Asynchrony 2: teleport through portals

Less than a year, as I got to continue the article about asynchrony. This article develops the ideas of the very first article about asynchrony [1] . It discusses a rather complicated task, by the example of which the power and flexibility of using coroutines in various nontrivial scenarios will be revealed. In conclusion, we will consider two tasks on the race condition (race-condition), as well as a small but very nice bonus.
For all this time, the first article has already hit the search top.
So let's go!
')

Task
The original wording is straightforward and sounds like this:
Get a heavy object over the network and transfer it to the UI.
We will complicate the task by adding “interesting” requirements on the UI:
- The action is generated from the UI stream through an event.
- The result must be returned back to the UI.
- We do not want to block the UI, so the operation must be done asynchronously.
Add "fun" conditions for obtaining the object:
- Network operations are slow, so the object will be cached.
- I want to have a persistent cache so that after restart the objects are saved.
- The persistent device is slow, so for faster return of objects we will additionally cache them in memory.
Let's take a look at the performance aspects:
- It would be desirable to have parallel, but not sequential record in caches (persistent storage and memory).
- Reading from caches should also be parallel, while if the value is found in one of the caches, then use it immediately, without waiting for a response from the other cache.
- Network operations should not in any way interfere with caches, that is, if, for example, caches are stupid, then this should not affect network interactions.
- I want to support a large number of connections in a limited number of threads, that is, I want asynchronous network interaction for a more careful attitude to resources.
Let us make logic worse:
- We will need to cancel operations.
- Moreover, if we received our object through the network, then cancellation should not be further applied to subsequent cache update operations, that is, it is necessary to implement a “cancellation cancellation” for some set of actions.
If it seemed to someone not hardcore enough, then we will add more requirements:
- It is necessary to implement timeouts on operations. And timeouts should be both for the whole operation, and for some parts. For example:
- timeout for all network interaction: connection, request, response;
- timeout for the entire operation, including network interaction and work with caches.
- Operations schedulers can be either their own or foreign (for example, a scheduler in a UI thread).
- No operations should block threads. This means that the use of mutexes and other synchronization tools is prohibited, as they will block our threads.

Now that's enough. If someone immediately had the answer, how to do it, then I will be happy to get acquainted with this decision. Well, below I propose my solution: it is clear that it will focus not on implementation, for example, caches and persistence, but on concrete parallel and asynchronous interaction taking into account the requirements for locks and schedulers.
Decision
To solve, we will use the following model.
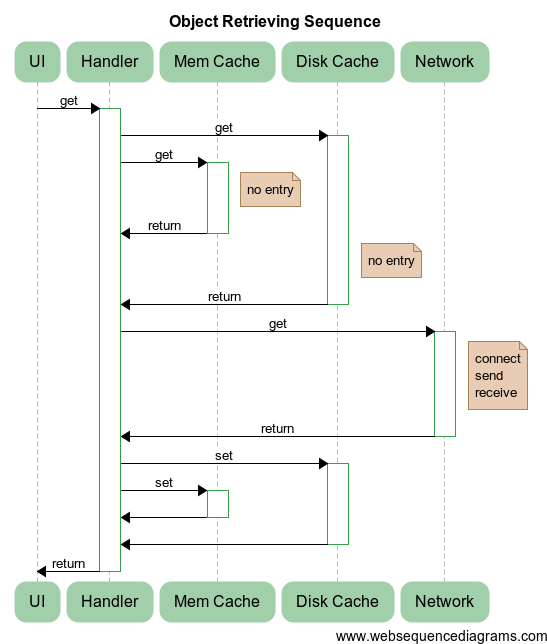
I will describe the essence of what is happening:
UI,Mem Cache,Disk Cache,Networkare the objects that perform the corresponding operations on our newly createdHandler.Handlerperforms a simple sequence:- In parallel, it starts the operation of retrieving data from the caches of the objects
Mem CacheandDisk Cache. If successful, that is, when receiving a response with the result found from at least one cache, it returns the result immediately. And in case of failure (as in the diagram), the execution continues. - After waiting for a lack of result from both caches,
Handleraccesses theNetworkto retrieve the object over the network. To do this, connect to the service (connect), send a request (send) and receive a response (receive). Such operations are performed asynchronously and do not block other network interactions. - The object received from the
Networkcomponent is written in parallel to both caches. - After waiting for the completion of writing to the cache, the value is returned to the UI stream.
- In parallel, it starts the operation of retrieving data from the caches of the objects
- The program contains the following schedulers and associated objects:
- A UI thread that initiates an asynchronous
Handleroperation and to which the result should return; - a common thread pool in which all the basic operations are performed, including
Mem CacheandDisk Cache; - network thread pool for
Network. It is created separately from the main thread pool so that the load on the main pool does not affect the network thread pool.
- A UI thread that initiates an asynchronous
As I wrote earlier, the objects will be implemented in the simplest way, since for aspects of asynchrony this does not really matter:
// stub: struct DiskCache { boost::optional<std::string> get(const std::string& key) { JLOG("get: " << key); return boost::optional<std::string>(); } void set(const std::string& key, const std::string& val) { JLOG("set: " << key << ";" << val); } }; // : - struct MemCache { boost::optional<std::string> get(const std::string& key) { auto it = map.find(key); return it == map.end() ? boost::optional<std::string>() : boost::optional<std::string>(it->second); } void set(const std::string& key, const std::string& val) { map[key] = val; } private: std::unordered_map<std::string, std::string> map; }; struct Network { // ... // std::string get(const std::string& key) { net::Socket socket; JLOG("connecting"); socket.connect(address, port); // - Buffer sz(1, char(key.size())); socket.write(sz); // - socket.write(key); // socket.read(sz); Buffer val(size_t(sz[0]), 0); // socket.read(val); JLOG("val received"); return val; } private: std::string address; int port; // ... }; // UI-: UI struct UI : IScheduler { void schedule(Handler handler) { // UI- // ... } void handleResult(const std::string& key, const std::string& val) { TLOG("UI result inside UI thread: " << key << ";" << val); // TODO: add some actions } }; As a rule, all UI frameworks contain a method that allows you to run necessary actions in a UI stream (for example, in Android:
Activity.runOnUiThread , Ultimate ++: PostCallback , Qt: via the signal-slot mechanism). These methods should be used in the implementation of the UI::schedule method.Initialization of the entire economy takes place in an imperative style:
// ThreadPool cpu(3, "cpu"); // ThreadPool net(2, "net"); // Alone diskStorage(cpu, "disk storage"); // Alone memStorage(cpu, "mem storage"); // scheduler<DefaultTag>().attach(cpu); // service<NetworkTag>().attach(net); // service<TimeoutTag>().attach(cpu); // portal<DiskCache>().attach(diskStorage); // portal<MemCache>().attach(memStorage); // portal<Network>().attach(net); UI& ui = single<UI>(); // UI- UI- portal<UI>().attach(ui); In the UI thread, for some user action we perform:
go([key] { // timeout : 1=1000 Timeout t(1000); std::string val; // boost::optional<std::string> result = goAnyResult<std::string>({ [&key] { return portal<DiskCache>()->get(key); }, [&key] { return portal<MemCache>()->get(key); } }); if (result) { // val = std::move(*result); JLOG("cache val: " << val); } else { // // { // : 0.5=500 Timeout tNet(500); val = portal<Network>()->get(key); } JLOG("net val: " << val); // // ( ) EventsGuard guard; // goWait({ [&key, &val] { portal<DiskCache>()->set(key, val); }, [&key, &val] { portal<MemCache>()->set(key, val); } }); JLOG("cache updated"); } // UI portal<UI>()->handleResult(key, val); }); 
Implementation of primitives used
As the attentive reader noted, I used a considerable number of primitives, the implementation of which can only be guessed. Therefore, below is a description of the approach and classes used. I think it will clarify what portals are, how to use them, and also answer the question about teleportation.

Waiting primitives
Let's start with the simplest - waiting for primitives.
goWait: starting an asynchronous operation and waiting for completion
So, for the seed, we will implement a function that will asynchronously start the operation and wait for it to complete:
void goWait(Handler); Of course, launching a handler in the current coroutine is quite suitable as an implementation. But in more complex scenarios, this does not suit us, so we will create a new coroutine to implement this function:
void goWait(Handler handler) { deferProceed([&handler](Handler proceed) { go([proceed, &handler] { // handler(); proceed(); // }); }); } I will describe briefly what is happening here. At the input of the goWait function, we get a handler, which should be run in a new coroutine. To perform the necessary operations, we use the
deferProceed function, which is implemented as follows: typedef std::function<void(Handler)> ProceedHandler; void deferProceed(ProceedHandler proceed) { auto& coro = currentCoro(); defer([&coro, proceed] { proceed([&coro] { coro.resume(); }); }); } What does this feature do? It actually wraps the defer call for more convenient use (what
defer and why it should be used, described in my previous article ), namely: it accepts not Handler , but ProceedHandler , in which Handler is passed as an input parameter to continue execution of the coroutine. Actually, proceed itself saves in its object a reference to the current coroutine and calls coro.resume() . Thus, we encapsulate all the work with coroutines, and the user only needs to work with the proceed handler.Go back to the
goWait function. So, when we call deferProceed , we have proceed , which needs to be called at the end of the operation in the handler . All we have to do is create a new coroutine, run our handler handler in it, and after it completes, immediately call proceed, which internally calls coro.resume() , thus continuing the execution of the original coroutine.This gives us a wait without blocking the thread: during a call to
goWait we sort of pause our operations in the current coroutine, and when the transferred handler finishes, we continue execution as if nothing had happened.goWait: start several asynchronous operations and wait for them to complete
Now we will implement a function that starts a whole batch of asynchronous operations and waits for them to complete:
void goWait(std::initializer_list<Handler> handlers); At the entrance we have a list of handlers that need to be run asynchronously, that is, each handler will start in its coroutine. The essential difference from the previous function is that we need to continue the execution of the original coroutine only after all handlers are completed. Some use for this purpose all sorts of mutexes and condition variables (and so some people actually do!), But we can't do that (see requirements), so we will look for other ways to implement.
The idea is actually quite trivial: you need to create a counter that, when it reaches a certain value, will call
proceed . Each handler at its completion will update the counter, and thus the last of the handlers will continue the execution of the original coroutine. However, there is one small difficulty: the counter must be divided between the running coroutines, and the last handler must not only call proceed, but also delete this counter from memory. All this can be implemented as follows: void goWait(std::initializer_list<Handler> handlers) { deferProceed([&handlers](Handler proceed) { std::shared_ptr<void> proceeder(nullptr, [proceed](void*) { proceed(); }); for (const auto& handler: handlers) { go([proceeder, &handler] { handler(); }); } }); } At the very beginning, we run the good old
deferProceed , but inside it is hidden a little magic. Few people know that when constructing shared_ptr you can pass not only a pointer to the data, but also a deleter , which will delete the object, calling not the delete ptr , but the handler. Actually, there we also will thrust a call proceed, in the end to continue the initial coroutine. And there is no need to delete the object itself, since we put “nothing” there - nullptr . Then everything is simple: in the loop we go through all the handlers and run them in the generated coroutines. Here, too, there is one nuance: we capture our proceeder by value, which will lead to its copying, which means an increase in our atomic reference counter inside shared_ptr . After the handler is finished, our lambda with captured proceeder will be deleted, which will decrease the counter. The one who last will reduce the counter to zero and delete the proceeder object will call deleter for the shared shared_ptr , that is, it will eventually coro.proceed() .
For greater clarity, the following is a sequence of operations on the example of running two handlers in different threads:
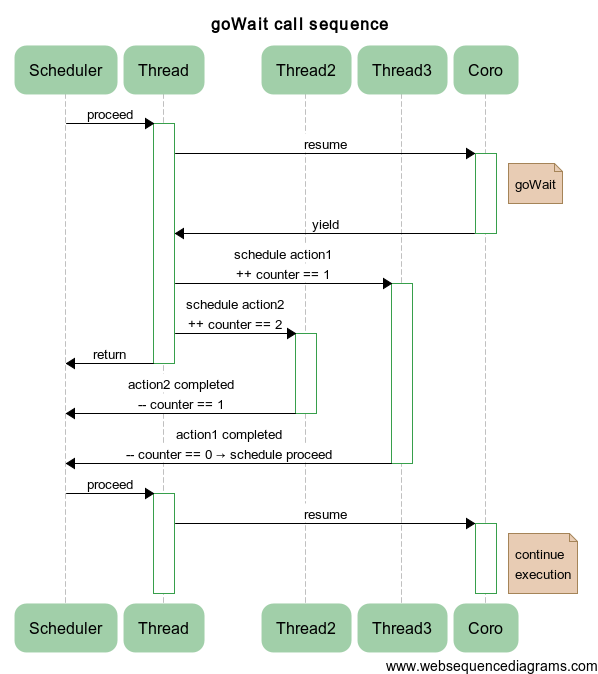
Example: Recursively Parallel Fibonacci Numbers
To illustrate use, consider the following example. Suppose we found a whim and we wanted to calculate the Fibonacci series recursively and in parallel. No problems:
int fibo (int v) { if (v < 2) return v; int v1, v2; goWait({ [v, &v1] { v1 = fibo(v-1); }, [v, &v2] { v2 = fibo(v-2); } }); return v1 + v2; } I note that there will never be a stack overflow: every call to the
fibo function occurs in its own coroutine.Waiter: start of several asynchronous operations and waiting for their completion
Often we need not just to wait for a fixed set of handlers, but in the meantime to do something useful and only then to wait. Sometimes we don’t know how many handlers may be needed, that is, we create them as we perform our operations. In fact, we need to operate with a group of handlers as a whole. To do this, you can use the
Waiter primitive with the following interface: struct Waiter { Waiter& go(Handler); void wait(); }; There are only two methods:
- go: run another handler;
- wait: wait for all running handlers.
You can run the above methods several times over the entire lifetime of the
Waiter object.The idea of implementation is exactly the same: it is necessary to have a
proceeder that continues the work of our coroutine. However, a small subtlety is added: now proceeder is divided between the running coroutines and the Waiter object. Accordingly, at the time the wait method is called, we need to get rid of the copy in the Waiter itself. Here's how to do it: void Waiter::wait() { if (proceeder.unique()) { // Waiter proceeder => JLOG("everything done, nothing to do"); return; } defer([this] { // proceeder auto toDestroy = std::move(proceeder); // proceeder , // - }); // proceeder , // init0(); } And again nothing needs to be done! Thanks for this
shared_ptr . Amen!
Example: Recursively Parallel Fibonacci Numbers
To consolidate the material, we consider an alternative implementation of our whit using
Waiter : int fibo (int v) { if (v < 2) return v; int v1; Waiter w; w.go([v, &v1] { v1 = fibo(v-1); }); int v2 = fibo(v-2); w.wait(); return v1 + v2; } Another option:
int fibo (int v) { if (v < 2) return v; int v1, v2; Waiter() .go([v, &v1] { v1 = fibo (v-1); }) .go([v, &v2] { v2 = fibo (v-2); }) .wait(); return v1 + v2; } I do not want to choose.
goAnyWait: start several asynchronous operations and wait for at least one to complete
We will still run several operations at the same time. But we will wait exactly until at least one operation is completed:
size_t goAnyWait(std::initializer_list<Handler> handlers); At the entrance we have a list of handlers, the output is the number of the handler, which ended first.
To implement this primitive, we slightly modernize our approach. Now we are going to separate not
void* ptr == nullptr , but quite a specific atomic counter counter . At the very beginning, it is initialized to 0 . Each handler at the end of its work increases the counter. And if it suddenly turned out that a change in the value from 0 to 1 occurred, then he and only he calls proceed() : size_t goAnyWait(std::initializer_list<Handler> handlers) { VERIFY(handlers.size() >= 1, "Handlers amount must be positive"); size_t index = static_cast<size_t>(-1); deferProceed([&handlers, &index](Handler proceed) { std::shared_ptr<std::atomic<int>> counter = std::make_shared<std::atomic<int>>(); size_t i = 0; for (const auto& handler: handlers) { go([counter, proceed, &handler, i, &index] { handler(); if (++ *counter == 1) { // , ! index = i; proceed(); } }); ++ i; } }); VERIFY(index < handlers.size(), "Incorrect index returned"); return index; } As you might guess, this trick can also be used for cases when you need to wait for two, three or more handlers.
goAnyResult: start several asynchronous operations and wait for at least one result to be received
We now turn to the most delicious, which, in fact, necessary for our task. Namely: run a few operations and wait for the desired result. In this case, any handler may not return the result. That is, he will finish his work, but at the same time he will say: “Well, I didn’t hurt, I didn’t hush.”
With this approach, additional complexity appears. After all, all handlers can complete the work, but we will not get the result. Therefore, it will be necessary, first, to somehow check at the end of all operations whether we have obtained the desired result, and second, to return an “empty” result. To signal emptiness, we will use
boost::optional<T_result> , while goAnyResult obtained with this plain prototype: template<typename T_result> boost::optional<T_result> goAnyResult( std::initializer_list< std::function< boost::optional<T_result>() > > handlers) There is nothing terrible here: we simply pass a list of handlers that optionally return our
T_result . That is, handlers must have a signature: boost::optional<T_result> handler(); The situation in comparison with the previous primitive is only slightly modified. The counter remains the same, only now when it is destroyed, it is necessary to check the
counter , and if we get 1 when increasing it, then it is necessary to return the “empty” value, since no one has been able to distort the counter and return the required result. Thus, instead of a simple atomic value for counter we have a whole Counter object: template<typename T_result> boost::optional<T_result> goAnyResult( std::initializer_list< std::function< boost::optional<T_result>() > > handlers) { typedef boost::optional<T_result> Result; typedef std::function<void(Result&&)> ResultHandler; struct Counter { Counter(ResultHandler proceed_) : proceed(std::move(proceed_)) {} ~Counter() { tryProceed(Result()); // - } void tryProceed(Result&& result) { if (++ counter == 1) proceed(std::move(result)); } private: std::atomic<int> counter; ResultHandler proceed; }; Result result; deferProceed([&handlers, &result](Handler proceed) { std::shared_ptr<Counter> counter = std::make_shared<Counter>( [&result, proceed](Result&& res) { result = std::move(res); proceed(); } ); for (const auto& handler: handlers) { go([counter, &handler] { Result result = handler(); if (result) // counter->tryProceed(std::move(result)); }); } }); return result; } The intrigue here is that
std::move only moves the result when the condition inside tryProceed is satisfied. And all because std::move does not perform the movement as such, no matter how someone would like it. This is just a cast operation on links.With the expectations figured out, go to the schedulers and thread pools.
Scheduler, pools, sync
Scheduler Interface
After reviewing the basic basics, so to speak, we proceed to the dessert.
We introduce the scheduler interface:
struct IScheduler : IObject { virtual void schedule(Handler handler) = 0; }; Its task is to execute handlers. Note that the scheduler interface has no undo, no timeout, or pending operations. The scheduler interface should be crystal clear so that it can be easily docked with various frameworks (cf. [2] : here you will find it very convenient to cross with the actors and delays, with UI schedulers).

Thread pool
We need a thread pool to perform various actions that implements the scheduler interface:
typedef boost::asio::io_service IoService; struct IService : IObject { virtual IoService& ioService() = 0; }; struct ThreadPool : IScheduler, IService { ThreadPool(size_t threadCount); void schedule(Handler handler) { service.post(std::move(handler)); } private: IoService& ioService(); std::unique_ptr<boost::asio::io_service::work> work; boost::asio::io_service service; std::vector<std::thread> threads; }; What do we have here?
- The constructor in which we set the number of threads.
- Implementing the scheduler interface using
boost::asio::io_service::post. - A member of the
workclass that holds theio_serviceeventio_service, otherwise, if there are no events, the cycle will complete its work and the threads will close. - Array of threads.
In addition, our class implements (and privately) a certain muddy
IService interface with the ioService method, which is returned by IoService , which is boost::asio::io_service . All this looks strange, but now I will try to explain what the trick is.The fact is that to work with network sockets and timeouts we need an advanced scheduler interface. This interface is actually hidden inside
boost::asio::io_service . The remaining components, which I will use in the future, should somehow get access to the instance boost::asio::io_service . To prevent easy access to this class, I introduced the IService interface, which allows you to receive the coveted instance. However, in the implementation of the method is made private. This provides some level of protection against misuse, since in order to pull this object out, you first need to convert the ThreadPool to IService , and then call the desired method. An alternative would be to use friendly classes. But I didn’t want to spoil ThreadPool knowledge of possible uses, so I thought that the approach used was a reasonable price for encapsulation.Coroutine class
After the introduction of the thread pool and the scheduler, it was the turn to introduce a class for coroutine manipulations. It will be called, oddly enough,
Journey (why it will be clear later): struct Journey { void proceed(); Handler proceedHandler(); void defer(Handler handler); void deferProceed(ProceedHandler proceed); static void create(Handler handler, mt::IScheduler& s); private: Journey(mt::IScheduler& s); struct CoroGuard { CoroGuard(Journey& j_) : j(j_) { j.onEnter0(); } ~CoroGuard() { j.onExit0(); } coro::Coro* operator->() { return &j.coro; } private: Journey& j; }; void start0(Handler handler); void schedule0(Handler handler); CoroGuard guardedCoro0(); void proceed0(); void onEnter0(); void onExit0(); mt::IScheduler* sched; coro::Coro coro; Handler deferHandler; }; ?
- .
create. Journeysched,corodeferHandler-,defer.CoroGuard– -,onEnter0onExit0.
, , :
void Journey::schedule0(Handler handler) { VERIFY(sched != nullptr, "Scheduler must be set in journey"); sched->schedule(std::move(handler)); } void Journey::proceed0() { // guardedCoro0()->resume(); } Journey::CoroGuard Journey::guardedCoro0() { return CoroGuard(*this); } // void Journey::proceed() { schedule0([this] { proceed0(); }); } // , Handler Journey::proceedHandler() { return [this] { proceed(); }; } // // . 1 void Journey::start0(Handler handler) { schedule0([handler, this] { // guardedCoro0()->start([handler] { JLOG("started"); // try { handler(); } catch (std::exception& e) { (void) e; JLOG("exception in coro: " << e.what()); } JLOG("ended"); }); }); } defer:
void Journey::defer(Handler handler) { // deferHandler = handler; // coro::yield(); } // deferProceed, void Journey::deferProceed(ProceedHandler proceed) { defer([this, proceed] { proceed(proceedHandler()); }); } It's simple! ,
deferHandler . TLS Journey* t_journey = nullptr; void Journey::onEnter0() { t_journey = this; } // . 2 void Journey::onExit0() { if (deferHandler == nullptr) { // => , delete this; } else { // deferHandler(); deferHandler = nullptr; } // , t_journey = nullptr; } create : void Journey::create(Handler handler, mt::IScheduler& s) { (new Journey(s))->start0(std::move(handler)); } ,
Journey , , . , …! … , . , . !
:
void Journey::teleport(mt::IScheduler& s) { if (&s == sched) { JLOG("the same destination, skipping teleport <-> " << s.name()); return; } JLOG("teleport " << sched->name() << " -> " << s.name()); sched = &s; defer(proceedHandler()); } :
- , , . , , .
- , :
defer, . , .

Scheduler / Thread Scheduler2 / Thread2 :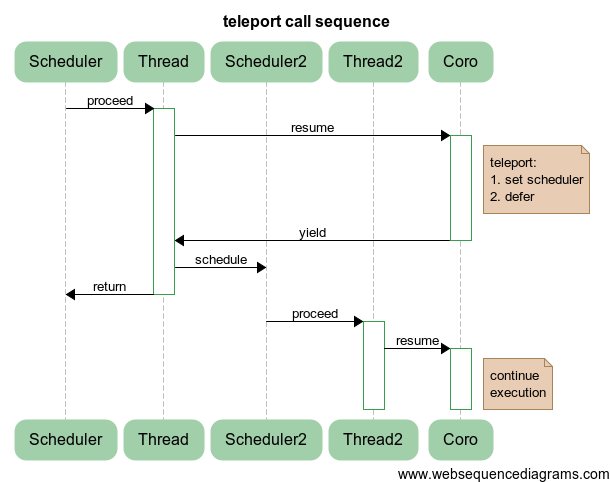
? , , , . , UI- , UI, , :
auto result = someCalculations(); teleport(uiScheduler); showResult(result); teleport(calcScheduler); auto newResult = continueSmartCalculations(result); teleport(uiScheduler); updateResult(newResult); //… , UI, , UI-. , , , – , , .

. , . , UI- UI-, . , , , .
struct Portal { Portal(mt::IScheduler& destination) : source(journey().scheduler()) { JLOG("creating portal " << source.name() << " <=> " << destination.name()); teleport(destination); } ~Portal() { teleport(source); } private: mt::IScheduler& source; }; ( ), . .
RAII- , , (, UI- ), .
:
ThreadPool tp1(1, "tp1"); ThreadPool tp2(1, "tp2"); go([&tp2] { Portal p(tp2); JLOG("throwing exception"); throw std::runtime_error("exception occur"); }, tp1); tp1, tp2. , , tp1 , . !

(, , ), :
struct Scheduler { Scheduler(); void attach(mt::IScheduler& s) { scheduler = &s; } void detach() { scheduler = nullptr; } operator mt::IScheduler&() const { VERIFY(scheduler != nullptr, "Scheduler is not attached"); return *scheduler; } private: mt::IScheduler* scheduler; }; struct DefaultTag; template<typename T_tag> Scheduler& scheduler() { return single<Scheduler, T_tag>(); } template<typename T> struct WithPortal : Scheduler { struct Access : Portal { Access(Scheduler& s) : Portal(s) {} T* operator->() { return &single<T>(); } }; Access operator->() { return *this; } }; template<typename T> WithPortal<T>& portal() { return single<WithPortal<T>>(); } , :
ThreadPool tp1(1, "tp1"); ThreadPool tp2(1, "tp2"); struct X { void op() {} }; portal<X>().attach(tp2); go([] { portal<X>()->op(); }, tp1); X tp2. , X ( return &single<T>() ) . Journey -, !
, . . . , .
. : .
, - ? , . .
? , , . « », – .
. , . :
struct Alone : mt::IScheduler { Alone(mt::IService& service); void schedule(Handler handler) { strand.post(std::move(handler)); } private: boost::asio::io_service::strand strand; }; Alone IService , io_service::strand boost.asio . boost.asio , , . , (mutual exclusion).Alone , , .:
struct MemCache { boost::optional<std::string> get(const std::string& key); void set(const std::string& key, const std::string& val); }; // ThreadPool common_pool(3); // Alone mem_alone(common_pool); // portal<MemCache>().Attach(mem_alone); // // auto value = portal<MemCache>()->get(key); // portal<MemCache>()->set(anotherKey, anotherValue); , . , !

, . , . , , .

? , , , (. «»). .
: – . , , , , . ! , , , ?
. , , , - , - , , . .
:
enum EventStatus { ES_NORMAL, ES_CANCELLED, ES_TIMEDOUT, }; struct EventException : std::runtime_error { EventException(EventStatus s); EventStatus status(); private: EventStatus st; }; (. ) , :
struct Goer { Goer(); EventStatus reset(); bool cancel(); bool timedout(); private: struct State { State() : status(ES_NORMAL) {} EventStatus status; }; bool setStatus0(EventStatus s); State& state0(); std::shared_ptr<State> state; }; : , .
-
Journey : void Journey::handleEvents() { // if (!eventsAllowed || std::uncaught_exception()) return; auto s = gr.reset(); if (s == ES_NORMAL) return; // throw EventException(s); } void Journey::disableEvents() { handleEvents(); eventsAllowed = false; } void Journey::enableEvents() { eventsAllowed = true; handleEvents(); } , . - , . :
struct EventsGuard { EventsGuard(); // disableEvents() ~EventsGuard(); // enableEvents() }; ,
handleEvents ? : void Journey::defer(Handler handler) { // handleEvents(); deferHandler = handler; coro::yield(); // handleEvents(); } , . - ,
handleEvents . .:
Goer go(Handler handler, mt::IScheduler& scheduler) { return Journey::create(std::move(handler), scheduler); } Journey::create Goer : struct Journey { // … Goer goer() const { return gr; } // … private: // … Goer gr; }; Goer Journey::create(Handler handler, mt::IScheduler& s) { return (new Journey(s))->start0(std::move(handler)); } // . 1 Goer Journey::start0(Handler handler) { // … return goer(); } : Goer op = go(myMegaHandler); // … If (weDontNeedMegaHandlerAnymore) op.cancel(); op.cancel() , handleEvents() .
, , ,
Journey , -, , go . , , . : go , defer , deferProceed . ., Journey , TLS.:
struct Timeout { Timeout(int ms); ~Timeout(); private: boost::asio::deadline_timer timer; }; boost::asio::deadline_timer : Timeout::Timeout(int ms) : timer(service<TimeoutTag>(), boost::posix_time::milliseconds(ms)) { // Goer goer = journey().goer(); // timer.async_wait([goer](const Error& error) mutable { // mutable, goer if (!error) // , goer.timedout(); }); } Timeout::~Timeout() { // timer.cancel_one(); // , handleEvents(); } RAII-, , .
:
// Timeout t(100); // 100 for (auto element: container) { performOperation(element); handleEvents(); } 100 – !

:
// 200 Timeout outer(200); portal<MyObject>()->performOp(); { // 100 // Timeout inner(100); portal<MyAnotherObject>()->performAnotherOp(); // EventsGuard guard; performGuardedAction(); } . , – «» . .
? :
- , .
- . , .
- – . , .
1
, 1.
:
Goer Journey::start0(Handler handler) { schedule0([handler, this] { guardedCoro0()->start([handler] { JLOG("started"); try { handler(); } catch (std::exception& e) { (void) e; JLOG("exception in coro: " << e.what()); } JLOG("ended"); }); }); return goer(); } . Where? , ?
Answer

Goer Journey::start0(Handler handler) { + Goer gr = goer(); schedule0([handler, this] { guardedCoro0()->start([handler] { JLOG("started"); @@ -121,7 +122,7 @@ JLOG("ended"); }); }); - return goer(); + return gr; } 2
. :
void Journey::onExit0() { if (deferHandler == nullptr) { delete this; } else { deferHandler(); deferHandler = nullptr; } t_journey = nullptr; } ?
Answer

defer handler, .
{ @@ -153,8 +154,8 @@ - deferHandler(); - deferHandler = nullptr; + Handler handler = std::move(deferHandler); + handler(); } defer handler, .
: (GC)

, , GC . :
struct A { ~A() { TLOG("~A"); } }; struct B:A { ~B() { TLOG("~B"); } }; struct C { ~C() { TLOG("~C"); } }; ThreadPool tp(1, "tp"); go([] { A* a = gcnew<B>(); C* c = gcnew<C>(); }, tp); :
tp#1: ~C tp#1: ~B tp#1: ~A ! - , .
, , :
template<typename T, typename... V> T* gcnew(V&&... v) { return gc().add(new T(std::forward(v)...)); } GC& gc() { return journey().gc; } struct GC { ~GC() { // for (auto& deleter: boost::adaptors::reverse(deleters)) deleter(); } template<typename T> T* add(T* t) { // T deleters.emplace_back([t] { delete t; }); return t; } private: std::vector<Handler> deleters; }; GC Journey , . : , .findings
, :
- /.
- .
- .
- , .
- – : , , . .
, . , . , .
, . : , , , UI, , . , .
. ! , .

Code
github.com/gridem/Synca
bitbucket.org/gridem/synca
C++ Party, Yandex
tech.yandex.ru/events/cpp-party/march-msk/talks/1761
C++ User Group
youtu.be/uUQX5QS1CCg
habrahabr.ru/post/212793
Literature
[1] : habrahabr.ru/post/201826
[2] Akka- doc.akka.io/docs/akka/2.1.4/scala/scheduler.html
Source: https://habr.com/ru/post/240525/
All Articles