How do we measure the download speed of Yandex. Mail
If your site loads slowly, you risk that people will not appreciate how beautiful it is, or how convenient it is. No one will like it when everything slows down. We regularly add new functionality to Yandex.Mail, sometimes we fix bugs, which means we constantly have new code and new logic. All this directly affects the speed of the interface.

Yandex.Mail is opened every day by millions of people from different parts of the globe. And no one should slow it down, so our work is not complete without various measurements. In this post, we with alexeimoisseev and kurau decided to talk about what metrics we have and what problems they solve. Perhaps this is useful to you.
We measure the time of the first page load with NTA . NTA is used as follows. The speed of the first load (that which the front-end can affect) is measured from PerformanceTiming.domLoading until the moment of full rendering (this is not onload, but the actual time of the first drawing of letters). I specifically emphasize this, as many measure speed from PerformanceTiming.navigationStart . A lot of time can pass between NavigationStart and domLoading, because it includes the time of redirects, dns lookup, connections, etc. And this metric is wrong. For example, for the dns lookup and the connection time, the NOC and the administrators should be responsible, not the front-end developers. Accordingly, it is very important, even in such metrics, to divide the area of responsibility.
')
Modern browsers, including IE9, have NTA support.
But these measurements are not enough. The user mail is loaded only once, and then he opens dozens of letters without reloading the page. And it is important for us to know how quickly this happens.
We make any changes to the page through a single module that allocates timers to different parts (preparation, data request from the server, template making, DOM update) and forwarding them to the consumer modules. Timers are arranged through the usual Date.now (). That is, when clicking on a link, we save the Date.now () value into a variable. After updating the DOM, we again remember Date.now () and calculate the difference with the previous value.
Interestingly, we did not immediately reach the separation of the update process at the stages and in the first versions we measured only the total execution time and the time of the request to the server. Stages and detailed measurements appeared after an unsuccessful release, where we slowed down a lot and could not understand why. Now the update module itself logs all its stages, and you can easily understand the reason for the slowdown: the server began to respond slower or JavaScript runs for too long.
It looks like this:
All timings are collected and calculated. At stages, the difference between the “end” and “start” is not considered, and all calculations are made at the end:
And on the server such records arrive:
Stages of the first boot:
Stages rendering any page:
It should be noted that for fairness, the “total execution time” is not the sum of all metrics, but is computed by a separate metric “start” - “end”. This allows not to lose the upgrade stage. Detailed metrics allow you to quickly find the problem and ideally should be approximately equal to the total execution time. Full equality cannot be obtained due to Promise or setTimeout.
- Ok, now we have metrics and we can send them to the server.
- What next?
- And let's build a schedule!
- What will we consider?
When I hear this phrase, I remember two jokes:
As you already understood, “average” in the sense in which we most often understand it is nothing more than the arithmetic average. In the more general case, it has a special name - “expectation”, which in the discrete case (we will consider it later) is just the arithmetic average. In general, in statistics, “average” refers to a whole family of measures of central tendency, each of which with a certain accuracy characterizes the localization of the distribution of data.
In our situation, we are dealing with data in which there are emissions that strongly affect the arithmetic mean. For clarity, we take the "real" data for the day and build a histogram. Let me remind you that with a sufficiently large amount of data it becomes similar to the distribution density graph.
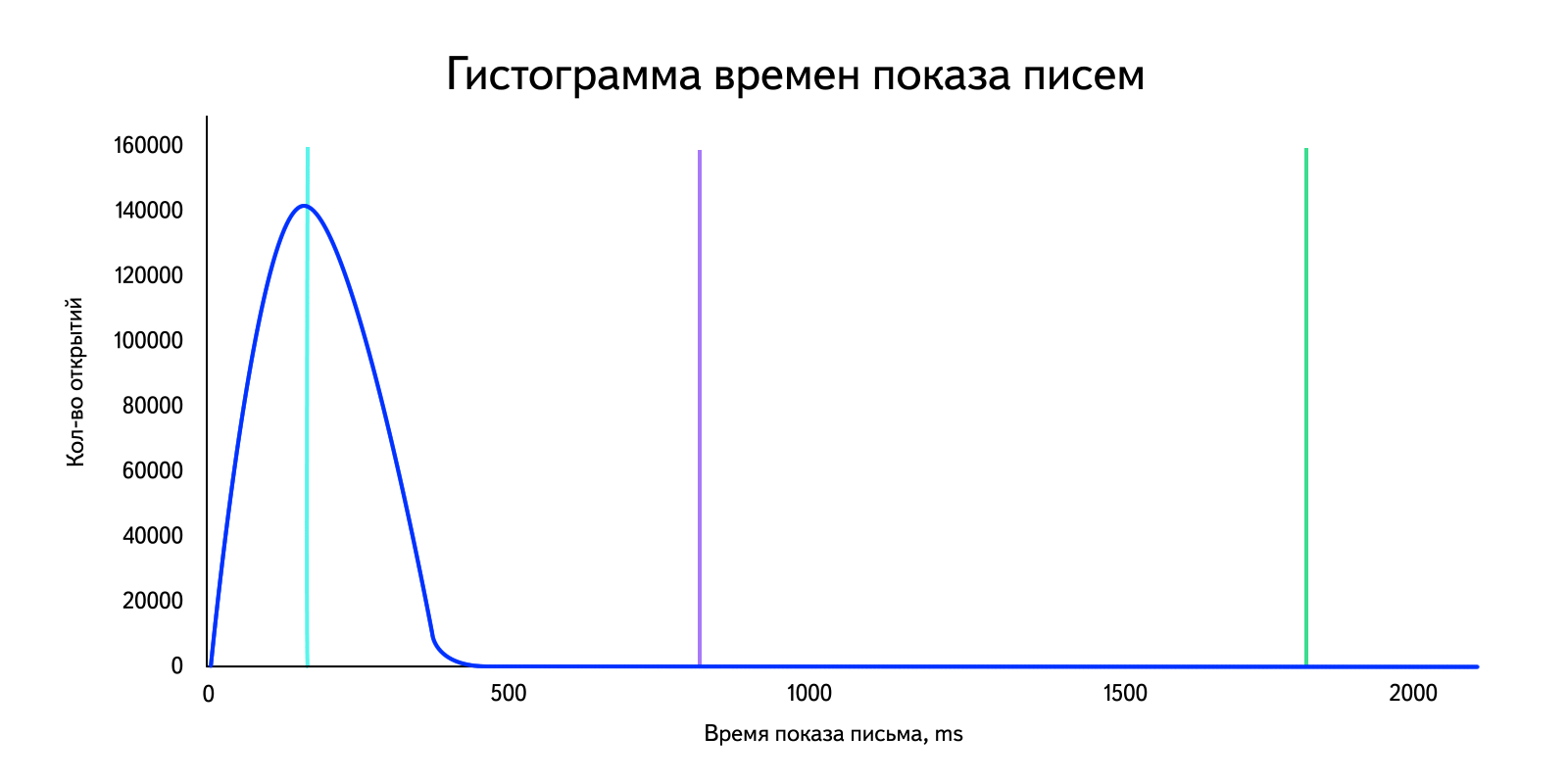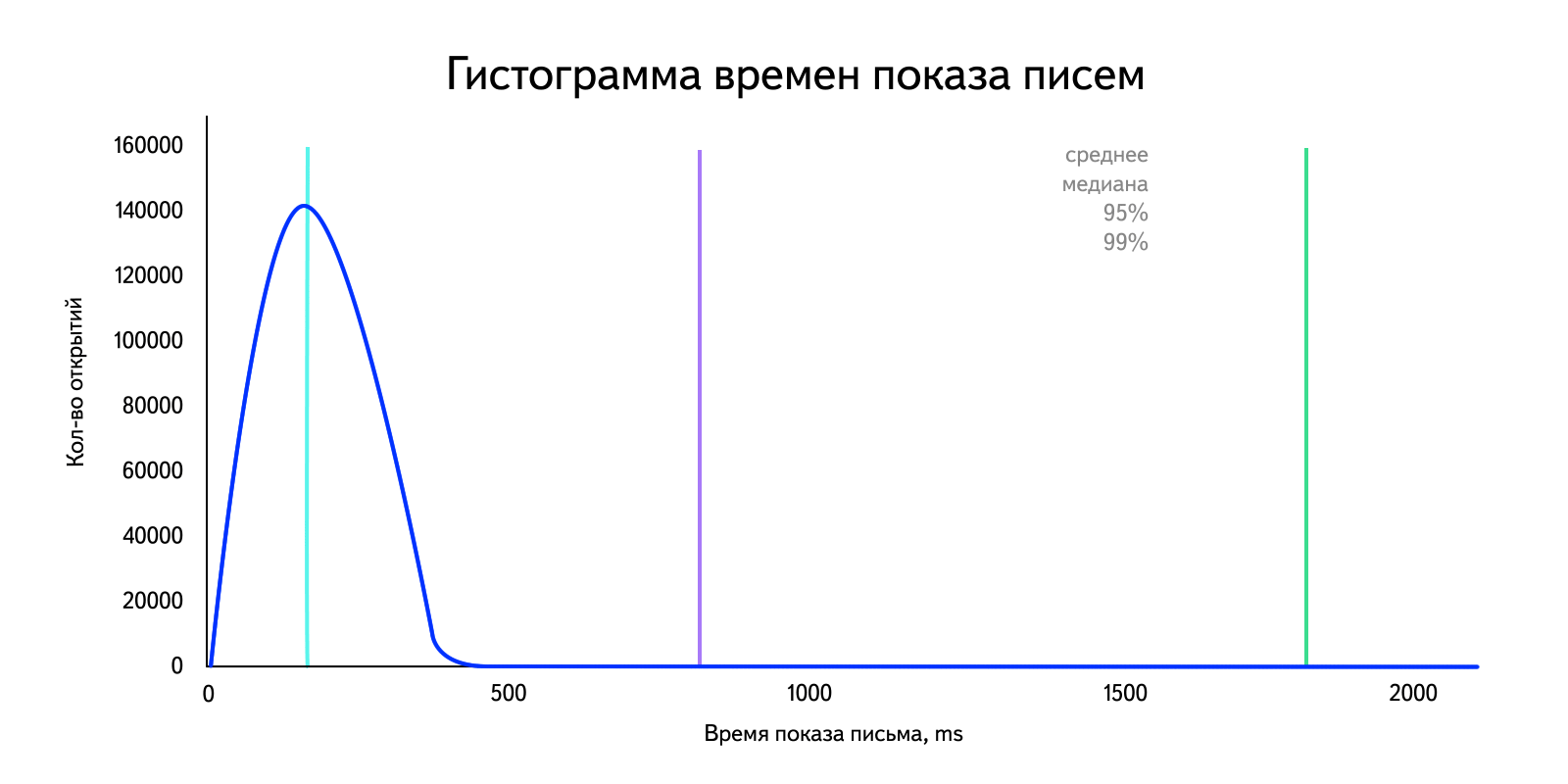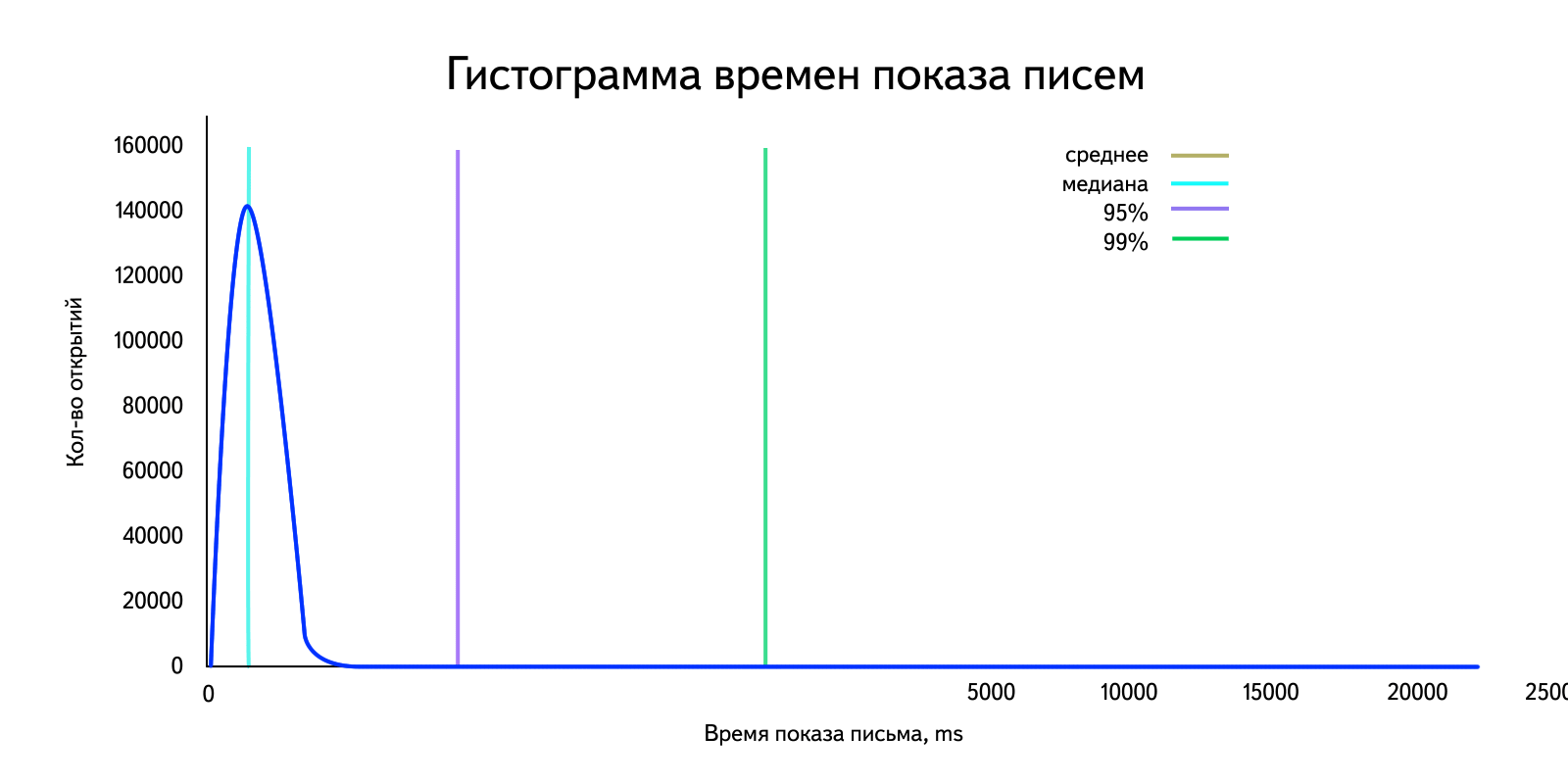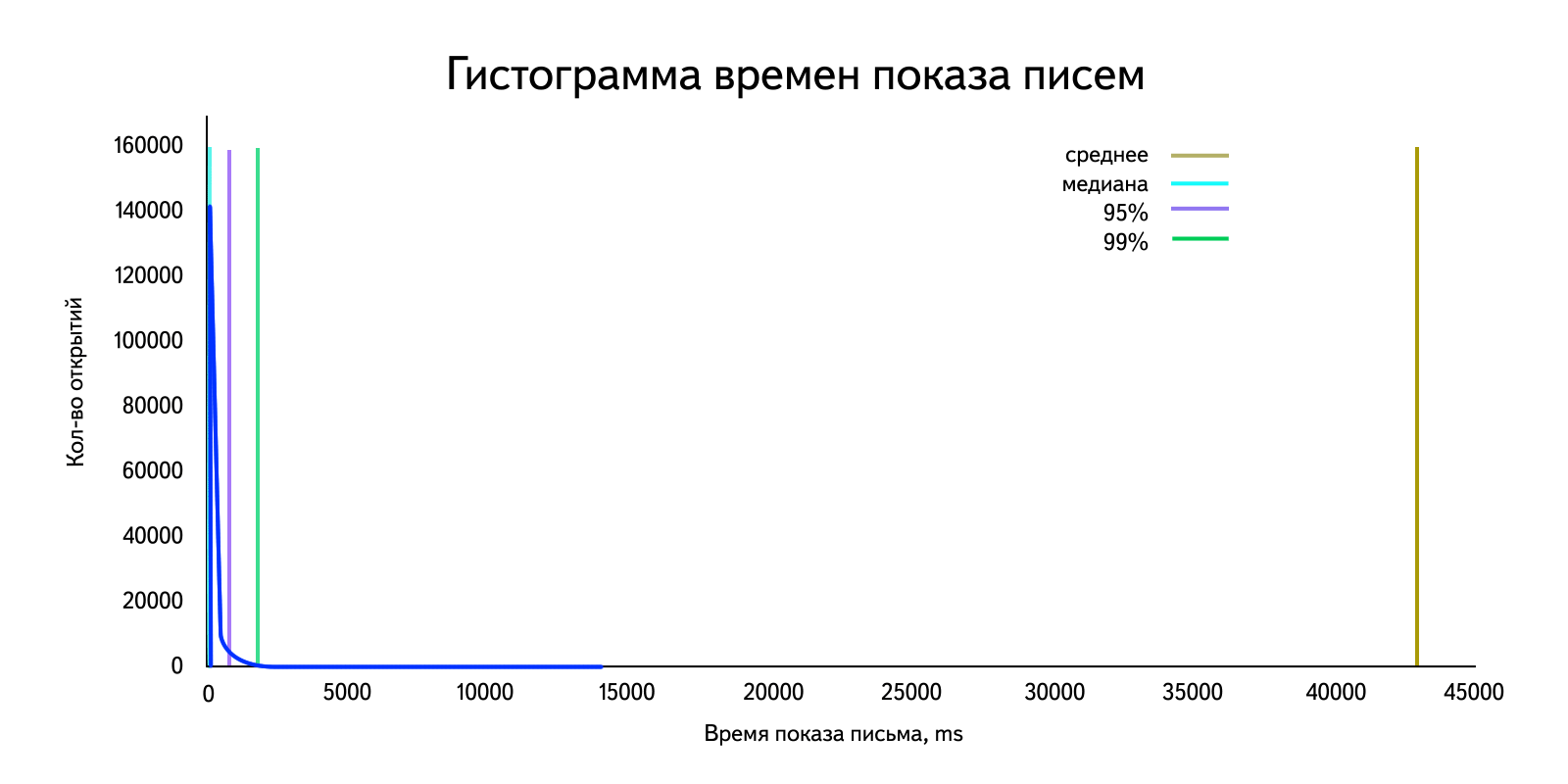
Calculate the arithmetic average:

Horror. I note that depending on the amount of emissions, this value will change. This is clearly seen if we calculate, for example, the arithmetic average for 99% of users, discarding the “large” ones:

The way to estimate a sample is not based on all data, and taking only a subset is often used in the case of data with outliers. To do this, resort to special estimates of the central trend, based on the truncation of the data. This group includes primarily the median (Md).
Median
As you know, the median is the median, not the average value in the sample. If we have numbers 1, 2, 2, 3, 8, 10, 20, then the median is 3, and the average is 6.5. In general, the median perfectly shows how much the average user loads. Even if you divide these groups into “fast” and “slow”, you will still get the correct value.
Suppose we have a median of 1 s. Is it good or bad? And if we accelerate by 100 ms and make 0.9 s, then it will be what?
In case of acceleration or deceleration, the median will, of course, change. But she cannot tell how many users accelerated, and how much slowed down. Browsers can be accelerated, computers can be updated, the code can be optimized, and as a result, you will have one little talking figure.
To understand which group of users was affected by the changes, you can build the following graph: take the time intervals 0–100 ms, 100 ms — 300 ms, 300 ms — 1000 ms, 1000 ms — infinity and consider how many percent of requests fit into each of them .

But even here a problem arises. Every time we had to draw conclusions: it got a little better here and it got a little worse. Isit possible to draw a conclusion right away? simplify the schedule even more?
When you learn how to count metrics and make graphs, everyone will have a desire to build them for EVERYTHING. As a result, we get excellent 100,500 graphs, a bunch of scattered metrics, where everyone shows the boss what is more profitable for him. Poorly? Of course, bad! If you have problems, it is not clear what to look at! Hundreds of graphs - and all correct.
The standard situation: the backend builds its graphs, the DBs are different, the frontend is third. And where is the user? In the end, we all work on it and the schedule should be built from it. How to do it?
APDEX is an integration metric that immediately says: good or bad. The metric works very simply. We select the time interval [0; t], such that if the time the page was displayed fell into it, then the user is happy. We take another interval, (t; 4t] (four times the first), and we believe that if the page is shown during this time, the user is generally satisfied with the speed of work, but not so happy. And we apply the formula:
It turns out a value from zero to one, which, apparently, best shows whether mail works well or poorly.
In the APDEX formula, unhappy or generally satisfied users influence the rating more than happy ones, which means it’s worth working with them. Ideally, the unit should be obtained.
In Yandex, APDEX is used quite widely. He gained such popularity largely because his results can be processed automatically, since this is just one number. On the contrary, in the case of graphics with multiple intervals, only good or bad can be determined by a person.
At the same time, the use of APDEX does not cancel the construction of other graphs. The same percentiles are needed and useful in case of analyzing problems, it will be clear from them what is happening. Thus, it is an auxiliary schedule.
The correct schedule is the one that shows the real user interaction with your site. You can infinitely improve the backend and make it arbitrarily fast, but the user, by and large, does not care. If the front end is slowing down, the backend will not help, and vice versa. You should always go to the search for a problem from the end user.
Take, for example, an abstract user from Ekaterinburg. When we, long ago, began to introduce speed metrics, we found that the farther a user is from Moscow, the slower his mail is. Why? Everything is very simple: our DCs were then in the capital, and the speed of light has a finite value. The signal must travel thousands of kilometers by wire. A simple calculation shows that the distance of 2000 km the light will pass in about 7 ms. In reality, it will take even more time, because the light does not travel in a vacuum or in a straight line, there are many routers along the way, etc. Thus, optimize, do not optimize, and each TCP packet will have a delay of tens of milliseconds. Naturally, in such a situation it is not necessary to invest in code optimization, but in creating a CDN , so that any user will be closer to us.
Sometimes it turns out that you see smooth graphics, and users complain about the brakes. It always means that you either have a measurement error, or you are not measuring it. Metrics need to be stress tested to eliminate errors in the metrics themselves. Moreover, stress testing should be performed not by the means of the metric itself, but from the outside.
Slow backends, add loops, or respond with errors. See how the metrics change at each stage: from the backend to the frontend and browser. This is the only way you can make sure that you measure what you really need.
For example, we in stress testing somehow reached the point that every second request responded with an error. This allowed us to determine whether data is included in the metrics request or not.
It is very important that the optimization is not one-time or occasional. Over the metrics of speed it is necessary to organize the process. To begin, enough real-time graphs and testing of each release for speed. Thus, we will remain honest with ourselves and will understand exactly where we are slow. The streamlined process allows you to track releases in which changes in speed have occurred, which means we can definitely fix it. Even if your team does not have time to purposefully and constantly engage in optimization, you can at least make sure that it does not get worse.
Yandex.Mail is opened every day by millions of people from different parts of the globe. And no one should slow it down, so our work is not complete without various measurements. In this post, we with alexeimoisseev and kurau decided to talk about what metrics we have and what problems they solve. Perhaps this is useful to you.
What is interesting to us
- The first time the interface is loaded.
- The time it takes to draw any block on the page (from a click before it appears in the DOM and is ready to interact with the user).
- The number of abnormally long page rendering and their causes (for example, abnormally long we consider any transition for more than two seconds).
We measure the time of the first page load with NTA . NTA is used as follows. The speed of the first load (that which the front-end can affect) is measured from PerformanceTiming.domLoading until the moment of full rendering (this is not onload, but the actual time of the first drawing of letters). I specifically emphasize this, as many measure speed from PerformanceTiming.navigationStart . A lot of time can pass between NavigationStart and domLoading, because it includes the time of redirects, dns lookup, connections, etc. And this metric is wrong. For example, for the dns lookup and the connection time, the NOC and the administrators should be responsible, not the front-end developers. Accordingly, it is very important, even in such metrics, to divide the area of responsibility.
')
Modern browsers, including IE9, have NTA support.
But these measurements are not enough. The user mail is loaded only once, and then he opens dozens of letters without reloading the page. And it is important for us to know how quickly this happens.
We make any changes to the page through a single module that allocates timers to different parts (preparation, data request from the server, template making, DOM update) and forwarding them to the consumer modules. Timers are arranged through the usual Date.now (). That is, when clicking on a link, we save the Date.now () value into a variable. After updating the DOM, we again remember Date.now () and calculate the difference with the previous value.
Interestingly, we did not immediately reach the separation of the update process at the stages and in the first versions we measured only the total execution time and the time of the request to the server. Stages and detailed measurements appeared after an unsuccessful release, where we slowed down a lot and could not understand why. Now the update module itself logs all its stages, and you can easily understand the reason for the slowdown: the server began to respond slower or JavaScript runs for too long.
It looks like this:
this.timings['look-ma-im-start'] = Date.now();this.timings['look-ma-finish'] = Date.now();All timings are collected and calculated. At stages, the difference between the “end” and “start” is not considered, and all calculations are made at the end:
var totalTime = this.timings['look-ma-finish'] - this.timings['look-ma-im-start'];And on the server such records arrive:
serverResponse=50&domUpdate=60&yate=100What we measure
Stages of the first boot:
- training,
- static loading (HTTP request and parsing),
- execution of modules (declaration of models, types, etc.),
- initialization of base objects
- drawing,
- Execution of event handlers for the first drawing.
Stages rendering any page:
- preparing for the request to the server
- request data from the server
- template making,
- DOM update,
- event handling at view,
- performing callback "after drawing".
It should be noted that for fairness, the “total execution time” is not the sum of all metrics, but is computed by a separate metric “start” - “end”. This allows not to lose the upgrade stage. Detailed metrics allow you to quickly find the problem and ideally should be approximately equal to the total execution time. Full equality cannot be obtained due to Promise or setTimeout.
- Ok, now we have metrics and we can send them to the server.
- What next?
- And let's build a schedule!
- What will we consider?
And let's calculate the average
When I hear this phrase, I remember two jokes:
- On average, a person has less than two hands.
- The deputy’s salary is 100,000 rubles, the doctor’s salary is 10,000 rubles. The average salary is 55,000 rubles.
As you already understood, “average” in the sense in which we most often understand it is nothing more than the arithmetic average. In the more general case, it has a special name - “expectation”, which in the discrete case (we will consider it later) is just the arithmetic average. In general, in statistics, “average” refers to a whole family of measures of central tendency, each of which with a certain accuracy characterizes the localization of the distribution of data.
In our situation, we are dealing with data in which there are emissions that strongly affect the arithmetic mean. For clarity, we take the "real" data for the day and build a histogram. Let me remind you that with a sufficiently large amount of data it becomes similar to the distribution density graph.
Calculate the arithmetic average:
Horror. I note that depending on the amount of emissions, this value will change. This is clearly seen if we calculate, for example, the arithmetic average for 99% of users, discarding the “large” ones:
The way to estimate a sample is not based on all data, and taking only a subset is often used in the case of data with outliers. To do this, resort to special estimates of the central trend, based on the truncation of the data. This group includes primarily the median (Md).
Median
As you know, the median is the median, not the average value in the sample. If we have numbers 1, 2, 2, 3, 8, 10, 20, then the median is 3, and the average is 6.5. In general, the median perfectly shows how much the average user loads. Even if you divide these groups into “fast” and “slow”, you will still get the correct value.
Suppose we have a median of 1 s. Is it good or bad? And if we accelerate by 100 ms and make 0.9 s, then it will be what?
Ok, I sped up the rendering by 100ms.
In case of acceleration or deceleration, the median will, of course, change. But she cannot tell how many users accelerated, and how much slowed down. Browsers can be accelerated, computers can be updated, the code can be optimized, and as a result, you will have one little talking figure.
To understand which group of users was affected by the changes, you can build the following graph: take the time intervals 0–100 ms, 100 ms — 300 ms, 300 ms — 1000 ms, 1000 ms — infinity and consider how many percent of requests fit into each of them .
But even here a problem arises. Every time we had to draw conclusions: it got a little better here and it got a little worse. Is
Honey, I took another schedule
When you learn how to count metrics and make graphs, everyone will have a desire to build them for EVERYTHING. As a result, we get excellent 100,500 graphs, a bunch of scattered metrics, where everyone shows the boss what is more profitable for him. Poorly? Of course, bad! If you have problems, it is not clear what to look at! Hundreds of graphs - and all correct.
The standard situation: the backend builds its graphs, the DBs are different, the frontend is third. And where is the user? In the end, we all work on it and the schedule should be built from it. How to do it?
APDEX
APDEX is an integration metric that immediately says: good or bad. The metric works very simply. We select the time interval [0; t], such that if the time the page was displayed fell into it, then the user is happy. We take another interval, (t; 4t] (four times the first), and we believe that if the page is shown during this time, the user is generally satisfied with the speed of work, but not so happy. And we apply the formula:
(number of happy users + number of generally satisfied / 2) / (number of all users).
It turns out a value from zero to one, which, apparently, best shows whether mail works well or poorly.
In the APDEX formula, unhappy or generally satisfied users influence the rating more than happy ones, which means it’s worth working with them. Ideally, the unit should be obtained.
In Yandex, APDEX is used quite widely. He gained such popularity largely because his results can be processed automatically, since this is just one number. On the contrary, in the case of graphics with multiple intervals, only good or bad can be determined by a person.
At the same time, the use of APDEX does not cancel the construction of other graphs. The same percentiles are needed and useful in case of analyzing problems, it will be clear from them what is happening. Thus, it is an auxiliary schedule.
What is the correct schedule
The correct schedule is the one that shows the real user interaction with your site. You can infinitely improve the backend and make it arbitrarily fast, but the user, by and large, does not care. If the front end is slowing down, the backend will not help, and vice versa. You should always go to the search for a problem from the end user.
Take, for example, an abstract user from Ekaterinburg. When we, long ago, began to introduce speed metrics, we found that the farther a user is from Moscow, the slower his mail is. Why? Everything is very simple: our DCs were then in the capital, and the speed of light has a finite value. The signal must travel thousands of kilometers by wire. A simple calculation shows that the distance of 2000 km the light will pass in about 7 ms. In reality, it will take even more time, because the light does not travel in a vacuum or in a straight line, there are many routers along the way, etc. Thus, optimize, do not optimize, and each TCP packet will have a delay of tens of milliseconds. Naturally, in such a situation it is not necessary to invest in code optimization, but in creating a CDN , so that any user will be closer to us.
One more thing
Sometimes it turns out that you see smooth graphics, and users complain about the brakes. It always means that you either have a measurement error, or you are not measuring it. Metrics need to be stress tested to eliminate errors in the metrics themselves. Moreover, stress testing should be performed not by the means of the metric itself, but from the outside.
Slow backends, add loops, or respond with errors. See how the metrics change at each stage: from the backend to the frontend and browser. This is the only way you can make sure that you measure what you really need.
For example, we in stress testing somehow reached the point that every second request responded with an error. This allowed us to determine whether data is included in the metrics request or not.
Conclusion
It is very important that the optimization is not one-time or occasional. Over the metrics of speed it is necessary to organize the process. To begin, enough real-time graphs and testing of each release for speed. Thus, we will remain honest with ourselves and will understand exactly where we are slow. The streamlined process allows you to track releases in which changes in speed have occurred, which means we can definitely fix it. Even if your team does not have time to purposefully and constantly engage in optimization, you can at least make sure that it does not get worse.
Source: https://habr.com/ru/post/244243/
All Articles