Script on NodeJS for Backup data: Start
I have long been looking for a program to save my projects. In this case, the mandatory requirement was:
1. Save only changed files in the storage;
2. Pack the changed files;
3. To be free.
However, the search did not give anything. Rather, the search gave, but usually one of the items was missing. Therefore, I decided to write my own, and at the same time “feel live” NodeJS. 2 days wrote. And even screwed encryption to the program. That did not cause any special difficulties, since the encryption module is included in the standard delivery of the node. At the same time, the packaging, encryption, and storage management modules are extensible So that you can simply add new features, expanding the functionality. In the current version, saving works only in the file system, without packaging, but with encryption.
')
View help on the use here .
This could be the end - it's done. But there is one drawback - the program works SYNCHRONNO. And although it works quite quickly (if you do not save gigabytes of information), but still the node is focused on ASYNCHRONOUS work. So I looked at the Screencast on Node.JS and decided to do everything on the "right", taking into account the features of the node.
Since I decided to write “correctly”, I will start with a general scheme of work:
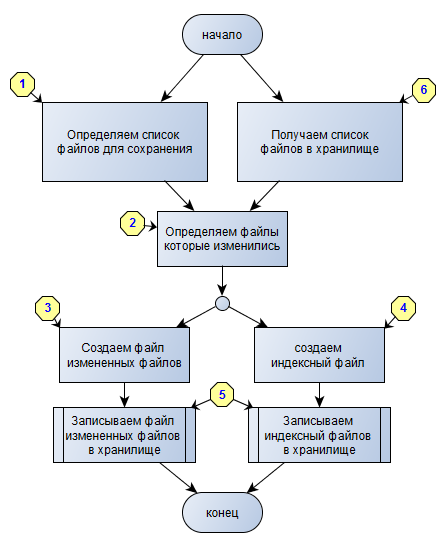
The diagram clearly shows which operations can be performed in parallel, and which cannot.
Let's start to implement the blocks. Each block will be written in a separate file so that it is clearer and clearer.
The task is simple - we have a directory at the entrance, we need to get the following properties for each element: size, checksum (we will use md5), date of change. This we need to further determine the changed elements. I write items, not files, not by chance. We will determine these values for directories. The directory size is the size of all nested items. The directory checksum is the checksum of all checksums of the children. Accordingly, in order to understand whether there have been changes in the directory or not, it will be enough just to compare the checksums of this directory in the storage and on the disk.
When measuring the speed of the asynchronous implementation always wins. In order to speed up the work process, I did a checksum calculation by redirecting flows using the pipe () function. The calculation was that then the reading of the file and the calculation will take place not in javascrip, but in the core of the node. However, this step did not justify itself. For some reason, a variant of the form:
Although I was hoping for a different result. I hope in the comments I will point out errors. I also imposed a limit on the number of simultaneously processed files for checksum calculation. Great value does not give a significant gain in speed, but at a certain threshold value (I had it = 2.5 thousand), the program fell with an error when creating a new stream to open a file:
This block is fully implemented in javascript and we will not consider it in detail. There is nothing difficult in comparing two objects with attributes of elements. It is worth mentioning that it is enough for us to compare the old and new attributes of a directory in order to understand whether there are changes in it or not. And do not forget that if the element is not in the old version, it means that it was added, which means it should be included in the list of changed elements.
All sources mentioned in the article are here . Also in the archive there is a test.js file for running time measurement tests (just do not forget to change the path to the one you have on the disk).
In the next article we will look at block number 3. There we will use Transform streams for packing / unpacking and encrypting / decrypting data. And also we will make an interface for working with different repositories of backups.
psUpdated article. The comments given in the comments were taken into account.
Link to all source codes - these are all source codes mentioned (and not mentioned) in the following articles: Script for NodeJS for Backup and data: Start , Script for NodeJS for Backup for data: End .
Help on the manufacturer's website
The link for downloading the program is a link to the final program. Unlike the source code, the data in this archive will change. In particular, it is planned to add support for FTP and yandex-disk. Currently, the work with the file system is supported as storage - i.e. saving occurs in the specified folder.
1. Save only changed files in the storage;
2. Pack the changed files;
3. To be free.
However, the search did not give anything. Rather, the search gave, but usually one of the items was missing. Therefore, I decided to write my own, and at the same time “feel live” NodeJS. 2 days wrote. And even screwed encryption to the program. That did not cause any special difficulties, since the encryption module is included in the standard delivery of the node. At the same time, the packaging, encryption, and storage management modules are extensible So that you can simply add new features, expanding the functionality. In the current version, saving works only in the file system, without packaging, but with encryption.
')
View help on the use here .
This could be the end - it's done. But there is one drawback - the program works SYNCHRONNO. And although it works quite quickly (if you do not save gigabytes of information), but still the node is focused on ASYNCHRONOUS work. So I looked at the Screencast on Node.JS and decided to do everything on the "right", taking into account the features of the node.
Since I decided to write “correctly”, I will start with a general scheme of work:
The diagram clearly shows which operations can be performed in parallel, and which cannot.
Let's start to implement the blocks. Each block will be written in a separate file so that it is clearer and clearer.
1. Determine the list of files to save.
The task is simple - we have a directory at the entrance, we need to get the following properties for each element: size, checksum (we will use md5), date of change. This we need to further determine the changed elements. I write items, not files, not by chance. We will determine these values for directories. The directory size is the size of all nested items. The directory checksum is the checksum of all checksums of the children. Accordingly, in order to understand whether there have been changes in the directory or not, it will be enough just to compare the checksums of this directory in the storage and on the disk.
Synchronous implementation of this functionality
(function(){ // var fs = require('fs'); var path = require('path'); var crypto = require('crypto'); // function _get_attributes(itemName,basePath) { // //console.info(basePath,"\t\t\t",itemName); // var retSize = 0; // var retHash = crypto.createHash('md5'); // . var retInfo; // var filepath = path.join(basePath,itemName); // var stat = fs.statSync(filepath); // if( stat.isDirectory() ) { // retInfo = {}; // var items = fs.readdirSync(filepath); var hashs = []; for(var i in items) { // var attr = _get_attributes(items[i],filepath); // retSize += attr[0]; // hashs.push(attr[1]); // retInfo[ items[i] ] = attr; } // hashs.sort(); for(var j in hashs) { retHash.update(hashs[j]); } } else { // retSize = stat.size; // // var buffer = new Buffer(64*1024); // var fdr = fs.openSync(filepath, 'rs'); while(true) { // var bytesRead = fs.readSync(fdr, buffer,0,buffer.length); if(bytesRead>0) { // retHash.update(buffer.slice(0,bytesRead)); } else { // break; } } // fs.closeSync(fdr); // retInfo = stat.mtime.toISOString(); } // // base64 '='. return [retSize,retHash.digest('base64').replace(/=/g,''),retInfo]; } // module.exports = function(_basepath) { return _get_attributes('',_basepath); } })(); Asynchronous implementation of this functionality.
// var fs = require('fs'); var path = require('path'); var crypto = require('crypto'); var async = require('async'); // . var qHashFile = async.queue(function (args, cb) { // var oHash = crypto.createHash('md5'); // var rs = fs.createReadStream(args.filePath); // - , rs.on('error', args.callback); // rs.on('data', function (data) { oHash.update(data); }); // rs.on('end', function () { // args.callback(null,oHash.digest('base64').replace(/=/g,'')); // cb(); }); }, 16); // // function getAttrDir(dirPath,callback) { //console.log("getAttrDir",dirPath); // fs.readdir(dirPath,function(err,items) { // , if (err) return callback(err); // var ret={ size : 0, // items:{} // }; var hashs=[]; // async.each(items, function(itemName,cb){ // getAttrItem(path.join(dirPath,itemName),function(err,attr){ // , if (err) return callback(err); // ret.size += attr.size; // ret.items[itemName] = attr; // hashs.push(attr.hash); // cb(); }); }, function(err) { // , if (err) return callback(err); // , // hashs.sort(); var oHash = crypto.createHash('md5'); hashs.forEach(function(hash) { oHash.update(hash); }); // ret.hash = oHash.digest('base64').replace(/=/g,''); // //console.log("getHashFile",dirPath,ret); callback(null,ret); }); }); } // function getAttrItem(itemPath,callback) { // fs.stat(itemPath, function(err,stat) { // , if (err) return callback(err); // if( stat.isDirectory() ) { // getAttrDir(itemPath,callback); } else { // qHashFile.push( { filePath : itemPath, callback : function(err,hash) { // callback(err,{ size : stat.size, // hash : hash, // mtime : stat.mtime.toISOString() // }); } }, function(err){ // , if(err) return callback(err); }); } }); } // module.exports = getAttrItem; When measuring the speed of the asynchronous implementation always wins. In order to speed up the work process, I did a checksum calculation by redirecting flows using the pipe () function. The calculation was that then the reading of the file and the calculation will take place not in javascrip, but in the core of the node. However, this step did not justify itself. For some reason, a variant of the form:
// var oHash = crypto.createHash('md5'); // var rs = fs.createReadStream(args.filePath); // - , rs.on('error', args.callback); // rs.on('data', function (data) { oHash.update(data); }); // rs.on('end', function () { // args.callback(null,oHash.digest('base64').replace(/=/g,'')); // cb(); }); Always won the option: // var oHash = crypto.createHash('md5'); oHash.setEncoding('base64'); // var rs = fs.createReadStream(args.filePath); // rs.on('end', function() { // oHash.end(); // args.callback(null,oHash.read().replace(/=/g,'')); // cb(); }); // rs.pipe(oHash); Although I was hoping for a different result. I hope in the comments I will point out errors. I also imposed a limit on the number of simultaneously processed files for checksum calculation. Great value does not give a significant gain in speed, but at a certain threshold value (I had it = 2.5 thousand), the program fell with an error when creating a new stream to open a file:
events.js:72 throw er; // Unhandled 'error' event ^ Error: EMFILE, open '<- >' 2. Determine the files that have changed.
This block is fully implemented in javascript and we will not consider it in detail. There is nothing difficult in comparing two objects with attributes of elements. It is worth mentioning that it is enough for us to compare the old and new attributes of a directory in order to understand whether there are changes in it or not. And do not forget that if the element is not in the old version, it means that it was added, which means it should be included in the list of changed elements.
All sources mentioned in the article are here . Also in the archive there is a test.js file for running time measurement tests (just do not forget to change the path to the one you have on the disk).
In the next article we will look at block number 3. There we will use Transform streams for packing / unpacking and encrypting / decrypting data. And also we will make an interface for working with different repositories of backups.
psUpdated article. The comments given in the comments were taken into account.
- Removed shielding of js code, as indicated that it is already shielded .
- Code rewritten using the library async . With it, the code became pleasing to the eye (although it could not overtake my initial version on the tests :)). I used the async.each method to work with the list of directory entries. As well as the async.queue method for calculating checksums of files.
- Added error handling when creating a stream for reading. That allowed to make sure that the error occurs precisely because of the creation of a large number of these same stream for reading files.
- Now attributes are returned in the form of an object with talking names (size, hash, items, mdate), and not in the form of arrays with obscure indices.
- The code itself tried to make it more uniform.
Link to all source codes - these are all source codes mentioned (and not mentioned) in the following articles: Script for NodeJS for Backup and data: Start , Script for NodeJS for Backup for data: End .
Help on the manufacturer's website
The link for downloading the program is a link to the final program. Unlike the source code, the data in this archive will change. In particular, it is planned to add support for FTP and yandex-disk. Currently, the work with the file system is supported as storage - i.e. saving occurs in the specified folder.
Source: https://habr.com/ru/post/244223/
All Articles