New optimizations for x86 in the expected GCC 5.0
So, the actual development of new optimizations in GCC 5.0 can be considered complete. The GCC 5.0 product is now in the stage3 phase, that is, there is a refinement of the already implemented optimizations. In this and subsequent articles I will discuss the optimizations implemented in GCC 5.0 for x86 and their impact on the performance of programs for the Intel Atom and Intel Core line processors . Today we will talk about vectorization of group memory calls. In subsequent articles, I will talk about accelerations in the 32-bit PIC mode and additional vectorization gain.
As you have probably guessed, the vectorization of group memory calls has been significantly improved in GCC 5.0. The group memory reference is an iterable sequence of calls. For example:
iterated over i is a group of loads from memory of length 3. The length of the group of calls to memory is the distance between the lowest and highest addresses in the group. For the example above, this is (i + 2) - (i) + 1 = 3
The number of memory hits in a group does not exceed its length. For example:
iterated on i is a group of length 3, despite the fact that there are only 2 memory references.
')
GCC 4.9 vectorizes groups where length is a power of 2 (2, 4, 8 ...).
GCC 5.0 vectorizes groups where the length is 3 or degree 2 (2, 4, 8 ...). Other lengths are not vectorized, as they are very rare in real applications.
Most often, the vectorization of the memory reference group is used when working with arrays of structures.
1. Converting images, say, in the structure of RGB. An example .
2. Work with N-dimensional coordinates (say, to normalize three-dimensional points). An example .
3. Multiplication of vectors by a constant matrix:
In general, in GCC 5.0 (compared to 4.9)
The following tables provide an estimate of the performance gains when using GCC 5.0 on byte structures (the largest number of elements in a vector) compared with GCC 4.9. The following cycle is used for evaluation:
Where:
Such a matrix is used to minimize computations within the cycle to relatively fast additions and subtractions.
Compile options "-Ofast" plus "-march = slm" for Silvermont , "-march = core-avx2" for Haswell, and all combinations -DLDGSIZE = {1,2,3,4,8} -DSTGSIZE = {1,2 3,4,8}
The performance gain of GCC 5.0 compared to 4.9 (how many times it accelerated, the more - the better).
Silvermont : Intel Atom (TM) CPU C2750 @ 2.41GHz
Gain up to 6.5 times!
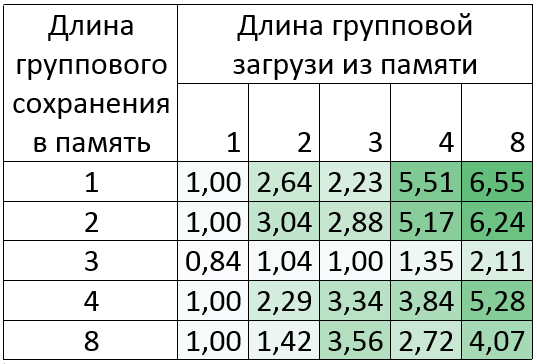
As can be seen from the table, the results for groups in the memory of length 3 are not very good. This is because such a conversion requires 8 instructions "pshufb", the duration of which in Silvermont is about 5 cycles. Despite this, the vectorization of other commands in the cycle may give a greater increase. This can be seen in the example of a group of downloads from memory lengths of 2, 3, 4 and 8.
Example GCC assembler for a group of downloads from memory length 2:
Here, as in the Haswell example below, it is worth noting that most of the ".LC" constants will be invariants in a loop, but only if there are free registers. Otherwise, they will have to be installed directly in phufb: "pshufb .LC0,% xmm3". Such pshufb will be larger by the size of the address and potentially take longer to execute.
Haswell : Intel Core (TM) i7-4770K CPU @ 3.50GHz
Gain up to 3 times!

In this case, the results for groups in memory of length 3 are much better, since in Haswell the instruction “pshufb” is executed in 1 clock cycle. Moreover, the greatest increase here is precisely for the implemented vectorization of groups of memory calls of length 3.
Example GCC assembler for a group of downloads from memory length 2:
From the above, the conclusion follows: using GCC 5.0, you can significantly speed up the performance of applications similar to those described above. You can start trying now! Most edits are planned to be ported to Android NDK.
Compilers used in measurements:
You can download the example on which measurements were taken from the original text of the article in English .
As you have probably guessed, the vectorization of group memory calls has been significantly improved in GCC 5.0. The group memory reference is an iterable sequence of calls. For example:
x = a[i], y = a[i + 1], z = a[i + 2] iterated over i is a group of loads from memory of length 3. The length of the group of calls to memory is the distance between the lowest and highest addresses in the group. For the example above, this is (i + 2) - (i) + 1 = 3
The number of memory hits in a group does not exceed its length. For example:
x = a[i], z = a[i + 2] iterated on i is a group of length 3, despite the fact that there are only 2 memory references.
')
GCC 4.9 vectorizes groups where length is a power of 2 (2, 4, 8 ...).
GCC 5.0 vectorizes groups where the length is 3 or degree 2 (2, 4, 8 ...). Other lengths are not vectorized, as they are very rare in real applications.
Most often, the vectorization of the memory reference group is used when working with arrays of structures.
1. Converting images, say, in the structure of RGB. An example .
2. Work with N-dimensional coordinates (say, to normalize three-dimensional points). An example .
3. Multiplication of vectors by a constant matrix:
a[i][0] = 7 * b[i][0] - 3 * b[i][1]; a[i][1] = 2 * b[i][0] + b[i][1]; In general, in GCC 5.0 (compared to 4.9)
- A vectorization of a group of memory hits of length 3 has appeared.
- Significantly improved vectorization of a group of downloads from memory for any length
- They began to use techniques of vectorization of groups of memory hits that are optimal for a particular x86 processor.
The following tables provide an estimate of the performance gains when using GCC 5.0 on byte structures (the largest number of elements in a vector) compared with GCC 4.9. The following cycle is used for evaluation:
int i, j, k; byte *in = a, *out = b; for (i = 0; i < 1024; i++) { for (k = 0; k < STGSIZE; k++) { byte s = 0; for (j = 0; j < LDGSIZE; j++) s += in[j] * c[j][k]; out[k] = s; } in += LDGSIZE; out += STGSIZE; } Where:
- c is a constant matrix:
const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1}; Such a matrix is used to minimize computations within the cycle to relatively fast additions and subtractions.
- in and out - pointers to global arrays "a [1024 * LDGSIZE]" and "b [1024 * STGSIZE]"
- byte is unsigned char
- LDGSIZE and STGSIZE are macros that define the length of a group of loadings from memory and save to memory, respectively.
Compile options "-Ofast" plus "-march = slm" for Silvermont , "-march = core-avx2" for Haswell, and all combinations -DLDGSIZE = {1,2,3,4,8} -DSTGSIZE = {1,2 3,4,8}
The performance gain of GCC 5.0 compared to 4.9 (how many times it accelerated, the more - the better).
Silvermont : Intel Atom (TM) CPU C2750 @ 2.41GHz
Gain up to 6.5 times!
As can be seen from the table, the results for groups in the memory of length 3 are not very good. This is because such a conversion requires 8 instructions "pshufb", the duration of which in Silvermont is about 5 cycles. Despite this, the vectorization of other commands in the cycle may give a greater increase. This can be seen in the example of a group of downloads from memory lengths of 2, 3, 4 and 8.
Example GCC assembler for a group of downloads from memory length 2:
| GCC 4.9 | GCC 5.0 |
| movdqa .LC0 (% rip),% xmm7 movdqa .LC1 (% rip),% xmm6 movdqa .LC2 (% rip),% xmm5 movdqa .LC3 (% rip),% xmm4 movdqu a (% rax,% rax),% xmm1 movdqu a + 16 (% rax,% rax),% xmm0 movdqa% xmm1,% xmm3 pshufb% xmm7,% xmm3 movdqa% xmm0,% xmm2 pshufb% xmm5,% xmm1 pshufb% xmm6,% xmm2 pshufb% xmm4,% xmm0 por% xmm2,% xmm3 por% xmm0,% xmm2 | movdqa .LC0 (% rip),% xmm3 movdqu a (% rax,% rax),% xmm0 movdqu a + 16 (% rax,% rax),% xmm1 movdqa% xmm3,% xmm4 pand% xmm0,% xmm3 psrlw $ 8,% xmm0 pand% xmm1,% xmm4 psrlw $ 8,% xmm1 packuswb% xmm4,% xmm3 packuswb% xmm1,% xmm0 |
Haswell : Intel Core (TM) i7-4770K CPU @ 3.50GHz
Gain up to 3 times!
In this case, the results for groups in memory of length 3 are much better, since in Haswell the instruction “pshufb” is executed in 1 clock cycle. Moreover, the greatest increase here is precisely for the implemented vectorization of groups of memory calls of length 3.
Example GCC assembler for a group of downloads from memory length 2:
| GCC 4.9 | GCC 5.0 |
| vmovdqa .LC0 (% rip),% ymm7 vmovdqa .LC1 (% rip),% ymm6 vmovdqa .LC2 (% rip),% ymm5 vmovdqa .LC3 (% rip),% ymm4 vmovdqu a (% rax,% rax),% ymm0 vmovdqu a + 32 (% rax,% rax),% ymm2 vpshufb% ymm7,% ymm0,% ymm1 vpshufb% ymm5,% ymm0,% ymm0 vpshufb% ymm6,% ymm2,% ymm3 vpshufb% ymm4,% ymm2,% ymm2 vpor% ymm3,% ymm1,% ymm1 vpor% ymm2,% ymm0,% ymm0 vpermq $ 216,% ymm1,% ymm1 vpermq $ 216,% ymm0,% ymm0 | vmovdqa .LC0 (% rip),% ymm3 vmovdqu a (% rax,% rax),% ymm0 vmovdqu a + 32 (% rax,% rax),% ymm2 vpand% ymm0,% ymm3,% ymm1 vpsrlw $ 8,% ymm0,% ymm0 vpand% ymm2,% ymm3,% ymm4 vpsrlw $ 8,% ymm2,% ymm2 vpackuswb% ymm4,% ymm1,% ymm1 vpermq $ 216,% ymm1,% ymm1 vpackuswb% ymm2,% ymm0,% ymm0 vpermq $ 216,% ymm0,% ymm0 |
Compilers used in measurements:
You can download the example on which measurements were taken from the original text of the article in English .
Source: https://habr.com/ru/post/244137/
All Articles