Writing a framework on asyncio, aiohttp and thinking about Python3 part one

A year and a half ago, there was a question of compatibility of written code with Python3 . Since it has become less obvious that only Python3 is being Python3 and, sooner or later, all libraries will be ported to it. And in all distributions the default will be a triple . But gradually, as I Asyncio what was new in the latest versions of Python I became more and more pleased with Asyncio and, rather, not even Acyncio but Acyncio written to work with it. And, after some time, a small wrapper appeared around aiohttp in the style of like django . Who cares what came out of this please under the cat.
Introduction
Overview of other aiohttp frameworks
1. Structure
2. aiohttp and jinja2
3. aiohttp and routes
4. Statics and GET, POST parameters, redirects
5. Websocket
6. asyncio and mongodb, aiohttp, session, middleware
7. aiohttp, supervisor, nginx, gunicorn
8. After installation, about examples.
9.RoadMap
Introduction
At that time, almost all libraries frequently used in projects were already ready for Python3 .
The dead PIL was beautifully replaced by Pillow , tweppy on twython , python-openid on python3-openid , etc. Jinja2 , xlrt , xlwt and others have already been supporting Python3 .
Roughly speaking, all that had to be implemented was for the system to give data in the form of bytes :
def application(env, start_response): start_response('200 OK', [('Content-Type','text/html')]) return bytes("Hello World", 'utf-8') It is a little, with library renaming to suffer:
py = sys.version_info py3k = py >= (3, 0, 0) if py3k: unicode = str import io as StringIO import builtins as __builtin__ else: import StringIO And, of course, as we learn what's new, Python3 could not help but draw Asyncio attention. The asynchronous engine built into python3 . Appeared, however, only in version 3.4 . And only from version 3.5 , which was released the other day, it has got quite a good syntactic sugar, more on that below.
The first time, of course, it was wildly inconvenient to write something on it and, as far as I understood, everyone still used tornado , gevent , twisted or wrapped around the same asynio and twisted - autobuh . Pretty good product. But as time went on, one of the developers of asyncio svetlov created a fairly rapidly developing asynchronous framework aiohttp . Aiohttp simplifies development using asyncio about the level of flask or bottle .
But with fairly easily connected websockets and, if desired, allowing you to perform most operations asynchronously, and, in my opinion, with a fairly small price for it, especially with an eye to python3.5 .
It looks like this:
#python3.4 @asyncio.coroutine def read_data(): data = yield from db.fetch('SELECT . . . ') #python3.5 async def read_data(): data = await db.fetch('SELECT ...') Since so far for writing chats, toys, conferences with webrtc , where there are websoket I had to use either gevent or autobah or in some cases node.js , having weighed all the aiohttp and cons, I really wanted to rewrite my libraries on aiohttp , which over the last The year managed to grow its eco-system, and a number of convenient opportunities. And so this publication appeared.
We must also add that in aiohttp it is quite possible to write and synchronously, perform blocking operations, although this is not entirely correct.
Next will be described the work with aiohttp and the creation of a small framework in the style of like django , with similar structure and capabilities.
Naturally, it is not necessary to expect any batteries from version 0.1, but I think that in the next version, you can already see a lot of positive changes.
Overview of other frameworks based on asyncio and aiohttp
Here I want to give a very brief overview, so that there is a general overview of the current state of affairs with writing asynchronous libraries that simplify the life of developers in Python3 .
All of the frameworks listed below can be divided into two categories - those that are dependent on aiohttp and are based on it, and those that work without it, only with asyncio .
Pulsar - framework using asyncio and multiprocessing . Integrates with django , hello world on it looks like a regular wsgi . On github there are quite a few examples of use, for example, chats, the author, as far as I understand, loves angular.js
from pulsar.apps import wsgi def hello(environ, start_response): data = b'Hello World!\n' response_headers = [ ('Content-type','text/plain'), ('Content-Length', str(len(data))) ] start_response('200 OK', response_headers) return [data] if __name__ == '__main__': wsgi.WSGIServer(callable=hello).start() Mufin is aiohttp based framework . He has a number of plugins, as I understand it, written, as far as possible, asynchronously. Also, there is a test application deployed on Heroku in the form of a chat.
import muffin app = muffin.Application('example') @app.register('/', '/hello/{name}') def hello(request): name = request.match_info.get('name', 'anonymous') return 'Hello %s!' % name introduction is another aiohttp based framework
from interest import Service, http class Service(Service): @http.get('/') def hello(self, request): return http.Response(text='Hello World!') service = Service() service.listen(host='127.0.0.1', port=9000, override=True, forever=True) Spanner.py is positioned as a micro web-framework written in python for people :), the author was inspired by Flask and express.js . Uses only asyncio . Looks really pretty laconic.
from webspanner import Spanner app = Spanner() @app.route('/') def index(req, res): res.write("Hello world") Growler - framework using only asyncio , the authors say that they took the ideas of node.js and express .
import asyncio from growler import App from growler.middleware import (Logger, Static, Renderer) loop = asyncio.get_event_loop() app = App('GrowlerServer', loop=loop) # middleware app.use(Logger()) app.use(Static(path='public')) @app.get('/') def index(req, res): res.render("home") Server = app.create_server(host='127.0.0.1', port=8000) loop.run_forever() astrid - A simple flask like framework based on aiohttp .
import os from astrid import Astrid from astrid.http import render, response @app.route('/') def index_handler(request): return response("Hello") app.run() 1. Structure
So, we should have the library itself, which we want to install using pip install and in which there should be modules or batteries included in the composition - for example, an admin or a web store. And there should be a project that we create in some place where the developer should be able to add their modules with different functionality.
In each component of both the project and the library itself there should be a folder with statics and a folder with templates, a file with a list of routes and a file or a file with requests to the database and outputting all this to templates.
If needed, python 3.5 installed like this:
sudo add-apt-repository ppa:fkrull/deadsnakes sudo apt-get update sudo apt-get install python3.5 python3.5-dev Library - installed via pip3 install :
apps-> app-> static templ view.py routes.py app1-> ... app2-> ... core-> core.py union.py utils.py An example of a project - there may be as many as you like, ideally for each site its own:
apps-> app-> static templ view.py routes.py app1-> ... app2-> ... static templ view.py route.py settings.py The content of the files with the list of routes we want to see approximately like this:
from core.union import route route('GET' , '/', page ) route( 'GET' , '/db', test_db ) And view where these routes are processed of this type:
async def page(request): return templ('index', request, {'key':'val'}) That is, everything looks quite simple and quite comfortable, except for the optional need to write a call to the coroutine @asyncio.coroutine or async def every time.
2. aiohttp, jinja2 and debugger
For aiohttp there is a specially written debugger and asynchronous wrapper for jinja2 . We will use them.
pip3 install aiohttp_jinja2 import asyncio, jinja2, aiohttp_jinja2 from aiohttp import web async def page(req): return aiohttp_jinja2.render_template('index.tpl', req,{'k':'v'}) async def init(loop): app = web.Application(loop=loop) aiohttp_jinja2.setup(app, loader=jinja2.FileSystemLoader('./')) app.router.add_route('GET', '/', page) srv = await loop.create_server(app.make_handler(), '127.0.0.1', 80) return srv app = web.Application() loop = asyncio.get_event_loop() loop.run_until_complete(init(loop)) try: loop.run_forever() except KeyboardInterrupt: pass But we need to call templates from different places and preferably as simple as possible, for example:
return templ('index', request, {'key':'val'}) And for the template itself, you need to somehow abbreviate the path. Places where templates can be stored may be several pieces:
- Templates in the `templ` folder at the root of the project itself.
- Templates that lie in the project modules or library modules.
Therefore, conditionally agree that if the templates are in the root of any project, then the name of the template will be simply indicated, for example, 'template' . And templates from modules will look like this:
return templ("apps.app:template", request, {'key':'val'}) where the app component and template template.
Therefore, in the place where we initialize the paths, connecting the templates we call the function that will collect all the paths to the directories where the templates are located:
aiohttp_jinja2.setup(app, loader=jinja2.FunctionLoader ( load_templ ) ) def get_path(app): if type(app) == str: __import__(app) app = sys.modules[app] return os.path.dirname(os.path.abspath(app.__file__)) def get_templ_path(path): module_name = ''; module_path = ''; file_name = ''; name_templ = 'default'; if ':' in path: module_name, file_name = path.split(":", 1) # app.table main module_path = os.path.join( get_path( module_name), "templ") else: module_path = os.path.join( os.getcwd(), 'templ', name_templ) return module_name, module_path, file_name+'.tpl' def render_templ(t, request, p): # = p = dict(**p) return aiohttp_jinja2.render_template( t, request, p ) def load_templ(t, **p): (module_name, module_path, file_name) = get_templ_path(t) def load_template (module_path, file_name): path = os.path.join(module_path, file_name) template = '' filename = path if os.path.exists ( path ) else False if filename: with open(filename, "rb") as f: template = f.read() return template template = load_template( module_path, file_name) if not template: return 'Template not found {}' .format(t) return template.decode('UTF-8') Here I would like to focus on the sequence of actions:
1) We parse our template path, for example, 'apps.app:index' , simply check that if there is a in the path, then the templates are not taken from the root of the project, and then we call the function to search for paths from imports:
def get_path(app): if type(app) == str: # . "news". __import__(app) # "news" news app app = sys.modules[app] # return os.path.dirname(os.path.abspath(app.__file__)) 2) Knowing the path and name of the template, we read it from the disk (I note that asyncio does not support asynchronous read operations from disk):
filename = path if os.path.exists ( path ) else False if filename: with open(filename, "rb") as f: template = f.read() Here I would like to note one thing, often in the examples for connecting to jinja2, including in aiohttp_jinja2, it is recommended to use FileSystemLoader for initialization simply by passing a path or a list of paths to it, for example:aiohttp_jinja2.setup(app, loader=jinja2.FileSystemLoader('/templ/'))
And in our case, we used FunctionLoader :aiohttp_jinja2.setup(app, loader=jinja2.FunctionLoader ( load_templ ) )
This is due to the fact that we want to store templates in different directories, for different modules, and not worry about the same names. And in the case of the FunctionLoader we go only along the necessary paths. As a result, our modules have independent namespaces.
In order to write in the template call abbreviated templ we write a small wrapper and assign it to builtins.templ , after which we can call templ from any place without importing it permanently:
def render_templ(t, request, p): return aiohttp_jinja2.render_template( t, request, p ) builtins.templ = render_templ aiohttp_debugtoolbar
aiohttp_debugtoolbar - connects quite easily, where we initialize our app :
app = web.Application(loop=loop, middlewares=[ aiohttp_debugtoolbar.middleware ]) aiohttp_debugtoolbar.setup(app) It connects through a very middleware , how to write your own will talk a little lower.
The aiohttp_debugtoolbar itself has a pleasant impression on me, and everything I need is present, a few screenshots:
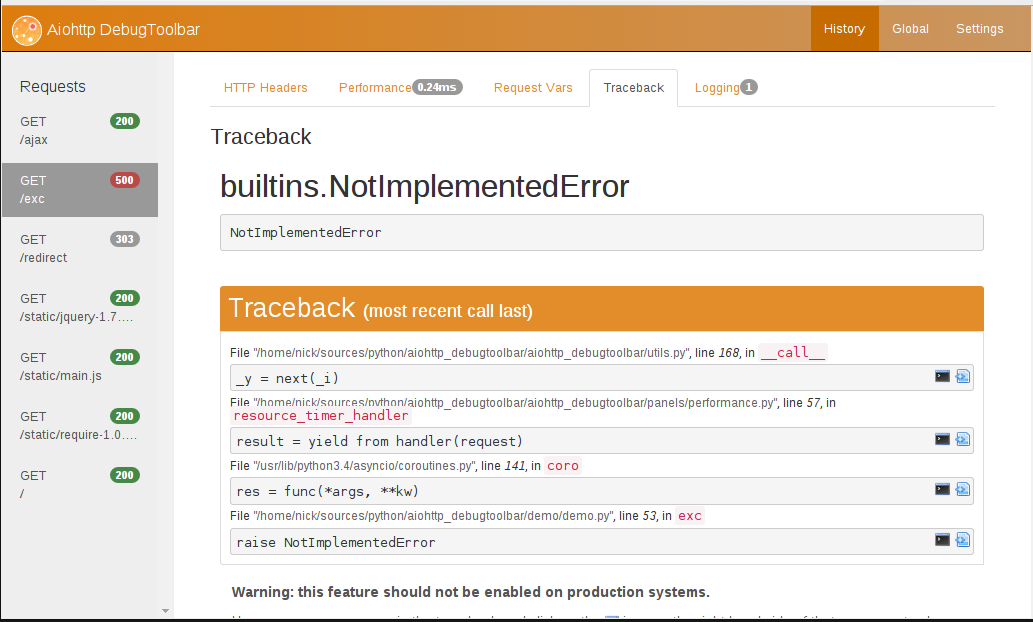

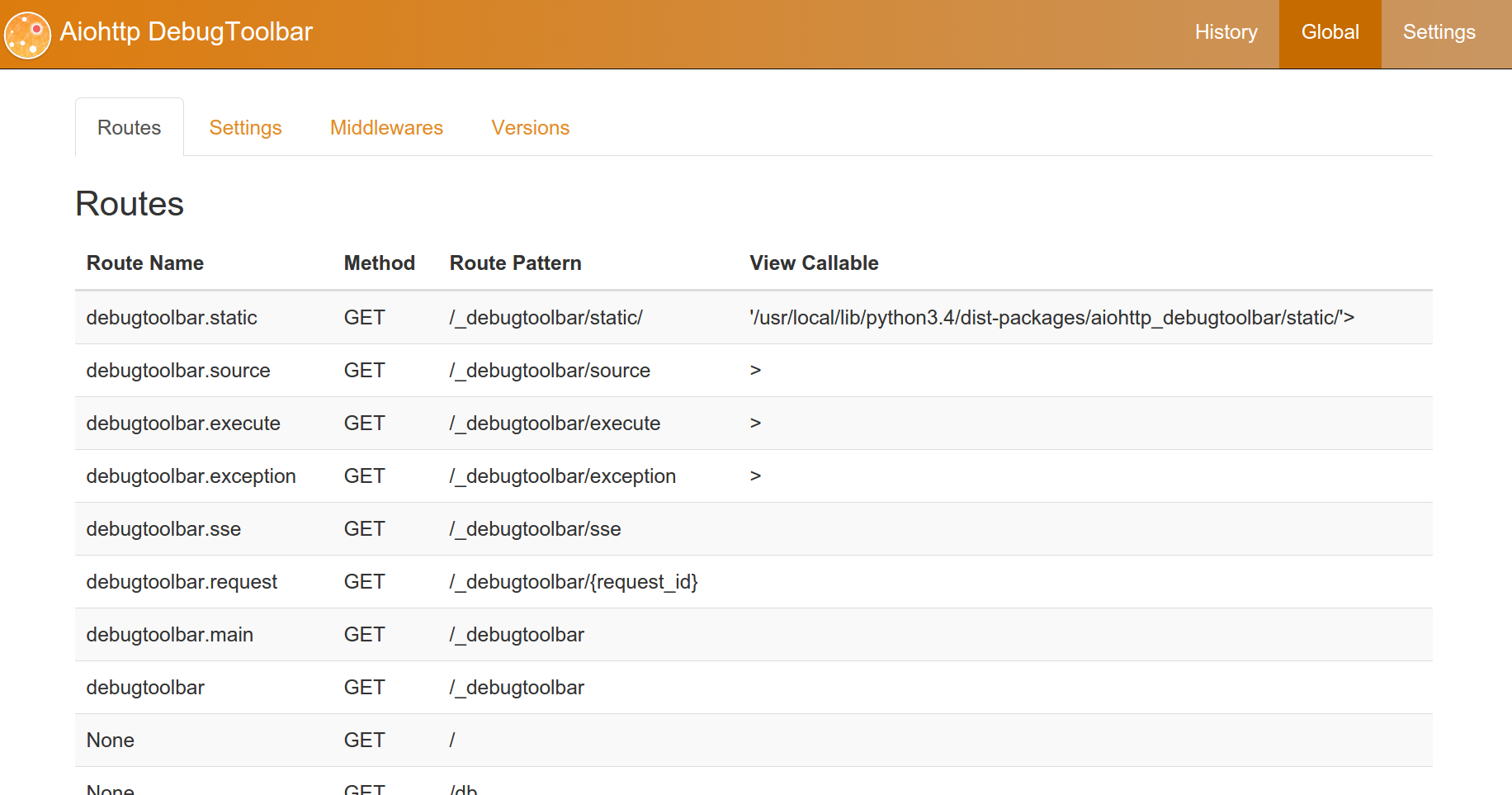
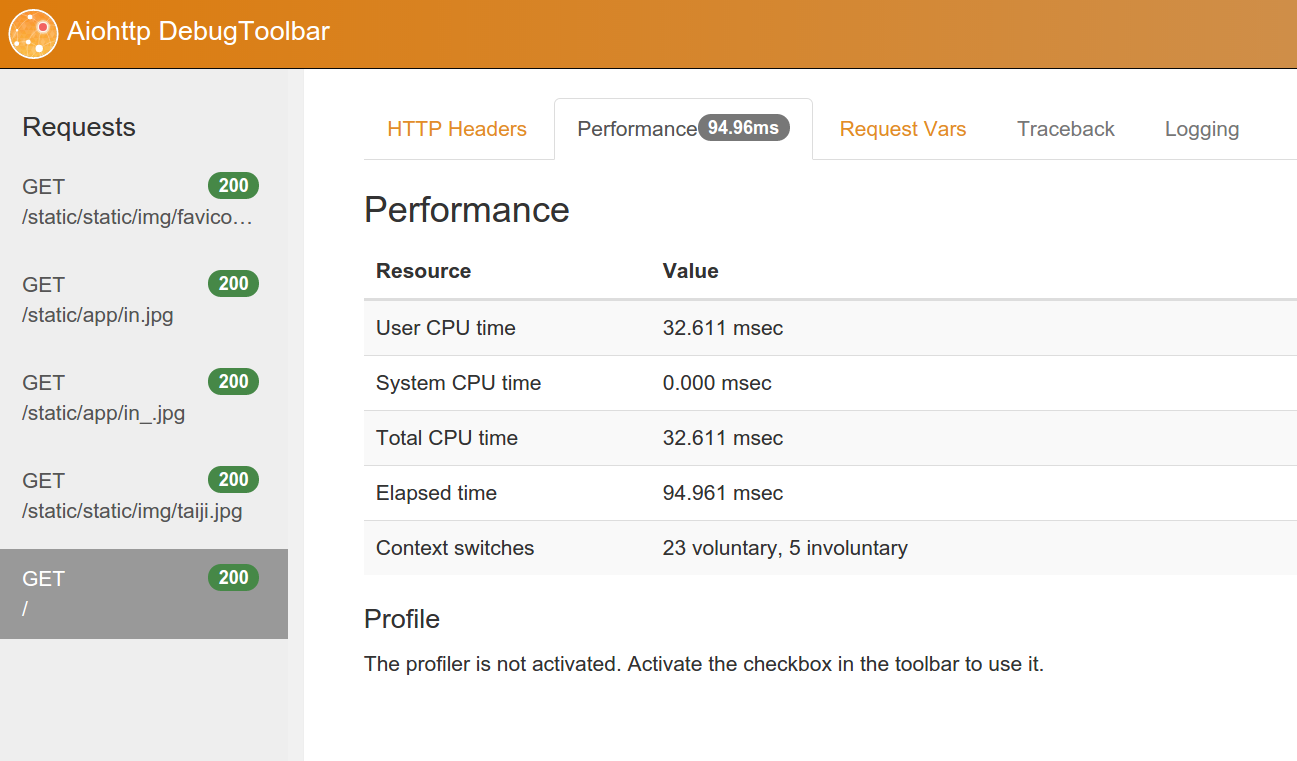

3. aiohttp and routes
In aiohttp routes look quite simple, an example from the documentation with obtaining a dynamic parameter from the address:
@asyncio.coroutine def variable_handler(request): return web.Response( text="Hello, {}".format(request.match_info['name'])) app = web.Application() app.router.add_route('GET', '/{name}', variable_handler) But since we have a modular system, we need to call our routes in each module in our routes.py . And it is desirable to simplify it as much as possible, for example:
from core import route route('GET', '/', page, 'page' ) route('GET', '/db', test_db, 'test_db' ) There will have to use a global variable, although it is not very kosher. The route function has a simple view:
def route(t, r, func, name=None): routes.append((t, r, func, name)) In the global variable, which is a list, we put tuples of the values of each route. And then during the initialization we simply go through all the tuples and in the authentic call of the route:
for res in routes: name = res[3] if name is None: name = '{}:{}'.format(res[0], res[2]) app.router.add_route( res[0], res[1], res[2], name=name) Naturally, before going through all the routes we need to initialize the paths where the routes.py files are routes.py . We do this using a function that looks like this in a simplified form:
def union_routes( dir=settings.root ): name_app = dir.split(os.path.sep) name_app = name_app[len(name_app) - 1] for name in os.listdir(dir): path = os.path.join(dir, name) if os.path.isdir ( path ) and os.path.isfile ( os.path.join( path, 'routes.py' )): name = name_app+'.'+path[len(dir)+1:]+'.routes' builtins.__import__(name, globals=globals()) 4. Return statics
Of course, by normal statics it is better to give using nginx but our framework should also be able to give statics.aiohttp already had a static return function, but it was noticed a little later than necessary and its own function was already written.
Static files will be recognized by route /static/path . Those files that are located in the project root will be recognized by the path /static/static/file_name , and files in the components /static/modul_name/file_name .
Naturally, all static files will be in the /static folders of any module or project, and may have any number of nestings, say /static/img/big_img/ .
We begin to implement, as always, with initialization. Here we are just one route serving all the main types of static addresses.
app.router.add_route('GET', '/static/{component:[^/]+}/{fname:.+}', union_stat) Further in the union_stat function union_stat we simply parse the parameters of the route {component:[^/]+}/{fname:.+} Which received:
component = request.match_info.get('component', "st") fname = request.match_info.get('fname', "st") And form the appropriate path.
After that, in another auxiliary function, we create the headers we need for the files, for example:
mimetype, encoding = mimetypes.guess_type(filename) if mimetype: headers['Content-Type'] = mimetype if encoding: headers['Content-Encoding'] = encoding And we read the file itself from the disk.
At the end, we return the headers and the file itself:
return web.Response( body=content, headers=MultiDict( headers ) ) def union_stat(request, *args): component = request.match_info.get('component', "Anonymous") fname = request.match_info.get('fname', "Anonymous") path = os.path.join( settings.root, 'apps', component, 'static', fname ) if component == 'static': path = os.path.join( os.getcwd(), 'static') elif not os.path.exists( path ): path = os.path.join( os.getcwd(), 'apps', component, 'static' ) else: path = os.path.join( settings.root, 'apps', component, 'static') content, headers = get_static_file(fname, path) return web.Response(body=content, headers=MultiDict( headers ) ) def get_static_file( filename, root ): import mimetypes, time root = os.path.abspath(root) + os.sep filename = os.path.abspath(os.path.join(root, filename.strip('/\\'))) headers = {} mimetype, encoding = mimetypes.guess_type(filename) if mimetype: headers['Content-Type'] = mimetype if encoding: headers['Content-Encoding'] = encoding stats = os.stat(filename) headers['Content-Length'] = stats.st_size from core.core import locale_date lm = locale_date("%a, %d %b %Y %H:%M:%S GMT", time.gmtime(stats.st_mtime), 'en_US.UTF-8') headers['Last-Modified'] = str(lm) headers['Cache-Control'] = 'max-age=604800' with open(filename, 'rb') as f: content = f.read() f.close() return content, headers UPD. All the same, in the latest version of the library, the return of statics was slightly redone. Now, static is given by aiohttp , from the static folder in the project root.
path = os.path.join( os.path.dirname(__file__), 'static') app.router.add_static('/static/', path, name='static') In the /static folder, there should be relative links to all folders with statics of all modules, both standard libraries and those that were created in the project. Relative references are created during the launch of commands to create a project structure or create an application structure.
utils.py -p name_project utils.py -a name_app I will say a few words about POST , GET requests and redirection in aiohttp . GET requests look pretty standard.
async def get_get(request): query = request.GET['query'] async def get_post(request): data = await request.post() filename = data['mp3'].filename Redirect to the address specified in the route 'test' with 302 response
async def redirect(request): data = await request.post() . . . url = request.app.router['test'].url() return web.HTTPFound( url ) A list of all the answers.
5. aiohttp and websocket
One of the most pleasant features of aiohttp is the ability to easily connect web-sites, simply by calling a function in the route that is responsible for processing them. Without any extra crutches.
For example, app.router.add_route('GET', '/ws', ws) . If we look at the route from our little wrapper we just wrote, it might look like this: route('GET', '/ws', ws )
The processing of the web socket software itself looks pretty simple, and let's say writing a small chat by the amount of code is quite succinctly.
async def websocket_handler(request): ws = web.WebSocketResponse() await ws.prepare(request) async for msg in ws: if msg.tp == aiohttp.MsgType.text: if msg.data == 'close': await ws.close() else: ws.send_str(msg.data + '/answer') elif msg.tp == aiohttp.MsgType.error: print('ws connection closed %s' % ws.exception()) print('websocket connection closed') return ws For example, the same is the case with Node.JS , using the ws module:
var WebSocketServer = new require('ws'); var clients = {}; var webSocketServer = new WebSocketServer.Server({ port: 8081 }); webSocketServer.on('connection', function(ws) { var id = Math.random(); clients[id] = ws; ws.on('message', function(message) { for (var key in clients) { clients[key].send(message); } }); ws.on('close', function() { console.log('onnection closed ' + id); delete clients[id]; }); }); 6. asyncio and mongodb, aiohttp, session, middleware
aiohttp has such a great tool as middleware , in different cases this term means slightly different things, so let's look at it using the example of creating a connector to the database.
Such frameworks as flask or bootle have the ability to call any function before loading the rest or after, for example, in the bootle :
@bottle.hook('after_request') def enable_cors(): response.headers['Access-Control-Allow-Origin'] = '*' In the case of aiohttp , including for about such cases, middleware was invented.
So, we want to write database requests as simple as possible, request.db :
def test_db(request): return templ('apps.app:db_test', request, { 'key': request.db.doc.find_one({"_id":"test"}) }) To do this, we will create middleware and initialize it at the very beginning, this is done quite simply, an example with an already initialized debager, sessions and base.
app = web.Application(loop=loop, middlewares=[ aiohttp_debugtoolbar.middleware, db_handler(), session_middleware(EncryptedCookieStorage(b'Secret byte key')) ]) def db_handler(): async def factory(app, handler): async def middleware(request): if request.path.startswith('/static/') or request.path.startswith('/_debugtoolbar'): response = await handler(request) return response # db_inf = settings.database kw = {} if 'rs' in db_inf: kw['replicaSet'] = db_inf['rs'] from pymongo import MongoClient mongo = MongoClient( db_inf['host'], 27017) db = mongo[ db_inf['name'] ] db.authenticate('admin', settings.database['pass'] ) request.db = db # ( ) response = await handler(request) mongo.close() # return response return middleware return factory What I would like to draw attention to, since the middleware responds to every server request, first of all, we check that the request does not contain the address at which we get the static, as well as the address at which the debugger is called. In order for each request not to pull the base.
def middleware(request): if request.path.startswith('/static/') or request.path.startswith('/_debugtoolbar'): ``` : ```python mongo = MongoClient( db_inf['host'], 27017) And at the end we close the connection:
mongo.close() Everything looks quite simple, some utilities from the author aiohttp svetlov are initialized and created in a similar way through middleware .
Well, then in more detail it is necessary to stop at the driver for mongodb . Unfortunately, it is not yet asynchronous, it is more correct to say that the asynchronous driver is there, but it has long been abandoned and leaves much to be desired, and there is no gridFS support, no pymongo innovations pymongo and so on.
But still, progress does not stand still and PyMongo developer and at the same time an asynchronous driver for MongoDB for Tornado , Motor - A. Jesse Jiryu Davis is actively working on integrating Asyncio into Motor . And already promises this fall to release version 0.5 with support for Asyncio .
7. aiohttp, supervisor, nginx, gunicorn
aiohttp are several ways to run aiohttp :
- `aiohttp` is better to simply run from the console if we are developing, and using` supervisor` if production.
- Start using `gunicorn` and` supervisor`.
I think for both cases, in a simplified version, the nginx configuration is suitable as a proxy , although gunicorn can be launched via a socket if desired.
server { server_name test.dev; location / { proxy_pass http://127.0.0.1:8080; } } Aiohttp and supervisor
Install supervisor:
apt install supervisor In /etc/supervisor/conf.d/ create the /etc/supervisor/conf.d/ file and in it:
[program:aio] command=python3 index.py directory=/path/to/project/ user=nobody autorestart=true redirect_stderr=true After that we update configs of all applications, without restarting.
supervisorctl reread >>aio: available >>erp: changed :
supervisorctl update >>erp: stopped >>erp: updated process group >>aio: added process group :
supervisorctl status >>aio RUNNING pid 31570, uptime 0:06:49 >>erp FATAL Exited too quickly (process log may have details) import asyncio from aiohttp import web def test(request): return {'title': 'Hello' } async def init(loop): app = web.Application( loop = loop ) app.router.add_route('GET', '/', basic_handler, name='index') handler = app.make_handler() srv = await loop.create_server(handler, '127.0.0.1', 8080) return srv, handler loop = asyncio.get_event_loop() srv, handler = loop.run_until_complete( init( loop ) ) try: loop.run_forever() except KeyboardInterrupt: loop.run_until_complete(handler.finish_connections()) , sys.path :
# sys.path.append( settings.root ) # sys.path.append( os.path.dirname( __file__ ) ) Aiohttp gunicorn supervisor
gunicorn , index , .
from aiohttp import web def index(request): return web.Response(text="Hello!") app = web.Application() app.router.add_route('GET', '/', index) gunicorn , , app .
def init_gunicorn(): app = web.Application( middlewares=[ aiohttp_debugtoolbar.middleware, db_handler(), session_middleware(EncryptedCookieStorage(b'Sixteen byte key')) ]) aiohttp_debugtoolbar.setup(app) aiohttp_jinja2.setup(app, loader=jinja2.FunctionLoader ( load_templ ) ) union_routes(os.path.join ( settings.root, 'apps' ) ) union_routes(os.path.join ( os.getcwd(), 'apps' ) ) for res in routes: app.router.add_route( res[2], res[0], res[1], name=res[3]) app.router.add_route('GET', '/static/{component:[^/]+}/{fname:.+}', union_stat) return app gunicorn
import sys, os, settings sys.path.append( settings.root ) sys.path.append( os.path.dirname( __file__ ) ) from core.union import init_gunicorn app = init_gunicorn() gunicorn
>> gunicorn app:app -k aiohttp.worker.GunicornWebWorker -b localhost:8080 supervisor .
gunicorn supervisor , gunicorn.conf.py :
worker_class ='aiohttp.worker.GunicornWebWorker' bind='127.0.0.1:8080' workers=8 reload=True user = "nobody" /etc/supervisor/conf.d/name.conf :
[program:name] command=/usr/local/bin/gunicorn app:app -c /path/to/project/gunicorn.conf.py directory=/path/to/project/ user=nobody autorestart=true redirect_stderr=true :
supervisorctl reread supervisorctl update 8. , .
pip3 install tao1 ..utils.py -p name , , -p --project --startProject .utils.py -a name apps -a --app --startApp ;-)
utils.py .
.argparse :
parser = argparse.ArgumentParser() parser.add_argument('-project', '-startproject', '-p', type=str, help='Create project' ) parser.add_argument('-app', '-startapp', '-a', type=str, help='Create app' ) args = parser.parse_args() ``` : ```python import shutil shutil.copytree( os.path.join( os.path.dirname(__file__), 'sites', 'test'), str(args.project) ) setup.py
https://pypi.python.org/ scripts=['tao1/core/utils.py'] .
utils.py /usr/local/bin/ ( ubuntu) .
9. Road map
0.2 — 0.5
- ( memcached).
- .
- - .
- . .
- .
, , , , , php Node , . , , .
PS . , , , . Asyncio . .
.
:
pep-0492
svetlov aiohttp
aiohttp github
aiohttp readthedocs
aiohttp-jinja2 readthedocs
yield from
aiohttp_session
aio-libs —
')
Source: https://habr.com/ru/post/242541/
All Articles