False correlations from the open data of the Perm region
On November 6-7, 2014, the Open Region. Hackathon " on the development of applications and services based on the open data of the Perm region.
The site opendata.permkrai.ru published about 1400 statistical indicators in various areas of the province. What can be done with this data? The first thought that came to my mind was to create an analogue of the site Spurious Correlations (false correlations).
Tl; DR:
Sources: github.com/yakov-bakhmatov/odpr
Application: odpr.bakhmatov.ru
Methods for obtaining and data formats are described on the page for developers . In short, the web service provides metadata description (a list of indicators, a list of “cubes” - additional parameters of indicators, such as OKATO, OKVED, countries of the world, etc., a list of indicator-cube pairs) in xml format and the data itself (by a pair of indicator identifiers and a cube) in xml and csv formats.
')
To simplify the primary analysis with "eyes", I chose the csv format. In this format, the entries are
Calendar level is a number from 1 to 5 (1 - year, 2 - half year, 3 - quarter, 4 - month, 5 - day).
A quick analysis revealed the following problems:
All these problems are somehow solved, we proceed to the implementation of the idea.
For each pair of indicators that have the same calendar level and overlapping date ranges, we calculate the Pearson correlation coefficient. We select those pairs whose modulus of the correlation coefficient is greater than 0.9 (| r |> 0.9). When opening (or updating) a web application page, we will show graphs of a random pair, built in one coordinate system.
You also need a list of all available pairs with a search or filter.
I wanted to create an application quickly, trying to stay in the time frame of the hackathon. Here is my selection of tools:
First, the data must be downloaded from the source. Here the first trouble was waiting - after pumping out several dozens of data files, the site opendata.permkrai.ru began to give the 500th error. I had to stretch this stage to several approaches.
Secondly, I decided to limit myself to the OKATO “cube”.
A total of 1151 files were downloaded, totaling 256 MiB.
Then, each file was sorted out, the lines were grouped by set (calendar level, indicator, OKATO).
Lines that are not related to the Perm region were discarded.
Doubles, missed periods were deleted. The values of the indicators were "normalized".
After this stage, 11,468 data series remain.
There is nothing difficult. We calculate the correlation coefficient between two rows, if these rows belong to different indicators, have the same calendar level, have at least 8 points at the intersection of date ranges.
It turned out 129507 pairs with a correlation coefficient of more than 0.9 (or less than -0.9).
Generally speaking, almost 130 thousand pairs is a lot. In a reasonable time, such a number of graphs simply cannot be seen.
But the fact is that within the indicator there can be a very small difference between the rows (and the correlation coefficient, on the contrary, is large - close to 1). If the indicator X contains n rows, and the indicator Y contains m rows, then the correlating pairs will be n * m, although one pair is enough to illustrate the dependence.
We fix. We group all pairs by set (the indicator of the first member of the pair; the indicator of the second member of the pair; the sign of the correlation coefficient) and leave one representative from each group.
After that, 19,390 pairs remained in 11,278 rows of 501 indicators.
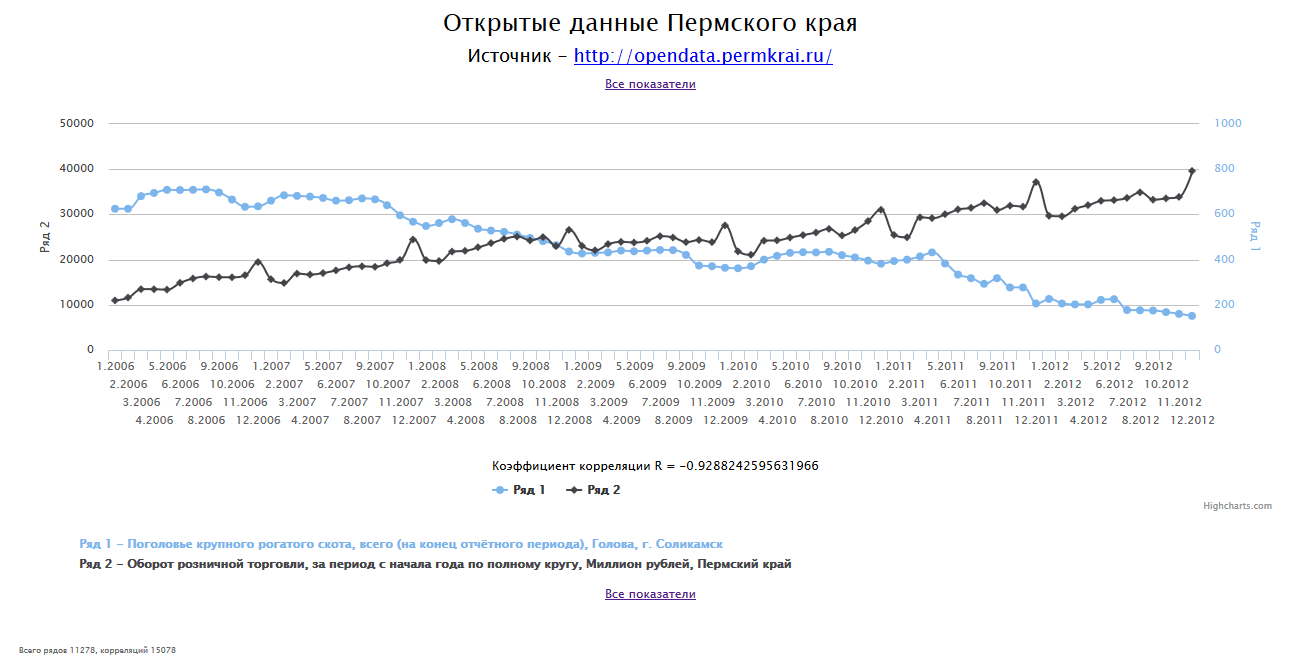
The resulting graphs can be viewed in two ways. You can refresh the page and get a random schedule each time. You can go to the list of all indicators and select the item of interest.
The site will be available until a couple hundred rubles allocated for it run out. Sources are available on github-e, if you wish, everyone can deploy the application and experiment with the data.
The application was created just for fun for three evenings. Evening spent on writing this article. We can assume that the day I missed. Hackathon a success!
The site opendata.permkrai.ru published about 1400 statistical indicators in various areas of the province. What can be done with this data? The first thought that came to my mind was to create an analogue of the site Spurious Correlations (false correlations).
Tl; DR:
Sources: github.com/yakov-bakhmatov/odpr
Application: odpr.bakhmatov.ru
Initial data
Methods for obtaining and data formats are described on the page for developers . In short, the web service provides metadata description (a list of indicators, a list of “cubes” - additional parameters of indicators, such as OKATO, OKVED, countries of the world, etc., a list of indicator-cube pairs) in xml format and the data itself (by a pair of indicator identifiers and a cube) in xml and csv formats.
')
To simplify the primary analysis with "eyes", I chose the csv format. In this format, the entries are
Calendar Level; Date; Indicator Name; Cube Additional Parameters; Value
Calendar level is a number from 1 to 5 (1 - year, 2 - half year, 3 - quarter, 4 - month, 5 - day).
A quick analysis revealed the following problems:
- For some indicators there is little data - one or two records. Such indicators just need to be discarded.
- There are data relating to other regions of Russia. Such lines need to be filtered.
- A large number of values is increasing with the beginning of the year. If you display them on a graph, you get a “saw”. It is better to “normalize” these values so that each of them contains numbers related to the specified quarter / month, and not to the period from the beginning of the year.
- There are gaps in the data - there is information not for all months / quarters in a year and not for all years in a row. I discarded the years with missing months / quarters, the figures with the missed years were excluded.
- Duplicate indicators.
All these problems are somehow solved, we proceed to the implementation of the idea.
The idea of the application
For each pair of indicators that have the same calendar level and overlapping date ranges, we calculate the Pearson correlation coefficient. We select those pairs whose modulus of the correlation coefficient is greater than 0.9 (| r |> 0.9). When opening (or updating) a web application page, we will show graphs of a random pair, built in one coordinate system.
You also need a list of all available pairs with a search or filter.
Instruments
I wanted to create an application quickly, trying to stay in the time frame of the hackathon. Here is my selection of tools:
- server part - clojure + http-kit;
- client part - clojurescript for the list of indicators, highcharts library for displaying charts;
- The best and time-tested nosql repository is simple files in the native format of clojure edn.
Process
Data loading
First, the data must be downloaded from the source. Here the first trouble was waiting - after pumping out several dozens of data files, the site opendata.permkrai.ru began to give the 500th error. I had to stretch this stage to several approaches.
Secondly, I decided to limit myself to the OKATO “cube”.
A total of 1151 files were downloaded, totaling 256 MiB.
Data preparation
Then, each file was sorted out, the lines were grouped by set (calendar level, indicator, OKATO).
Lines that are not related to the Perm region were discarded.
Doubles, missed periods were deleted. The values of the indicators were "normalized".
After this stage, 11,468 data series remain.
Correlation Calculation
There is nothing difficult. We calculate the correlation coefficient between two rows, if these rows belong to different indicators, have the same calendar level, have at least 8 points at the intersection of date ranges.
It turned out 129507 pairs with a correlation coefficient of more than 0.9 (or less than -0.9).
Post processing
Generally speaking, almost 130 thousand pairs is a lot. In a reasonable time, such a number of graphs simply cannot be seen.
But the fact is that within the indicator there can be a very small difference between the rows (and the correlation coefficient, on the contrary, is large - close to 1). If the indicator X contains n rows, and the indicator Y contains m rows, then the correlating pairs will be n * m, although one pair is enough to illustrate the dependence.
We fix. We group all pairs by set (the indicator of the first member of the pair; the indicator of the second member of the pair; the sign of the correlation coefficient) and leave one representative from each group.
After that, 19,390 pairs remained in 11,278 rows of 501 indicators.
Web application
The resulting graphs can be viewed in two ways. You can refresh the page and get a random schedule each time. You can go to the list of all indicators and select the item of interest.
Conclusion
The site will be available until a couple hundred rubles allocated for it run out. Sources are available on github-e, if you wish, everyone can deploy the application and experiment with the data.
The application was created just for fun for three evenings. Evening spent on writing this article. We can assume that the day I missed. Hackathon a success!
Source: https://habr.com/ru/post/242333/
All Articles