular, we have out of the box status checks, monitoring (the number of requests, logs), easy to set up scaling etc. But ELB is not always the best choice for load distribution, and sometimes not at all a suitable tool.Under the cat, I will show two examples of using Route 53 instead of Elastic Load Balancer: the first is from the experience of Loggly, the second from my personal one.
Loggly
Loggly is a service for centralized collection and analysis of logs. The infrastructure is deployed in the AWS cloud. The main work on collecting logs is performed by the so-called collectors - applications written in C ++, which receive information from clients via TCP, UDP, HTTP, HTTPS. The requirements for collectors are very serious: work as fast as possible and not lose a single package! In other words, the application should collect all the logs, despite the intensity of the incoming traffic. Naturally, the collectors should be horizontally scaled, and the traffic between them should be evenly distributed.
')
The first pancake is lumpy
The guys from Loggly for balancing first decided to use ELB.
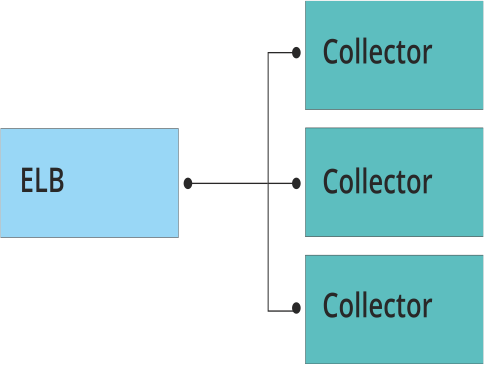
The first problem they encountered was performance. At tens of thousands of events per second, the delay on the balancer began to grow, which was incomparable with the appointment of collectors. Further, the problems fell like ripe apples: it is impossible to send traffic to port 514, UDP is not supported, and the well-known problem of the “cold balancer” Pre-Warming the Load Balancer - manifests itself with a sharp increase in load.
Substitute Route53
Then we began to look for a replacement ELB. It turned out that a simple DNS round robin is completely satisfied, and Route53 solves the problem of traffic distribution, eliminating problems with ELB. Without an intermediate link in the form of a balancer, the delay has decreased, as traffic began to go directly from clients to instances with collectors. No additional “warm-up” is required with sharp increases in message volumes. Route53 also checks the health of the collectors and increases the availability of the system as a whole, the loss of information is reduced to zero.
Conclusion
For high-load services with sharp fluctuations in the number of requests using different protocols and ports, it is better not to even try to use ELB: sooner or later you will encounter restrictions and problems.
Percona Cluster
In our infrastructure, the main data warehouse is Percona Cluster. Many applications use it. The main requirements were fault tolerance, performance and minimal effort to support it. I wanted to do and forget once.
From the side of the application, they decided to use a constant DNS name for each environment (dev, test, live) to communicate with the cluster. Thereby they made life easier for developers and themselves in the configuration and assembly of applications.
ELB did not fit
The balancer did not suit us for about the same reasons as in the case of Loggly. Immediately thought about the HA Proxy as load balancing, especially since Percona is advised to use just such a solution. But I did not want to receive another point of failure in the form of the HA Proxy server. In addition, the additional costs of maintenance and administration are not needed.
Route53 + Percona
When we paid attention to this service as a load balancer and check the status of the cluster servers, it seemed that with a few clicks we would get the desired result. But, after a detailed study of the documentation, we found a fundamental limitation that the entire architecture of the environment and the cluster in it was hacked to pieces. The fact is that Percona Cluster, like most other servers, is located on private subnets, and Route 53 can only check public addresses!
The disappointment did not last long - a new idea arose: make the state check yourself and use the Route 53 API to update the DNS record.
Final solution
On the project everywhere, Monit is used to monitor system services. It was configured for the following automatic actions:
- MySQL Port Check
- Changing DNS records when there is no response
- Sending a notification
- Attempt to restart service
We get this behavior when one of the nodes in the cluster crashes: the support service receives a notification, the DNS record changes so that the sick node does not receive requests, monitd tries to restart the service, if it fails, it is notified again. The application continues to work as if nothing had happened, not even knowing about the problems.
Conclusion
The two cases described in the article show that Route 53 is sometimes much better suited for load balancing and fault tolerance than ELB. At the same time, the cloud providers API allows you to bypass many of the limitations of their own services.
Source: https://habr.com/ru/post/245447/
All Articles