Taming of the Shrew (in fact, no) FineReader
After a short story about how ABBYY FineReader works (aka the “theoretical part”), it's time to move on to applying the knowledge gained. And yes, there are no cats under the cut: everything is very serious.
How to the user to participate in the processing of the document
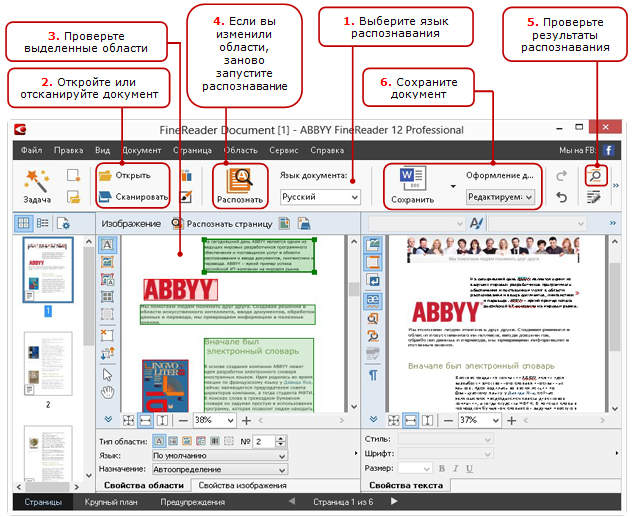
In order not to reinvent the wheel, I'll start with a simple and clear scheme from Help (see the figure on the right).
Now, knowing the list of all operations, we will look at examples - what can not go according to plan and how to deal with it.
Well recognized only good images.
What to do when there are images, but not very good ones? Improve right in FineReader all you can, and if you can not improve - try to get the image again, eliminating the problem. Since the topic is very extensive, with proper interest there will be a separate post about how to make friends with automatic and manual image processing tools right in FineReader. In the meantime, I limit myself to noticing that the image will be processed better if it:
')
- (after scanning) has no pronounced geometric distortions - skew or noticeable bending of the pages of a thick book at the spine of a double-page spread,
- (after photographing, in addition to the previous one) does not have nonlinear geometric distortions (“pillow”, “trapezium”), has uniform focusing (and preferably brightness) over the entire area, has no noise from insufficient illumination, does not have pronounced illumination from flash (especially on glossy paper).
Document / Project Setup Phase
It is possible and necessary to immediately indicate the language of the text, the parameters of image preprocessing, some parameters of analysis and recognition. Here is a screenshot of one of the tabs in the settings dialog.
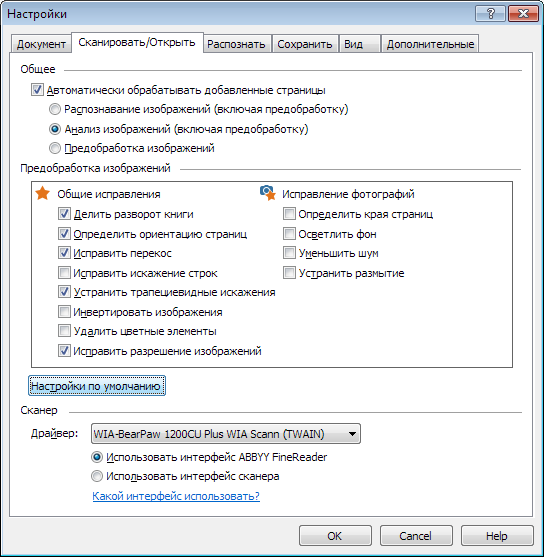
These and other settings are described in detail in the Help.
Stage of analysis
The program automatically selects areas of different types in terms of recognition. At this stage, we can both independently mark out the areas, and correct (if necessary) those that have found the Analysis module.
In order not to write a lot of superfluous about the tools for working with areas, I refer to the Help section , but here I will explain what for what, “what is good, what is bad” (applied to areas) and how to fix a bad result.
Assigning areas of different types
In the FineReader user interface, several types of areas are available, for them there are various options for the hidden property panel (at the bottom of the Image window) and the context menu (by right-clicking):
- “Recognition Zone” (gray frame by default) - this name is used in the user interface, in my opinion it would be more correct to call the “area for automatic analysis”. The purpose of such an area is to indicate where on the page in general you need to look for something useful. Therefore, as a result of subsequent analysis or analysis + recognition, within each “recognition zone” there can be zero and more areas of other types. Recognition zones are especially useful in block patterns (for more details, see Help).Examples of correctly drawn recognition zones.A real example from Tolstoy's digitization project - part of the pages is numbered lines (lines numbered with multiples of 10 are numbered), which is not necessary as a result and makes it difficult to read / edit text if automatic analysis included these numbers in the text area of the column. If the pages were almost equally aligned on the scanner or qualitatively cropped after scanning, before analyzing, you can apply a block template to the desired group of pages, where the recognition area (or areas) simply does not contain parts of the page that we don’t need:
Remember that, in contrast to the text area, the recognition area can turn into areas of different types, as was necessary in this project. - Text area - contains the text of one or more lines, each of which contains logically connected text, therefore, to select two columns in one block is a very bad idea. May have non-rectangular shape. Sometimes you need to set or correct after incorrect definition of autoanalysis the direction of the text, “inverse” (simplified: dark text on a light background - “plain text”, and light text on a dark background - “inverse” text, the default is set to “Auto” and almost never requires correction).
These parameters are set on the block, so selecting the text of a different direction or different inverse in one block is another bad idea.About the directions of the main text of the pageIn European languages, in normal text orientation, lines are read from top to bottom (in a block with rotated text - from logical top to logical bottom), but in the case of hieroglyphic languages, everything is much more fun - even on one page, some areas may contain text in horizontal orientation, and others are columnar, and the hieroglyphs have the same orientation in all these areas (if the topic of the Far Eastern and Middle Eastern languages is interesting - ask for a separate post about the local bells and whistles). 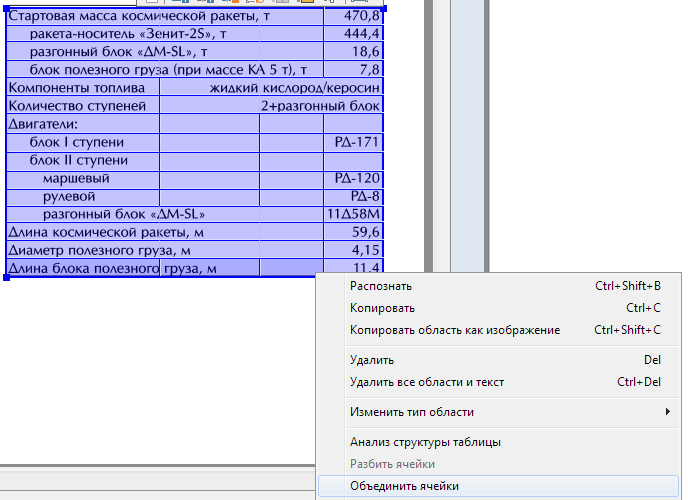 Table area - contains a table, both with visible row and column separators, and invisible (partially or everywhere). A table can only have a rectangular shape, each of the cells is also a rectangle, but using the union of groups of cells or groups of rows, you can transfer very complex text configurations.
Table area - contains a table, both with visible row and column separators, and invisible (partially or everywhere). A table can only have a rectangular shape, each of the cells is also a rectangle, but using the union of groups of cells or groups of rows, you can transfer very complex text configurations.
Each cell can contain recognizable text (possibly empty) or a picture. If you want to recognize the text in the cell, then you can set special recognition parameters for it, and if not, then you should specify the "picture in the whole cell". By the way, you can immediately select a rectangular group of table cells and change the desired property for all at once.
Tables are a complex object for automatic analysis, especially with partially or everywhere invisible separators. It is extremely important that manually correcting the location and layout of the table before the first or repeated recognition is always easier than correcting the wrong structure of the text after recognition - in FineReader or even after saving, in the target application. So in the section "Practicum" I will give a lot of examples from real life error correction automatic marking of tables.- Picture area - may have a non-rectangular shape. It has two types - plain (displaces column text) and background (does not supplant column text), they have slight differences when drawing (for example, when stretching a background picture, the text areas covered with it are not removed).
- Barcode area - contains the barcode of the autodetectable or explicitly specified type. Like a picture, it may have a non-rectangular shape, although this is rarely necessary.
Important Considerations
- Recognition and synthesis see only those fragments of text that were found in the text areas or text cells of the tables. If a piece of text is not selected in blocks, it will not be recognized.
- Similarly, with pictures - if a part of the picture was out of the area or one holistic picture was divided into several areas - most likely, there will be problems as a result of processing.
- Recognition languages in FineReader are not set for a tick - they affect very many mechanisms, starting with analysis: for example, hieroglyphic (Chinese, Japanese, Korean) or Arabic text have many features that are not always taken into account, but only when choosing the appropriate languages recognition.
Features of the interaction of closely spaced or intersecting areas
The following rules are important both for the proper handling of areas in the program shell, and for understanding what will happen to them in the recognition and preservation results.
- The intersection of text and tabular blocks with each other , if there are characters or parts of them that turned out to be in more than one block, is almost always a mistake , such analysis results should be corrected, especially since this is usually done in several mouse movements.
The intersection of picture areas with each other is almost always a mistake, although less critical for processing text. Such cases are also desirable to correct. - The picture area against the background of a larger text area is a legitimate and often sought-after combination. The main application is the processing of so-called inline-pictures, when inside a line (or between lines) there is a fragment (pictogram, formula or its part, etc.) that is poorly recognized or not recognized at all in the text model used in FineReader.

 Examples of proper use of pictures in the tableNote that using the checkbox in the properties panel of the area (below), the cells from the left column of the table are made with pictures.
Examples of proper use of pictures in the tableNote that using the checkbox in the properties panel of the area (below), the cells from the left column of the table are made with pictures.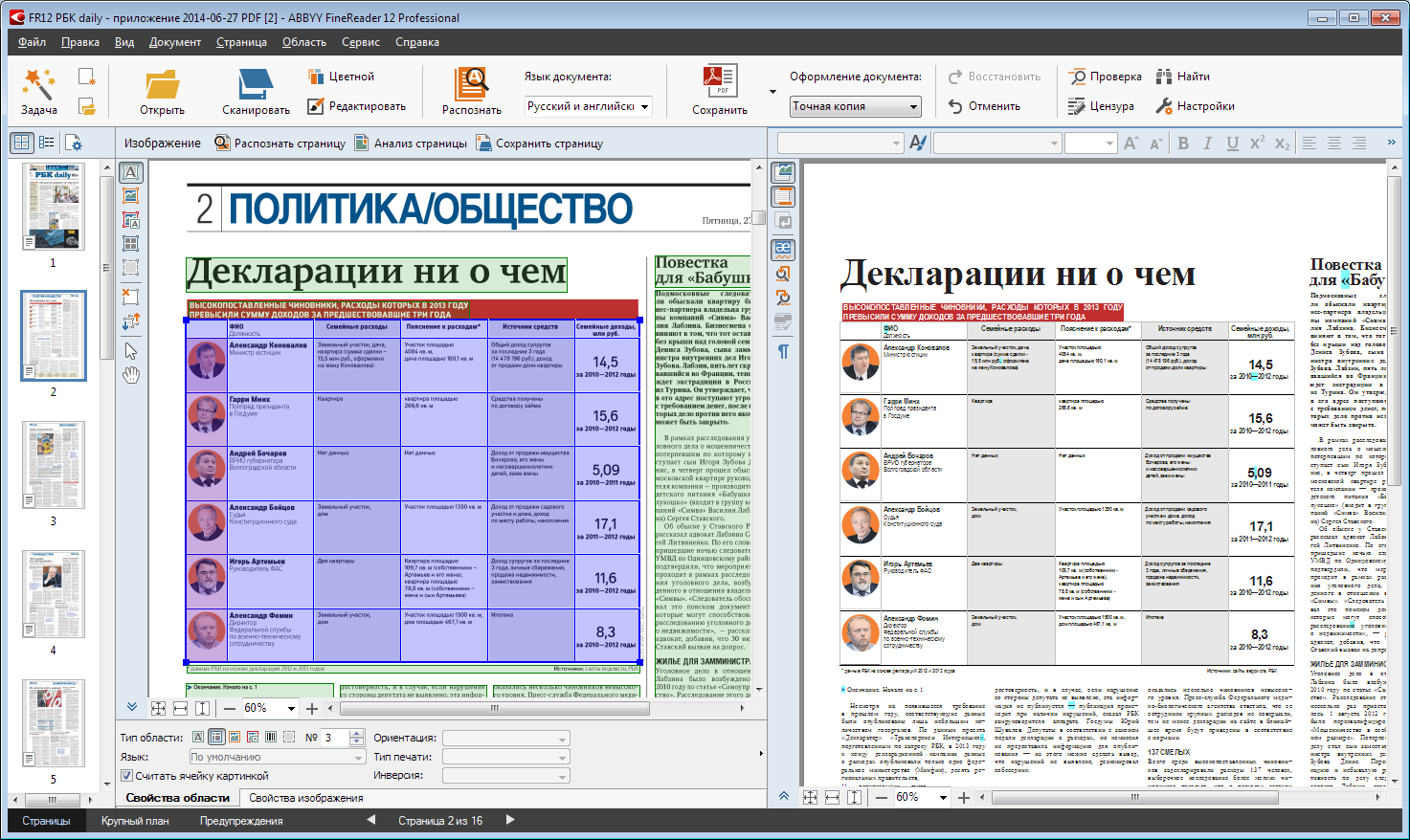
The text area on the background of the “picture” area is also an important tool: there can be captions to them against the background of ordinary picture areas, and the main (“columnar”) text of the document, as well as the table, can be located on the “background” picture areas.Examples of proper use of text areas on the background of images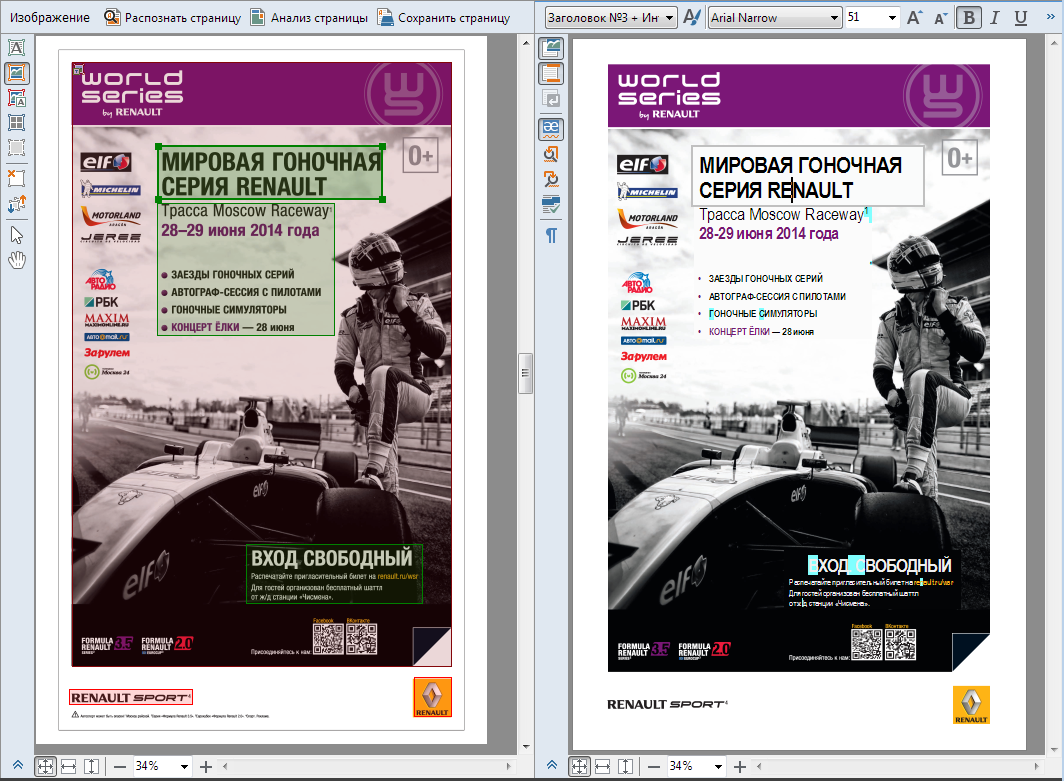
Tricks to make it easier to work with blocks
The described agreements are reflected in the behavior of the block editor. For example, if you draw a new one or stretch an existing block so that it completely or almost completely overlaps the other blocks - these other blocks are automatically deleted.Logical / illogical selection of areas
Now is the time to think - for what purposes and what format the document I would like to receive as a result of processing. Here are some considerations that affect the number and nature of block markup fixes in difficult cases:Option 1: we need only text (perhaps we don’t understand it, but this is the case)
If you need to save a document to PDF with images of the pages of the original document and added “invisible” recognized text (to search and copy it), the main thing is to ensure a reasonable selection of text in text and table blocks. By "rationality" here means the following:- There are no “garbage” areas where elements of pictures or page design elements are recognized (by garbage) as text or tables.
- areas logically distinguish lines, preventing characters from falling into more than one area and unnecessarily crushing lines into more than one area.
- that, from the point of view of a person, is the tables in the original, should be highlighted in tabular areas. This affects both the quality of recognition (for example, the base lines of lines in different cells may not be aligned vertically), and the convenience of searching and copying text fragments in the output document.
If individual images should not be copied from the output PDF document, then such areas can be excluded from the document at all (not to create new ones and not to leave the ones found by automatics, at least to delete the illogically found pictures, and if not laziness, that's all).
I hope to broader and deeper reveal the theme of "rationality" of pictures in the article on the preservation of documents - if this is interesting to the readers of this material.Option 2: you need everything at once
If a document that includes not only text content (in one or two columns), it is supposed to be saved immediately as an e-book in FB2 / e-pub formats or in any intermediate editable format (Word or HTML) for further editing and production of an e-book, then meaningful selection of tables and pictures becomes especially important.
Among other things, you need to decide what to do with the groups of adjacent pictures, and what to do with the captions for the pictures, both next to each other and overlapping the pictures. We will analyze this topic in more detail in the Practicum, using real examples.Something like the conclusion of this part
So, we now imagine how to deal with incorrectly allocated blocks, which in difficult cases from the point of view of our technology really complicate life.
Of course, FineReader is great, so the user does not know anything about it. Therefore, we will return to this topic in a separate “Practicum”. If readers show interest, of course :)
Source: https://habr.com/ru/post/240361/
All Articles