Enterprise OpenStack and Database as a Service (DBaaS)
Posted by: John Devereaux
As OpenStack evolves and the community provides new functionality at the request of private and corporate clients, there is one important service that should benefit from infrastructure as a service (IaaS) managed by OpenStack, which is the database as a service (dBaaS). The development of dBaaS focused efforts of the participants of the project OpenStack called Trove. Most Trove conversations revolve around the open source MySQL database, but other enterprise-level databases, such as Oracle dB 12c, can actually run under Trove’s control, such as the actual functionality that the company should provide with Trove, including including multi-tenancy.

')
Database (DB) is one of the most critical services for an enterprise. Its function is to store data, make it possible to search, analyze and extract data for applications. Clients need the ability to scale both relational and non-relational cloud databases. The main objective of the Trove project is to provide OpenStack users with the ability to easily and efficiently manage the database, bypassing the complexity associated with the administration of the database itself.
At the moment, the Trove model looks like this:
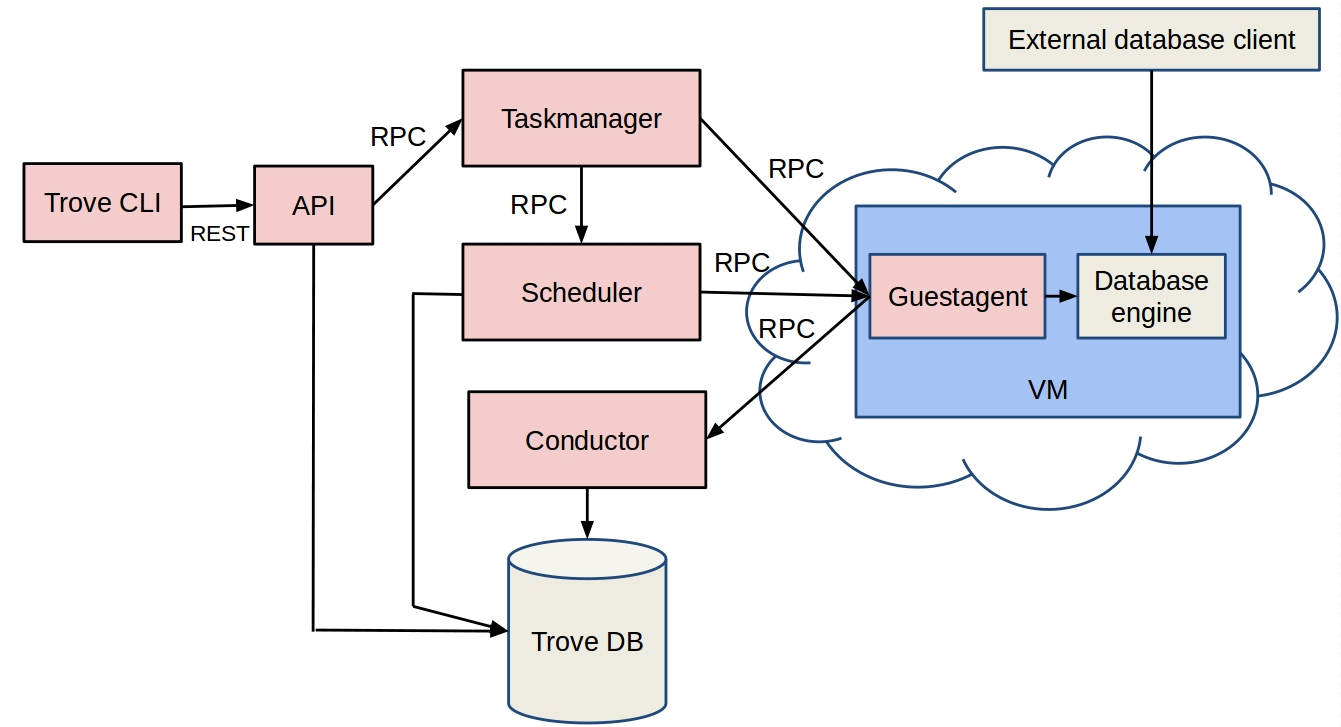
Be that as it may, another important goal of a Trove project is to allocate resources and automate complex operations, which are usually performed by a maintenance engineer / DBA. These include: deploying the database, applying database patches, backing up data and restoring the database, monitoring the database and setting up a new database.
To date, the process of creating an instance of a database based on the current Trove build looks like this:

This corresponds to the steps below:
Step 1: A request to create a virtual database is sent.
Step 2: A request is made for authentication via Keystone.
Step 3: A copy of the Trove is provided (which also leads to the creation of a new VM on which the database will run).
Step 4: Trove returns a response that includes the description of the instance, including:
a.ID instance
b.Type or version of data storage
c. size of volume
d.IP address of instance
e. Other requested or required variables
At the moment, the limitation of the OpenStack DBaaS platform is that Trove so far supports only the operation of instances with one tenant. One of the new features of Oracle dB 12c is multi-tenancy, which is a critical functionality currently being implemented by customers such as Thomson Reuters and other financial companies. Considering the growing interest in OpenStack on their part, including the implementation of this functionality in a development plan is critical for attracting clients in the financial sector.
A multi-tenant architecture allows a single instance of software (software) to provide services to multiple clients. Each such client is called a tenant. Tenants may be able to customize some components of the application, such as the color of the user interface, but they do not have the ability to customize the application code.
A multi-tenant architecture can be economical, since in this case the costs of software development and maintenance are shared between tenants. It can be opposed to a single tenant architecture (single-tenancy), in which each client has their own copy of the software, and can also have access to the code. With a multi-tenant architecture, the provider needs to do updates only once. With a single tenant architecture, it is necessary for the provider to reach several software instances to apply the updates.
The current Oracle plan for the OpenStack Trove:
1. Each tenant receives a dedicated copy of the database.
a. based on a preconfigured VM image;
b. the tenant works at the compute node / nodes and at the node / nodes for storing data.
2. The client has the ability to fully control the services.
3. Support should be provided for any database application, any database query language and connection methods.
4. Oracle will change its licensing model for every CPU / core for the first time and announce the monthly subscription prices.
To implement these changes, Trove needs to slightly modify the architecture:
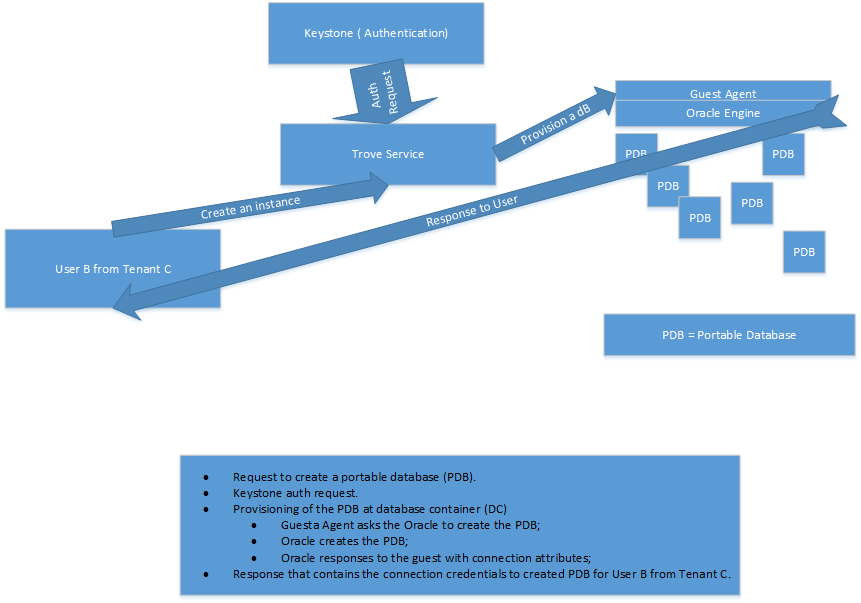
In this case, the task flow looks like this:
1. The user sends a request to the database (in our case it is a portable database (PDB).
2.Keystone receives an authorization request.
3. Provided container database (DC):
a. The guest agent asks Oracle to create a PDB.
b.Oracle creates a PDB.
c.Oracle sends a response to the guest agent with connection attributes.
4. The reply containing the credentials of the connection is returned to the user.
For this to work, the Trove project requires the following components:
a.API-server (API Server) - receives requests and calls directly to the guest agents for solving operational tasks, such as obtaining a list of database users, but it calls the task manager to solve complex periodic tasks.
b. The Message Bus is a message queue broker (Messaging Queue Broker) that routes messages between API points, such as a task manager and a guest agent, via HTTP requests.
c. The Task Manager is the “workhorse” of the system, which is responsible for provisioning instances, monitoring the life cycle of each instance and performing operations on any instance. It interacts with the API server, receiving and responding to messages. Remember, both Task Manager and the API server need to call HTTP functions to access OpenStack services.
d. Guest Agent — A service running on a guest instance that is running a database and managing and executing operations in the data warehouse. It provides online data storage and sends the heartbeat signal to the API via the Conductor service.
e. Conductor is a guest service running on a host that is responsible for receiving messages from guest instances to update information on a host. When performing database backup, Explorer performs the necessary actions using RPC messages transmitted via the message bus, as follows:
1.trove-conductor is the entry point
2.RpcService, configured in /etc/trove/trove-conductor.conf, defines the conductor manager
3. Requests are in the message queue.
4. Heartbeat updates the status of all instances. There are three main options: NEW (NEW), BUILDING (CREATED) and ACTIVE (ACTIVE). You can add other statuses.
However, Trove is not quite ready for such a new structure.
The community development plan for the Icehouse release includes the following items:
• Kernel generalization to improve extensibility.
• Support for database versions with multiple cores.
• Support for provisioning and cluster management.
• Extensibility for building complete architectures (using Conductor and Scheduler components).
• Support for functionalities like “parameters-group” of the Amazon relational database service.
• Automate and run tasks on a schedule.
• Designate / Ceilometer support.
• Automation of failure handling.
• Coverage of Tempest tests.
For today in this list is absent, though there should be multi-lending. When using services such as Murano (it allows your users to choose which database service to deploy with the appropriate settings of the variety), the ability to determine the amount of resources that need to be allocated for a given tenant is attractive to corporate clients who want to make maximum use of the orchestration tool for combining the management and operation of the components of their equipment and software. Murano, for example, enhances access control using the Keystone service, which guarantees access only to specified users and allows Trove to interact with guest agents, which makes it possible to quickly create a database.
All of this functionality is attractive to enterprise-level users, and for many this is enough. But for those customers who need an additional level of corporate functionality, the development plan for Trove should include movement in this direction.
Original article in English .
As OpenStack evolves and the community provides new functionality at the request of private and corporate clients, there is one important service that should benefit from infrastructure as a service (IaaS) managed by OpenStack, which is the database as a service (dBaaS). The development of dBaaS focused efforts of the participants of the project OpenStack called Trove. Most Trove conversations revolve around the open source MySQL database, but other enterprise-level databases, such as Oracle dB 12c, can actually run under Trove’s control, such as the actual functionality that the company should provide with Trove, including including multi-tenancy.
')
Database as a service (DBaaS)
Database (DB) is one of the most critical services for an enterprise. Its function is to store data, make it possible to search, analyze and extract data for applications. Clients need the ability to scale both relational and non-relational cloud databases. The main objective of the Trove project is to provide OpenStack users with the ability to easily and efficiently manage the database, bypassing the complexity associated with the administration of the database itself.
At the moment, the Trove model looks like this:
Be that as it may, another important goal of a Trove project is to allocate resources and automate complex operations, which are usually performed by a maintenance engineer / DBA. These include: deploying the database, applying database patches, backing up data and restoring the database, monitoring the database and setting up a new database.
Trove today
To date, the process of creating an instance of a database based on the current Trove build looks like this:
This corresponds to the steps below:
Step 1: A request to create a virtual database is sent.
Step 2: A request is made for authentication via Keystone.
Step 3: A copy of the Trove is provided (which also leads to the creation of a new VM on which the database will run).
Step 4: Trove returns a response that includes the description of the instance, including:
a.ID instance
b.Type or version of data storage
c. size of volume
d.IP address of instance
e. Other requested or required variables
At the moment, the limitation of the OpenStack DBaaS platform is that Trove so far supports only the operation of instances with one tenant. One of the new features of Oracle dB 12c is multi-tenancy, which is a critical functionality currently being implemented by customers such as Thomson Reuters and other financial companies. Considering the growing interest in OpenStack on their part, including the implementation of this functionality in a development plan is critical for attracting clients in the financial sector.
Multi-Affinity and Trove
A multi-tenant architecture allows a single instance of software (software) to provide services to multiple clients. Each such client is called a tenant. Tenants may be able to customize some components of the application, such as the color of the user interface, but they do not have the ability to customize the application code.
A multi-tenant architecture can be economical, since in this case the costs of software development and maintenance are shared between tenants. It can be opposed to a single tenant architecture (single-tenancy), in which each client has their own copy of the software, and can also have access to the code. With a multi-tenant architecture, the provider needs to do updates only once. With a single tenant architecture, it is necessary for the provider to reach several software instances to apply the updates.
The current Oracle plan for the OpenStack Trove:
1. Each tenant receives a dedicated copy of the database.
a. based on a preconfigured VM image;
b. the tenant works at the compute node / nodes and at the node / nodes for storing data.
2. The client has the ability to fully control the services.
3. Support should be provided for any database application, any database query language and connection methods.
4. Oracle will change its licensing model for every CPU / core for the first time and announce the monthly subscription prices.
To implement these changes, Trove needs to slightly modify the architecture:
In this case, the task flow looks like this:
1. The user sends a request to the database (in our case it is a portable database (PDB).
2.Keystone receives an authorization request.
3. Provided container database (DC):
a. The guest agent asks Oracle to create a PDB.
b.Oracle creates a PDB.
c.Oracle sends a response to the guest agent with connection attributes.
4. The reply containing the credentials of the connection is returned to the user.
For this to work, the Trove project requires the following components:
a.API-server (API Server) - receives requests and calls directly to the guest agents for solving operational tasks, such as obtaining a list of database users, but it calls the task manager to solve complex periodic tasks.
b. The Message Bus is a message queue broker (Messaging Queue Broker) that routes messages between API points, such as a task manager and a guest agent, via HTTP requests.
c. The Task Manager is the “workhorse” of the system, which is responsible for provisioning instances, monitoring the life cycle of each instance and performing operations on any instance. It interacts with the API server, receiving and responding to messages. Remember, both Task Manager and the API server need to call HTTP functions to access OpenStack services.
d. Guest Agent — A service running on a guest instance that is running a database and managing and executing operations in the data warehouse. It provides online data storage and sends the heartbeat signal to the API via the Conductor service.
e. Conductor is a guest service running on a host that is responsible for receiving messages from guest instances to update information on a host. When performing database backup, Explorer performs the necessary actions using RPC messages transmitted via the message bus, as follows:
1.trove-conductor is the entry point
2.RpcService, configured in /etc/trove/trove-conductor.conf, defines the conductor manager
3. Requests are in the message queue.
4. Heartbeat updates the status of all instances. There are three main options: NEW (NEW), BUILDING (CREATED) and ACTIVE (ACTIVE). You can add other statuses.
However, Trove is not quite ready for such a new structure.
In perspective
The community development plan for the Icehouse release includes the following items:
• Kernel generalization to improve extensibility.
• Support for database versions with multiple cores.
• Support for provisioning and cluster management.
• Extensibility for building complete architectures (using Conductor and Scheduler components).
• Support for functionalities like “parameters-group” of the Amazon relational database service.
• Automate and run tasks on a schedule.
• Designate / Ceilometer support.
• Automation of failure handling.
• Coverage of Tempest tests.
For today in this list is absent, though there should be multi-lending. When using services such as Murano (it allows your users to choose which database service to deploy with the appropriate settings of the variety), the ability to determine the amount of resources that need to be allocated for a given tenant is attractive to corporate clients who want to make maximum use of the orchestration tool for combining the management and operation of the components of their equipment and software. Murano, for example, enhances access control using the Keystone service, which guarantees access only to specified users and allows Trove to interact with guest agents, which makes it possible to quickly create a database.
All of this functionality is attractive to enterprise-level users, and for many this is enough. But for those customers who need an additional level of corporate functionality, the development plan for Trove should include movement in this direction.
Original article in English .
Source: https://habr.com/ru/post/240951/
All Articles