How to just write a distributed web service in Python + AMQP
Hi, Habr. I have been writing in Python for quite some time. Recently had to deal with RabbitMQ. I like it. Because he without any problems (it is clear that with some subtleties) is going to cluster. Then I thought: it would be nice to use it as a message queue in a piece of the API of the project I'm working on. The API itself is written in tornado, the main point was to exclude the blocking code from the API. All synchronous operations were performed in the thread pool.
The first thing I decided was to make a separate process (s) “worker”, which would take over all the synchronous work. I conceived that the “worker” was as simple as possible, and made tasks from the queue one after another. Say I chose something from the database, answered, took over the next task, and so on. The workers themselves can be run a lot and then AMQP is already playing the role of some kind of IPC.
After some time, a module has grown out of it, which assumes all the routine associated with AMQP and the transfer of messages back and forth, and also compresses them with gzip if there is too much data. So was born the crew . Actually, using it, we will write a simple API that will consist of a server on tornado and simple and uncomplicated “worker” processes. Looking ahead, I’ll say that all code is available on github , and what I’m going to talk about next is collected in the example folder .
So, let's understand in order. The first thing we need to do is install RabbitMQ. How to do this, I will not describe. Let me just say that on the same ubunt he is put and works out of the box. On my Mac, the only thing I had to do was put LaunchRocket, which collected all the services that were installed through homebrew and brought to the GUI:
')

Next we create our project virtualenv and install the module itself through pip:
In the module dependencies, the tornado is not intentionally indicated, since it may not be on the host with a worker. And web parts usually create requirements.txt, where all other dependencies are listed.
I will write the code in parts so as not to disturb the order of the narration. What we will have in the end, you can see here .
The tornado server itself consists of two parts. In the first part, we define handlers request handlers, and in the second, an event-loop is run. Let's write the server and create our first api method.
Master.py file:
Thanks to coroutine in a tornado, the code looks easy. You can write the same without coroutine.
Master.py file:
Our server is ready. But if we run it, and we go to /, then we will not wait for an answer, there is no one to handle it.
Now we write a simple worker:
File worker.py:
So, as you can see in the code, there is a simple function wrapped by the Task Decorator (“test”), where test is the unique identifier of the task. In your worker there can not be two tasks with the same identifiers. Of course, it would be correct to call the task “crew.example.test” (which is usually what I call in the production environment), but for our example, simply “test” is enough.
Immediately striking context.settings.counter. This is a kind of context that is initialized in the worker process when the run function is called. Also, the context already has context.headers - these are the response headers for separating the metadata from the response. In the example with the callback function, this particular dictionary is passed to _on_response.
Headers are reset after each response, but context.settings do not. I use context.settings to pass to the worker (s) function the connection to the database and, in general, any other object.
Also worker processes startup keys, there are not many of them:
URL connection to the database and other variables can be taken from the environment variable. Therefore, a worker in the parameters waits only for him to connect with AMQP (host and port) and the logging level.
So, we start everything and check:
When starting the tornado server, tornado connected to RabbitMQ, created Exchange DLX and started listening to the DLX queue. This is a Dead-Letter-Exchange - a special queue in which tasks fall, which no worker has taken over a specific timeout. He also created a queue with a unique identifier, where answers from workers will be received.
After running, worker created in turn for each queue wrapped by the Decorator Task and subscribed to them. When a task arrives, the main-loop worker creates a single thread, controlling the execution time of the task in the main thread and performing the wrapped function. After return from the wrapped function, it serializes it and enqueues the server in the response queue.
After the request is received, the tornado server assigns the task to the appropriate queue, indicating the identifier of its unique queue to which the response should be received. If no worker has taken the task, then RabbitMQ redirects the task to the exchange DLX and the tornado server receives a message that the queue timeout has expired, generating an exception.
To demonstrate how the mechanism for completing tasks, which are hung during execution, works, we will write another web method and task in the worker.
In the master.py file add:
And add it to the list of handlers:
And in worker.py:
As you can see from the example above, the task will go into an infinite loop. However, if the task fails in 3 seconds (counting the time it takes it to get out of the queue), the main loop in the worker will send the SystemExit exception to the stream. And yes, you have to process it.
As mentioned above, the context is such a special object that is imported and has several built-in variables.
Let's make simple statistics on the answers of our worker.
Add the following handler to the master.py file:
Also register in the list of request handlers:
This handler is not very different from the previous ones, it simply returns the value that the worker passed to him.
Now the task itself.
In the file worker.py add:
The function returns a string with information about the number of tasks processed by the worker.
Now we implement a couple of handlers. One at the request will just hang and wait, and the second will take POST data. After the transfer of the latter, the first will give them.
master.py:
Let's write the publish task.
worker.py:
If you do not need to transfer control to the worker, you can simply publish directly from the tornado server
Often there is a situation where we can perform several tasks in parallel. The crew has a little syntactic sugar for this:
In this case, the task will be assigned two tasks in parallel and the exit from with will be made at the end of the last.
But you need to be careful, as some task may cause an exception. It will be equated directly to the variable. Thus, you need to check if test_result and stat_result are not instances of the Exception class.
When eigrad offered to write an interlayer, with which you can start any wsgi application using the crew, I immediately liked this idea. Just imagine, requests will not rush to your wsgi application, but will flow evenly through the queue at wsgi-worker.
I have never written a wsgi server and do not even know where to start. But you can help me, pull-requests I accept.
I also think to add a client for another popular asynchronous framework, for twisted. But while I deal with it, I don’t have enough free time.
Thanks to the developers of RabbitMQ and AMQP. Great ideas.
Also thank you, readers. I hope you do not waste time.
The first thing I decided was to make a separate process (s) “worker”, which would take over all the synchronous work. I conceived that the “worker” was as simple as possible, and made tasks from the queue one after another. Say I chose something from the database, answered, took over the next task, and so on. The workers themselves can be run a lot and then AMQP is already playing the role of some kind of IPC.
After some time, a module has grown out of it, which assumes all the routine associated with AMQP and the transfer of messages back and forth, and also compresses them with gzip if there is too much data. So was born the crew . Actually, using it, we will write a simple API that will consist of a server on tornado and simple and uncomplicated “worker” processes. Looking ahead, I’ll say that all code is available on github , and what I’m going to talk about next is collected in the example folder .
Training
So, let's understand in order. The first thing we need to do is install RabbitMQ. How to do this, I will not describe. Let me just say that on the same ubunt he is put and works out of the box. On my Mac, the only thing I had to do was put LaunchRocket, which collected all the services that were installed through homebrew and brought to the GUI:
')
Next we create our project virtualenv and install the module itself through pip:
mkdir -p api cd api virtualenv env source env/bin/activate pip install crew tornado In the module dependencies, the tornado is not intentionally indicated, since it may not be on the host with a worker. And web parts usually create requirements.txt, where all other dependencies are listed.
I will write the code in parts so as not to disturb the order of the narration. What we will have in the end, you can see here .
Write the code
The tornado server itself consists of two parts. In the first part, we define handlers request handlers, and in the second, an event-loop is run. Let's write the server and create our first api method.
Master.py file:
# encoding: utf-8 import tornado.ioloop import tornado.gen import tornado.web import tornado.options class MainHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): # test c 100 resp = yield self.application.crew.call('test', priority=100) self.write("{0}: {1}".format(type(resp).__name__, str(resp))) application = tornado.web.Application( [ ('/', MainHandler), ], autoreload=True, debug=True, ) if __name__ == "__main__": tornado.options.parse_command_line() application.listen(8888) tornado.ioloop.IOLoop.instance().start() Thanks to coroutine in a tornado, the code looks easy. You can write the same without coroutine.
Master.py file:
class MainHandler(tornado.web.RequestHandler): def get(self): # test c 100 self.application.crew.call('test', priority=100, callback=self._on_response) def _on_response(resp, headers): self.write("{0}: {1}".format(type(resp).__name__, str(resp))) Our server is ready. But if we run it, and we go to /, then we will not wait for an answer, there is no one to handle it.
Now we write a simple worker:
File worker.py:
# encoding: utf-8 from crew.worker import run, context, Task @Task('test') def long_task(req): context.settings.counter += 1 return 'Wake up Neo.\n' run( counter=0, # This is a part of this worker context ) So, as you can see in the code, there is a simple function wrapped by the Task Decorator (“test”), where test is the unique identifier of the task. In your worker there can not be two tasks with the same identifiers. Of course, it would be correct to call the task “crew.example.test” (which is usually what I call in the production environment), but for our example, simply “test” is enough.
Immediately striking context.settings.counter. This is a kind of context that is initialized in the worker process when the run function is called. Also, the context already has context.headers - these are the response headers for separating the metadata from the response. In the example with the callback function, this particular dictionary is passed to _on_response.
Headers are reset after each response, but context.settings do not. I use context.settings to pass to the worker (s) function the connection to the database and, in general, any other object.
Also worker processes startup keys, there are not many of them:
$ python worker.py --help Usage: worker.py [options] Options: -h, --help show this help message and exit -v, --verbose make lots of noise --logging=LOGGING Logging level -H HOST, --host=HOST RabbitMQ host -P PORT, --port=PORT RabbitMQ port URL connection to the database and other variables can be taken from the environment variable. Therefore, a worker in the parameters waits only for him to connect with AMQP (host and port) and the logging level.
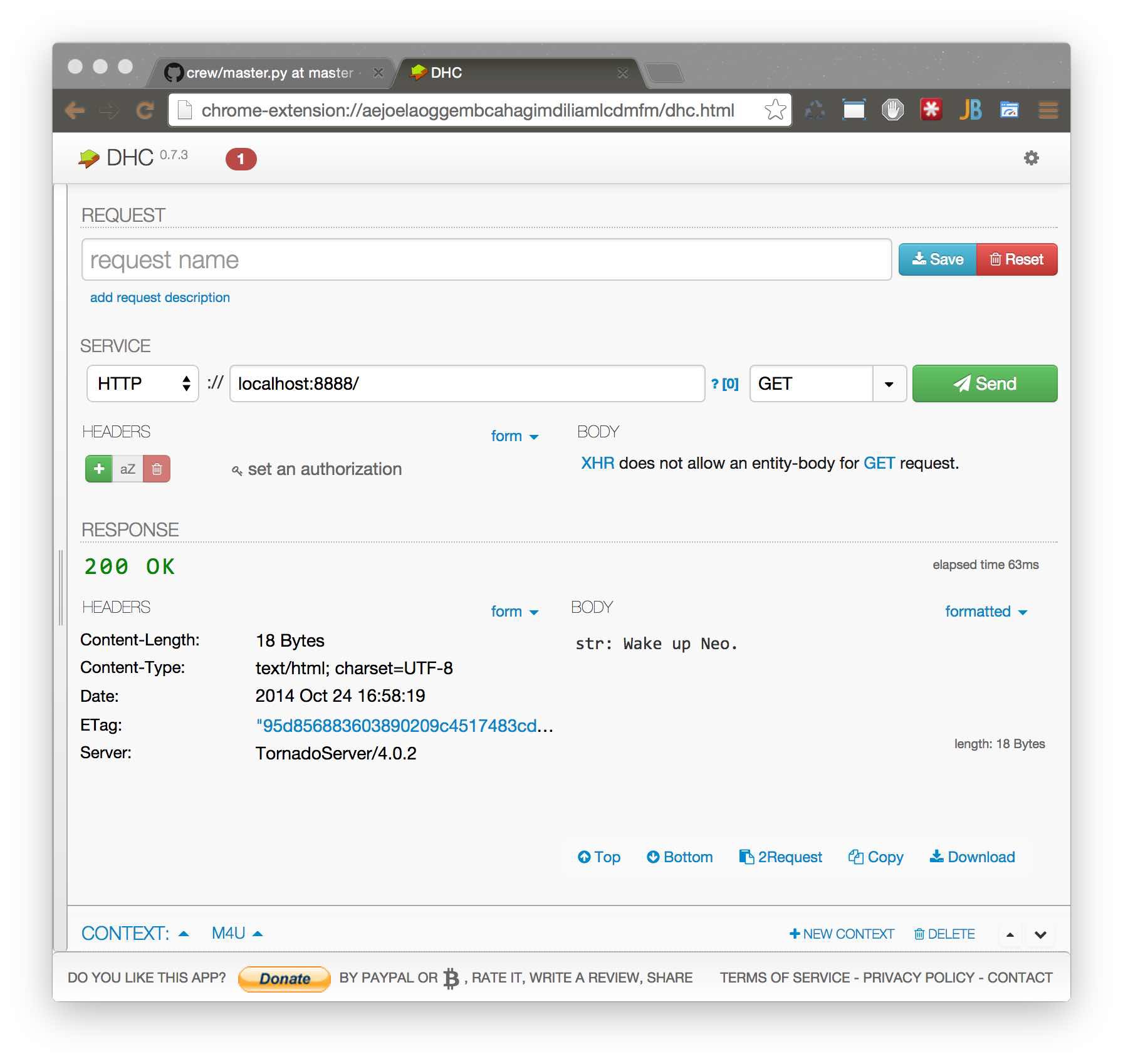
So, we start everything and check:
$ python master.py & python worker.py It works, but what happened behind the screen?
When starting the tornado server, tornado connected to RabbitMQ, created Exchange DLX and started listening to the DLX queue. This is a Dead-Letter-Exchange - a special queue in which tasks fall, which no worker has taken over a specific timeout. He also created a queue with a unique identifier, where answers from workers will be received.
After running, worker created in turn for each queue wrapped by the Decorator Task and subscribed to them. When a task arrives, the main-loop worker creates a single thread, controlling the execution time of the task in the main thread and performing the wrapped function. After return from the wrapped function, it serializes it and enqueues the server in the response queue.
After the request is received, the tornado server assigns the task to the appropriate queue, indicating the identifier of its unique queue to which the response should be received. If no worker has taken the task, then RabbitMQ redirects the task to the exchange DLX and the tornado server receives a message that the queue timeout has expired, generating an exception.
Hanging task
To demonstrate how the mechanism for completing tasks, which are hung during execution, works, we will write another web method and task in the worker.
In the master.py file add:
class FastHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): try: resp = yield self.application.crew.call( 'dead', persistent=False, priority=255, expiration=3, ) self.write("{0}: {1}".format(type(resp).__name__, str(resp))) except TimeoutError: self.write('Timeout') except ExpirationError: self.write('All workers are gone') And add it to the list of handlers:
application = tornado.web.Application( [ (r"/", MainHandler), (r"/stat", StatHandler), ], autoreload=True, debug=True, ) And in worker.py:
@Task('dead') def infinite_loop_task(req): while True: pass As you can see from the example above, the task will go into an infinite loop. However, if the task fails in 3 seconds (counting the time it takes it to get out of the queue), the main loop in the worker will send the SystemExit exception to the stream. And yes, you have to process it.
Context
As mentioned above, the context is such a special object that is imported and has several built-in variables.
Let's make simple statistics on the answers of our worker.
Add the following handler to the master.py file:
class StatHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): resp = yield self.application.crew.call('stat', persistent=False, priority=0) self.write("{0}: {1}".format(type(resp).__name__, str(resp))) Also register in the list of request handlers:
application = tornado.web.Application( [ (r"/", MainHandler), (r"/fast", FastHandler), (r"/stat", StatHandler), ], autoreload=True, debug=True, ) This handler is not very different from the previous ones, it simply returns the value that the worker passed to him.
Now the task itself.
In the file worker.py add:
@Task('stat') def get_counter(req): context.settings.counter += 1 return 'I\'m worker "%s". And I serve %s tasks' % (context.settings.uuid, context.settings.counter) The function returns a string with information about the number of tasks processed by the worker.
PubSub and Long polling
Now we implement a couple of handlers. One at the request will just hang and wait, and the second will take POST data. After the transfer of the latter, the first will give them.
master.py:
class LongPoolingHandler(tornado.web.RequestHandler): LISTENERS = [] @tornado.web.asynchronous def get(self): self.LISTENERS.append(self.response) def response(self, data): self.finish(str(data)) @classmethod def responder(cls, data): for cb in cls.LISTENERS: cb(data) cls.LISTENERS = [] class PublishHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def post(self, *args, **kwargs): resp = yield self.application.crew.call('publish', self.request.body) self.finish(str(resp)) ... application = tornado.web.Application( [ (r"/", MainHandler), (r"/stat", StatHandler), (r"/fast", FastHandler), (r'/subscribe', LongPoolingHandler), (r'/publish', PublishHandler), ], autoreload=True, debug=True, ) application.crew = Client() application.crew.subscribe('test', LongPoolingHandler.responder) if __name__ == "__main__": application.crew.connect() tornado.options.parse_command_line() application.listen(8888) tornado.ioloop.IOLoop.instance().start() Let's write the publish task.
worker.py:
@Task('publish') def publish(req): context.pubsub.publish('test', req) If you do not need to transfer control to the worker, you can simply publish directly from the tornado server
class PublishHandler2(tornado.web.RequestHandler): def post(self, *args, **kwargs): self.application.crew.publish('test', self.request.body) Parallel execution of tasks
Often there is a situation where we can perform several tasks in parallel. The crew has a little syntactic sugar for this:
class Multitaskhandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self, *args, **kwargs): with self.application.crew.parallel() as mc: # mc - multiple calls mc.call('test') mc.call('stat') test_result, stat_result = yield mc.result() self.set_header('Content-Type', 'text/plain') self.write("Test result: {0}\nStat result: {1}".format(test_result, stat_result)) In this case, the task will be assigned two tasks in parallel and the exit from with will be made at the end of the last.
But you need to be careful, as some task may cause an exception. It will be equated directly to the variable. Thus, you need to check if test_result and stat_result are not instances of the Exception class.
Future plans
When eigrad offered to write an interlayer, with which you can start any wsgi application using the crew, I immediately liked this idea. Just imagine, requests will not rush to your wsgi application, but will flow evenly through the queue at wsgi-worker.
I have never written a wsgi server and do not even know where to start. But you can help me, pull-requests I accept.
I also think to add a client for another popular asynchronous framework, for twisted. But while I deal with it, I don’t have enough free time.
Thanks
Thanks to the developers of RabbitMQ and AMQP. Great ideas.
Also thank you, readers. I hope you do not waste time.
Source: https://habr.com/ru/post/241740/
All Articles