Speech recognition in FreePBX using Yandex Speechkit
Hi, Habr!
I decided to share the experience of integrating Asterisk and the voice recognition service of Yandex.
My customer caught fire to introduce Voice2Text feature into his PBX.
')
As PBX used FreePBX.
Immediately it occurred to the use of speech recognition services from Google, but after several hours of unsuccessful attempts to achieve the desired result, I decided to try a similar Yandex service.
Details under the cut.
Initial data:
FreePBX Distro 12 Stable-6.12.65, CentOS 6.5, Asterisk 11 + an incredible desire to implement the Voice2Text feature :)
By default, FreePBX writes all entries to .wav, we also need to transfer files for recognition to .mp3. For this we use sendmailmp3.
Work sendmailmp3 can be divided into several stages:
Let's use the script that installs sendmailmp3 and all the necessary packages.
Go to / tmp:
Download the script that installs sendmailmp3:
Making the file executable:
And run the script:
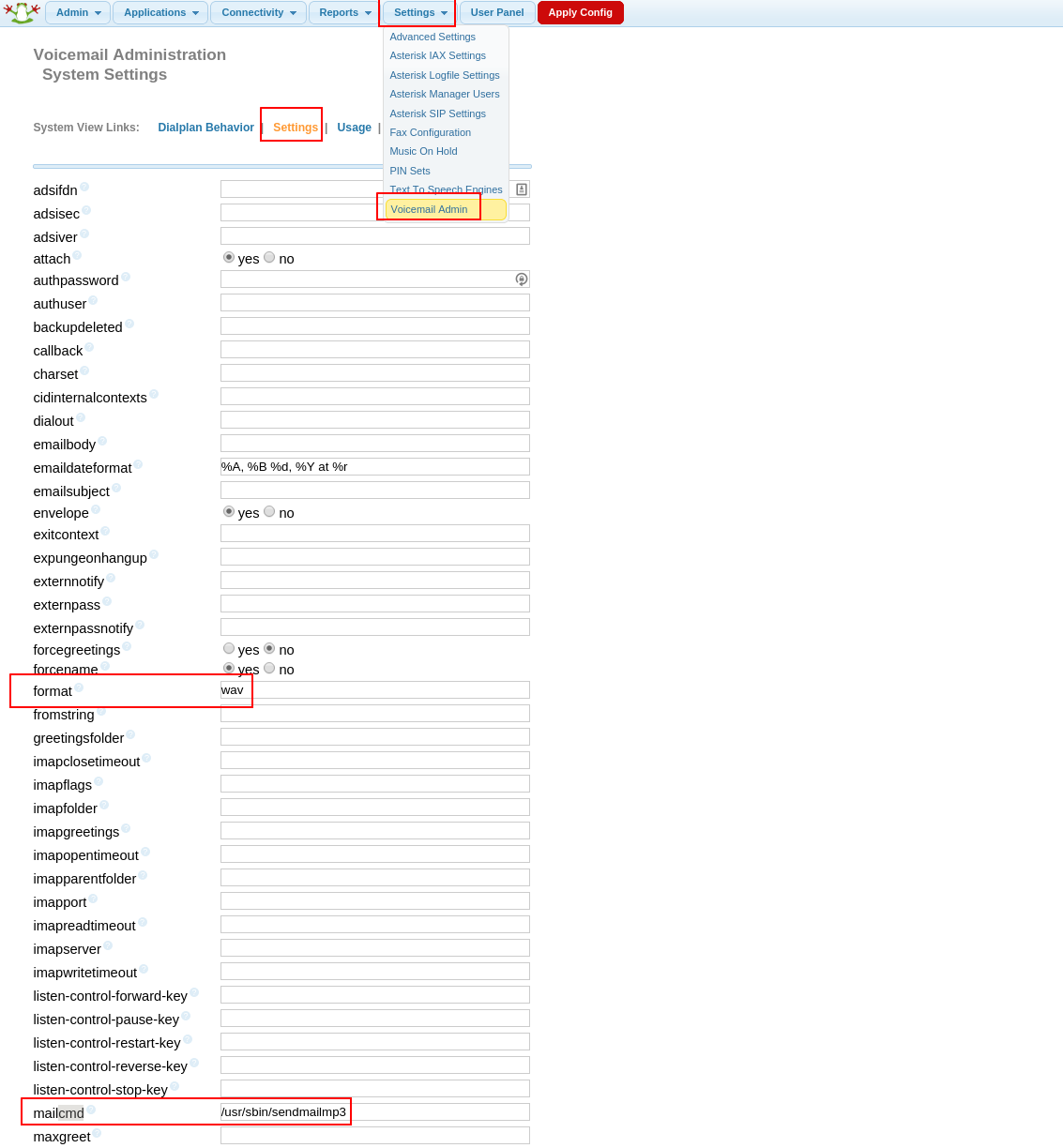
Next, go to the FreePBX web interface, the Settings tab, Voicemail Admin, Settings:
And there in the mailcmd field we write / usr / sbin / sendmailmp3
And in the field format: wav
Now our messages will be sent to the mail in mp3 format, we will add the Voice2Text feature.
The choice of Yandex services is due to the fact that you can send the file directly to mp3, and not transcode to flac or speex (at least I did not find any other information about the supported formats), and also because the maximum message length is much more than that of Google.
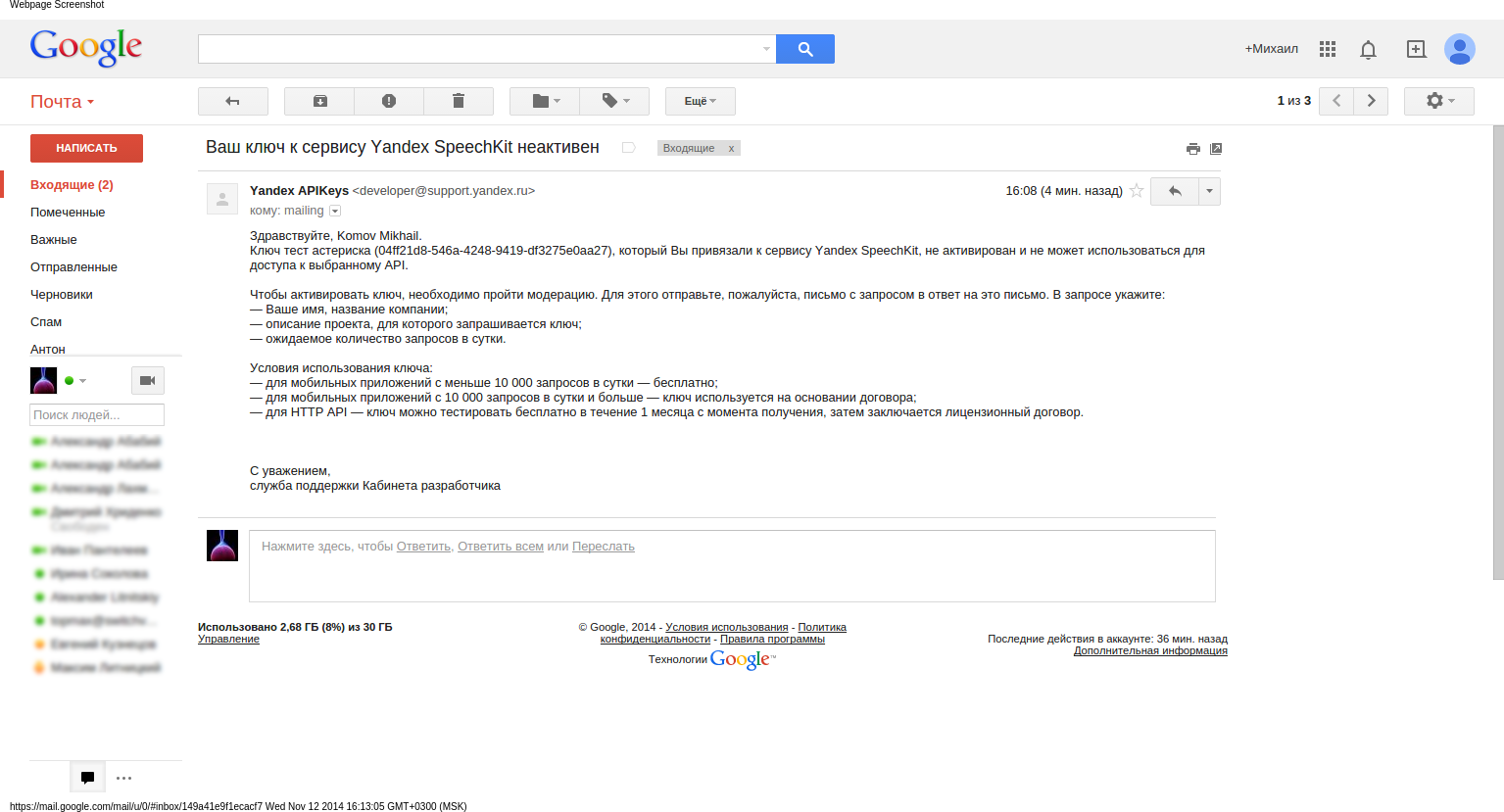
Before our script starts to work fully, you need to follow the link , then go to the developer’s office, log in to it using the Yandex mailbox and request the API key. After that, you will receive a letter to the specified mail with further instructions:
After your key is activated, you need to create a curl request that will send our file for recognition. The view should be as follows:
asr.yandex.net/asr_xml ?
uuid = <unique user id>
& key = <API key>
& topic = <voice request topic>
& [lang = <query language>]
The following formats are supported:
The answer is returned in the form of XML containing the n-best list of recognition hypotheses (up to 5 values), indicating the degree of confidence for each hypothesis.
An example of successful recognition:
<? xml version = "1.0" encoding = "utf-8"?>
Basmannaya street
An example of unsuccessful recognition:
<? xml version = "1.0" encoding = "utf-8"?>
/>
As a result, a message with recognition options and an attachment with an mp3 file like this falls onto the mailbox you specified:
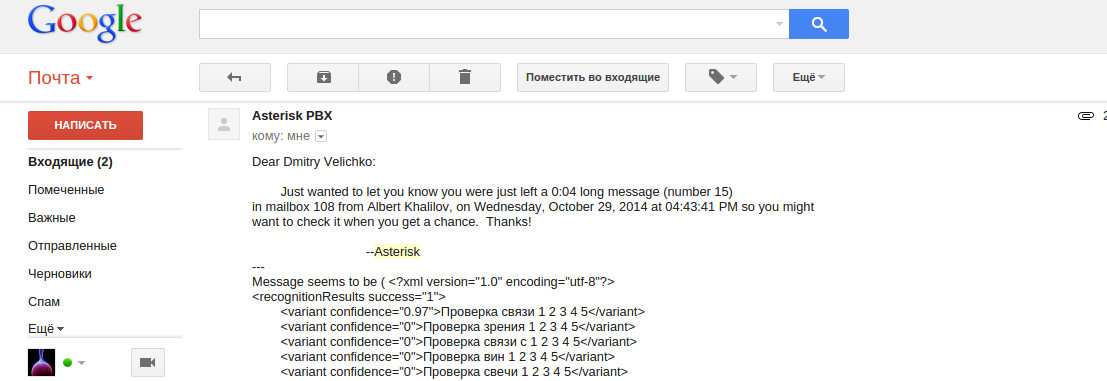
The resulting script is as follows:
In my opinion, this option is somewhat simpler than was described here , because it all comes down to launching and modifying one script and a couple of clicks in the web interface, and also sends recordings in mp3, not in .wav. Of course, someone will say that this is not a unix-way :), but maybe someone will be useful, if only for familiarization purposes.
I decided to share the experience of integrating Asterisk and the voice recognition service of Yandex.
My customer caught fire to introduce Voice2Text feature into his PBX.
')
As PBX used FreePBX.
Immediately it occurred to the use of speech recognition services from Google, but after several hours of unsuccessful attempts to achieve the desired result, I decided to try a similar Yandex service.
Details under the cut.
Initial data:
FreePBX Distro 12 Stable-6.12.65, CentOS 6.5, Asterisk 11 + an incredible desire to implement the Voice2Text feature :)
By default, FreePBX writes all entries to .wav, we also need to transfer files for recognition to .mp3. For this we use sendmailmp3.
Work sendmailmp3 can be divided into several stages:
- Catch the stream
- analyze email content
- split the message into parts
- extract audio file
- convert wav to mp3
- restore mail contents
- Send a message to the sendmail command
Let's use the script that installs sendmailmp3 and all the necessary packages.
Go to / tmp:
cd /tmp Download the script that installs sendmailmp3:
wget http://pbxinaflash.com/installmp3stt.sh Making the file executable:
chmod +x installmp3stt.sh And run the script:
./installmp3stt.sh Next, go to the FreePBX web interface, the Settings tab, Voicemail Admin, Settings:
And there in the mailcmd field we write / usr / sbin / sendmailmp3
And in the field format: wav
Now our messages will be sent to the mail in mp3 format, we will add the Voice2Text feature.
The choice of Yandex services is due to the fact that you can send the file directly to mp3, and not transcode to flac or speex (at least I did not find any other information about the supported formats), and also because the maximum message length is much more than that of Google.
Before our script starts to work fully, you need to follow the link , then go to the developer’s office, log in to it using the Yandex mailbox and request the API key. After that, you will receive a letter to the specified mail with further instructions:
After your key is activated, you need to create a curl request that will send our file for recognition. The view should be as follows:
asr.yandex.net/asr_xml ?
uuid = <unique user id>
& key = <API key>
& topic = <voice request topic>
& [lang = <query language>]
The following formats are supported:
- audio / x-speex 1
- audio / x-pcm; bit = 16; rate = 8000
- audio / x-pcm; bit = 16; rate = 16000 2
- audio / x-alaw; bit = 13; rate = 8000
- audio / x-wav
- audio / x-mpeg-3 3
The answer is returned in the form of XML containing the n-best list of recognition hypotheses (up to 5 values), indicating the degree of confidence for each hypothesis.
An example of successful recognition:
<? xml version = "1.0" encoding = "utf-8"?>
Basmannaya street
An example of unsuccessful recognition:
<? xml version = "1.0" encoding = "utf-8"?>
/>
As a result, a message with recognition options and an attachment with an mp3 file like this falls onto the mailbox you specified:
The resulting script is as follows:
sendmailmp3
#! /bin/sh # Asterisk voicemail attachment conversion script, including voice recognition using Google API # # Revision history : # 22/11/2010 - V1.0 - Creation by N. Bernaerts # 07/02/2012 - V1.1 - Add handling of mails without attachment (thanks to Paul Thompson) # 01/05/2012 - V1.2 - Use mktemp, pushd & popd # 08/05/2012 - V1.3 - Change mp3 compression to CBR to solve some smartphone compatibility (thanks to Luca Mancino) # 01/08/2012 - V1.4 - Add PATH definition to avoid any problem (thanks to Christopher Wolff) # 31/01/2013 - V2.0 - Add Google Voice Recognition feature (thanks to Daniel Dainty idea and sponsoring :-) # 04/02/2013 - V2.1 - Handle error in case of voicemail too long to be converted # set language for voice recognition (en-US, en-GB, fr-FR, ...) LANGUAGE="ru_RU" # set PATH PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" # save the current directory pushd . # create a temporary directory and cd to it TMPDIR=$(mktemp -d) cd $TMPDIR # dump the stream to a temporary file cat >> stream.org # get the boundary BOUNDARY=`grep "boundary=" stream.org | cut -d'"' -f 2` # cut the file into parts # stream.part - header before the boundary # stream.part1 - header after the bounday # stream.part2 - body of the message # stream.part3 - attachment in base64 (WAV file) # stream.part4 - footer of the message awk '/'$BOUNDARY'/{i++}{print > "stream.part"i}' stream.org # if mail is having no audio attachment (plain text) PLAINTEXT=`cat stream.part1 | grep 'plain'` if [ "$PLAINTEXT" != "" ] then # prepare to send the original stream cat stream.org > stream.new # else, if mail is having audio attachment else # cut the attachment into parts # stream.part3.head - header of attachment # stream.part3.wav.base64 - wav file of attachment (encoded base64) sed '7,$d' stream.part3 > stream.part3.wav.head sed '1,6d' stream.part3 > stream.part3.wav.base64 # convert the base64 file to a wav file dos2unix -o stream.part3.wav.base64 base64 -di stream.part3.wav.base64 > stream.part3.wav # convert wav file to mp3 file # -b 24 is using CBR, giving better compatibility on smartphones (you can use -b 32 to increase quality) # -V 2 is using VBR, a good compromise between quality and size for voice audio files lame -mm -b 24 stream.part3.wav stream.part3.mp3 # convert back mp3 to base64 file base64 stream.part3.mp3 > stream.part3.mp3.base64 # generate the new mp3 attachment header # change Type: audio/x-wav to Type: audio/mpeg # change name="msg----.wav" to name="msg----.mp3" sed 's/x-wav/mpeg/g' stream.part3.wav.head | sed 's/.wav/.mp3/g' > stream.part3.mp3.head # convert wav file to flac compatible for Google speech recognition # sox stream.part3.wav -r 16000 -b 16 -c 1 audio.flac vad reverse vad reverse lowpass -2 2500 # call Google Voice Recognition sending flac file as POST curl -v -4 "asr.yandex.net/asr_xml?key=23988820-8719-4a2e-82ba-9ddd5a9bfe67&uuid=12345678123456781234567812345678&topic=queries&lang=ru-RU" -H "Content-Type: audio/x-mpeg-3" --data-binary "@stream.part3.mp3" 1>audio.txt # curl --data-binary @audio.flac --header 'Content-type: audio/x-flac; rate=16000' 'https://www.google.com/speech-api/v2/recognize?key=AIzaSyB5lwncPRYpNrHXtN-Sy-LNDMLLU5vM1n8&xjerr=1&client=chromium&pfilter=0&lang='ru_RU'&maxresults=1' 1>audio.txt # extract the transcript and confidence results FILETOOBIG=`cat audio.txt | grep "<HTML>"` TRANSCRIPT=`cat audio.txt | cut -d"," -f3 | sed 's/^.*utterance\":\"\(.*\)\"$/\1/g'` CONFIDENCE=`cat audio.txt | cut -d"," -f4 | sed 's/^.*confidence\":0.\([0-9][0-9]\).*$/\1/g'` # generate first part of mail body, converting it to LF only mv stream.part stream.new cat stream.part1 >> stream.new sed '$d' < stream.part2 >> stream.new # beginning of transcription section echo "---" >> stream.new # if audio attachment is too big if [ "$FILETOOBIG" != "" ] then # error message echo "Voice message is too long to be transcripted." >> stream.new else # append result of transcription echo "Message seems to be ( $CONFIDENCE% confidence ) :" >> stream.new echo "$TRANSCRIPT" >> stream.new fi # end of message body tail -1 stream.part2 >> stream.new # append mp3 header cat stream.part3.mp3.head >> stream.new dos2unix -o stream.new # append base64 mp3 to mail body, keeping CRLF unix2dos -o stream.part3.mp3.base64 cat stream.part3.mp3.base64 >> stream.new # append end of mail body, converting it to LF only echo "" >> stream.tmp echo "" >> stream.tmp cat stream.part4 >> stream.tmp dos2unix -o stream.tmp cat stream.tmp >> stream.new fi # send the mail thru sendmail cat stream.new | sendmail -t # go back to original directory popd # remove all temporary files and temporary directory sleep 50 rm -Rf $TMPDIR In my opinion, this option is somewhat simpler than was described here , because it all comes down to launching and modifying one script and a couple of clicks in the web interface, and also sends recordings in mp3, not in .wav. Of course, someone will say that this is not a unix-way :), but maybe someone will be useful, if only for familiarization purposes.
Source: https://habr.com/ru/post/242109/
All Articles