Adapting ZenCoding to C # - ZenSharp
Many probably know that for HTML & CSS there is a great tool ZenCoding (emmet), which allows you to greatly simplify the input of routine language constructs, defining a special language mnemonic. C # is a less verbose language than Html, but nevertheless, the input of its constructions can be optimized.
I propose a dynamic extension of the mnemonic idea, which I first heard from Dmitry Nesteruk [ 1 ].
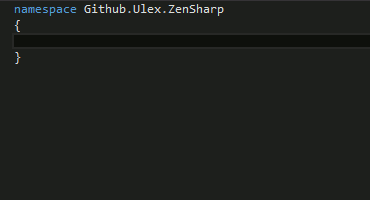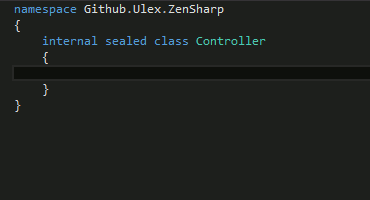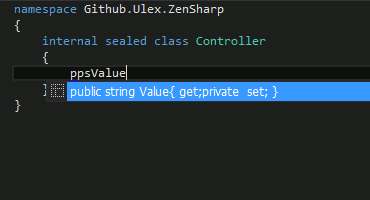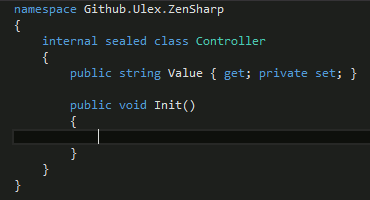
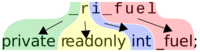
')
It turned out a small plugin for ReSharper, mnemonics for which can be configured through a special language, similar to a formal grammar.
The plugin for ReSharper is available in the extensions gallery. GitHub source code
The main idea behind ZenSharp is to create a language in which you can immediately define two languages - the language of abbreviations and the corresponding full spelling.
The entire abbrev definition file (* .ltg) consists of two parts:
A simple example of a rule definition: if we want the text to expand on the ex set to expand in expand text , then the starting rule must be defined as follows:
I call these rules "defining abbreviations."
In total there are three types of rules:
There is some sugar in the template description language:
It's easier to explain why all this is needed with a real example. Take a small
part of the standard rules:
Suppose we entered into the studio some kind of abracadabra of the type pcSome. Understanding how disclosure of this rule will occur is necessary, starting from the starting rule start. This rule defines two alternatives - class or interface. The grammar works on the PEG principle (parsing expression grammar), i.e. operator | is an ordered selection operator.
An alternative class is checked. Inside the class, access is successfully expanded and picks up the first letter p, revealing the “public” in its extended spelling. Next is the lazy part "sealed" = s. Our abracadabra has a part of cSome, and it does not fit this part, so we skip it, do not remove anything from
abbreviations and add nothing to the disclosure. Next comes the alternative of a class or a static class. The class fits us, so we have the “public class” expansion and the short string Some.
The special rule identifier takes all the alphabetic characters from the abbreviations and transfers them into a long spelling without changes (this is done for convenience).
As a result, our pcSome abracadabra turned into public class Some {$ END $}.
I repeat that the plugin for ReSharper 8.2 is available in the gallery.
Source code at github.com/ulex/ZenSharp
This is the first of two scheduled articles. I tried to describe the insides of ZenSharp. In the second article I will tell a little more about the standard templates. I myself use ZenSharp for no more than a month, from time to time adding convenient rules. I would appreciate feedback.
I propose a dynamic extension of the mnemonic idea, which I first heard from Dmitry Nesteruk [ 1 ].
')
It turned out a small plugin for ReSharper, mnemonics for which can be configured through a special language, similar to a formal grammar.
The plugin for ReSharper is available in the extensions gallery. GitHub source code
Small description
The main idea behind ZenSharp is to create a language in which you can immediately define two languages - the language of abbreviations and the corresponding full spelling.
The entire abbrev definition file (* .ltg) consists of two parts:
- rule definitions (i.e., what and how is what is revealed),
- determine the action area of these rules.
A simple example of a rule definition: if we want the text to expand on the ex set to expand in expand text , then the starting rule must be defined as follows:
start ::= "expand text"="ex" I call these rules "defining abbreviations."
In total there are three types of rules:
- Defining abbreviation. Consists of a pair of lines defined in the form of "expand" = "short" Ie if you want to get an abbreviation so that, by typing p, to get public, then this rule is declared as "public" = "p"
- String. Just a string that will always be used when expanding the abbreviation rule. In other words, just a text that does not depend on which letter we use in the abbreviation. The string rule is the same as the rule that defines the abbreviation with an empty abbrev string.
- Wildcard. A special type that is introduced specifically to support the possibility of entering the name of a variable / function in the abbreviation language. You can use two default rules for the type and name of a variable.
Syntactic sugar
There is some sugar in the template description language:
- brackets
- question mark after parentheses rewrite rule to (x)? => ((x) | "")
- if the abbreviation does not contain special characters, then it can be defined
without quotes, i.e. "some" = s, not "some" = "s" - multi-line definition of alternatives. This is done to conveniently write the start rule so as not to create garbage in the VCS.
start :: = rulea | ruleb
it's the same asstart ::= | rulea | ruleb
Explanation of examples
It's easier to explain why all this is needed with a real example. Take a small
part of the standard rules:
interface ::= access "interface"=i space classBody class ::= access ("sealed "=s)? ("class"=c | "static class"=C) space classBody access ::= (internal=i | public=p | private=_ | protected=P) space classBody ::= identifier "{" cursor "}" scope "InCSharpTypeAndNamespace" { start ::= class | interface } Suppose we entered into the studio some kind of abracadabra of the type pcSome. Understanding how disclosure of this rule will occur is necessary, starting from the starting rule start. This rule defines two alternatives - class or interface. The grammar works on the PEG principle (parsing expression grammar), i.e. operator | is an ordered selection operator.
An alternative class is checked. Inside the class, access is successfully expanded and picks up the first letter p, revealing the “public” in its extended spelling. Next is the lazy part "sealed" = s. Our abracadabra has a part of cSome, and it does not fit this part, so we skip it, do not remove anything from
abbreviations and add nothing to the disclosure. Next comes the alternative of a class or a static class. The class fits us, so we have the “public class” expansion and the short string Some.
The special rule identifier takes all the alphabetic characters from the abbreviations and transfers them into a long spelling without changes (this is done for convenience).
As a result, our pcSome abracadabra turned into public class Some {$ END $}.
I repeat that the plugin for ReSharper 8.2 is available in the gallery.
Source code at github.com/ulex/ZenSharp
This is the first of two scheduled articles. I tried to describe the insides of ZenSharp. In the second article I will tell a little more about the standard templates. I myself use ZenSharp for no more than a month, from time to time adding convenient rules. I would appreciate feedback.
Source: https://habr.com/ru/post/243085/
All Articles