Yandex post office: how we made a service analyzing the results of mailings in realtime
Yandex has a service for bona fide letter mailers - the Post Office . (For unscrupulous, we have Antispam and the "Unsubscribe" button in the Mail.) With it, they can understand how many of their letters Yandex.Mail users delete, how much time they read, how much they read. My name is Anton Kholodkov, and I was developing the server part of this system. In this post I will talk about how we developed it and what difficulties we encountered.

For the sender, the Post Office interface is completely transparent. It is enough to register your domain or email in the system. The service collects and analyzes data on a variety of parameters: name and domain of the sender, time, sign of spam / not spam, read / not read. Also implemented is aggregation over a list-id field — a special header for identifying mailings. We have several data sources.
First, the metabase delivery system. It generates events that the letter entered the system. Secondly, the web-based mail interface, where the user changes the state of the letter: reads it, marks it as spam or deletes it. All these actions should get into the repository.
')
When saving and modifying information there are no strict time requirements. Recording may be added or changed for quite some time. At this point, the statistics will reflect the previous state of the system. With large amounts of data it is imperceptible to the user. One or two of his actions, which have not yet been put in the base, will not be able to change the statistics to any great significance.
In the web interface, the response speed is very important - inhibitions look ugly. In addition, it is important not to allow "jumps" of values when updating the browser window. This situation occurs when data is extracted from one head, then from another.
I want to say a few words about choosing a platform. We immediately realized that not every solution will cope with the data flow that we have. Initially there were three candidates: MongoDB , Postgres , our own bundle of Lucene + Zookeeper . We refused the first two due to insufficient performance. Especially big problems were when inserting large amounts of data. As a result, we decided to use the experience of our colleagues and used the Lucene + Zookeeper bundle - the same bundle is used by Yandex.Mail Search.
The standard of communication between components within the system has become JSON. Java and Javascript have convenient tools for working with it. In C ++, use yajl and boost :: property_tree. All components implement the REST API.
The data in the system is stored in Apache Lucene. As you know, Lucene is a library developed by the Apache Foundation for full-text search. It allows you to store and retrieve any pre-indexed data. We turned it into a server: we taught us how to store data, add it to an index, and compress it. With the help of http request you can search, add, modify. There are various types of aggregation.
For each status change record to be processed in all cluster heads, use Zookeeper, another Apache Fondation product. We have finalized it and added the ability to use as a queue.
A special daemon is written to extract and analyze data from Lucene. It focuses all the logic of work. Web interface calls are turned into http requests to Lucene. Immediately implemented the logic of data aggregation, sorting and other processing that are needed to display data in the web interface.
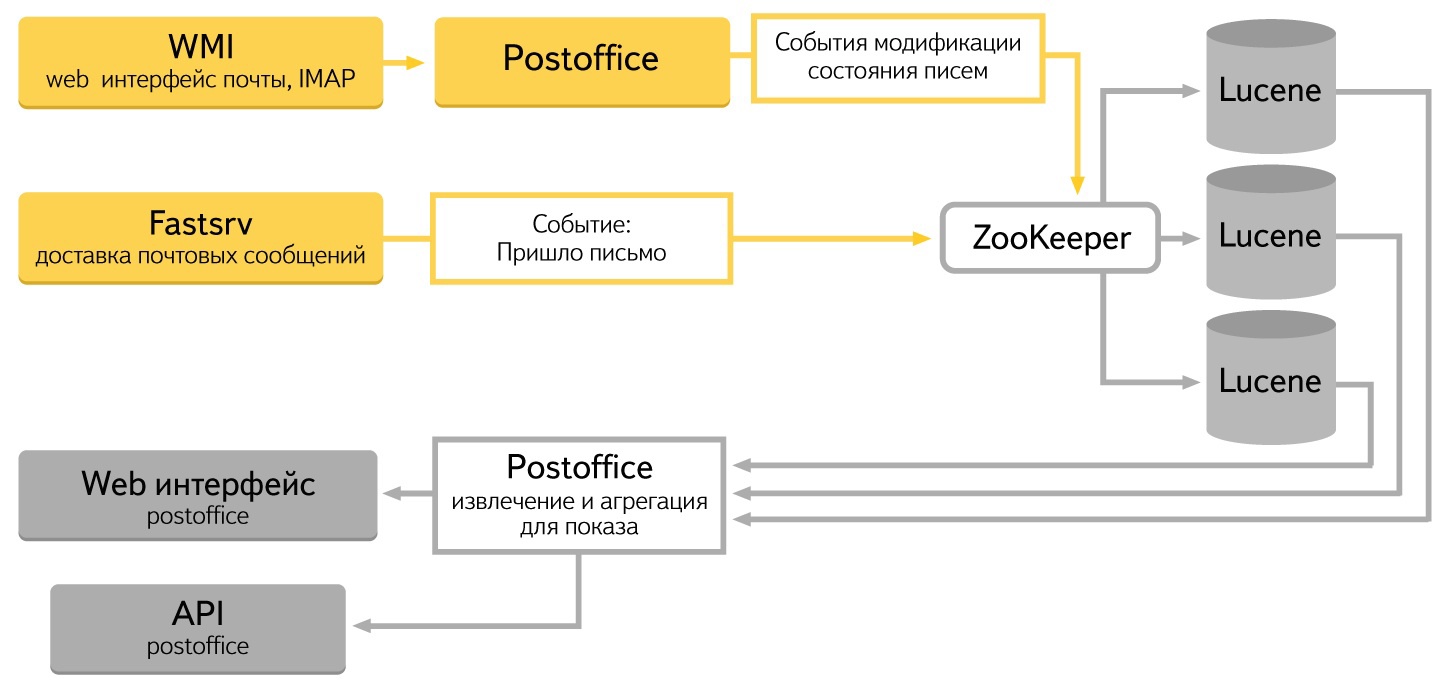
When users perform actions in the web interface, information about these actions is saved through Zookeeper in Lucene. Each action — for example, pressing the “Spam” button — changes the state of the system, and you need to carefully modify all the data it affects. This is the most difficult part of the system, we rewrote and debugged it the longest.
The first attempt to solve the problem was, as they say, "head on." We wanted to put Lucene status records on the fly. Aggregate data was assumed in real time when retrieved. This solution worked fine on a small number of records. Summing hundreds of records took microseconds. Everything looked great. Problems began with a large number of records. For example, thousands of already processed seconds. Tens of thousands - tens of seconds. It annoyed users and us. It was necessary to look for ways to speed up data output.
In this case, the aggregation of ordinary users with tens, hundreds and thousands of letters per day was not a problem. The problem was the individual mailers who sent out hundreds of thousands of letters in a very short time. It was impossible to calculate real-time data for them.
The solution was found after analyzing requests from the web interface. There were few kinds of queries, and they all boiled down to summing up the data or finding the average of a series of data. We added aggregation records to the database and began to modify them when adding or changing letter status records. For example, a letter arrived - they added one to the total counter. The user deleted the letter - they took one from the total counter and added one to the deleted ones. The user has marked the letter with spam - they have added one to the counter of "spam letters". The number of records that need to be processed to fulfill the request has decreased, and this greatly accelerated the aggregation. Zookeeper makes it easy to ensure data integrity. Changing aggregate records takes time, but we can afford a small data lag.
What was the result? Now there are four cars on the system at Lucene, three at Zookeeper. Input data comes from 10 machines and is issued on six frontend machines. Per second, the system processes 4,500 modification requests and 1,100 read requests. Storage capacity today is 3.2 terabytes.
The storage system on Lucene + Zookeeper has proven itself very stable. You can disable the node on the fly on Lucene, you can add a node. Zookeeper keeps history and rolls the necessary number of events on the new machine. After a while we will get a head with relevant information. One machine in the cluster is allocated for storing data backups.
Despite the short development time, the system turned out to be reliable and fast. The architecture makes it easy to scale - both vertically and horizontally - and add new data analysis capabilities. Which we will add for you soon.
For the sender, the Post Office interface is completely transparent. It is enough to register your domain or email in the system. The service collects and analyzes data on a variety of parameters: name and domain of the sender, time, sign of spam / not spam, read / not read. Also implemented is aggregation over a list-id field — a special header for identifying mailings. We have several data sources.
First, the metabase delivery system. It generates events that the letter entered the system. Secondly, the web-based mail interface, where the user changes the state of the letter: reads it, marks it as spam or deletes it. All these actions should get into the repository.
')
When saving and modifying information there are no strict time requirements. Recording may be added or changed for quite some time. At this point, the statistics will reflect the previous state of the system. With large amounts of data it is imperceptible to the user. One or two of his actions, which have not yet been put in the base, will not be able to change the statistics to any great significance.
In the web interface, the response speed is very important - inhibitions look ugly. In addition, it is important not to allow "jumps" of values when updating the browser window. This situation occurs when data is extracted from one head, then from another.
I want to say a few words about choosing a platform. We immediately realized that not every solution will cope with the data flow that we have. Initially there were three candidates: MongoDB , Postgres , our own bundle of Lucene + Zookeeper . We refused the first two due to insufficient performance. Especially big problems were when inserting large amounts of data. As a result, we decided to use the experience of our colleagues and used the Lucene + Zookeeper bundle - the same bundle is used by Yandex.Mail Search.
The standard of communication between components within the system has become JSON. Java and Javascript have convenient tools for working with it. In C ++, use yajl and boost :: property_tree. All components implement the REST API.
The data in the system is stored in Apache Lucene. As you know, Lucene is a library developed by the Apache Foundation for full-text search. It allows you to store and retrieve any pre-indexed data. We turned it into a server: we taught us how to store data, add it to an index, and compress it. With the help of http request you can search, add, modify. There are various types of aggregation.
For each status change record to be processed in all cluster heads, use Zookeeper, another Apache Fondation product. We have finalized it and added the ability to use as a queue.
A special daemon is written to extract and analyze data from Lucene. It focuses all the logic of work. Web interface calls are turned into http requests to Lucene. Immediately implemented the logic of data aggregation, sorting and other processing that are needed to display data in the web interface.
When users perform actions in the web interface, information about these actions is saved through Zookeeper in Lucene. Each action — for example, pressing the “Spam” button — changes the state of the system, and you need to carefully modify all the data it affects. This is the most difficult part of the system, we rewrote and debugged it the longest.
The first attempt to solve the problem was, as they say, "head on." We wanted to put Lucene status records on the fly. Aggregate data was assumed in real time when retrieved. This solution worked fine on a small number of records. Summing hundreds of records took microseconds. Everything looked great. Problems began with a large number of records. For example, thousands of already processed seconds. Tens of thousands - tens of seconds. It annoyed users and us. It was necessary to look for ways to speed up data output.
In this case, the aggregation of ordinary users with tens, hundreds and thousands of letters per day was not a problem. The problem was the individual mailers who sent out hundreds of thousands of letters in a very short time. It was impossible to calculate real-time data for them.
The solution was found after analyzing requests from the web interface. There were few kinds of queries, and they all boiled down to summing up the data or finding the average of a series of data. We added aggregation records to the database and began to modify them when adding or changing letter status records. For example, a letter arrived - they added one to the total counter. The user deleted the letter - they took one from the total counter and added one to the deleted ones. The user has marked the letter with spam - they have added one to the counter of "spam letters". The number of records that need to be processed to fulfill the request has decreased, and this greatly accelerated the aggregation. Zookeeper makes it easy to ensure data integrity. Changing aggregate records takes time, but we can afford a small data lag.
What was the result? Now there are four cars on the system at Lucene, three at Zookeeper. Input data comes from 10 machines and is issued on six frontend machines. Per second, the system processes 4,500 modification requests and 1,100 read requests. Storage capacity today is 3.2 terabytes.
The storage system on Lucene + Zookeeper has proven itself very stable. You can disable the node on the fly on Lucene, you can add a node. Zookeeper keeps history and rolls the necessary number of events on the new machine. After a while we will get a head with relevant information. One machine in the cluster is allocated for storing data backups.
Despite the short development time, the system turned out to be reliable and fast. The architecture makes it easy to scale - both vertically and horizontally - and add new data analysis capabilities. Which we will add for you soon.
Source: https://habr.com/ru/post/240181/
All Articles