Probabilistic programming
Introduction
This publication is the first part of a brief introduction to illustrations in probabilistic programming , which is one of the modern applied areas of machine learning and artificial intelligence. While writing this publication, I was glad to find that recently there was already an article on Habrahabr about probabilistic programming with consideration of applied examples from the field of the theory of knowledge , although, unfortunately, there are still few materials on the Russian-speaking Internet on this topic.
I, the author, Yura Perov, have been doing probabilistic programming for the past two years as part of my main educational and scientific activities. I had a productive acquaintance with probabilistic programming when, as a student at the Institute of Mathematics and Fundamental Informatics of the Siberian Federal University, I undertook an internship at the Laboratory of Computer Science and Artificial Intelligence at the Massachusetts Institute of Technology under the guidance of Professor Joshua Tenenbaum and Dr. Vikas Mansinghi, and then continued at Fac. technical sciences of Oxford University, where at the moment I am a master's student under the guidance of Prof. Frank Wood
I like to define probabilistic programming as a compact , compositional way of representing generating probabilistic models and conducting statistical inference in them, taking into account data using generalized algorithms. Although probabilistic programming does not bring much new fundamental to the theory of machine learning, this approach attracts with its simplicity: “probabilistic generating models to the masses!”
')
"Normal" programming
To get acquainted with probabilistic programming, let's first talk about “ordinary” programming. In “ordinary” programming, the basis is an algorithm, usually deterministic, which allows us to obtain output from the input data according to well-established rules.
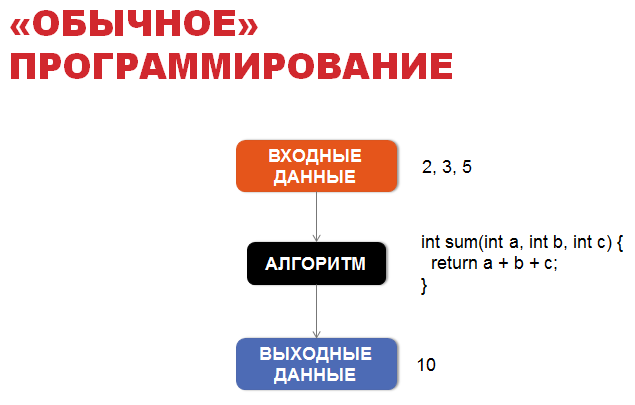
For example, if we have boy Vasya, and we know where he is, where he throws the ball and what are the external conditions (for example, wind power), we will know what window he unfortunately will break in the school building. To do this, it is enough to simulate the simple laws of school physics, which can be easily written as an algorithm.
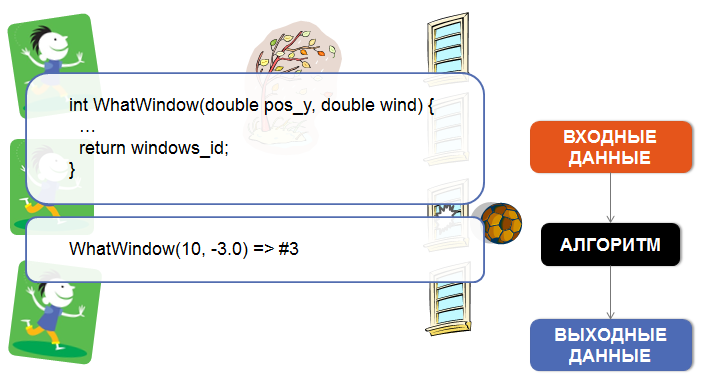
And now probabilistic programming
However, often we only know the result, the outcome, and we are interested in finding out what unknown values led to this particular result? To answer this question using the theory of mathematical modeling, a probabilistic model is created, some of the parameters of which are not precisely defined.
For example, in the case of the boy Vasya, knowing what window he broke, and having a priori knowledge of which window he and his friends usually play football, and knowing the weather forecast for that day, we want to know the a posteriori distribution of the boy’s location Wasi: where did he throw the ball from?

So, knowing the output, we are interested in finding out the most likely values of hidden, unknown parameters.
In the framework of machine learning are considered including generating probabilistic models. In the framework of generating probabilistic models, the model is described as an algorithm, but instead of exact single-valued values of hidden parameters and some input parameters, we use probability distributions on them.
There are more than 15 probabilistic programming languages, a list with a brief description of each of them can be found here . This publication provides example code in the probabilistic Venture / Anglican languages, which have a very similar syntax and which originate from the probabilistic language Church . Church, in turn, is based on the "ordinary" programming language Lisp and Scheme. An interested reader is highly recommended to familiarize themselves with the book “Structure and Interpretation of Computer Programs” , which is one of the best ways to begin acquaintance with the language of “ordinary” programming Scheme.
Bayesian linear regression example
Consider setting a simple probabilistic Bayesian linear regression model in the probabilistic programming language Venture / Anglican as a probabilistic program:
01: [ASSUME t1 (normal 0 1)] 02: [ASSUME t2 (normal 0 1)] 03: [ASSUME noise 0.01] 04: [ASSUME noisy_x (lambda (time) (normal (+ t1 (* t2 time)) noise))] 05: [OBSERVE (noisy_x 1.0) 10.3] 06: [OBSERVE (noisy_x 2.0) 11.1] 07: [OBSERVE (noisy_x 3.0) 11.9] 08: [PREDICT t1] 09: [PREDICT t2] 10: [PREDICT (noisy_x 4.0)] The hidden sought-for parameters are the values of the coefficients t1 and t2 of the linear function x = t1 + t2 * time . We have a priori assumptions about these coefficients, namely, we assume that they are distributed according to the Normal distribution law Normal (0, 1) with an average of 0 and a standard deviation of 1. Thus, we determined in the first two lines of the probabilistic program the prior probability for hidden variables, P (T) . The statement [ASSUME name expression] can be viewed as a definition of a random variable with the name name , which takes the value of a calculated expression (program code) expression , which contains uncertainty.
Probabilistic programming languages (meaning specifically Church, Venture, Anglican), like Lisp / Scheme, are functional programming languages, and use Polish notation when writing expressions for computation. This means that in the expression of the function call, the operator is first located, and only then the arguments: (+ 1 2) , and the function call is surrounded by parentheses. In other programming languages, such as C ++ or Python, this will be equivalent to code 1 + 2 .
In probabilistic programming languages, the expression of a function call can be divided into three different types:
- Call of deterministic procedures (primitive-procedure arg1 ... argN) , which, with the same arguments, always return the same value. Such procedures, for example, include arithmetic operations.
- Call probabilistic (stochastic) procedures (stochastic-procedure arg1 ... argN) , which at each call generate an element from a corresponding distribution at random. Such a call defines a new random variable . For example, a call to a probabilistic procedure (normal 1 10) determines a random variable distributed according to the Normal distribution law Normal (1, sqrt (10)) , and the result of performing each time will be some real number.
- Calling compound procedures (compound-procedure arg1 ... argN) , where compound-procedure is a user-entered procedure using the special expression lambda : (lambda (arg1 ... argN) body) , where body is the procedure body consisting of expressions. In the general case, a composite procedure is a stochastic (non-deterministic) composite procedure, since its body may contain probabilistic procedure calls.
Let's return to the source code in the Venture / Anglican programming language. After the first two lines, we want to set the conditional probability P (X | T) , that is, the conditional probability of the observed variables x1 , x2 , x3 for given values of the hidden variables t1 , t2 and the time parameter.
Before entering directly the observations themselves using the expression [OBSERVE ...], we define a general law for the observed variables xi within our model, namely, we assume that the data of the observed random variables for a given t1 , t2 and a given noise level noise Normal distribution Normal (t1 + t2 * time, sqrt (noise)) with average t1 + t2 * time and standard deviation noise . This conditional probability is defined in lines 3 and 4 of this probability program. noisy_x is defined as a function that takes a time parameter and returns a random value, the expression (normal (+ t1 (* t2 time)) noise) determined by calculation and determined by the values of the random variables t1 and t2 and the variable noise . Note that the expression (normal (+ t1 (* t2 time)) noise) contains uncertainty, therefore, each time we calculate it, we will generally receive a different value.
On lines 5-7, we directly enter the known values x1 = 10.3 , x2 = 11.1 , x3 = 11.9 . An instruction in the form [OBSERVE expression value] captures the observation that the random variable, which takes a value according to the execution of the expression , has assumed the value value .
We will repeat at this stage all that we have done. On lines 1–4, using the instructions of the form [ASSUME ...], we specified the probabilistic model directly: P (T) and P (X | T) . On lines 5-7, we directly specified the values of the observed random variables X known to us using instructions of the form [OBSERVE ...] .
On lines 8-9, we ask the probabilistic programming system for the a posteriori distribution P (T | X) of hidden random variables t1 and t2 . As already mentioned, with a large amount of data and rather complex models, it is impossible to obtain an accurate analytical representation, therefore instructions of the [PREDICT ...] type generate a sample of values of random variables from the a posteriori distribution P (T | X) or its approximation. An instruction of the form [PREDICT expression] generally generates one sample element from the values of a random variable that takes a value according to the execution of the expression . If instructions like [OBSERVE ...] are located in front of instructions like [PREDICT ...] , then the sample will be from the a posteriori distribution (or more precisely, of course, from the a posteriori distribution approximation) due to the previously listed observations.
Note that at the end we can also predict the value of the function x (time) at another point, for example, with time = 4.0 . In this case, the prediction is the generation of a sample from the a posteriori distribution of a new random variable for the values of hidden random variables t1 , t2 and the time = 4.0 parameter.
To generate a sample from the posterior distribution P (T | X) in the Venture programming language, the Metropolis-Hastings algorithm, which belongs to the Monte-Carlo methods according to the Markov circuit, is used as the main one. The generalized conclusion in this case is that the algorithm can be applied to any probabilistic programs written in this probabilistic programming language.
In the video attached below, you can look at the ongoing statistical inference in this model.
(The video shows an example based on the probabilistic programming language Venture.)
At the very beginning we have no data, so we see an a priori distribution of straight lines. By adding point by point (thus, data elements), we see the elements of the sample from the a posteriori distribution.
This concludes the first part of this entry into probabilistic programming.
Materials
Below I will provide recommended links for those who want to learn more about probabilistic programming right now:
- The site of the probable programming language Anglican, which is a fellow Venture and a descendant of Church
- Training course on the probabilistic programming language Anglican .
- A probabilistic programming course read at one of the machine learning schools: part 1 , part 2 and part 3 .
- Course "Design and implementation of probabilistic programming languages."
- The course "Probabilistic generating models of knowledge (one of the applications of probabilistic programming)" .
This publication is based on my undergraduate scientific work , which was defended this summer at the Institute of Mathematics and Fundamental Informatics of the Siberian Federal University. An interested reader will find in it a more detailed and formal introduction to probabilistic programming. At the end there is also a complete bibliography, on the basis of which this publication was also written.
Source: https://habr.com/ru/post/244625/
All Articles