Substitution Benefit Criterion and Dynamic Profiling
I continue the topic of interprocedural optimizations, the introduction to which can be found in the previous post . Today, I want to speculate a bit about function substitution (inlining) and how substitution affects application performance.
Periodically it is necessary to analyze cases when the same application compiled by different compilers shows different performance. Often the reason is the difference in substitution, which is performed automatically. Suddenly it turns out that in one case one set of calls is substituted, and in the other one it is somewhat different. As a result, the analysis of competing compilers is greatly complicated, since it becomes impossible to directly compare any hot functions. The time of their execution depends heavily on what calls have been placed.
The substitution is the most popular interprocedural optimization, which instead of calling a function inserts its body into the body of the calling function. What tasks does the compiler have to solve when deciding on substitution and how can a programmer improve application performance with this optimization? As the inlining decision is made by the Intel compiler, I approximately know, but it is interesting to check the proposed methods on the gcc compiler.
Why do substitutions improve performance?
- The overhead of calling a function disappears, i.e. there is no need to allocate space on the stack to store the call arguments or write arguments to registers.
- Improved code locality. Instead of switching to the instructions of the called procedure, which may not be in the cache, the control “smoothly flows” to the lines of code inserted as a result of the substitution.
- Most compiler optimizations are related to control flow graph (CFG) processing. Therefore, such optimizations work at the procedure level. The substitution allows you to use the entire context of the calling procedure to optimize the body of the substituted procedure. Due to this, after substitution, a gain can be obtained, for example, from constant pulling, from cycle optimization, etc.
Can the substitution have a negative impact on performance? Easy. Due to the substitution, the size of the procedure code, the number of local variables placed on the stack can increase. Both of these factors may affect the principle of code localization. Those. Because of the increase in the amount of executable code, the necessary instructions and data are less often cached and execution slows down. In addition, the sprawl of code negatively affects the compilation time and the size of the executable files (which can be especially critical for mobile architectures). The “small” functions are a good exception for substitution, i.e. those whose body contains fewer instructions than the cost of calling such functions. Thus, like most optimizations, substitution is a double-edged sword. Both the compiler and the programmer need criteria that determine which functions should be aimed at substituting in the first place, which in the second, and which should not be substituted at all.
')
Auto Subassembly
So, you can improve performance through substitution. Naturally, such a fertile area for improving application performance can not be under the scrutiny of optimizing compilers. Compilers can make substitutions automatically. The user adds one option, and the optimizing compiler chooses which calls to leave intact and which ones to substitute.
If you look at the Intel compiler options (icc –help), then it is easy to find the enable button for this mechanism.
-inline-level=<n> control inline expansion: n=0 disable inlining n=1 inline functions declared with __inline, and perform C++ inlining n=2 inline any function, at the compiler's discretion From this description of the options it is clear that there are several modes of operation. In general, prohibit substitution, use directives for the compiler set by the programmer, allow the compiler to choose the objects for optimization. Those. The option –inline-level = 2 is what we need, and it is this option that is used by default. Also in this list is a huge number of options of the form:
inline-max-total-size=<n> maximum increase in size for inline function expansion -no-inline-max-total-size no size limit for inline function expansion -inline-max-per-routine=<n> maximum number of inline instances in any function -no-inline-max-per-routine no maximum number of inline instances in any function -inline-max-per-compile=<n> maximum number of inline instances in the current compilation -no-inline-max-per-compile no maximum number of inline instances in the current compilation -inline-factor=<n> set inlining upper limits by n percentage From this it is clear that the statement of the problem for an automatic substitute is to implement substitution of functions in such a way as to achieve the best performance and fit within a certain framework of increasing the program code. It can be seen that there are options in the list that control the sprawl of the program code as a whole, and the sprawl of each procedure.
Substitution Utility Criteria
Let's try to evaluate the quality of the compiler's performance when performing automatic substitution. To do this, it is necessary to develop some obvious criterion for the usefulness of the substitution and understand whether it can be used.
In my opinion, we can formulate the following approximate criterion for the advantage of substitution. Each substitution carries some costs that degrade the quality of the entire program as a whole, but it also improves the quality of the particular code fragment where the substitution is made.
The simplest case, when the substitution is unprofitable, in my opinion, looks like this:
If (almost_always_false) { Foo(); } In this case, we received all the negative consequences of the substitution of the function Foo, “localized” on the stack of the calling function its local variables, increased the size of the code of the calling function. But the function is almost never called and our locally enhanced code snippet is not used, that is, the costs do not pay off. Thus, when making a substitution decision, it would be good to know how hot a particular challenge is. The proposed criterion is the following: the more often a function is called when it is executed, the more profitable it is to inline it. The second obvious factor is the size of the function. The smaller the size of the function, the more profitable it is to substitute, since in this case we will be able to accommodate more substitutions in the boundaries determined by the expansion threshold of the program.
It is obvious that you can come up with many more different criteria for the substitution utility, for example, to consider that it is more profitable to inline calls within cycles, if inlineing helps vectorization or it is more profitable to inline a call with constant arguments, etc. It is not entirely clear how the compiler can obtain this knowledge before making the decision on inlining without complicating the analysis and increasing the compilation time. Some cases where substitution is beneficial are not obvious until this benefit is obtained. For example, in the interprocedural analysis, we are unlikely to understand that thanks to the substitution, we are guaranteed to benefit from vectorization. Because for this you need to do almost all the work that is done during the optimization of the procedure, before making a decision about inlining.
If there are restrictions on the growth of the code, the order in which the decision about inlining is made becomes very important. The compiler bypasses all calls in a certain order and makes a decision about the substitution. At the same time, it changes the size of the calling function and checks whether the code sprawl limit has been exceeded. If at first some substitutions were made inside the called function, then the size of its code is no longer equal to the original at the moment of the decision to make the substitution. It is possible to manipulate heuristics that make decisions about profitability, but if at the moment of making a decision the limits of code expansion are already exceeded, then the compiler will not inline such a function. For quite large projects, the situation of reaching the limits of code sprawl is very ordinary.

It is easy to calculate the size of the code of the function being injected, although it can change a lot after substitution or some optimizations, but the compiler does not have knowledge of which parts of the code of the calling function are “hot” and which are not at compile time. The compiler has a profiler who “thoughtfully looking at” the procedure code tries to estimate the probability of a particular transition, and, thanks to his work, a certain weight is assigned to each continuous fragment of the procedure being processed. Unfortunately, the profiler estimates are very approximate and cause an analogy with a well-known anecdote about a blonde who was asked about the likelihood of meeting a dinosaur. "50 to 50, or an appointment or not," replied the blonde. And it was absolutely right in terms of logic and optimizing compiler! The authors of the anecdote suggest that the blonde should know something about dinosaurs. But if there is no knowledge, then the answer is quite logical. Almost all if transitions get a 50% chance. Well, you can still tell fortunes on the coffee grounds on how many iterations the average statistical cycle has for non-constant lower and upper bounds.
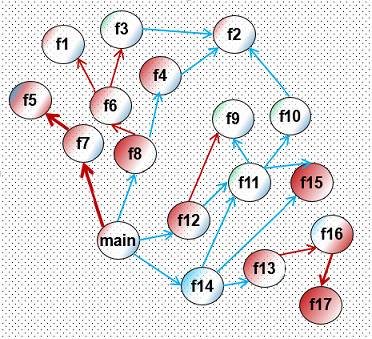
In general, the task of determining the weight of a code is already complex at the level of a single function. And what can be said about the weight of a particular call within the framework of the entire program? It may be that the function has a very “hot” challenge inside. Yes, it can only happen that the function itself is terribly “cold” and almost never gets control. It turns out that, in a good way, you need to have a method for estimating the importance of each call within the program, which would analyze both the call graph and the control flow graph for each function, and put the weight for each arc in the call graph on the basis of such an analysis. But such estimates may be completely inaccurate. The real weight of each call is very much dependent, for example, on the set of input data.
Actually, this idea is illustrated by drawing to my post. Here, based on the CFG analysis, I tried to highlight the cold and hot calls (the faces of the call graph). Red color means “hot” areas within the procedure, and red arrows are hot calls. Unfortunately, as already emphasized, all of this coloring can be different for different input data sets. Placing a believable weight when compiling is very difficult.
Criterion Testing
Nevertheless, the proposed criterion is quite simple and in accordance with it it can be said that, other things being equal, it is more advantageous to substitute the calls occurring in cycles. It is less profitable to substitute the challenges encountered after checking various conditions. It seems that this is obvious? Let's check if compilers use this consideration? Let's write something extremely obvious. In this example, the same function is substituted, so from the point of view of the size of the called function, all calls are the same. The frequency with which calls are used depends on which constants the user enters.
Cat main.c #include <stdio.h> static void inline foo(int i) { printf("foo %d\n",i); } int main() { int n,k,m; printf("Enter 3 integer numbers\n"); scanf("%d",&n); scanf("%d",&k); scanf("%d",&m); foo(1); for(int i=0; i<n; i++) { foo(2); } for(int i=0; i<n; i++) { for(int j=0; j<m; j++) { foo(3); } } foo(4); foo(5); if(n<k) foo(6); if(n<m) if(k<m) foo(7); foo(8); foo(9); } It is interesting to see in what order the Intel compiler will inline these calls. It is easy to investigate by adding the –inline-max-total-size = XX option to the compilation line and gradually changing the value of this variable from 0 upwards.
icc -std=c99 -inline-max-total-size=XX -ip main.c init.c It turns out that the order of substitutions in main will be the following: foo (7), foo (9), foo (8), foo (6), foo (3), foo (5), foo (2), foo (4), foo (1).
It is seen that in this case, the considerations on the "weight" of each call are not used. The compiler does not try to guess which calls occur more often.
I have done a similar procedure with gcc.
The compilation line was as follows:
gcc –O2 --param large-function-insns=40 --param large-function-growth=XX -std=c99 main.c init.c -o aout_gcc The –O2 option includes -finline-small-functions , and in this case gcc substitutes “small” functions, the substitution of which, in theory, does not greatly affect the size of the calling function.
The –O3 option includes -finline-functions when all functions are considered candidates for substitution.
I set the large-function-insns parameter so that my main function becomes “big” and its expansion is controlled by the large-function-growth parameter. Increasing the numerical value starting from zero, we get the order in which the gcc substitutions for _O2 do: foo (9), foo (8), foo (7), foo (6), foo (5), foo (4), foo (3), foo (2), foo (1). Those. gcc makes substitutions strictly in order. With –O3, the order is: foo (3), foo (9), foo (2), foo (8), foo (7), foo (6), foo (5), foo (4), foo (1) . I like this order more. At the very least, gcc has shown respect for the calls within the cycles.
Test results. Can you help the compiler?
This experiment showed that the order in which compilers perform substitution may not be optimal. The compiler can substitute "unfavorable" calls, then reach the threshold for expanding the function being processed and stop its work with it. As a result, performance will suffer. If, when analyzing your application, you see some small non-inline functions in a hot spot, then there are two reasons for this situation: the compiler did not find a specific call to be beneficial for the substitution or the substitution decision was not made due to exceeding the code extension threshold. This can be affected by changing the threshold values or by placing attributes of the inline type on the function. Since changes in threshold values cannot be made for a specific function, such a change will increase the size of the entire application. The same can be said about the inline attribute. The attribute will affect both “hot” and “cold” calls. In this case, inline does not guarantee substitution if the code expansion thresholds are already exceeded. A more powerful attribute is always_inline. In this case, the function will always be inline.
More targeted substitution can be influenced by pragmas. Pragmas affect a specific call, and they can be used to achieve more accurate targeting of what exactly is inline. There are #pragma inline, #pragma noinline, #pragma forceinline . #pragma inline affects the compiler solution and helps, if the code sprawl threshold is not yet exceeded, but the compiler does not consider substitution beneficial. #pragma forceinline - obliges the compiler to make a substitution.
Returning to our example. Substitution of the inline attribute does not help in this example. You can ask the compiler to make the substitution more aggressively and substitute the definition of the function foo with the attribute always_inline :
static void inline foo (int) __attribute __ ((always_inline));
This will lead to the fact that all calls will be substituted (despite the violation of expansion thresholds). This method has an obvious disadvantage - both cold and hot calls will be substituted. More optimal is the use of pragmas. I rewrite the code of the main function in this form:
int main() { int n,k,m; printf("Enter 3 integer numbers\n"); scanf("%d",&n); scanf("%d",&k); scanf("%d",&m); foo(1); for(int i=0; i<n; i++) { #pragma forceinline foo(2); } for(int i=0; i<n; i++) { for(int j=0; j<m; j++) { #pragma forceinline foo(3); } } foo(4); foo(5); if(n<k) #pragma noinline foo(6); if(n<m) if(k<m) #pragma noinline foo(7); foo(8); foo(9); } Those. It turned out a working algorithm to improve application performance:
- Build the app.
- Gather information about hot parts of the application using, for example, Vtune Amplifier.
- Check whether there are non-submitted calls on these sites and zainlaynit them using pragmas.
- Check how it affected the performance of the application.
Substitution profitability criterion and dynamic profiler
It is clear that this method is resource-intensive, especially because of the use of the Amplifier and the need to examine something with my eyes. Fortunately, there is a fairly reliable means of optimizing substitutions - a dynamic profiler. The dynamic profiler is used to get an idea of the hot parts of the program and to estimate the frequency of calls to certain functions.
I am conducting the following experiment with the original text of my mini-program:
icc -std=c99 init.c main.c -prof_gen -o prof_a ./prof_a < 345.txt >& prof_out Here, an instrumented application was created using the –prof_gen option. Then this application was launched, as a result of its work, a file with the dyn extension appeared, containing collected statistics on the application operation. Running the compiler with the –prof_use option allows you to use these statistics to optimize the application. File 345.txt contains input constants 3,4,5. By manipulating the –inline-max-total-size option, I get the order in which the compiler substitutes functions.
icc -std=c99 -prof-use -inline-max-total-size=XX -ip main.c init.c The order is: foo (3), foo (2), foo (7), foo (9), foo (8), foo (7), foo (6), foo (5), foo (4), foo (one). If you look at the output of the application, it is clear that most of the calls were made 1 time and only foo (3) and foo (2) were called more often. Thanks to the dynamic profiler, the compiler was able to better determine the order of functions for the substitution.
Now we change the input data for the constants (n = 5, k = 4, m = 3). In this case, foo (6) and foo (7) are not called. Delete (!) The previous file with statistics and, repeating the experiment, we get a new order: foo (3), foo (2), foo (9), foo (8), foo (5), foo (4), foo (1 ). Calls foo (6) and foo (7) were not substituted even with a large code expansion threshold. (Which certainly pleases).
If you do not delete the file with statistics, then we get a file that reflects the statistics of the two launches.
Well, we will do the same for gcc 4.9 in the same way.
gcc -O2 -fprofile-generate -std=c99 main.c -o aout_gcc_prof ./aout_gcc_prof < 543.txt There was a file with statistics with the extension gdca.
gcc -O2 -fprofile-use --param max-unrolled-insns=0 --param large-function-insns=40 --param large-function-growth=XX -std=c99 main.c -o aout_gcc By manipulating c XX, one can see that after receiving information from the dynamic profiler, the gcc and icc compilers behave the same, i.e. do substitution in accordance with the actual weight of each call.
Considering the code with different options and even more so in cases of different compilers is quite interesting. Here, for example, at the moment when the gcc compiler has already substituted foo (3), but the code expansion threshold did not allow to substitute foo (2), gcc made a clone of the foo function to call from 2. That is, I created a new function without arguments with a constant tightened 2. At the same time, both compilers tried to improve the locality of the code and brought the “cold code” to a separate location. Icc at the end of the main routine, and gcc created a separate section, main.cold, for this. When you run the instrumented compiler with 543.txt input data, these sections have foo (6) and foo (7) calls.
findings
Of course, the experiment described here is not complete, and it could be expanded by analyzing whether the compiler takes into account, forming a queue of calls for substitution, other factors, for example, the size of the function for substitution. One could try to understand in what order the call graph, etc., are bypassed. But in general, the following conclusion was obtained. Without a dynamic profiler, compilers do not attempt to guess the possible “weight” or possible frequency of a particular call. Accordingly, the order of substitutions looks quite random. In the case of dynamic profiling, when the weight of each call is determined experimentally, both compilers use this information, and as a result, the order of substitutions fully corresponds to the criterion proposed here. Those. the best substitution benefits can be obtained using a dynamic profiler.
Well, developers can effectively use pragmas in their work to tell the compiler which calls should be inlined first. If it is clear to the programmer that some calculations will be performed rarely, then it makes sense to put them into separate functions and forbid them to be substituted with directives. This will improve the locality of the executed code and, most likely, will lead to a small performance gain due to more optimal use of the cache subsystem.
A beautiful blonde and a dinosaur are borrowed from publicly available Internet resources, not containing references to the authors of these materials and any restrictions for borrowing them:
1. www.pinterest.com
2. solnushki.ru
Source: https://habr.com/ru/post/240203/
All Articles