Rushim Captcha SilkRoad

Silk Road, the famous black market, was closed about a year ago. Until recently, I thought he was dead. This would make writing an article easier, but not so well. I just read about his return to the network.
Now I want to delve into the code that I wrote a few years ago to disassemble the captcha mechanism of the “old” version of the site.
Motivation
I first heard about The Silk Road in articles gwern'a . After connecting Tor, I got the opportunity to see this site.
')
My first thought is this: there is a lot of interesting real-time market data that is difficult to access programmatically.
Is it really Drug Wars with a real price upgrade?
Indices that show
MJ ▲0.21 , COKE ▼3.53 ?After a while, I could collect a price history for all these products.
I have already begun to imagine graphs, schemes and cases of
Sr::Listing . First we need to automate the authorization process.All the code in this article will be presented in Ruby, but I will not publish the API for two reasons:
- Most likely, it just does not work anymore;
- It has never been neatly decorated.
Tor
Silk Road has been converted to a hidden service TOR. So our API should call Tor.
Vidalia opens locally SOCKS5 proxy on startup. You must configure the client for correct HTTP requests. Fortunately, socksify gem allows us to do this. This trick will allow us to convert SOCKS requests in our
auto_configure application. require 'socksify' require 'socksify/http' module Sr class TorError < RuntimeError; end class Tor # Loads the torproject test page and tests for the success message. # Just to be sure. def self.test_tor? uri = 'https://check.torproject.org/?lang=en-US' begin page = Net::HTTP.get(URI.parse(uri)) return true if page.match(/browser is configured to use Tor/i) rescue ; end false end # Our use case has the Tor SOCKS5 proxy running locally. On unix, we use # `lsof` to see the ports `tor` is listening on. def self.find_tor_ports p = `lsof -i tcp | grep "^tor" | grep "\(LISTEN\)"` p.each_line.map do |l| m = l.match(/localhost:([0-9]+) /) m[1].to_i end end # Configures future connections to use the Tor proxy, or raises TorError def self.auto_configure! return true if @configured TCPSocket::socks_server = 'localhost' ports = find_tor_ports ports.each do |p| TCPSocket::socks_port = p if test_tor? @configured = true return true end end TCPSocket::socks_server = nil TCPSocket::socks_port = nil fail TorError, "SOCKS5 connection failed; ports: #{ports}" end end end All is ready. We have created a fairly simple process.
Captcha
Now we come to the topic of the article: SilkRoad captcha bypass.
I've never done this before, so it should be interesting. All the above code is the result of six hours of work.
I decided to call the project successful if the application recognizes text with an accuracy of one third of all codes.
In the end, it turned out to do something more than planned.
Due to the fact that the authors of Silk Road had to develop paranoia in themselves, they could not use services like reCAPTCHA. I’m not sure that their decision was samopisny in the end, but let's look at a few examples:




There are several obvious features of this captcha:
- Standard format: a dictionary word cropped to five characters, along with a number from 0 to 999;
- The font never changes;
- Any symbol can be at any position along the X axis;
- Any symbol can be rotated, but only a few degrees;
- In the background, there is something like a spiral that does not painfully contrast with the text;
- They are all horrible and pink, which gives us one channel of color information.
I wrote Mechanize , which downloaded 2,000 captcha examples from the site at two-second intervals. After I decided them by hand, calling in the format (text)
.jpg . It was very sad, believe me.But there are pluses: I received many test samples in my new application.
We remove the background
The most, in my opinion, the right step to start. At this stage, I wanted to get images in shades of gray, containing only characters (preferably), as well as screening out all the "noise" of the image.
Using Gimp, I played with several effects and several sequences. I had mistakes, but ultimately I got this:
Original:
Corrected:

Shades of gray, 0.09:
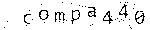
The result was obtained with the following code for RMagick :
# Basic image processing gets us to a black and white image # with most background removed def remove_background(im) im = im.equalize im = im.threshold(Magick::MaxRGB * 0.09) # the above processing leaves a black border. Remove it. im = im.trim '#000' im end This freed our image from unnecessary details, but still there was “garbage” - small black dots between the letters. Let's get rid of them:
# Consider a pixel "black enough"? In a grayscale sense. def black?(p) return p.intensity == 0 || (Magick::MaxRGB.to_f / p.intensity) < 0.5 end # True iff [x,y] is a valid pixel coordinate in the image def in_bounds?(im, x, y) return x >= 0 && y >= 0 && x < im.columns && y < im.rows end # Returns new image with single-pixel "islands" removed, # see: Conway's game of life. def despeckle(im) xydeltas = [[-1, -1], [0, -1], [+1, -1], [-1, 0], [+1, 0], [-1, +1], [0, +1], [+1, +1]] j = im.dup j.each_pixel do |p, x, y| if black?(p) island = true xydeltas.each do |dx2, dy2| if in_bounds?(j, x + dx2, y + dy2) && black?(j.pixel_color(x + dx2, y + dy2)) island = false break end end im = im.color_point(x, y, '#fff') if island end end im end So we got something like this:
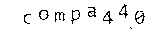
Wonderful.
Segmentation
Now I want to cut our captcha into bitmaps so that each contains one character. We move around the image from left to right, looking for white indents.
# returns true if column "x" is blank (non-black) def blank_column?(im, x) (0 ... im.rows).each do |y| return false if black?(im.pixel_color(x, y)) end true end # finds columns of white, and splits the image into characters, yielding each def each_segmented_character(im) return enum_for(__method__, im) unless block_given? st = 0 x = 0 while x < im.columns # Zoom over to the first non-blank column x += 1 while x < im.columns && blank_column?(im, x) # That's now our starting point. st = x # Zoom over to the next blank column, or end of the image. x += 1 while x < im.columns && (!blank_column?(im, x) || (x - st < 2)) # slivers smaller than this can't possibly work: it's noise. if x - st >= 4 # The crop/trim here also removes vertical whitespace, which puts the # resulting bitmap into its minimal bounding box. yield im.crop(st, 0, x - st, im.rows).trim('#fff') end end end This cuts off our captcha on the same pieces:
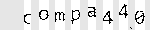
Then each piece turns into a separate box with a letter, thus separating from the others.
I executed this code for many of the previously prepared caps, and this is what happened in some cases:

Think of it as a histogram. Dark areas are places where the algorithm cut the image. You can see offsets ...
We also see how the rotation of symbols affects the clarity of the result. If the characters rotated at a large angle, then our task would be significantly more complicated.
So, every character is quite possible to read. Since the letters are taken from an English dictionary, the more frequently used symbols are more clearly visible. We will review this question later.
But did not know that J is used so rarely!
Neural networks for character recognition
There is a cool Ruby gem called AI4R . Since
Ai4r::Positronic not always available, I decided to use a neural network.You start with an empty array of bits. You teach him drawings of famous solutions:
- "Such a model is A."
- "And this model is also in A."
- "This model is found in V."
After checking for a variety of examples, several suitable candidate symbols appear, and the network will tell you the correct option using its base.
But there are difficulties. The more characters you have and the more parameters for recognition you specify, the longer it will take to train the algorithm.
I took each character into squares, made it 20x20 in size and applied a monochrome effect, and began training.
require 'ai4r' require 'RMagick' module Sr class Brain def initialize @keys = *(('a'..'z').to_a + ('0'..'9').to_a) @ai = Ai4r::NeuralNetwork::Backpropagation.new([GRID_SIZE * GRID_SIZE, @keys.size]) end # Returns a flat array of 0 or 1 from the image data, suitable for # feeding into the neural network def to_data(image) # New image of our actual grid size, then paste it over padded = Magick::Image.new(GRID_SIZE, GRID_SIZE) padded = padded.composite(image, Magick::NorthWestGravity, Magick::MultiplyCompositeOp) padded.get_pixels(0, 0, padded.columns, padded.rows).map do |p| ImageProcessor.black?(p) ? 1 : 0 end end # Feed this a positive example, eg, train('a', image) def train(char, image) outputs = [0] * @keys.length outputs[ @keys.index(char) ] = 1.0 @ai.train(to_data(image), outputs) end # Return all guesses, eg, {'a' => 0.01, 'b' => '0.2', ...} def classify_all(image) results = @ai.eval(to_data(image)) r = {} @keys.each.with_index do |v, i| r[v] = results[i] end r end # Returns best guess def classify(image) res = @ai.eval(to_data(image)) @keys[res.index(res.max)] end end end I changed my mechanize tool to load new captchas. This time, the captcha solved the algorithm, and then performed authorization in the system.
Correctly guessed codes are automatically broken down into characters by character and added to the base of examples to improve the application knowledge.
When the authorization attempt failed, the captcha sent a separate folder so that I could solve it myself. As soon as I changed the name of the captcha to her answer, the algorithm took the image, divided it into squares and replenished its base. From time to time I had to solve a couple of dozen examples.
After several hours of training, the percentage of successfully solved problems was 90%.
Unfortunately, the captcha length was usually equal to eight characters, therefore, the probability of a successful solution was 0.90 ** 8, or 43%. My initial goal was achieved, but I wanted more.
Use of the dictionary and frequency of use of letters
At times, our network gave strange candidate solutions that did not correspond to reality. Something weird that didn't fit the format. She recognized characters independently and combined the result without further context.
But the “verbal” part of the captcha was not random letters, but rather parts of real words. Cut off words from a special list. If I had a sheet, then it would be possible to build a logical chain of reasoning to improve the result of character recognition. This is how I generated my word list:
cat /usr/share/dict/words *.txt | tr AZ az | grep -v '[^az]' \ | cut -c1-5 | grep '...' | sort | uniq > dict5.txt Afterwards, I could assume that
dict5.txt contained all the possible options that the captcha could contain. # Returns the "word" and "number" part of a captcha separately. # "word" takes the longest possible match def split_word(s) s.match(/(.+?)?(\d+)?\z/.to_a.last(2) rescue [nil, nil] end def weird_word?(s) w, d = split_word(s) # nothing matched? return true if w.nil? || d.nil? # Digit in word part?, Too long? return true if w.match /\d/ || w.size > 5 # Too many digits? return true if d.size > 3 # Yay return false end def in_dict?(w) return dict.bsearch { |p| p >= w } == w end But how to fix strange words that are not in the dictionary?
My first thought was to look at the list of candidates of the system, but the matter was different. The script performed poor-quality segmentation, alas
Let's take a look at this interesting table:
# az English text letter frequency, according to Wikipedia LETTER_FREQ = { a: 0.08167, b: 0.01492, c: 0.02782, d: 0.04253, e: 0.12702, f: 0.02228, g: 0.02015, h: 0.06094, i: 0.06966, j: 0.00153, k: 0.00772, l: 0.04025, m: 0.02406, n: 0.06749, o: 0.07507, p: 0.01929, q: 0.00095, r: 0.05987, s: 0.06327, t: 0.09056, u: 0.02758, v: 0.00978, w: 0.02360, x: 0.00150, y: 0.01974, z: 0.00074 } Noticed our poor and rarely used J again?
Peter Norvig wrote an interesting article How to write a pronunciation corrector . We have a dictionary and, presumably, a word with a typo. Let's fix this:
# This finds every dictionary entry that is a single replacement away from # word. It returns in a clever priority: it tries to replace digits first, # then the alphabet, in z..e (frequency) order. As we're just focusing on the # "word" part, "9" is most definitely a mistake, and "z" is more likely a # mistake than "e". def edit1(word) # Inverse frequency, "zq...e" letter_freq = LETTER_FREQ.sort_by { |k, v| v }.map(&:first).join # Total replacement priority: 0..9zq..e replacement_priority = ('0'..'9').to_a.join + letter_freq # Generate splits, tagged with the priority, then sort them so # the splits on least-frequent english characters get processed first splits = word.each_char.with_index.map do |c, i| # Replace what we're looking for with a space w = word.dup; w[i] = ' ' [replacement_priority.index(c), w] end splits.sort_by!{|k,v| k}.map!(&:last) # Keep up with results so we don't end up with duplicates yielded = [] splits.each do |w| letter_freq.each_char do |c| candidate = w.sub(' ', c) next if yielded.include?(candidate) if in_dict?(candidate) yielded.push(candidate) yield candidate end end end end The big trick is to replace. Using the table of frequency of use of symbols and a list of possible words that differ only by one symbol from the options proposed by the network, we simply replace the symbol with the one needed to correct the "typo".
This step increased the success rate from 43% to 56%. It made me realize that the goal is really achieved.
An article about breaking a new (second) Captcha SilkRoad will be published soon. Do not miss!
Thanks for the idea of the article ilusha_sergeevich
Source: https://habr.com/ru/post/241145/
All Articles