Quotient filter
A quotient filter is a probabilistic data structure that allows you to check whether an element belongs to a set. It is described in 2011 as a replacement for the Bloom filter. The answer may be:
- the element does not exactly belong to the set;
- the element probably belongs to the set.
')
The structure stores hashes of elements that belong to the set S:
F = h (S) = {h (x) | x in S}
That is why the structure is probabilistic.
Suppose we are looking for the element A. We calculate its hash and look for it in the structure.
Situation 1: element hash was not found. The answer is that the element does not exactly belong to the set.
Situation 2: when searching, a hash was found, but it is impossible to say for sure whether it belongs to element A. Sometimes it happens that the hashes of two different elements match (this coincidence is called a full collision). Therefore, we cannot say for sure whether we have found the hash of the element A or whether it was a collision. The answer is that the element probably belongs to the set.
The filter can be represented as a hash table T with m = 2 ^ q groups of hashes. To distribute hashes into groups, the “quotienting” method is used (hence the name of the filter). The method was proposed by Knut (The Art of Computer Programming: Searching and Sorting, volume 3. Section 6.4, exercise 13).
The hash is broken down into 2 parts:
quotient fq = f / (2 ^ r)
remainder fr = f mod (2 ^ r)
As a result, adding the hash f to the filter is reduced to adding a part of fr to the group T [fq]. The full hash is restored by the formula:
f = fq * (2 ^ r) + fr.
Formula (taken from [2])
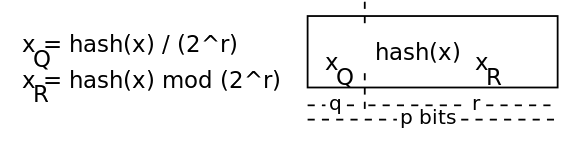
Table T is stored as an array of A [0..m - 1] elements with a length (r + 3) bits. Each slot in the array stores the remainder of the hash and 3 bits of information needed to restore the hash.
If the 2 private hashes match, then this is called a soft collision. All hashes that have private matches are stored in an array sequentially in a segment (run). In this case the condition is always fulfilled: if fq1 <fq2, then fr1 is always in the array before fr2.
Let's see what makes the additional 3 bits stored with each balance.
1. bit busy (is occupied). If slot i has this bit, then there is a hash in the array, which has a partial fq = i (but it may not be in this slot, but shifted further).
2. bit continuation (is continuation). If slot i has this bit, then the residue stored in it belongs to the same segment as the remainder stored in the previous slot i - 1.
3. bit offset (is shifted). If it is set, it means that the residue stored in slot i does not belong to group i, but was simply shifted.
If the offset bit = 0, then the remainder belonging to this slot (fq = i) is stored in slot i. The continuation bit allows you to understand when a segment ends. The busy bit allows you to determine the slot to which the segment belongs.
The combinations are well described on Wikipedia ([2])
is_occupied
__is_continuation
____is_shifted
0 0 0: Empty Slot
0 0 1: Slot is holding the canonical slot.
0 1 0: not used.
0 1 1: Slot is a holding slot that has been shifted from its canonical slot.
1 0 0: Slot is holding slot.
1 0 1: Slot is holding it out of the canonical slot.
The canonical slot exists but is shifted right.
1 1 0: not used.
1 1 1: Slot is a holding slot that has been shifted from its canonical slot.
The canonical slot exists but is shifted right.
The group of segments that go in a row without empty slots between them is called a cluster. The first slot of the cluster is always not shifted (offset bit = 0).
Example (taken from [1])
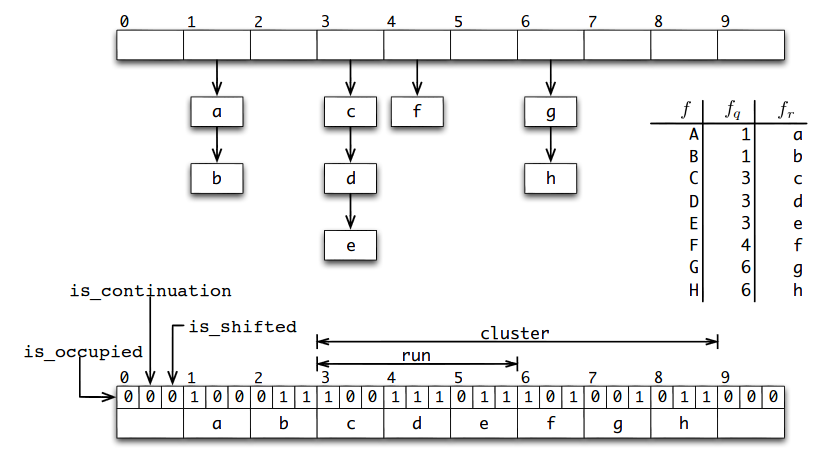
Above shows a hash table T. Many of the elements are identical, for example, a and b. Below is an array in which these elements are stored.
We find the hash of the f element, which we then break into the quotient fq and the remainder of fr. Check the slot fq in the array. If the busy bit is not worth it - the element is not contained in the filter.
If the slot is busy, it is necessary to find the beginning of the segment. The beginning of the segment may be located in the slot, or it may be shifted by another segment, therefore we are looking for the beginning of the cluster.
First we go to the left of our slot fq, until we find the beginning of the cluster (offset bit = 0). While we go to the left, we remember the number of segments that we have slipped. Each slot with a busy bit is the beginning of the segment. With each such slot we increase the segment counter.
Having found the beginning of the cluster, we begin to move to the right. Each slot with an unexposed continuation bit is the beginning of a new segment, i.e. the previous segment has ended. With each such slot we reduce the segment count. When the counter is reset - we found the segment we need. We run on it and compare with our remnant fr. If the segment is over, and the remainder is not found - the element is definitely not in the filter. If it was found, then perhaps the element is in the filter.
Example (taken from [2])
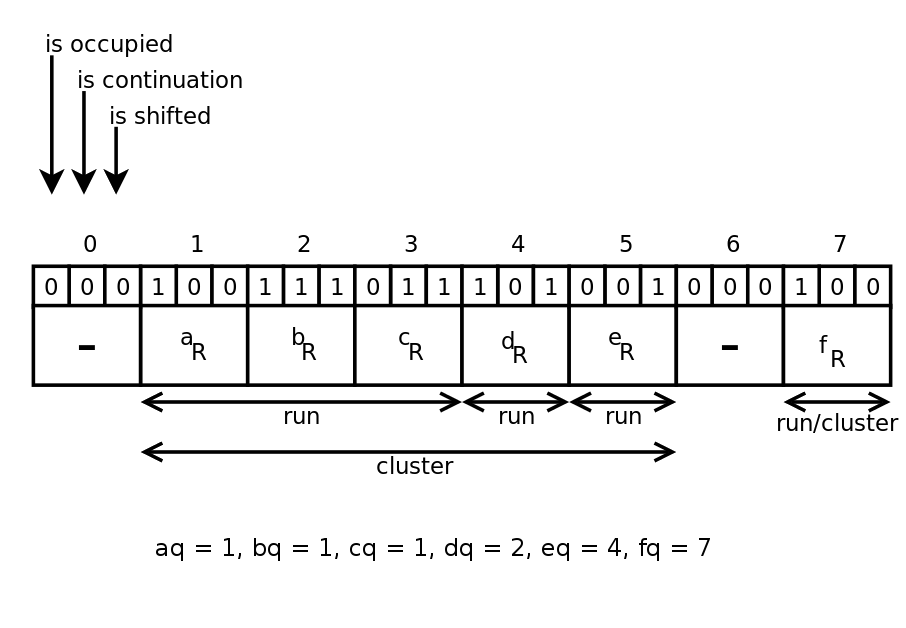
Looking for the element e. We calculate its hash, divide the hash by the quotient eq and the remainder er. eq = 4. In slot 4 there are bits of employment and offset (there is a dr residue in it), therefore there is an element in this slot, but it has been shifted. We are looking for the beginning of the cluster.
Moving left we remember that we passed 3 segments (the busy bit = 1 for slots 4, 2, 1). Slot 1 - the beginning of the cluster (offset bit = 0), we move to the right. The beginning of each segment is a slot with a continuation bit = 0. For the 1st segment - slot 1, for the 2nd segment - slot 4, for the 3rd segment - slot 5. We check every remainder in the 3rd segment, starting with slot 5 . In the 3rd segment there is only one remainder, and it coincides with the er calculated by us. The answer is that the element probably belongs to the set.
By the same algorithm as the search element, we are looking for a slot for fr. Finding the slot, insert / delete fr and shift the elements, if necessary. Then expose (for insertion) or remove (for deletion and if the deleted item was the only one with private = fq) the busy bit for slot A [fq].
When elements are shifted, the busy bits do not change. If the remainder was inserted at the beginning of the segment, then the remainder occupying this slot is shifted and becomes the continuation of the segment, therefore the continuation bit is set. For each residue that was shifted, set the offset bit.
Example (taken from [2])
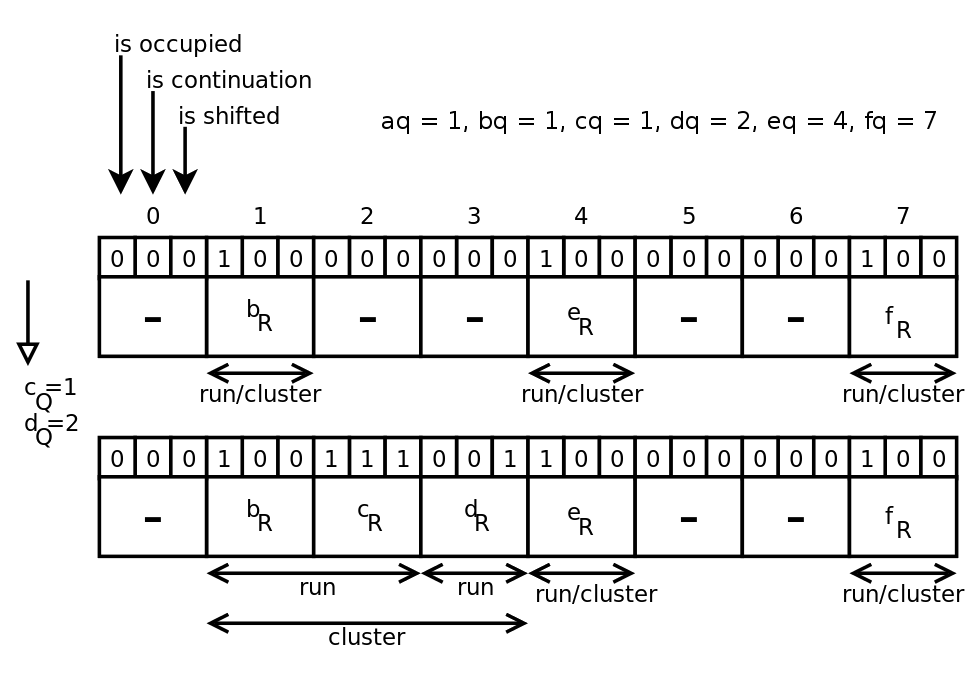
The insertion of elements c and d occurs.
bq = 1, cq = 1, br <cr, therefore the remainder cr is inserted into slot 2, the continuation and offset bits are inserted at slot 2.
dq = 2, so the slot 2 has a busy bit. But slot 2 is already taken, so dr falls into slot 3, the offset bit of slot 3 is affixed.
Why all this complex system? There are several advantages:
1. All data are arranged sequentially in memory. You need to load only the desired cluster, which is usually small, and not the entire array. This reduces the amount of misses in reading from the processor's data cache.
2. Ability to reduce / increase the size of the array. To do this, you do not need to hash the data again; it is enough to transfer one bit from the remainder to the private or vice versa.
3. Merge of two filters into one.
1. vldb.org/pvldb/vol5/p1627_michaelabender_vldb2012.pdf - description of the filter from the authors
2. en.wikipedia.org/wiki/Quotient_filter is a great Wikipedia article.
Write about errors and inaccuracies - I will gladly correct them.
- the element does not exactly belong to the set;
- the element probably belongs to the set.
Structure
')
The structure stores hashes of elements that belong to the set S:
F = h (S) = {h (x) | x in S}
That is why the structure is probabilistic.
Suppose we are looking for the element A. We calculate its hash and look for it in the structure.
Situation 1: element hash was not found. The answer is that the element does not exactly belong to the set.
Situation 2: when searching, a hash was found, but it is impossible to say for sure whether it belongs to element A. Sometimes it happens that the hashes of two different elements match (this coincidence is called a full collision). Therefore, we cannot say for sure whether we have found the hash of the element A or whether it was a collision. The answer is that the element probably belongs to the set.
The filter can be represented as a hash table T with m = 2 ^ q groups of hashes. To distribute hashes into groups, the “quotienting” method is used (hence the name of the filter). The method was proposed by Knut (The Art of Computer Programming: Searching and Sorting, volume 3. Section 6.4, exercise 13).
The hash is broken down into 2 parts:
quotient fq = f / (2 ^ r)
remainder fr = f mod (2 ^ r)
As a result, adding the hash f to the filter is reduced to adding a part of fr to the group T [fq]. The full hash is restored by the formula:
f = fq * (2 ^ r) + fr.
Formula (taken from [2])
Table T is stored as an array of A [0..m - 1] elements with a length (r + 3) bits. Each slot in the array stores the remainder of the hash and 3 bits of information needed to restore the hash.
If the 2 private hashes match, then this is called a soft collision. All hashes that have private matches are stored in an array sequentially in a segment (run). In this case the condition is always fulfilled: if fq1 <fq2, then fr1 is always in the array before fr2.
Information bits
Let's see what makes the additional 3 bits stored with each balance.
1. bit busy (is occupied). If slot i has this bit, then there is a hash in the array, which has a partial fq = i (but it may not be in this slot, but shifted further).
2. bit continuation (is continuation). If slot i has this bit, then the residue stored in it belongs to the same segment as the remainder stored in the previous slot i - 1.
3. bit offset (is shifted). If it is set, it means that the residue stored in slot i does not belong to group i, but was simply shifted.
If the offset bit = 0, then the remainder belonging to this slot (fq = i) is stored in slot i. The continuation bit allows you to understand when a segment ends. The busy bit allows you to determine the slot to which the segment belongs.
The combinations are well described on Wikipedia ([2])
is_occupied
__is_continuation
____is_shifted
0 0 0: Empty Slot
0 0 1: Slot is holding the canonical slot.
0 1 0: not used.
0 1 1: Slot is a holding slot that has been shifted from its canonical slot.
1 0 0: Slot is holding slot.
1 0 1: Slot is holding it out of the canonical slot.
The canonical slot exists but is shifted right.
1 1 0: not used.
1 1 1: Slot is a holding slot that has been shifted from its canonical slot.
The canonical slot exists but is shifted right.
The group of segments that go in a row without empty slots between them is called a cluster. The first slot of the cluster is always not shifted (offset bit = 0).
Example (taken from [1])
Above shows a hash table T. Many of the elements are identical, for example, a and b. Below is an array in which these elements are stored.
Item Search
We find the hash of the f element, which we then break into the quotient fq and the remainder of fr. Check the slot fq in the array. If the busy bit is not worth it - the element is not contained in the filter.
If the slot is busy, it is necessary to find the beginning of the segment. The beginning of the segment may be located in the slot, or it may be shifted by another segment, therefore we are looking for the beginning of the cluster.
First we go to the left of our slot fq, until we find the beginning of the cluster (offset bit = 0). While we go to the left, we remember the number of segments that we have slipped. Each slot with a busy bit is the beginning of the segment. With each such slot we increase the segment counter.
Having found the beginning of the cluster, we begin to move to the right. Each slot with an unexposed continuation bit is the beginning of a new segment, i.e. the previous segment has ended. With each such slot we reduce the segment count. When the counter is reset - we found the segment we need. We run on it and compare with our remnant fr. If the segment is over, and the remainder is not found - the element is definitely not in the filter. If it was found, then perhaps the element is in the filter.
Example (taken from [2])
Looking for the element e. We calculate its hash, divide the hash by the quotient eq and the remainder er. eq = 4. In slot 4 there are bits of employment and offset (there is a dr residue in it), therefore there is an element in this slot, but it has been shifted. We are looking for the beginning of the cluster.
Moving left we remember that we passed 3 segments (the busy bit = 1 for slots 4, 2, 1). Slot 1 - the beginning of the cluster (offset bit = 0), we move to the right. The beginning of each segment is a slot with a continuation bit = 0. For the 1st segment - slot 1, for the 2nd segment - slot 4, for the 3rd segment - slot 5. We check every remainder in the 3rd segment, starting with slot 5 . In the 3rd segment there is only one remainder, and it coincides with the er calculated by us. The answer is that the element probably belongs to the set.
Insert / delete item
By the same algorithm as the search element, we are looking for a slot for fr. Finding the slot, insert / delete fr and shift the elements, if necessary. Then expose (for insertion) or remove (for deletion and if the deleted item was the only one with private = fq) the busy bit for slot A [fq].
When elements are shifted, the busy bits do not change. If the remainder was inserted at the beginning of the segment, then the remainder occupying this slot is shifted and becomes the continuation of the segment, therefore the continuation bit is set. For each residue that was shifted, set the offset bit.
Example (taken from [2])
The insertion of elements c and d occurs.
bq = 1, cq = 1, br <cr, therefore the remainder cr is inserted into slot 2, the continuation and offset bits are inserted at slot 2.
dq = 2, so the slot 2 has a busy bit. But slot 2 is already taken, so dr falls into slot 3, the offset bit of slot 3 is affixed.
Differences from the Bloom filter
Why all this complex system? There are several advantages:
1. All data are arranged sequentially in memory. You need to load only the desired cluster, which is usually small, and not the entire array. This reduces the amount of misses in reading from the processor's data cache.
2. Ability to reduce / increase the size of the array. To do this, you do not need to hash the data again; it is enough to transfer one bit from the remainder to the private or vice versa.
3. Merge of two filters into one.
Links
1. vldb.org/pvldb/vol5/p1627_michaelabender_vldb2012.pdf - description of the filter from the authors
2. en.wikipedia.org/wiki/Quotient_filter is a great Wikipedia article.
Write about errors and inaccuracies - I will gladly correct them.
Source: https://habr.com/ru/post/242285/
All Articles