Assessing the impact of Cache levels on I / O performance in EMC VNX5400
Introduction
After testing and writing an article about the effect of caching mechanisms on the performance of the younger model (entry level) EMC VNXe3200 , periodically they began to itch their hands to do the same with its older fellow VNX2 arrays. Recently, this opportunity presented itself. Managed to run tests on the VNX5400. In addition to testing directly the VNX5400, we also tested the EMC ExtremCache solution (PCI-E SSD EMC XtremSF700 card on eMLC chips + EMC XtremSW software). But about EMC ExtremCache there will be the following article. In the meantime, let's talk about arrays VNX2.
EMC 2 updated its line of midrange storage systems in the fall of 2013. The second-generation VNX arrays (VNX2) looked, in my opinion, like a job well done on the mistakes made in the first-generation VNX (VNX1). Vendor also presented them as a radical and innovative midrenge update line. However, now, more than a year after they hit the market, the VNX2 still has not lost its relevance. I will not dwell on the characteristics and capabilities of the arrays themselves, I will simply give links to the official documents of the Data Sheet and Spec Sheet .
Description of the stand and tests
Under the spoiler
Testing was carried out using IOMETER. The load profile is the same as when testing the VNXe3200 . Standard database pattern (Intel / StorageReview.com).
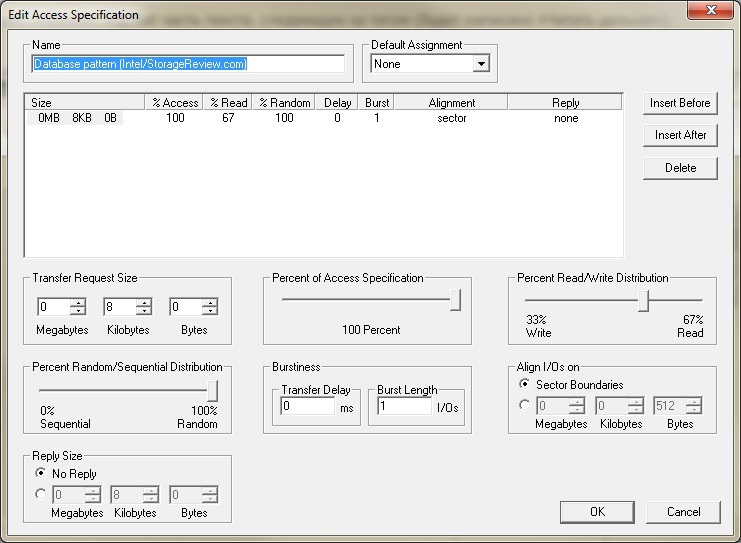
')
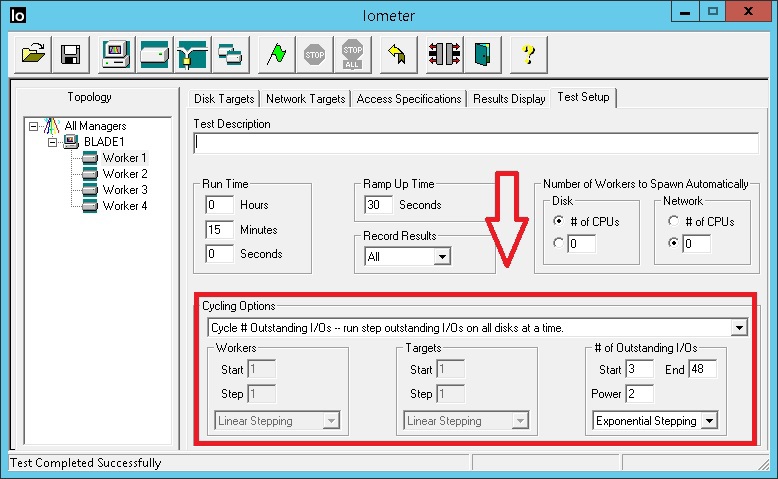
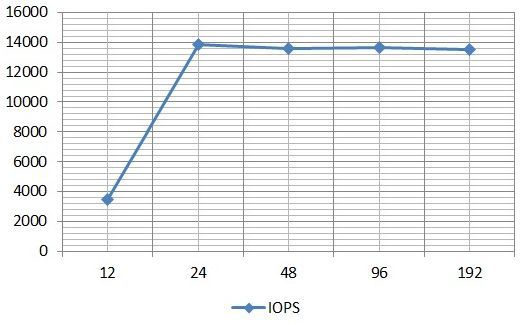
There was an HP DL360 G5 server with 1 CPU (4-core) and 4GB RAM. The server has 2 PCI-E slots. A dual-port Qlogic 4Gb / s HBA was installed in one of the slots, connected directly to the VNX5400. Since the physical cores in the CPU are much lower than when testing the VNXe3200, we had to initially increase the number of I / O streams per Worker IOMETER. The ratio of 1 Worker to 1 core CPU. At each Worker, 3 I / O streams were initially set up with a “multiplier” 2. That is, each subsequent run (15 min) of the test in a cycle increased the number of flows by 2 times. Only 5 consecutive runs and respectively on the Worker on 3/6/12/24/48 IO threads. In general, the test file received 12/24/48/96/192 stream. Those. the maximum is the same as for VNXe3200. The time of each test is 15x5 = 75 minutes, not counting the “Rump up time”. The settings in IOMETER are as follows.
On the VNX5400, there was already a FastVP disk pool with moons on which OSs were installed, so I didn’t tinker and create everything anew. The pool included 3 and 100Gb SSD disks (Extreme Performance Tier) and 15 900Gb SAS 10K RPM disks in Raid5 4 + 1 (Perfomance tier), i.e. 3 private (not visible to the user) Raid Groups in 4 + 1 configuration. Test moons with the “Lowest Available Tier” policy were created on the pool, so that these moons would be located entirely on SAS disks and SSD disks from Extreme Perfomance Tier would not affect the results.

The server used OS Win2012R2 SP1 and software for managing access paths to the moon PowerPath from EMC 2 .
EMC 2 recommends using 150 IOPS for SAS 10k RPM drives (FC / SAS 15k RPM - 180 IOPS, SATA / NL_SAS - 90 IOPS, SSD eMLS - 3500 IOPS, SSD SLC - 5000 IOPS) for performance calculations. That is, in theory, our 15 disks can produce 150x15 = 2250 IOPS. We need to calculate how much IOPS will be obtained from these server disks, taking into account our read / write load profile as a percentage of 67/33 and the overhead of writing to RAID5. We get the following equation with one unknown 2250 = X * 0.33 * 4 + X * 0.67. Where X is our IOPS, which will get the server from our disks, and 4 is the size of the “penalty” on the record for Raid5. As a result, we get X = 2250 / 1.99 = ~ 1130 IOPS. Let me remind you that in practice in peak loads we usually get 1.5-2 times higher figures for IOPS. That is, with proper distribution of data across all three private Raid5 disk groups, we can count on the range of 1695-2260 IOPS.
')
There was an HP DL360 G5 server with 1 CPU (4-core) and 4GB RAM. The server has 2 PCI-E slots. A dual-port Qlogic 4Gb / s HBA was installed in one of the slots, connected directly to the VNX5400. Since the physical cores in the CPU are much lower than when testing the VNXe3200, we had to initially increase the number of I / O streams per Worker IOMETER. The ratio of 1 Worker to 1 core CPU. At each Worker, 3 I / O streams were initially set up with a “multiplier” 2. That is, each subsequent run (15 min) of the test in a cycle increased the number of flows by 2 times. Only 5 consecutive runs and respectively on the Worker on 3/6/12/24/48 IO threads. In general, the test file received 12/24/48/96/192 stream. Those. the maximum is the same as for VNXe3200. The time of each test is 15x5 = 75 minutes, not counting the “Rump up time”. The settings in IOMETER are as follows.
On the VNX5400, there was already a FastVP disk pool with moons on which OSs were installed, so I didn’t tinker and create everything anew. The pool included 3 and 100Gb SSD disks (Extreme Performance Tier) and 15 900Gb SAS 10K RPM disks in Raid5 4 + 1 (Perfomance tier), i.e. 3 private (not visible to the user) Raid Groups in 4 + 1 configuration. Test moons with the “Lowest Available Tier” policy were created on the pool, so that these moons would be located entirely on SAS disks and SSD disks from Extreme Perfomance Tier would not affect the results.
The server used OS Win2012R2 SP1 and software for managing access paths to the moon PowerPath from EMC 2 .
Some calculations.
EMC 2 recommends using 150 IOPS for SAS 10k RPM drives (FC / SAS 15k RPM - 180 IOPS, SATA / NL_SAS - 90 IOPS, SSD eMLS - 3500 IOPS, SSD SLC - 5000 IOPS) for performance calculations. That is, in theory, our 15 disks can produce 150x15 = 2250 IOPS. We need to calculate how much IOPS will be obtained from these server disks, taking into account our read / write load profile as a percentage of 67/33 and the overhead of writing to RAID5. We get the following equation with one unknown 2250 = X * 0.33 * 4 + X * 0.67. Where X is our IOPS, which will get the server from our disks, and 4 is the size of the “penalty” on the record for Raid5. As a result, we get X = 2250 / 1.99 = ~ 1130 IOPS. Let me remind you that in practice in peak loads we usually get 1.5-2 times higher figures for IOPS. That is, with proper distribution of data across all three private Raid5 disk groups, we can count on the range of 1695-2260 IOPS.
Tests and Results
1. Test of Cache Controllers (SP - storage processor) VNX5400 file 2Gb
This test was conducted on a 2GB file (the size of the test LUN from NTFS is 10 Gb), on the basis that it fits perfectly into SP Cache and as a result all I / O will be worked out from the RAM memory of the storage controllers. That is, conditionally, a small “hot” data area appeared on the array. At the same time, FastCache on the array was turned off.
As a result, we got the following graph in the Unisphere Analyzer embedded in the array.

At the same time, SP Cache was filled in the following way (cache works both for reading and writing):
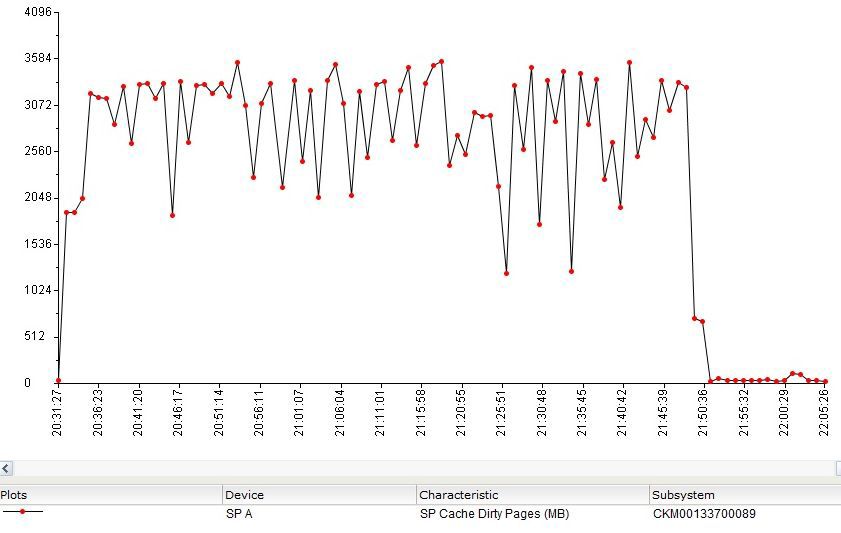
That is, within a few minutes after the start of the test, all 2Gb of the test file were loaded into Cache.
Graph of IOPS average values versus the number of input / output streams by results in IOMETER:

Graph of average values of I / O response time versus the number of I / O streams by results in IOMETER:
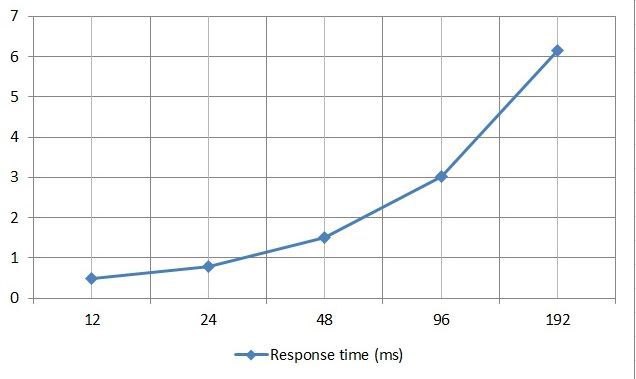
I remind you that it is considered to be comfortable value of the average response time for databases up to 10 ms. The graph shows that with 192 IO streams, which is a rather large value, we got a slightly smaller average response time than in the same test on the VNXe3200 (it was 8 ms). In absolute terms, the difference is not significant, but nonetheless is one of the reasons for the large gap in the number of IOPS. The VNXe3200 had an average of about 23,800 IOPS per 192 IO streams in a similar test. If we calculate the difference in percent for the response time and for IOPS, we get both there and there about the same 20-25%.
2. Test of Cache Controllers (SP - storage processor) VNX5400 file 15Gb
The test was conducted on a 15GB file (LUN with NTFS - 20Gb). FastCache is still off. The size of the RAM in the SP in the VNX5400 is 16 Gb. But if you rely on logs from the array, then the actual amount of RAM used for caching is about 4Gb for VNX5400. Everything else is apparently used to ensure the operation of the most basic OS controllers and another, rather wide, functional storage system (tiering, thin provisioning, snapshots, clone, replication, fast cache, etc.).

Thus, our 15 Gb highly loaded (hot) data will not fit in SP Cache. In general, this is exactly what can be seen on the graph from the Unisphere Analizer. Fully random I / O across all 15 Gb cannot be fully cached by the controllers, so in this test, the main performance volume comes from physical spindles, i.e. directly discs.
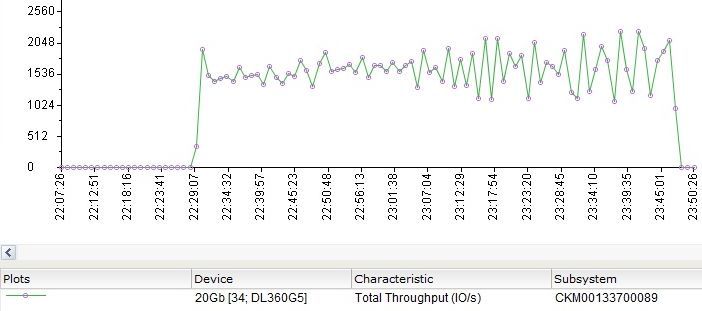
At the same time, SP Cache continues to work, although not so effectively.
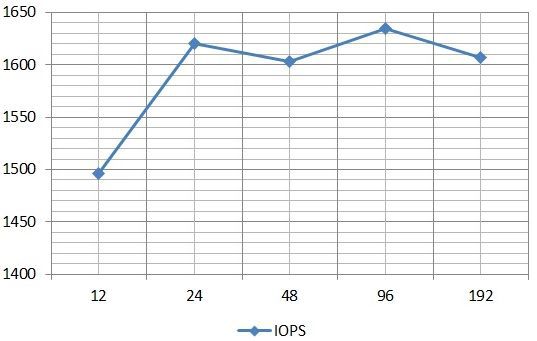
Graph of IOPS average values versus the number of input / output streams by results in IOMETER:
Graph of average values of I / O response time versus the number of I / O streams by results in IOMETER:
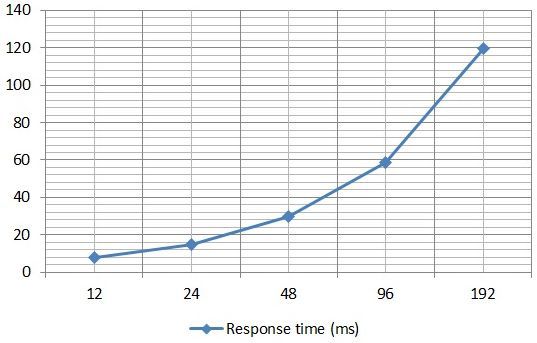
The graph shows that the response time already on 24 streams is about 14 ms, i.e. out of the comfort zone. I was also surprised that I missed so much with an estimate of peak disk performance and I “went” to figure it out. As a result, I found out that during the test the load not on all private RGs in the Perfomance Tier is the same. Those. based on performance considerations, our test file is unevenly distributed across all 3rd RGs in the Performance Tier. On the graph it looks like this (disks 5, 6 and 7 are SSD from Extreme Perfomance Tier).

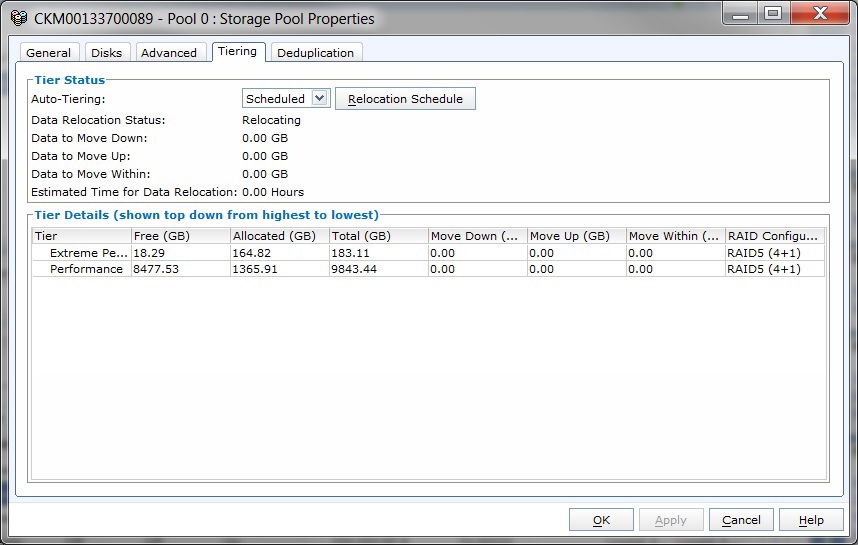
That is, not all 15 spindles were involved in the full test. To smooth out a similar effect in FastVP pools on VNX2 arrays there is a technology that allows redistributing “hot” and “cold” data not only between disks with different performance (SSD, SAS, NL_SAS), but also between private RGs within one Tier. The redistribution of data between private RGs occurs at the same time according to a schedule as the migration of data between Tier-s. In the array interface, this can be seen in the properties of the pool on the "Tiering" tab. In particular, in my case immediately after the test, it looked like this.
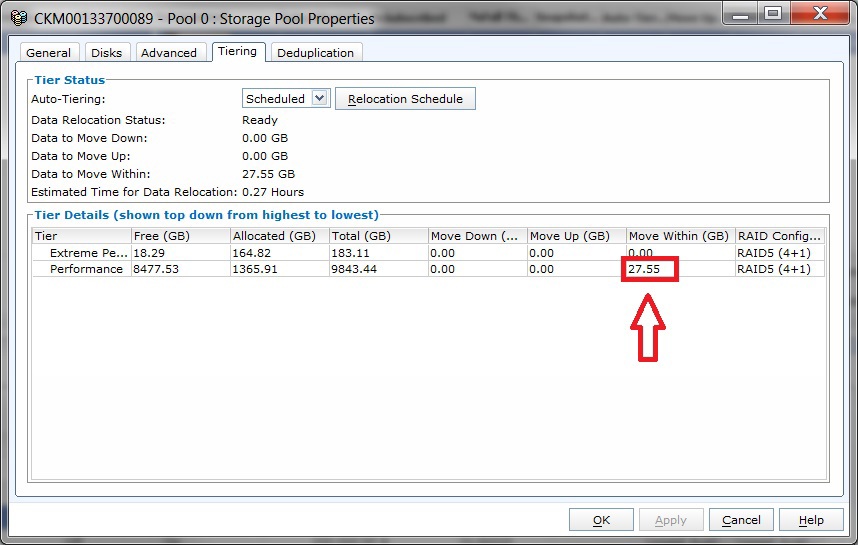
Let me remind you that when the array was idle, the window looked like this.

Another interesting picture can be seen by overlapping SP Cache and overall performance of the tested LUN.
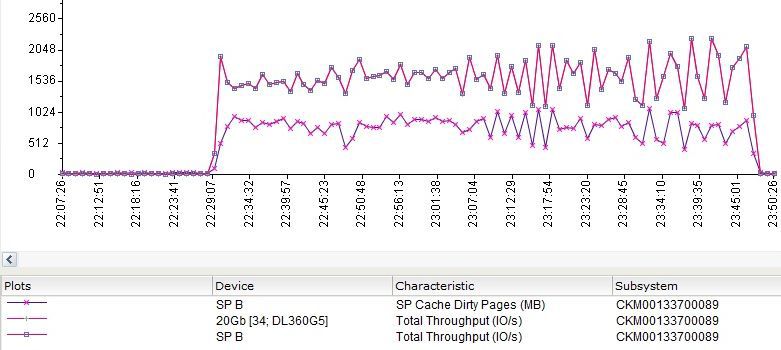
The graph shows that even in a rather unpleasant situation, SP Cache allows you to win "additional" IOPS.
3. Test FastCache in VNX5400 file 15Gb
After enabling FastCache on the array (two SSD 100Gb in Raid1), a test was performed on the same file in 15Gb (LUN with NTFS - 20Gb). FastCache in EMC 2 arrays is an additional level of caching based on SSD disks, which is embedded between SP Cache and the disks of the array itself. A 15Gb file (or conventionally a “hot” data region) should fit completely into a 100Gb FastCache, which should improve the results of the previous test.
Got the following graph from the Unisphere Analizer (in IOPS).

FastCache was filled as follows (in%).
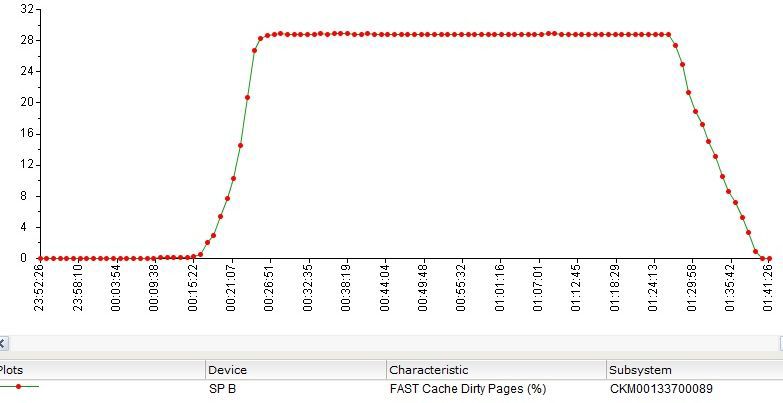
Read Hits / s - read operations that were processed from FastCache.
Read Misses / s - operations for which data was not found in FastCache and were requested from the array disks.
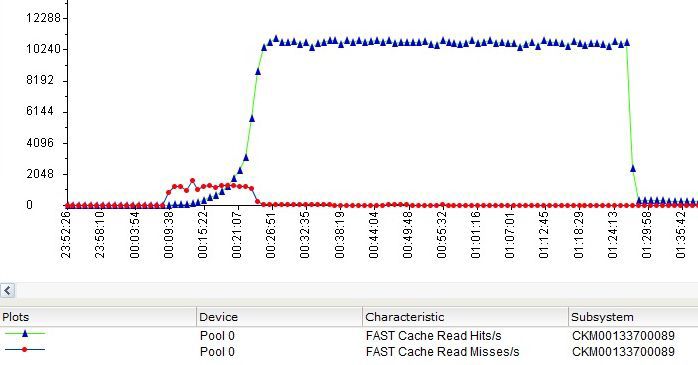
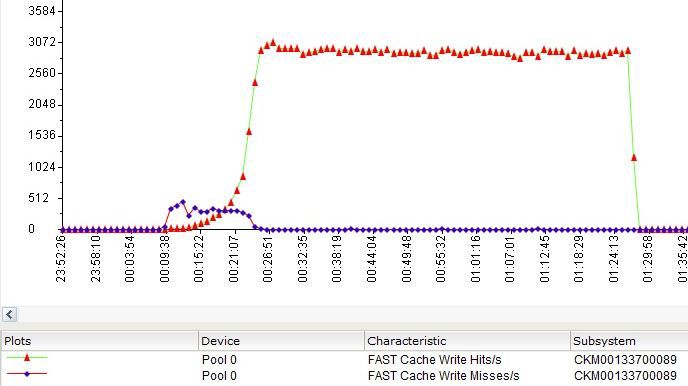
Write Hits / s - write operations in FastCache, which did not require a preliminary reset of "obsolete" data to disks (pre-clearing the cache), or operations that requested data written to the cache but not yet moved to disks.
Write Misses / s - write operations not processed through FastCache or requiring forced (emergency) release of space in the cache.
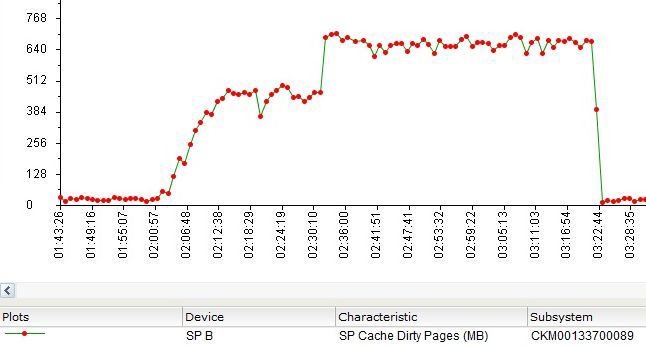
SP Cache also didn’t stand idle and worked through some of the I / O.
From the server side in IOMETR, everything looked as follows.
Graph of IOPS average values versus the number of input / output streams by results in IOMETER:
Graph of average values of I / O response time versus the number of I / O streams by results in IOMETER:

The last graph shows that after loading the “hot” area in FastCache, the response time even decreases and begins to grow only with increasing input / output streams. At the same time, the graph “breaks through” a ceiling of 10 ms far beyond the value of 100 IO streams.
4. Test of FastCache in VNX5400 150Gb file
The following test was performed on a 150Gb file (Test LUN with NTFS 200Gb). Those. Our “hot” data area in this test was about 1.5 times the size of FastCache on the array. The following results were obtained.
Graph from Unisphere Analizer (in IOPS).
Filling FastCache data went, but slowly enough. By the end of the 75 minute test, about 20% were filled in (conventionally about 20Gb from a 150Gb test file).

Hit schedules and non hit read operations in FastCache.

Hits / s and misses / s charts for write operations in FastCache.
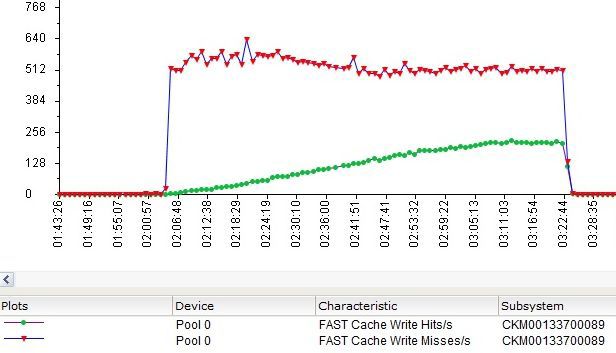
SP Cache is also not idle.
How it looked from the server and IOMETR.
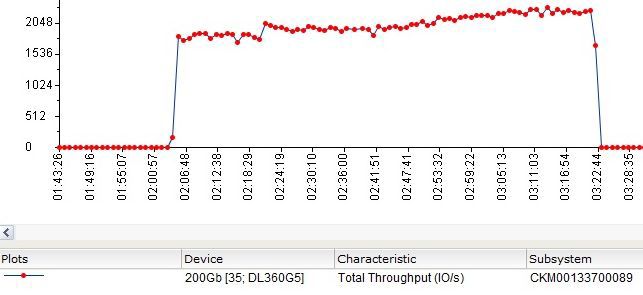
Graph of IOPS average values versus the number of input / output streams by results in IOMETER:
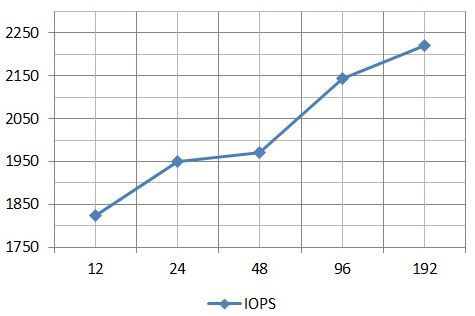
Graph of average values of I / O response time versus the number of I / O streams by results in IOMETER:

The graphs show that the IOPS values are slightly higher than they were when testing a 15Gb file without FastCache. So it would be possible to conclude that in this uncomfortable situation FastCache helps to squeeze out additional IOPS from the configuration. But in practice, everything was not quite so.
Firstly, in this test, all private Raid Group (Raid5 4 + 1) in the “Perfomance Tier” were loaded more evenly.

Secondly, I decided to conduct an additional test with a 150Gb file, but with FastCache turned off. I will not paint it in detail, here are the charts from IOMETR (I did not believe it at first and ran the test twice).
Graph of IOPS average values versus the number of input / output streams by results in IOMETER:

Graph of average values of I / O response time versus the number of I / O streams by results in IOMETER:
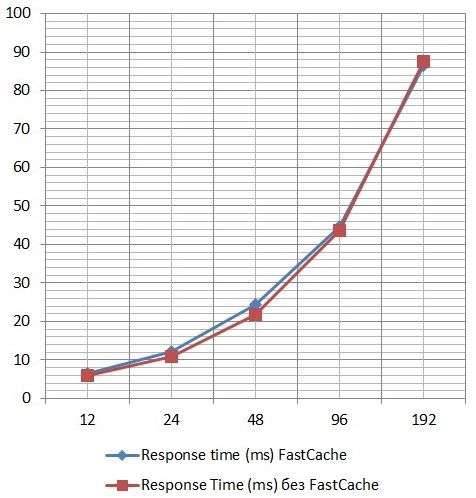
That is, in a situation where the amount of hot data exceeds the size of FastCache and with a high percentage of random requests, filling in FastCache takes some time. In such situations, FastCache introduces, albeit a small, but nonetheless additional delay in the Response time. In this situation, you can suggest to use the optional Extreme Perfomance Tier on the SSD in the pool. Part of the hot data in this case will "settle" on it and will not be processed through FastCache. Accordingly, the amount of hot data processed through FastCache will decrease and will be in a more comfortable range. That would not be unfounded, I conducted another test.
5. Test of FastCache in VNX5400 file 80Gb
This test was conducted on an 80Gb file (Test LUN with NTFS 100Gb), which is close enough to the FastCache volume in the array under test. That is, the “hot” data area was quite large, but nevertheless completely fit into FastCache.
Graph from Unisphere Analizer (in IOPS).

FastCache was filled more actively than on a 150Gb file.
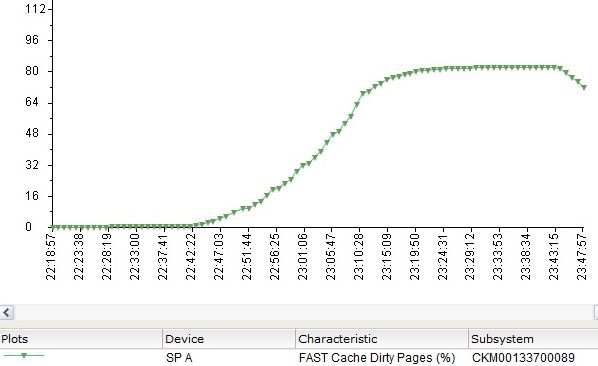
SP Cache also handled some I / O.

On the server side and IOMETR, everything looked the same much more rosy than on a 150Gb file.
Graph of IOPS average values versus the number of input / output streams by results in IOMETER:

Graph of average values of I / O response time versus the number of I / O streams by results in IOMETER:

Starting from about 24 IO streams (about 15 minutes from the start of the test), the data began to fall more and more into FastCache. Accordingly, the overall performance in the test began to grow as well, while the response time, as the IO flows increased, did not grow as significantly as in the test with the 150Gb file.
A small digression about disk pools
Under the spoiler
When designing a disk pool, if you do not know the actual size of the hot and warm data area, EMC recommends that you maintain the following proportions for a three-level pool:
10% - SSD drives
20% - SAS drives
70% - NL-SAS drives
In addition, you should take into account that when you add flash tier to the pool automatically, all the metadata of the thin moon created on the pool will be placed on the SSD. If there is enough space for them. This allows you to increase the overall performance of thin moons and pool. Under this metadata, you need to plan an additional place on the SSD at the rate of 3Gb volume for every 1Tb actually occupied by thin moons in the pool. At the same time, the moons having the highest available tier tiring policy will take precedence when placed on an SSD dash over any other data.
Using the lowest available tier policy for thin, deduplicated, or compressed moons results in placing their metadata on the slowest disks. That negatively affects the performance of these moons.
For the correct work of the tiring you need free space in the pool. At least 10% of free space on each dash is recommended. Otherwise, the system will not be able to “shift” pieces (chunks) of data between different types of disks in the pool.
10% - SSD drives
20% - SAS drives
70% - NL-SAS drives
In addition, you should take into account that when you add flash tier to the pool automatically, all the metadata of the thin moon created on the pool will be placed on the SSD. If there is enough space for them. This allows you to increase the overall performance of thin moons and pool. Under this metadata, you need to plan an additional place on the SSD at the rate of 3Gb volume for every 1Tb actually occupied by thin moons in the pool. At the same time, the moons having the highest available tier tiring policy will take precedence when placed on an SSD dash over any other data.
Using the lowest available tier policy for thin, deduplicated, or compressed moons results in placing their metadata on the slowest disks. That negatively affects the performance of these moons.
For the correct work of the tiring you need free space in the pool. At least 10% of free space on each dash is recommended. Otherwise, the system will not be able to “shift” pieces (chunks) of data between different types of disks in the pool.
findings
Based on the tests performed, the following can be said. No matter how strange it may sound, but FastCache is not always good. In an improperly designed system, it can affect performance, including in the direction of deterioration. In order not to miss the design stage, it is better to drive a copy or part of your actual loads on the demo array. Demo array can be requested from the vendor. If this is not possible, then it is necessary to proceed from the ratios of hot / warm / cold data that the same vendor suggests using in the calculations (based on statistical data and some considerations of your own). The first option with a demo array, in my opinion, is preferable. In general, on a properly designed array, the additional level of caching (FastCache) on the VNX2 gives a decent performance boost.
The performance of the VNX5400 is not much higher than the performance of the VNXe3200, at least in small and comparable configurations (the number of disks, the size of the FastCase). Perhaps this is due to the fact that the junior array was released only this 2014. The same conclusions can be applied to the VNX5200, in which the SP (controllers) are no different from the VNX5400 (the service partner number for the replacement is the same). The VNX5200 has only a limit on the maximum number of disks (125 pieces versus 250 pieces on the VNX5400), a limit on the maximum FastCache size (600Gb vs. 1000Gb for the VNX5400) and has one slot less for an optional expansion card with ports for connecting servers.
All tests performed are “synthetics”, which have nothing to do with your actual loads. However, in my opinion, such modeling helps to understand the general tendencies of storage behavior in various situations.
Like ps
In case you need a storage system for streaming traffic (Nr: recording and processing large video streams), then no cache will help you here. The moment will come when it overflows and in this situation there will be the number of spindles (disks) in your storage system.
If you have a very high transaction load. A large OLTP database or VDI with thousands or tens of thousands of users, you probably need an all flash array, rather than a classic storage system and Tiering.
Source: https://habr.com/ru/post/245385/
All Articles