Interactive voice editing of text with the help of new speech technologies from Yandex
Today, our Dictation application for interactive voice writing and editing has appeared in the AppStore and Google Play . His main task is to demonstrate some of the new features of the Yandex speech technology complex. It is about what our speech recognition and synthesis technologies are interesting and unique to, I want to tell you in this post.
A couple of words, so that you understand what it will be about. Yandex has long been providing a free mobile API that can be used, for example, to recognize addresses and voice search queries. During this year we were able to bring its quality to almost the same level at which people themselves understand such requests and replicas. And now we are taking the next step - a model for recognizing free speech on any topic.
')
In addition, our speech synthesis supports the emotions in the voice. And, as far as we know, this is still the first commercially available speech synthesis with such an opportunity.
About all this, as well as some other features of SpeechKit: about voice activation, automatic placement of punctuation signs and recognition of semantic objects in the text - read below.
SpeechKit's speech recognition system works with different types of text, and last year we worked on expanding its scope. For this, we have created a new language model, while the largest, to recognize short texts on any topic.
Over the past year, the relative share of mistakenly recognized words ( Word Error Rate ) has decreased by 30%. For example, today SpeechKit correctly recognizes 95% of addresses and geographic objects, coming close to a person who understands 96–98% of words he heard. The completeness of recognition of a new model for dictation of various texts now amounts to 82%. With this level, you can create a complete solution for end users, which we wanted to show by the example of dictation.
Initially, SpeechKit worked only for search queries: general subjects and geo-navigation. Although even then we planned to make not just an additional input tool, a “voice” keyboard, but a universal interface that would completely replace any interaction with the system with live conversation.
For this it was necessary to learn to recognize any speech, texts on an arbitrary topic. And we started working on a separate language model for this, which was several times larger than the existing geosteering and general search models.
Such a size of the model set new conditions in terms of computing resources. For each frame are considered several thousand variants of recognition - and the more we have time, the higher the quality. And the system should work in a stream, in real time, so all calculations need to be optimized dynamically. Experimented, tried, searched for an approach: accelerations were achieved, for example, by changing the library of linear algebra.

But the most important and difficult thing was to collect enough correct data suitable for teaching streaming speech. Currently, about 500 hours of manually transcribed speech are used to train the acoustic model. This is not such a big base - for comparison, the popular scientific building of Switchboard , which is often used for research purposes, contains about 300 hours of live, spontaneous conversations. Of course, an increase in the base contributes to the growth of the quality of the model being taught, but we focus on the correct preparation of data and model the transcriptions more accurately, which allows us to study on a relatively small base with an acceptable quality.
A few words about how the recognition module works (we talked about this in detail some time ago). The stream of recorded speech is cut into frames of 20 ms, the signal spectrum is scaled and after a series of transformations for each frame, the MFCC is obtained.

The coefficients arrive at the input of the acoustic model, which calculates the probability distribution for approximately 4000 senons in each frame. Senon is the beginning, middle, or end of a phoneme.
SpeechKit's acoustic model is built on a combination of hidden Markov models and a deep forward-propagation neural network ( feedforward DNN ). This is a proven solution, and in the last article we described how the rejection of Gaussian mixtures in favor of DNN gave an almost double leap in quality.

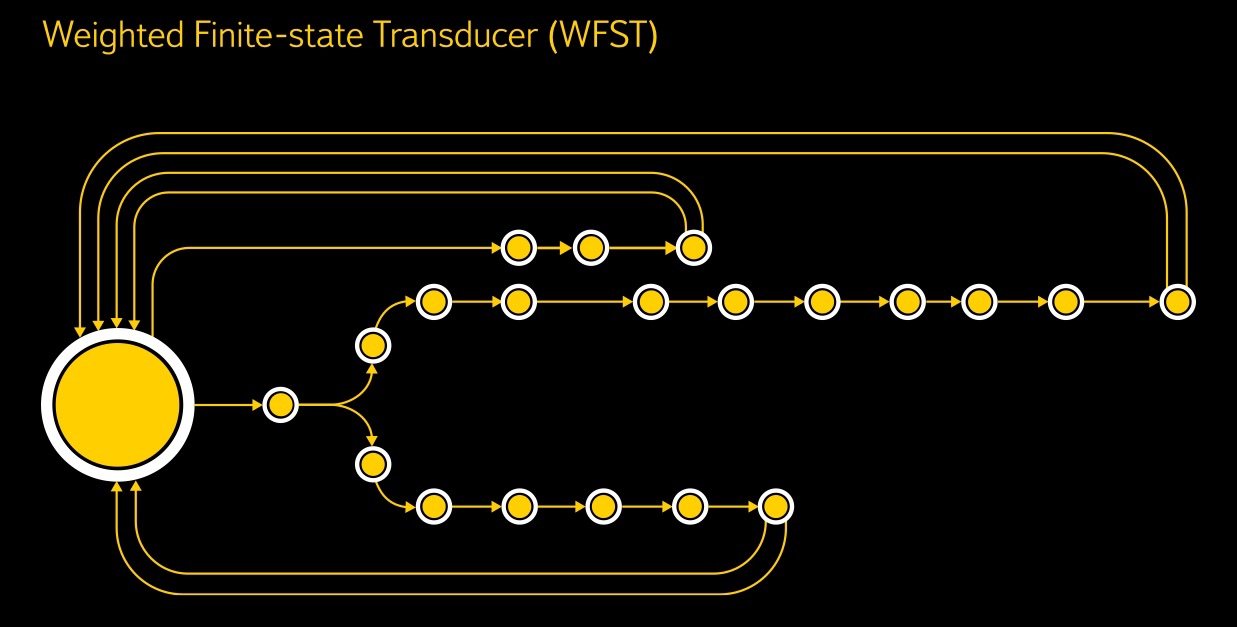
Then the first language model enters: several WFST - weighted finite transducers - turn senons into context-dependent phonemes, and from them entire words are constructed using the dictionary of pronunciations, with hundreds of hypotheses being obtained for each word.
Final processing takes place in the second language model. The RNN , a recurrent neural network, is connected to it, and this model ranks the hypotheses obtained, helping to select the most plausible option. A recurrent type network is especially effective for a language model. Defining the context of each word, it can take into account the influence not only of the closest words, as in the neural network of direct propagation (for example, for the trigram model, these are the two preceding words), but also further away, as if “remembering” them.

Recognition of long connected texts is available in the SpeechKit Cloud and SpeechKit Mobile SDK - to use the new language model, in the query parameters you need to select the theme “notes”.
The second key component of the voice interface is the voice activation system, which triggers the desired action in response to the key phrase. Without it, it will not be possible to fully untie the hands of the user. For SpeechKit, we have developed our voice activation module. The technology is very flexible - a developer using the SpeechKit library can choose any key phrase for his application.
Unlike, for example, Google solutions - their developers use a deep neural network for recognizing the catchphrase "Okay, Google". DNN gives high quality, but the activation system is limited to a single team, and training requires a huge amount of data. Say, the model for recognizing all familiar phrases was trained on the example of more than 40 thousand user voices that applied to their smartphones from Google Now.
With our approach, the voice activation module is, in fact, a recognition system in miniature. It only works in tougher conditions. First, command recognition must occur on the device itself, without accessing the server. And the computing power of the smartphone is very limited. Power consumption is also critical - if a conventional recognition module is turned on only for a certain time to process a specific request, the activation module runs continuously in the standby mode. And while this should not put the battery.

However, there is a relief - for the activation system you need a very small dictionary, because it is enough for it to understand a few key phrases, and the rest of the speech can be simply ignored. Therefore, the language activation model is much more compact. Most WFST states correspond to a certain part of our team — for example, the “beginning of the fourth phoneme”. There are also “junk” states describing silence, extraneous noise and the rest of the speech, which is different from the key phrase. If a full-featured recognition model in SpeechKit has tens of millions of states and takes up to 10 gigabytes, then for voice activation it is limited to hundreds of states and fits into several tens of kilobytes.
Therefore, a model for recognizing a new key phrase is built without difficulty, allowing you to quickly scale the system. There is one condition - the team should be long enough (preferably - more than one word) and rarely occur in everyday speech to eliminate false positives. “Please” is not a good choice for voice activation, and “listen to my command” is fine.
Together with a limited language model and a “light” acoustic one, the recognition of commands can be done by any smartphone. It remains to deal with power consumption. The system has a built -in voice activity detector that monitors the appearance of the human voice in the incoming audio stream. The remaining sounds are ignored, therefore in the background the power consumption of the activation module is limited only by the microphone.
The third major component of speech technology is text-to-speech synthesis. TTS solution SpeechKit allows you to voice any text in a male or female voice, and even set the desired emotion. None of the voice engines we know about in the market has such an opportunity.
There are several fundamentally different speech synthesis technologies, and in most modern systems, concatenative synthesis using the “unit selection” method is used. A pre-recorded voice sample is cut into specific constituent elements (for example, context-dependent phonemes) from which the speech base is composed. Then any necessary words are collected from individual units. A believable imitation of a human voice is obtained, but it is difficult to perceive it - the timbre jumps, unnatural intonations and sharp transitions occur at the junctions of individual units. This is especially noticeable when dubbing long coherent text. The quality of such a system can be improved by increasing the volume of the speech base, but it is a long and painstaking work that requires the involvement of a professional and very patient speaker. And the completeness of the base always remains a bottleneck of the system.
In SpeechKit, we decided to use statistical (parametric) speech synthesis based on hidden Markov models. The process, in fact, is similar to recognition, only occurs in the opposite direction. The source code is transferred to the G2P module (grapheme-to-phoneme), where it is converted into a sequence of phonemes.

Then they fall into the acoustic model, which generates vectors that describe the spectral characteristics of each phoneme. These numbers are transmitted to the vocoder, which synthesizes sound.

The timbre of such a voice is somewhat “computerized”, but it has natural and smooth intonations. At the same time, the smoothness of speech does not depend on the size and length of the readable text, and the voice is easy to adjust. It is enough to specify one key in the request parameters, and the synthesis module will give out a voice with the corresponding emotional coloring. Of course, no unit selection system is capable of this.
In order for the voice model to be able to build algorithms corresponding to different emotions, it was necessary to train it properly. Therefore, during the recording, our colleague Eugene, whose voice can be heard in SpeechKit, uttered her remarks in turn in a neutral voice, joyful and, conversely, annoyed. During the training, the system identified and described the parameters and characteristics of the voice corresponding to each of these states.
Not all voice modifications are built on learning. For example, SpeechKit also allows you to color the synthesized voice with the parameters “drunk” and “ill”. Our developers regretted Eugene, and she did not have to get drunk before recording or run in the cold to get a good cold.
For a drunken voice, the speech slows down in a special way - each phoneme sounds about two times slower, which gives a characteristic effect. And for the patient, the threshold for sound is raised - what is happening with the vocal chords of a person during laryngitis is actually modeled. The voicing of different phonemes depends on whether the air passes through the human vocal tract freely or on the way there are vibrating vocal cords. In the "disease" mode, each phoneme is sounded less likely, which makes the voice hoarse, planted.
The statistical method also allows you to quickly expand the system. In the unit selection model, in order to add a new voice, you need to create a separate speech base. The announcer must record many hours of speech, while perfectly maintaining the same intonation. In SpeechKit, to create a new voice, it is enough to record at least two hours of speech - approximately 1,800 special, phonetically balanced sentences.
It is important not only to translate the words that a person utters into letters, but also fill them with meaning. The fourth technology, which is available in limited form in SpeechKit Cloud, does not concern directly the work with the voice - it starts to work after the spoken words are recognized. But without it, a complete stack of speech technologies cannot be done - this is the selection of semantic objects in natural speech, which, at the output, provides not just recognized, but already marked text.
Now in SpeechKit, the allocation of dates and time, name, addresses is implemented. The hybrid system combines context-free grammars, keyword dictionaries and search statistics and various Yandex services, as well as machine learning algorithms. For example, in the phrase “go to Lev Tolstoy Street” the word “street” helps the system determine the context, after which the corresponding object is located in the Yandex.Map database.

In Dictation, we built a voice editing feature on this technology. The approach to the allocation of entities is fundamentally new, and the emphasis is placed on the simplicity of configuration - to set up the system, you do not need to own programming.
The system’s input is supplied with a list of different types of objects and examples of phrases from live speech describing them. Further, from these examples, using the Pattern Mining method, patterns are formed. They take into account the initial form, roots, morphological variations of words. The next step provides examples of the use of selected objects in various combinations that will help the system understand the context. On the basis of these examples, a hidden Markov model is constructed, where the objects observed in the user's replica become observable states, and the corresponding objects from the subject field with an already known value become hidden.
For example, there are two phrases: “insert" hello, friend "in the beginning" and "paste from buffer". The system determines that in the first case, after “insert” (editing action), an arbitrary text goes, and in the second, an object known to it (“clipboard”), and reacts differently to these commands. In the traditional system, this would require writing the rules or grammars manually, and in the new Yandex technology, context analysis is performed automatically.
While dictating something, in the resulting text you expect to see punctuation marks. And they should appear automatically so that you do not have to talk to the interface in the telegraph style: "Dear friend - a comma - how are you - a question mark." Therefore, SpeechKit is complemented by an automatic punctuation system.
The role of punctuation marks in speech is played by intonation pauses. Therefore, initially we tried to build a full-fledged acoustic and language model for their recognition. Each punctuation mark was assigned a phoneme, and from the point of view of the system, new “words” appeared in the recognizable speech, completely consisting of such “punctuation” phonemes - where pauses appeared or intonation changed in a certain way.
Great difficulty has arisen with data for learning - in most corpses, already normalized texts, in which the punctuation marks are omitted. There is also almost no punctuation in the text of search queries. We turned to Ekho Moskvy, which manually decoded all of their ethers, and they allowed us to use our archive. It quickly became clear that these transcriptions are not suitable for our purposes - they are made close to the text, but not literally, and therefore not suitable for machine learning. The next attempt was made with audiobooks, but in their case, on the contrary, the quality was too high. Well-set voices, with an expression of reciting text, are too far from real life, and the results of training on such data could not be applied in spontaneous dictation.
The second problem was that the chosen approach had a negative effect on the overall quality of recognition. For each word, the language model considers several neighbors in order to correctly define the context, and the additional “punctuation” words inevitably narrowed it. A few months of experiments did not lead to anything.
We had to start from scratch - we decided to place punctuation marks already at the post-processing stage. We started with one of the simplest methods, which, oddly enough, showed in the end quite an acceptable result. Pauses between words receive one of the labels: space, full stop, comma, question mark, exclamation mark, colon. To predict which label corresponds to a specific pause, the conditional random fields method (CRF) is used. To determine the context, three preceding and two following words are taken into account, and these simple rules make it possible to arrange signs with sufficiently high accuracy. But we continue to experiment with full-fledged models that can still correctly interpret the intonation of a person from the point of view of punctuation at the stage of voice recognition.
Today, SpeechKit is actively used to solve "combat" tasks in mass services for end users. The next milestone is to learn to recognize spontaneous speech in a live stream, so that you can decipher interviews in real time or automatically take notes on a lecture, getting already marked text at the output, with highlighted theses and key facts. This is a huge and very high-tech task that has not yet been solved by anyone in the world - and we don’t like others!
Feedback is very important for the development of SpeechKit. Put Yandex.Dict , talk to it more often - the more data we get, the faster the recognition quality grows in the library accessible to all of you. Feel free to correct recognition errors using the "Corrector" button - it helps to mark the data. And be sure to write in the feedback form in the application.
A couple of words, so that you understand what it will be about. Yandex has long been providing a free mobile API that can be used, for example, to recognize addresses and voice search queries. During this year we were able to bring its quality to almost the same level at which people themselves understand such requests and replicas. And now we are taking the next step - a model for recognizing free speech on any topic.
')
In addition, our speech synthesis supports the emotions in the voice. And, as far as we know, this is still the first commercially available speech synthesis with such an opportunity.
About all this, as well as some other features of SpeechKit: about voice activation, automatic placement of punctuation signs and recognition of semantic objects in the text - read below.
Omnivorous ASR and recognition quality
SpeechKit's speech recognition system works with different types of text, and last year we worked on expanding its scope. For this, we have created a new language model, while the largest, to recognize short texts on any topic.
Over the past year, the relative share of mistakenly recognized words ( Word Error Rate ) has decreased by 30%. For example, today SpeechKit correctly recognizes 95% of addresses and geographic objects, coming close to a person who understands 96–98% of words he heard. The completeness of recognition of a new model for dictation of various texts now amounts to 82%. With this level, you can create a complete solution for end users, which we wanted to show by the example of dictation.
Initially, SpeechKit worked only for search queries: general subjects and geo-navigation. Although even then we planned to make not just an additional input tool, a “voice” keyboard, but a universal interface that would completely replace any interaction with the system with live conversation.
For this it was necessary to learn to recognize any speech, texts on an arbitrary topic. And we started working on a separate language model for this, which was several times larger than the existing geosteering and general search models.
Such a size of the model set new conditions in terms of computing resources. For each frame are considered several thousand variants of recognition - and the more we have time, the higher the quality. And the system should work in a stream, in real time, so all calculations need to be optimized dynamically. Experimented, tried, searched for an approach: accelerations were achieved, for example, by changing the library of linear algebra.
But the most important and difficult thing was to collect enough correct data suitable for teaching streaming speech. Currently, about 500 hours of manually transcribed speech are used to train the acoustic model. This is not such a big base - for comparison, the popular scientific building of Switchboard , which is often used for research purposes, contains about 300 hours of live, spontaneous conversations. Of course, an increase in the base contributes to the growth of the quality of the model being taught, but we focus on the correct preparation of data and model the transcriptions more accurately, which allows us to study on a relatively small base with an acceptable quality.
A few words about how the recognition module works (we talked about this in detail some time ago). The stream of recorded speech is cut into frames of 20 ms, the signal spectrum is scaled and after a series of transformations for each frame, the MFCC is obtained.
The coefficients arrive at the input of the acoustic model, which calculates the probability distribution for approximately 4000 senons in each frame. Senon is the beginning, middle, or end of a phoneme.
SpeechKit's acoustic model is built on a combination of hidden Markov models and a deep forward-propagation neural network ( feedforward DNN ). This is a proven solution, and in the last article we described how the rejection of Gaussian mixtures in favor of DNN gave an almost double leap in quality.
Then the first language model enters: several WFST - weighted finite transducers - turn senons into context-dependent phonemes, and from them entire words are constructed using the dictionary of pronunciations, with hundreds of hypotheses being obtained for each word.
Final processing takes place in the second language model. The RNN , a recurrent neural network, is connected to it, and this model ranks the hypotheses obtained, helping to select the most plausible option. A recurrent type network is especially effective for a language model. Defining the context of each word, it can take into account the influence not only of the closest words, as in the neural network of direct propagation (for example, for the trigram model, these are the two preceding words), but also further away, as if “remembering” them.
Recognition of long connected texts is available in the SpeechKit Cloud and SpeechKit Mobile SDK - to use the new language model, in the query parameters you need to select the theme “notes”.
Voice activated
The second key component of the voice interface is the voice activation system, which triggers the desired action in response to the key phrase. Without it, it will not be possible to fully untie the hands of the user. For SpeechKit, we have developed our voice activation module. The technology is very flexible - a developer using the SpeechKit library can choose any key phrase for his application.
Unlike, for example, Google solutions - their developers use a deep neural network for recognizing the catchphrase "Okay, Google". DNN gives high quality, but the activation system is limited to a single team, and training requires a huge amount of data. Say, the model for recognizing all familiar phrases was trained on the example of more than 40 thousand user voices that applied to their smartphones from Google Now.
With our approach, the voice activation module is, in fact, a recognition system in miniature. It only works in tougher conditions. First, command recognition must occur on the device itself, without accessing the server. And the computing power of the smartphone is very limited. Power consumption is also critical - if a conventional recognition module is turned on only for a certain time to process a specific request, the activation module runs continuously in the standby mode. And while this should not put the battery.
However, there is a relief - for the activation system you need a very small dictionary, because it is enough for it to understand a few key phrases, and the rest of the speech can be simply ignored. Therefore, the language activation model is much more compact. Most WFST states correspond to a certain part of our team — for example, the “beginning of the fourth phoneme”. There are also “junk” states describing silence, extraneous noise and the rest of the speech, which is different from the key phrase. If a full-featured recognition model in SpeechKit has tens of millions of states and takes up to 10 gigabytes, then for voice activation it is limited to hundreds of states and fits into several tens of kilobytes.
Therefore, a model for recognizing a new key phrase is built without difficulty, allowing you to quickly scale the system. There is one condition - the team should be long enough (preferably - more than one word) and rarely occur in everyday speech to eliminate false positives. “Please” is not a good choice for voice activation, and “listen to my command” is fine.
Together with a limited language model and a “light” acoustic one, the recognition of commands can be done by any smartphone. It remains to deal with power consumption. The system has a built -in voice activity detector that monitors the appearance of the human voice in the incoming audio stream. The remaining sounds are ignored, therefore in the background the power consumption of the activation module is limited only by the microphone.
Speech synthesis
The third major component of speech technology is text-to-speech synthesis. TTS solution SpeechKit allows you to voice any text in a male or female voice, and even set the desired emotion. None of the voice engines we know about in the market has such an opportunity.
There are several fundamentally different speech synthesis technologies, and in most modern systems, concatenative synthesis using the “unit selection” method is used. A pre-recorded voice sample is cut into specific constituent elements (for example, context-dependent phonemes) from which the speech base is composed. Then any necessary words are collected from individual units. A believable imitation of a human voice is obtained, but it is difficult to perceive it - the timbre jumps, unnatural intonations and sharp transitions occur at the junctions of individual units. This is especially noticeable when dubbing long coherent text. The quality of such a system can be improved by increasing the volume of the speech base, but it is a long and painstaking work that requires the involvement of a professional and very patient speaker. And the completeness of the base always remains a bottleneck of the system.
In SpeechKit, we decided to use statistical (parametric) speech synthesis based on hidden Markov models. The process, in fact, is similar to recognition, only occurs in the opposite direction. The source code is transferred to the G2P module (grapheme-to-phoneme), where it is converted into a sequence of phonemes.
Then they fall into the acoustic model, which generates vectors that describe the spectral characteristics of each phoneme. These numbers are transmitted to the vocoder, which synthesizes sound.
The timbre of such a voice is somewhat “computerized”, but it has natural and smooth intonations. At the same time, the smoothness of speech does not depend on the size and length of the readable text, and the voice is easy to adjust. It is enough to specify one key in the request parameters, and the synthesis module will give out a voice with the corresponding emotional coloring. Of course, no unit selection system is capable of this.
In order for the voice model to be able to build algorithms corresponding to different emotions, it was necessary to train it properly. Therefore, during the recording, our colleague Eugene, whose voice can be heard in SpeechKit, uttered her remarks in turn in a neutral voice, joyful and, conversely, annoyed. During the training, the system identified and described the parameters and characteristics of the voice corresponding to each of these states.
Not all voice modifications are built on learning. For example, SpeechKit also allows you to color the synthesized voice with the parameters “drunk” and “ill”. Our developers regretted Eugene, and she did not have to get drunk before recording or run in the cold to get a good cold.
For a drunken voice, the speech slows down in a special way - each phoneme sounds about two times slower, which gives a characteristic effect. And for the patient, the threshold for sound is raised - what is happening with the vocal chords of a person during laryngitis is actually modeled. The voicing of different phonemes depends on whether the air passes through the human vocal tract freely or on the way there are vibrating vocal cords. In the "disease" mode, each phoneme is sounded less likely, which makes the voice hoarse, planted.
The statistical method also allows you to quickly expand the system. In the unit selection model, in order to add a new voice, you need to create a separate speech base. The announcer must record many hours of speech, while perfectly maintaining the same intonation. In SpeechKit, to create a new voice, it is enough to record at least two hours of speech - approximately 1,800 special, phonetically balanced sentences.
Selection of semantic objects
It is important not only to translate the words that a person utters into letters, but also fill them with meaning. The fourth technology, which is available in limited form in SpeechKit Cloud, does not concern directly the work with the voice - it starts to work after the spoken words are recognized. But without it, a complete stack of speech technologies cannot be done - this is the selection of semantic objects in natural speech, which, at the output, provides not just recognized, but already marked text.
Now in SpeechKit, the allocation of dates and time, name, addresses is implemented. The hybrid system combines context-free grammars, keyword dictionaries and search statistics and various Yandex services, as well as machine learning algorithms. For example, in the phrase “go to Lev Tolstoy Street” the word “street” helps the system determine the context, after which the corresponding object is located in the Yandex.Map database.
In Dictation, we built a voice editing feature on this technology. The approach to the allocation of entities is fundamentally new, and the emphasis is placed on the simplicity of configuration - to set up the system, you do not need to own programming.
The system’s input is supplied with a list of different types of objects and examples of phrases from live speech describing them. Further, from these examples, using the Pattern Mining method, patterns are formed. They take into account the initial form, roots, morphological variations of words. The next step provides examples of the use of selected objects in various combinations that will help the system understand the context. On the basis of these examples, a hidden Markov model is constructed, where the objects observed in the user's replica become observable states, and the corresponding objects from the subject field with an already known value become hidden.
For example, there are two phrases: “insert" hello, friend "in the beginning" and "paste from buffer". The system determines that in the first case, after “insert” (editing action), an arbitrary text goes, and in the second, an object known to it (“clipboard”), and reacts differently to these commands. In the traditional system, this would require writing the rules or grammars manually, and in the new Yandex technology, context analysis is performed automatically.
Auto punctuation
While dictating something, in the resulting text you expect to see punctuation marks. And they should appear automatically so that you do not have to talk to the interface in the telegraph style: "Dear friend - a comma - how are you - a question mark." Therefore, SpeechKit is complemented by an automatic punctuation system.
The role of punctuation marks in speech is played by intonation pauses. Therefore, initially we tried to build a full-fledged acoustic and language model for their recognition. Each punctuation mark was assigned a phoneme, and from the point of view of the system, new “words” appeared in the recognizable speech, completely consisting of such “punctuation” phonemes - where pauses appeared or intonation changed in a certain way.
Great difficulty has arisen with data for learning - in most corpses, already normalized texts, in which the punctuation marks are omitted. There is also almost no punctuation in the text of search queries. We turned to Ekho Moskvy, which manually decoded all of their ethers, and they allowed us to use our archive. It quickly became clear that these transcriptions are not suitable for our purposes - they are made close to the text, but not literally, and therefore not suitable for machine learning. The next attempt was made with audiobooks, but in their case, on the contrary, the quality was too high. Well-set voices, with an expression of reciting text, are too far from real life, and the results of training on such data could not be applied in spontaneous dictation.
The second problem was that the chosen approach had a negative effect on the overall quality of recognition. For each word, the language model considers several neighbors in order to correctly define the context, and the additional “punctuation” words inevitably narrowed it. A few months of experiments did not lead to anything.
We had to start from scratch - we decided to place punctuation marks already at the post-processing stage. We started with one of the simplest methods, which, oddly enough, showed in the end quite an acceptable result. Pauses between words receive one of the labels: space, full stop, comma, question mark, exclamation mark, colon. To predict which label corresponds to a specific pause, the conditional random fields method (CRF) is used. To determine the context, three preceding and two following words are taken into account, and these simple rules make it possible to arrange signs with sufficiently high accuracy. But we continue to experiment with full-fledged models that can still correctly interpret the intonation of a person from the point of view of punctuation at the stage of voice recognition.
Future plans
Today, SpeechKit is actively used to solve "combat" tasks in mass services for end users. The next milestone is to learn to recognize spontaneous speech in a live stream, so that you can decipher interviews in real time or automatically take notes on a lecture, getting already marked text at the output, with highlighted theses and key facts. This is a huge and very high-tech task that has not yet been solved by anyone in the world - and we don’t like others!
Feedback is very important for the development of SpeechKit. Put Yandex.Dict , talk to it more often - the more data we get, the faster the recognition quality grows in the library accessible to all of you. Feel free to correct recognition errors using the "Corrector" button - it helps to mark the data. And be sure to write in the feedback form in the application.
Source: https://habr.com/ru/post/243813/
All Articles