Yandex opens a new direction of its activity - Yandex Data Factory
Recently, in Paris, at the LeWeb conference , Yandex announced the opening of a new, important area of its activity - for commercial processing of big data - Yandex Data Factory .
We believe that the processing of big data is part of a new round of technical revolution that will make all of humanity even more efficient and lead us to a future that we still cannot even fully imagine. And there, working with large amounts of data will be no less important and widespread than the generation of electricity or railways today.

')
Before the public launch of Yandex Data Factory, we conducted several pilot projects with partner companies. For the company serving the power lines, Yandex Data Factory created a system that analyzes the pictures taken by the drones and automatically identifies threats: for example, trees growing too close to the wires. And for the road agency analyzed data on traffic congestion, quality of coverage, average speed of traffic and accidents. This allowed real-time forecast of traffic congestion for the next hour and identify areas with a high probability of accidents.
It seems that every time humanity learns to save 10% somewhere, an industrial revolution takes place. 200 years ago began to use the steam engine. One hundred years ago, thanks to the development of chemistry, new artificial materials appeared. Electronics in the 20th century changed not only production, but also life. When people realized that processing materials was cheaper in China and Southeast Asia, the entire industrial production of the world moved there. In fact, 10% savings are global shifts. Data analysis can help global production and economies become more efficient.
The Internet is not the only place where there is big data. Historically back in the 60s-70s of the last century, geologists generated them. They watched the waves reflected from the explosions on the surface — this was their way of looking underground. In geological exploration there is something to analyze. And two years ago we provided our parallel computing technologies and equipment for processing geological and geophysical data. Algorithms have become a new way to look underground.
Many of us think that Wi-Fi in airplanes is needed so that we can use our devices during flights. But initially the Internet appeared in them, because modern aircraft are thousands of sensors that measure a huge amount of indicators all the time they fly and generate data. Their part is transmitted to the ground before landing, and after it, a terabyte disk is removed from the aircraft and stored, not knowing what to do with everything that is written on it.
But if you look even at the data that is transmitted during the flight, you can predict in advance which parts, for example, need to be replaced on the plane. This will save both passenger time and aircraft building resources, which lose 10% on downtime due to spare parts. Yandex itself is literally streets from servers that consume 120 MW of power. And even when you have hundreds of thousands of servers, at the same time always at any second several hundred disks do not work. The machine can predict which disk will fail next and will prompt you to change it.
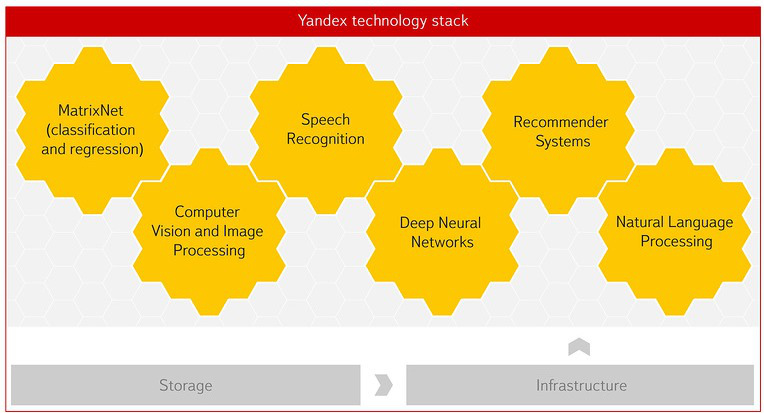
Yandex is one of the few companies in the world with the necessary technology and expertise. Searching the Internet is impossible without machine learning and the ability to analyze data. Now they are behind almost everything in Yandex - forecast traffic jams, statistical translation, speech recognition and images. A great influence on the development of this had a Soviet scientific school. Subsequently, we created a Data Analysis School to train specialists who know how to work with data. With our participation, the Faculty of Computer Science has appeared in the Higher School of Economics, where, among other things, there is a department for data analysis and artificial intelligence.
Matrixnet - our machine learning technology was originally created to solve ranking problems in search. Now it is used by scientists at CERN. One of the projects is related to the construction of a system for sampling data on collisions of particles in the collider in real time. This is an accurate and flexible filter based on MatrixNet, which allows scientists to very quickly get at their disposal only interesting and important data on collisions of particles in the LHC to use them in scientific works. Sometimes this is super rare data, found, for example, in 100 thousand cases per 100 billion. More than half of all LHCb scientific articles are based on the data filtered by our matrix-based algorithm.

Our second project with CERN is data storage optimization. Over the two years of operation, the LHC generated petabytes of data stored on hard drives, so that scientists have quick access to them. But the space on the HDD is already running out, and some of the data needs to be transferred to tape drives. This is a cheaper way to store, but less flexible - it’s not so easy to search for data on a tape. It is necessary to understand which part of the files to transfer, and which part to leave on hard drives. We proposed CERN to help rank thousands of accumulated files about experiments and highlight the data that needs to be left on the HDD. Thus, we will help free up several petabytes on the HDD, which is tens of percent.
The amount of data is growing at a very fast pace. Each of us carries a huge source of data in his pocket - the phone. Sensors are becoming cheaper, more and more data is being sent to the servers, and the question arises as to what to do with them. It seems to us that if we learn to use them and somehow work with them, then there are chances to save the world economy 10% of the resources. And, if this happens, we are waiting for a new industrial revolution.
We believe that the processing of big data is part of a new round of technical revolution that will make all of humanity even more efficient and lead us to a future that we still cannot even fully imagine. And there, working with large amounts of data will be no less important and widespread than the generation of electricity or railways today.
')
Before the public launch of Yandex Data Factory, we conducted several pilot projects with partner companies. For the company serving the power lines, Yandex Data Factory created a system that analyzes the pictures taken by the drones and automatically identifies threats: for example, trees growing too close to the wires. And for the road agency analyzed data on traffic congestion, quality of coverage, average speed of traffic and accidents. This allowed real-time forecast of traffic congestion for the next hour and identify areas with a high probability of accidents.
It seems that every time humanity learns to save 10% somewhere, an industrial revolution takes place. 200 years ago began to use the steam engine. One hundred years ago, thanks to the development of chemistry, new artificial materials appeared. Electronics in the 20th century changed not only production, but also life. When people realized that processing materials was cheaper in China and Southeast Asia, the entire industrial production of the world moved there. In fact, 10% savings are global shifts. Data analysis can help global production and economies become more efficient.
The Internet is not the only place where there is big data. Historically back in the 60s-70s of the last century, geologists generated them. They watched the waves reflected from the explosions on the surface — this was their way of looking underground. In geological exploration there is something to analyze. And two years ago we provided our parallel computing technologies and equipment for processing geological and geophysical data. Algorithms have become a new way to look underground.
Many of us think that Wi-Fi in airplanes is needed so that we can use our devices during flights. But initially the Internet appeared in them, because modern aircraft are thousands of sensors that measure a huge amount of indicators all the time they fly and generate data. Their part is transmitted to the ground before landing, and after it, a terabyte disk is removed from the aircraft and stored, not knowing what to do with everything that is written on it.
But if you look even at the data that is transmitted during the flight, you can predict in advance which parts, for example, need to be replaced on the plane. This will save both passenger time and aircraft building resources, which lose 10% on downtime due to spare parts. Yandex itself is literally streets from servers that consume 120 MW of power. And even when you have hundreds of thousands of servers, at the same time always at any second several hundred disks do not work. The machine can predict which disk will fail next and will prompt you to change it.
Yandex is one of the few companies in the world with the necessary technology and expertise. Searching the Internet is impossible without machine learning and the ability to analyze data. Now they are behind almost everything in Yandex - forecast traffic jams, statistical translation, speech recognition and images. A great influence on the development of this had a Soviet scientific school. Subsequently, we created a Data Analysis School to train specialists who know how to work with data. With our participation, the Faculty of Computer Science has appeared in the Higher School of Economics, where, among other things, there is a department for data analysis and artificial intelligence.
Matrixnet - our machine learning technology was originally created to solve ranking problems in search. Now it is used by scientists at CERN. One of the projects is related to the construction of a system for sampling data on collisions of particles in the collider in real time. This is an accurate and flexible filter based on MatrixNet, which allows scientists to very quickly get at their disposal only interesting and important data on collisions of particles in the LHC to use them in scientific works. Sometimes this is super rare data, found, for example, in 100 thousand cases per 100 billion. More than half of all LHCb scientific articles are based on the data filtered by our matrix-based algorithm.
Our second project with CERN is data storage optimization. Over the two years of operation, the LHC generated petabytes of data stored on hard drives, so that scientists have quick access to them. But the space on the HDD is already running out, and some of the data needs to be transferred to tape drives. This is a cheaper way to store, but less flexible - it’s not so easy to search for data on a tape. It is necessary to understand which part of the files to transfer, and which part to leave on hard drives. We proposed CERN to help rank thousands of accumulated files about experiments and highlight the data that needs to be left on the HDD. Thus, we will help free up several petabytes on the HDD, which is tens of percent.
The amount of data is growing at a very fast pace. Each of us carries a huge source of data in his pocket - the phone. Sensors are becoming cheaper, more and more data is being sent to the servers, and the question arises as to what to do with them. It seems to us that if we learn to use them and somehow work with them, then there are chances to save the world economy 10% of the resources. And, if this happens, we are waiting for a new industrial revolution.
Source: https://habr.com/ru/post/245393/
All Articles