Hadoop for network engineers
Apache Hadoop is a set of utilities for building a supercomputer capable of solving tasks that are too large for a single server. Many servers form a Hadoop cluster. Each machine in the cluster is named node, or node. If you need to increase system performance, then more servers are simply added to the cluster. Ethernet performs the functions of a supercomputer “system bus”. This article will cover aspects of the design of the network infrastructure, as well as the architecture that Cisco proposes to use for such systems.
To understand how Hadoop works, you need to understand the functions of two main components: HDFS (Hadoop File System) and MapReduce, which will be discussed in this article in more detail. Other possible components of the system are shown in Figure 1.
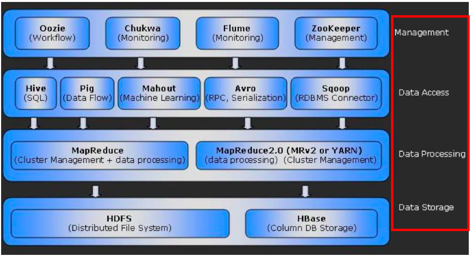
Figure 1. Hadoop Ecosystem
HDFS is a global file system distributed across a cluster that provides data storage . Files are divided into large blocks, usually 64, 128 or 512 MB, after which they are written to different nodes of the cluster. Thus, files of any size can be placed on HDFS, even exceeding the storage capacity of a single server. Each recorded block is at least twice replicated to other nodes. On the one hand, replication provides fault tolerance. On the other - the possibility of local data processing without a load on the network infrastructure. Cluster disk space with a standard replication ratio should be three times as much as the information you want to keep. It is also necessary to have an additional 25–30% outside HDFS to store intermediate data arising during processing. That is, 1 TB of “useful information” requires 4 TB of “raw space”.
')
MapReduce is a system for distributing data processing tasks among Hadoop cluster nodes. This process, oddly enough, consists of two stages: Map and Reduce . The map runs simultaneously on many nodes and provides intermediate information that Reduce processes to provide the final result.
I will give a simplified example that will help you better understand what is happening. Imagine that you need to count the number of repetitions of words in a newspaper. You will write down every word and tick the box when it appears again in the text. This process will take a lot of time, especially if you get lost and have to start all over again. It will be much easier to divide the newspaper into small pieces and distribute them to friends and acquaintances asking them to perform the counting. Thus, the task will be distributed and each will provide you with some intermediate result. Since the data has already been pre-sorted, your task will be very simple - to sum up the information received. In terms of Hadoop, your friends will perform the Map stage, and you will Reduce. By the way, the intermediate data is called Shuffle, and pieces of the newspaper - Chunk.
The best option is when the Map process works with information on a local disk. If this is not possible due to the high utilization of the node, then the task will be transferred to another node, which will first copy the data, thus increasing the load on the network. If only one copy of the information was stored on HDFS, then remote processing cases would be frequent. By default, HDFS creates three copies of data on different nodes, and this is a good factor for fault tolerance and local computing.
There are two types of nodes: SlaveNodes and MasterNodes . SlaveNode nodes directly record and process information, launch DataNode and TaskTracker daemons . MasterNodes act as managers, they store file system metadata and provide block allocation on HDFS ( NameNode ), and also coordinate MapReduce using the Job Tracker daemon. Each daemon runs on its own Java Virtual Machine (JVM).
Consider the process of writing to HDFS a file divided into two blocks (Figure 2). The client calls the NameNode (NN) with a request on which DataNode (DN) these blocks should be placed on. The NameNode instructs to place Block1 on DN1. In addition, the NameNode commands DN1 to replicate Block1 to DN2, and DN2 to DN6. Similarly, Block2 fits on nodes DN2, DN5 and DN6. Each DN at intervals of several seconds sends a report to NN on the available blocks. If the report does not arrive, the DN is considered lost, which means that there is less by one replica of certain blocks. NN initiates their recovery on other DNs. If, after some time, the missing DN appears again, then NN will select the DN from which extra copies of the data will be deleted.
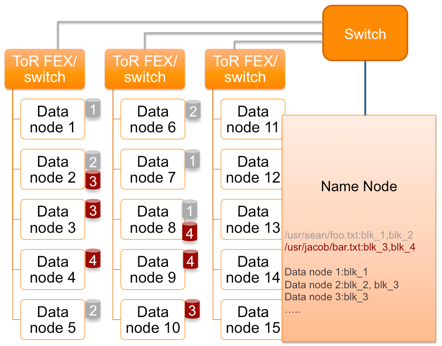
Figure 2. HDFS write process
Equivalent to NameNode in importance is the JobTracker daemon that manages distributed data processing. If you want to run the program on the entire cluster, then it is sent to MasterNode with the JobTracker daemon. JobTracker determines which data blocks are needed, and selects nodes where the Map stage can be executed locally; in addition, nodes are selected for Reduce. On the SlaveNode side, the process of interacting with JobTracker is performed by the TaskTracker daemon. It tells JobTracker the status of the task. If the task is not completed due to an error or a too long execution time, JobTracker will transfer it to another node. Frequent failure of the task node leads to the fact that it will be placed in the black list.
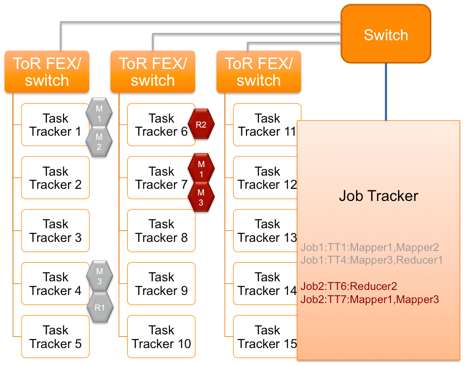
Figure 3. MapReduce data processing
Thus, for the network infrastructure, the Hadoop cluster generates several types of traffic:
- Heartbeats - service information between MasterNodes and SlaveNodes, which determines the availability of nodes, the status of task execution, sends commands to replicate or delete blocks, etc. Heartbeats load on the network is minimal, and these packets should not be lost because depends on the stability of the cluster.
- Shuffle - data that is transmitted after performing the stage Mar on Reduce. The nature of traffic, from many to one, generates an average load on the network.
- Write to HDFS - write and replicate large amounts of data in large blocks. High network load.
It is interesting to observe how the computing resources used for Hadoop evolve. In 2009, the configuration of a typical resource-balanced node was a single-duplex two-socket server with four hard disks, dual-core processors and 24 gigabytes of RAM connected to a gigabit Ethernet network. What has changed in five years? Four generations of processors have changed - they have become more powerful, they support more cores and memory, and the 10-gigabit network is widely used in data processing centers. And only the hard drives have not changed. In order to optimally utilize the available processors and memory, modern clusters are built on the basis of dual-unit servers, where you can put a large number of disks. The number of possible operations with the file subsystem, in turn, determines the needs of nodes in network bandwidth. Figure 4 shows data for servers of various configurations, from which it follows that when building a system, it is better to focus on high-speed 10GbE, since the nodes can potentially process more than 1 Gb / s.

Figure 4. I / O subsystem performance based on the number of hard drives
The requirements for local storage are also determined by the fact that Hadoop does not use servers in blade performance, where the ability to install local disks is extremely limited. It is also worth noting that for SlaveNodes they do not use virtualization and the disks are not collected in RAID.
Cisco has a complete set of products for building a hardware platform for Hadoop. These are servers, network devices, control systems and automation. Based on Cisco UCS and Nexus, an architecture for working with large amounts of data, called CPA (Common Platform Architecture), was created and tested. This section of the article will describe the features of the network design used in the solution.

Figure 5. Common Platform Architecture components
The solution is based on the following set of equipment:
- Fabric Interconnect 6200 (FI) - high-speed non-blocking universal switches with integrated graphics management system ( UCSM ) with all components of the connected server infrastructure.
- Nexus 2232 Fabric Extender - Fabric Line Interconnect in an independent version. Allow you to use ToR-connection scheme of servers, while maintaining a compact cable infrastructure and without increasing the number of control points. Provides 32 x 10GbE ports for connecting servers and 8 x 10GbE ports for connecting to Fabric Interconnect.
- UCS C240 - rack-mounted dual cell servers
- Cisco VIC — network adapters providing two 10GbE ports supporting hardware virtualization
Each server simultaneously connects to two Fabric Interconnect modules, as shown in Figure 6. Only one path is active, the second is needed for fault tolerance. In case of problems, an automatic switch to the backup path will occur, while the server's mac-address will remain unchanged. This feature is called Fabric Failover, is part of UCS and does not require any configuration on the part of the operating system.
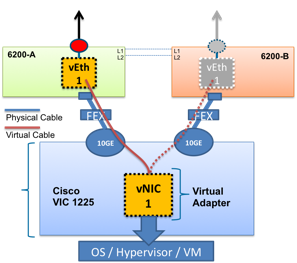
Figure 6. Connection diagram of the network adapter to the Fabric Interconnect
UCS allows you to flexibly control the distribution of traffic between FI. In the described architecture, three virtual interfaces are created on the server's network adapter, each of which is placed in a separate VLAN: vNIC0 - for access by the system administrator to the node, vNIC1 - for information that is exchanged between nodes within the cluster, vNIC2 - for other traffic types. For vNIC1 and vNIC2, support for large frames is included. In the normal mode, each of the interfaces uses the FI that was chosen as the main one when configuring the network adapter. In this example, all vNIC1 traffic will be switched to FI-A, and vNIC2 traffic to FI-B (Figure 7). In the event of failure of one of the FI, all traffic will automatically switch to the second.

Figure 7. Distribution of various types of traffic in the system
The solution uses two Fabric Interconnect modules for redundant control and switching systems. It is recommended to install 16 servers and 2 Fabric Extender modules in each server cabinet.

Figure 8. Scaling a Hadoop Cluster Based on Cisco Hardware
Hadoop cluster is scaled up by adding more Nexus 2232 servers and line cards. Automatic installation and configuration of new nodes can be done using Cisco UCS Director Express software, but this is a completely different story.
You can purchase Cisco products or find out pricing information from Cisco partners in Ukraine and Russia .
They will help you choose and implement the best solution for your business.
Hadoop Basics
To understand how Hadoop works, you need to understand the functions of two main components: HDFS (Hadoop File System) and MapReduce, which will be discussed in this article in more detail. Other possible components of the system are shown in Figure 1.
Figure 1. Hadoop Ecosystem
HDFS is a global file system distributed across a cluster that provides data storage . Files are divided into large blocks, usually 64, 128 or 512 MB, after which they are written to different nodes of the cluster. Thus, files of any size can be placed on HDFS, even exceeding the storage capacity of a single server. Each recorded block is at least twice replicated to other nodes. On the one hand, replication provides fault tolerance. On the other - the possibility of local data processing without a load on the network infrastructure. Cluster disk space with a standard replication ratio should be three times as much as the information you want to keep. It is also necessary to have an additional 25–30% outside HDFS to store intermediate data arising during processing. That is, 1 TB of “useful information” requires 4 TB of “raw space”.
')
MapReduce is a system for distributing data processing tasks among Hadoop cluster nodes. This process, oddly enough, consists of two stages: Map and Reduce . The map runs simultaneously on many nodes and provides intermediate information that Reduce processes to provide the final result.
I will give a simplified example that will help you better understand what is happening. Imagine that you need to count the number of repetitions of words in a newspaper. You will write down every word and tick the box when it appears again in the text. This process will take a lot of time, especially if you get lost and have to start all over again. It will be much easier to divide the newspaper into small pieces and distribute them to friends and acquaintances asking them to perform the counting. Thus, the task will be distributed and each will provide you with some intermediate result. Since the data has already been pre-sorted, your task will be very simple - to sum up the information received. In terms of Hadoop, your friends will perform the Map stage, and you will Reduce. By the way, the intermediate data is called Shuffle, and pieces of the newspaper - Chunk.
The best option is when the Map process works with information on a local disk. If this is not possible due to the high utilization of the node, then the task will be transferred to another node, which will first copy the data, thus increasing the load on the network. If only one copy of the information was stored on HDFS, then remote processing cases would be frequent. By default, HDFS creates three copies of data on different nodes, and this is a good factor for fault tolerance and local computing.
There are two types of nodes: SlaveNodes and MasterNodes . SlaveNode nodes directly record and process information, launch DataNode and TaskTracker daemons . MasterNodes act as managers, they store file system metadata and provide block allocation on HDFS ( NameNode ), and also coordinate MapReduce using the Job Tracker daemon. Each daemon runs on its own Java Virtual Machine (JVM).
Consider the process of writing to HDFS a file divided into two blocks (Figure 2). The client calls the NameNode (NN) with a request on which DataNode (DN) these blocks should be placed on. The NameNode instructs to place Block1 on DN1. In addition, the NameNode commands DN1 to replicate Block1 to DN2, and DN2 to DN6. Similarly, Block2 fits on nodes DN2, DN5 and DN6. Each DN at intervals of several seconds sends a report to NN on the available blocks. If the report does not arrive, the DN is considered lost, which means that there is less by one replica of certain blocks. NN initiates their recovery on other DNs. If, after some time, the missing DN appears again, then NN will select the DN from which extra copies of the data will be deleted.
Figure 2. HDFS write process
Equivalent to NameNode in importance is the JobTracker daemon that manages distributed data processing. If you want to run the program on the entire cluster, then it is sent to MasterNode with the JobTracker daemon. JobTracker determines which data blocks are needed, and selects nodes where the Map stage can be executed locally; in addition, nodes are selected for Reduce. On the SlaveNode side, the process of interacting with JobTracker is performed by the TaskTracker daemon. It tells JobTracker the status of the task. If the task is not completed due to an error or a too long execution time, JobTracker will transfer it to another node. Frequent failure of the task node leads to the fact that it will be placed in the black list.
Figure 3. MapReduce data processing
Thus, for the network infrastructure, the Hadoop cluster generates several types of traffic:
- Heartbeats - service information between MasterNodes and SlaveNodes, which determines the availability of nodes, the status of task execution, sends commands to replicate or delete blocks, etc. Heartbeats load on the network is minimal, and these packets should not be lost because depends on the stability of the cluster.
- Shuffle - data that is transmitted after performing the stage Mar on Reduce. The nature of traffic, from many to one, generates an average load on the network.
- Write to HDFS - write and replicate large amounts of data in large blocks. High network load.
Features of building infrastructure for Hadoop
It is interesting to observe how the computing resources used for Hadoop evolve. In 2009, the configuration of a typical resource-balanced node was a single-duplex two-socket server with four hard disks, dual-core processors and 24 gigabytes of RAM connected to a gigabit Ethernet network. What has changed in five years? Four generations of processors have changed - they have become more powerful, they support more cores and memory, and the 10-gigabit network is widely used in data processing centers. And only the hard drives have not changed. In order to optimally utilize the available processors and memory, modern clusters are built on the basis of dual-unit servers, where you can put a large number of disks. The number of possible operations with the file subsystem, in turn, determines the needs of nodes in network bandwidth. Figure 4 shows data for servers of various configurations, from which it follows that when building a system, it is better to focus on high-speed 10GbE, since the nodes can potentially process more than 1 Gb / s.
Figure 4. I / O subsystem performance based on the number of hard drives
The requirements for local storage are also determined by the fact that Hadoop does not use servers in blade performance, where the ability to install local disks is extremely limited. It is also worth noting that for SlaveNodes they do not use virtualization and the disks are not collected in RAID.
Cisco Common Platform Architecture
Cisco has a complete set of products for building a hardware platform for Hadoop. These are servers, network devices, control systems and automation. Based on Cisco UCS and Nexus, an architecture for working with large amounts of data, called CPA (Common Platform Architecture), was created and tested. This section of the article will describe the features of the network design used in the solution.
Figure 5. Common Platform Architecture components
The solution is based on the following set of equipment:
- Fabric Interconnect 6200 (FI) - high-speed non-blocking universal switches with integrated graphics management system ( UCSM ) with all components of the connected server infrastructure.
- Nexus 2232 Fabric Extender - Fabric Line Interconnect in an independent version. Allow you to use ToR-connection scheme of servers, while maintaining a compact cable infrastructure and without increasing the number of control points. Provides 32 x 10GbE ports for connecting servers and 8 x 10GbE ports for connecting to Fabric Interconnect.
- UCS C240 - rack-mounted dual cell servers
- Cisco VIC — network adapters providing two 10GbE ports supporting hardware virtualization
Each server simultaneously connects to two Fabric Interconnect modules, as shown in Figure 6. Only one path is active, the second is needed for fault tolerance. In case of problems, an automatic switch to the backup path will occur, while the server's mac-address will remain unchanged. This feature is called Fabric Failover, is part of UCS and does not require any configuration on the part of the operating system.
Figure 6. Connection diagram of the network adapter to the Fabric Interconnect
UCS allows you to flexibly control the distribution of traffic between FI. In the described architecture, three virtual interfaces are created on the server's network adapter, each of which is placed in a separate VLAN: vNIC0 - for access by the system administrator to the node, vNIC1 - for information that is exchanged between nodes within the cluster, vNIC2 - for other traffic types. For vNIC1 and vNIC2, support for large frames is included. In the normal mode, each of the interfaces uses the FI that was chosen as the main one when configuring the network adapter. In this example, all vNIC1 traffic will be switched to FI-A, and vNIC2 traffic to FI-B (Figure 7). In the event of failure of one of the FI, all traffic will automatically switch to the second.
Figure 7. Distribution of various types of traffic in the system
The solution uses two Fabric Interconnect modules for redundant control and switching systems. It is recommended to install 16 servers and 2 Fabric Extender modules in each server cabinet.
Figure 8. Scaling a Hadoop Cluster Based on Cisco Hardware
Hadoop cluster is scaled up by adding more Nexus 2232 servers and line cards. Automatic installation and configuration of new nodes can be done using Cisco UCS Director Express software, but this is a completely different story.
You can purchase Cisco products or find out pricing information from Cisco partners in Ukraine and Russia .
They will help you choose and implement the best solution for your business.
Source: https://habr.com/ru/post/245339/
All Articles