Is a torrent client on a linux gateway a myth or a reality?
I got somehow almost randomly a Mini-ITX format motherboard on the Intel Atom, and immediately flashed through my head the thought: “A quiet home server! ..” (the power supply unit will fit a notebook + soldered processor with passive cooling). Thought - done!
I bought a case, a memory, one 2.5 HDD (having planned to take the same for a mirror in a couple of months), as well as a second network card for distributing the Internet to a local network, and here on my near-server there is a new (for that time) Debian Squeeze.
I began to think about what I want on this server, and since I am from the category of people trying to squeeze out of the existing everything a little bit, it was decided to raise the web, mail and jabber server (there is white statics), plus “And a little bit more” to get hold of a torrent-rocking chair 24/7.
')
Everything would be fine if it were not for one BUT - a torrent client on the gateway. It sounds [not] a lot of crazy, because the torrent-traffic going to the torrent-client on the gateway, will forget about the entire Internet channel , leaving the local network device with a nose, isn’t it? But do not rush to conclusions: such nonsense is quite a right to life. Moreover, a working solution was found that allowed the rocking chair to coexist peacefully with other services on the same server, and not to interfere with the clients of the local network. But first things first…
I have repeatedly met the statement “it’s not worthwhile to be engaged in shaping incoming traffic, since he has already arrived, which means he has occupied a part / the entire width of your channel from the upstream distributor (for example, from the provider). ” This statement is true, but partially, because requires clarification:
For tcp connections there is a " slow start ". This means that packets between hosts will not start being sent immediately at maximum speed. Instead, it (speed) will increase / decrease gradually, based on the results of confirmation of receiving packets and the presence of losses. In other words, the speed of sending packets will “float”, adjusting to the channel bandwidth between the hosts.
Taking into account this behavior, we can somewhere between the hosts artificially lower the rate at which packets of tcp connections go through, thereby imposing the need to reduce the transmission speed to the hosts.
But in the case of udp-packages everything is somewhat sadder, because the sending party will simply “throw” them, not taking into account neither the loss nor the transit time of the packet (UDP — it is in Africa UDP: non-guaranteed delivery with all the consequences ...). And this is already fraught with the following: if udp-traffic drives out all the band guaranteed to you, for example, by the provider, then the packages will simply start dropping, and what packages they will be - is given to the Internet service provider, while the sending party will still send You have such traffic.
Sad? Yes, but not so much so that I abandoned my idea to drive the torrent rocking chair to the only 24/7 computer in the house and this is why: the torrent client makes a request to upload not the entire content of the distribution at once (they say, let's throw me all in one thread). Instead, requests are sent for some pieces, the size of which varies from 16 kilobytes to 4 megabytes. From which it follows that by delaying the injected parts of the distribution, it is possible to reduce the frequency of requests by our side for downloading other parts, and, as a result, to reduce the channel width consumed by the torrent client.
So, if we can force the sending party to reduce the rate of sending packets to us, then the width we use from the maximum allocated by the provider will be used more rationally.
The complete flow of the packet through the GNU / Linux network stack is as follows:
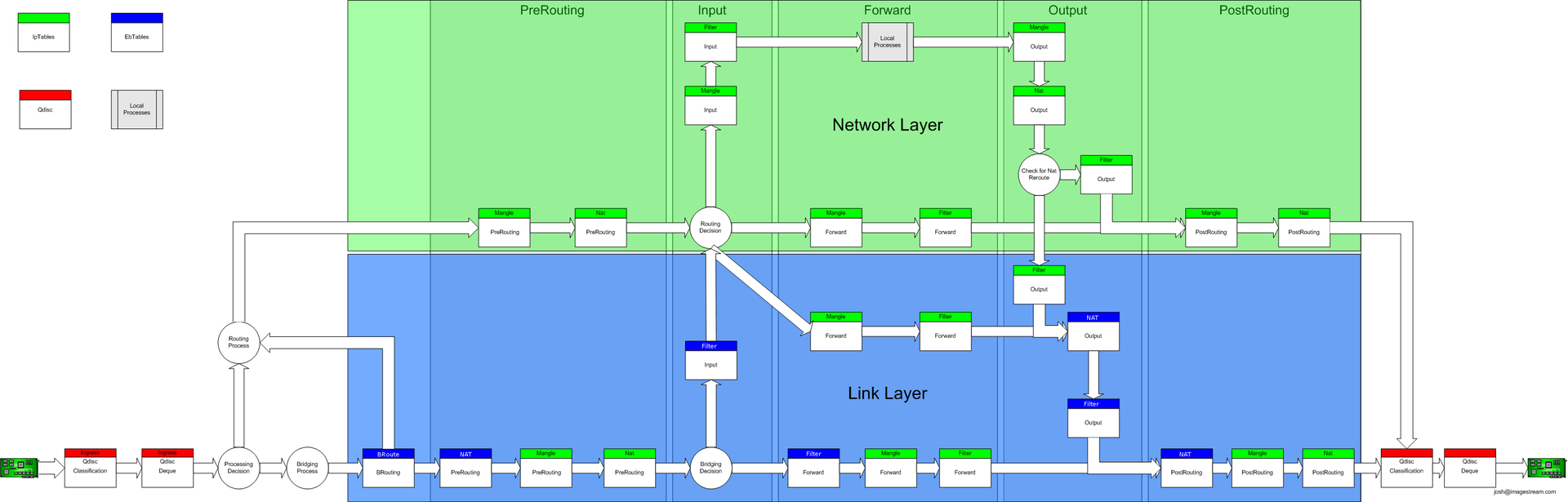
For simplicity, let's consider a situation in which a packet is sent from the vast expanses of the Internet to a device behind a linux router, and this packet has already left the provider’s equipment, i.e. the next point will be your WAN interface.
Before we get into the clutches of the mighty Iptables, the package will go through ingress-discipline, and already on this discipline we could “hang” classes describing their guaranteed and maximum speeds, but this qdisc has two significant limitations:
In general, ingress-discipline does not suit us for high-grade dynamic shaping.
After ingress, the packet is sent to Iptables where filtering / NAT / marking / ... occurs, and after that the packet is sent to the egres-discipline of the LAN interface, through which it (the packet) must leave the router and go to the local network.
I would like to draw attention to the fact that:
But now we can reformulate the statement about the shaping of incoming traffic: in GNU / Linux, shape incoming traffic correctly on the outgoing interface of the device, which will stand up to the consumers of the channel, while this device should not consume traffic for its own personal needs ( This will have to be considered when forming classes in the shaper).
As we have already found out, shaping traffic is more correct on egress discipline, i.e. on the outgoing interface in relation to the direction of the packet through the router. And this means that if you run the torrent client on the router itself, the packets destined for the client will never fall into the egress discipline and will not be able to “delay” them!
Realizing that on a router distributing the Internet to a local area network, launching a torrent client without a hard limit on the channel width consumed in it is not feng shui, thought about how this traffic can be shaped as if it went to the local area network, those. would you go first to the “giving” interface, and then you would get into the torrent client itself, and so that all this happens within the same piece of hardware?
At first, I began to look towards virtualization, but the problem was aggravated by the fact that the hardware was too weak to raise the para-virtual machine, but hardware virtualization could not. But only a protracted wander across the expanses of the Boundless, a solution was found that was suitable for all articles - OpenVZ .
Having installed the openvz core, we, in addition to isolation of the boiler, we get the venet interface on the host system running at the L3 level (veth devices can be used for L2), and all the ip traffic flying to the containers goes to the venet before i.e. we get the outgoing interface. What the doctor ordered!
Having deployed VZ-containers on the host and spreading the torrent client and other services in them, I got this scheme:
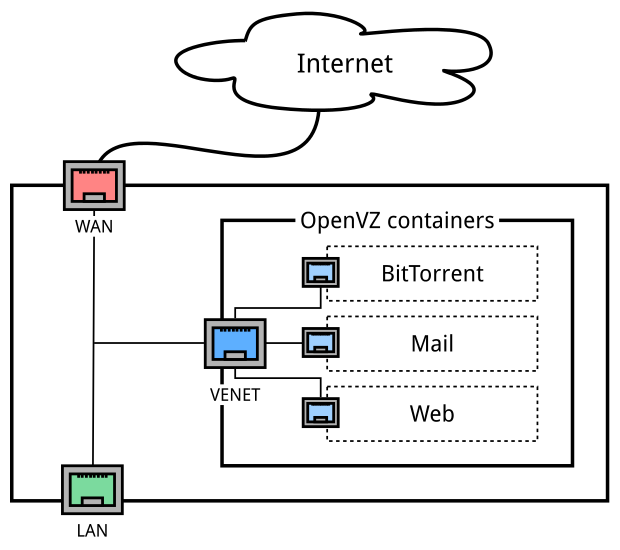
WAN - a physical interface looking into the world
VENET is a virtual L3 interface through which all traffic going to containers passes (subnet 192.168.254.0/24)
LAN - physical interface looking to the local network (subnet 192.168.0.0/24)
Almost done, except that only one interface can participate in dynamic traffic shaping. Feeling that there may be questions in this place, I will try to explain in a little more detail.
My channel width to the world is 100 Mbit / s, and absolutely predictably, I wanted to make the most of this for my own selfish and not-so-purpose purposes as follows:
Sounds good, doesn't it? And if we also take into account that the example with http traffic of the 2nd item is a small part of the requirements, having realized that you can achieve an idyll “torrents are stretching, pings are running, youtube looks”, then the desire to make it come to life appears even more.
I began to think about how to get around the problem associated with the 3rd item of requirements, because you cannot borrow unused width from other networks ... Well, since we cannot achieve dynamic shaping on two interfaces, we will shape it on the ifb device, having previously wrapped all traffic c egress-disciplines LAN and VENET on it.
Before peeking under the hood, I would like to briefly tell you about the principle of traffic classification, which I chose for myself:
Well, now let's get started.
That's all. I want to believe that the solution I have outlined will help someone, and will encourage someone to improve it.
I bought a case, a memory, one 2.5 HDD (having planned to take the same for a mirror in a couple of months), as well as a second network card for distributing the Internet to a local network, and here on my near-server there is a new (for that time) Debian Squeeze.
I began to think about what I want on this server, and since I am from the category of people trying to squeeze out of the existing everything a little bit, it was decided to raise the web, mail and jabber server (there is white statics), plus “And a little bit more” to get hold of a torrent-rocking chair 24/7.
')
Everything would be fine if it were not for one BUT - a torrent client on the gateway. It sounds [not] a lot of crazy, because the torrent-traffic going to the torrent-client on the gateway, will forget about the entire Internet channel , leaving the local network device with a nose, isn’t it? But do not rush to conclusions: such nonsense is quite a right to life. Moreover, a working solution was found that allowed the rocking chair to coexist peacefully with other services on the same server, and not to interfere with the clients of the local network. But first things first…
1. A bit of theory
I have repeatedly met the statement “it’s not worthwhile to be engaged in shaping incoming traffic, since he has already arrived, which means he has occupied a part / the entire width of your channel from the upstream distributor (for example, from the provider). ” This statement is true, but partially, because requires clarification:
In the context of TCP / IP
For tcp connections there is a " slow start ". This means that packets between hosts will not start being sent immediately at maximum speed. Instead, it (speed) will increase / decrease gradually, based on the results of confirmation of receiving packets and the presence of losses. In other words, the speed of sending packets will “float”, adjusting to the channel bandwidth between the hosts.
Taking into account this behavior, we can somewhere between the hosts artificially lower the rate at which packets of tcp connections go through, thereby imposing the need to reduce the transmission speed to the hosts.
But in the case of udp-packages everything is somewhat sadder, because the sending party will simply “throw” them, not taking into account neither the loss nor the transit time of the packet (UDP — it is in Africa UDP: non-guaranteed delivery with all the consequences ...). And this is already fraught with the following: if udp-traffic drives out all the band guaranteed to you, for example, by the provider, then the packages will simply start dropping, and what packages they will be - is given to the Internet service provider, while the sending party will still send You have such traffic.
Sad? Yes, but not so much so that I abandoned my idea to drive the torrent rocking chair to the only 24/7 computer in the house and this is why: the torrent client makes a request to upload not the entire content of the distribution at once (they say, let's throw me all in one thread). Instead, requests are sent for some pieces, the size of which varies from 16 kilobytes to 4 megabytes. From which it follows that by delaying the injected parts of the distribution, it is possible to reduce the frequency of requests by our side for downloading other parts, and, as a result, to reduce the channel width consumed by the torrent client.
So, if we can force the sending party to reduce the rate of sending packets to us, then the width we use from the maximum allocated by the provider will be used more rationally.
In the context of packet passing through a linux router
The complete flow of the packet through the GNU / Linux network stack is as follows:
For simplicity, let's consider a situation in which a packet is sent from the vast expanses of the Internet to a device behind a linux router, and this packet has already left the provider’s equipment, i.e. the next point will be your WAN interface.
Before we get into the clutches of the mighty Iptables, the package will go through ingress-discipline, and already on this discipline we could “hang” classes describing their guaranteed and maximum speeds, but this qdisc has two significant limitations:
- the classes added to this discipline cannot contain child classes, and hence the borrowing of unused width by the child classes from the parent will not work;
- the traffic going to the local network cannot be “scattered” into classes based on ip because to NAT'a it has not come yet.
In general, ingress-discipline does not suit us for high-grade dynamic shaping.
After ingress, the packet is sent to Iptables where filtering / NAT / marking / ... occurs, and after that the packet is sent to the egres-discipline of the LAN interface, through which it (the packet) must leave the router and go to the local network.
I would like to draw attention to the fact that:
- There is only one ingress-discipline and one egress-discipline on the entire path of the packet passing through the linux-router: ingress - on the interface, into which the packet flies, and egress - on the interface that releases the packets to the will;
- packets destined directly to the router will never fall into egress discipline (without tweaks with an ifb device).
But now we can reformulate the statement about the shaping of incoming traffic: in GNU / Linux, shape incoming traffic correctly on the outgoing interface of the device, which will stand up to the consumers of the channel, while this device should not consume traffic for its own personal needs ( This will have to be considered when forming classes in the shaper).
2. We go around restrictions
As we have already found out, shaping traffic is more correct on egress discipline, i.e. on the outgoing interface in relation to the direction of the packet through the router. And this means that if you run the torrent client on the router itself, the packets destined for the client will never fall into the egress discipline and will not be able to “delay” them!
Realizing that on a router distributing the Internet to a local area network, launching a torrent client without a hard limit on the channel width consumed in it is not feng shui, thought about how this traffic can be shaped as if it went to the local area network, those. would you go first to the “giving” interface, and then you would get into the torrent client itself, and so that all this happens within the same piece of hardware?
At first, I began to look towards virtualization, but the problem was aggravated by the fact that the hardware was too weak to raise the para-virtual machine, but hardware virtualization could not. But only a protracted wander across the expanses of the Boundless, a solution was found that was suitable for all articles - OpenVZ .
Having installed the openvz core, we, in addition to isolation of the boiler, we get the venet interface on the host system running at the L3 level (veth devices can be used for L2), and all the ip traffic flying to the containers goes to the venet before i.e. we get the outgoing interface. What the doctor ordered!
Having deployed VZ-containers on the host and spreading the torrent client and other services in them, I got this scheme:
WAN - a physical interface looking into the world
VENET is a virtual L3 interface through which all traffic going to containers passes (subnet 192.168.254.0/24)
LAN - physical interface looking to the local network (subnet 192.168.0.0/24)
Almost done, except that only one interface can participate in dynamic traffic shaping. Feeling that there may be questions in this place, I will try to explain in a little more detail.
My channel width to the world is 100 Mbit / s, and absolutely predictably, I wanted to make the most of this for my own selfish and not-so-purpose purposes as follows:
- if at some point something is pulled from outside by a torrent client (BitTorrent container) and only to them, then all the available band must be given to him
- if while downloading a torrent client, someone from the local network or subnetwork of containers starts downloading / watching via http, then the torrent traffic needs to be clamped to, say, 32Kb / s, and the rest of the width should be sent under http
- the most important thing is that the full width of the channel should be able to use any devices, regardless of which subnet they are in: behind the LAN interface or behind the VENET interface
Sounds good, doesn't it? And if we also take into account that the example with http traffic of the 2nd item is a small part of the requirements, having realized that you can achieve an idyll “torrents are stretching, pings are running, youtube looks”, then the desire to make it come to life appears even more.
I began to think about how to get around the problem associated with the 3rd item of requirements, because you cannot borrow unused width from other networks ... Well, since we cannot achieve dynamic shaping on two interfaces, we will shape it on the ifb device, having previously wrapped all traffic c egress-disciplines LAN and VENET on it.
3. For the cause!
Before peeking under the hood, I would like to briefly tell you about the principle of traffic classification, which I chose for myself:
- when determining the priority of packets, the following roles play a role: protocol and port number;
- all unclassified traffic cannot “accelerate” to the maximum, because then (in the case of torrent traffic) it is extremely reluctant to give the borrowed lane to a class with a higher priority. Those. I left a gap to “squeeze” more important packages.
Well, now let's get started.
We define the parameters, clear the disciplines and load the ifb-device
#!/bin/bash IPT="/sbin/iptables" TC="/sbin/tc" IP="/bin/ip" DEV_LAN="eth1" # , DEV_VENET="venet0" # , DEV_IFB_LAN="ifb0" # CEIL_IN="95mbit" # 5% CEIL_IN_BULK="90mbit" # # $TC qdisc del dev $DEV_LAN root >/dev/null 2>&1 $TC qdisc del dev $DEV_LAN ingress >/dev/null 2>&1 $TC qdisc del dev $DEV_VENET root >/dev/null 2>&1 $TC qdisc del dev $DEV_VENET ingress >/dev/null 2>&1 # ifb- rmmod ifb >/dev/null 2>&1 modprobe ifb numifbs=1 $IP link set $DEV_IFB_LAN up Create disciplines, classes and filters
# htb- ifb- $TC qdisc add dev $DEV_IFB_LAN root handle 1: htb default 80 # , $TC class add dev $DEV_IFB_LAN parent 1: classid 1:1 htb rate $CEIL_IN # , $TC class add dev $DEV_IFB_LAN parent 1:1 classid 1:10 htb rate 5mbit ceil 5mbit prio 0 $TC class add dev $DEV_IFB_LAN parent 1:1 classid 1:20 htb rate 10mbit ceil $CEIL_IN prio 1 $TC class add dev $DEV_IFB_LAN parent 1:1 classid 1:30 htb rate 10mbit ceil $CEIL_IN prio 2 $TC class add dev $DEV_IFB_LAN parent 1:1 classid 1:40 htb rate 10mbit ceil $CEIL_IN prio 3 $TC class add dev $DEV_IFB_LAN parent 1:1 classid 1:50 htb rate 10mbit ceil $CEIL_IN prio 4 $TC class add dev $DEV_IFB_LAN parent 1:1 classid 1:80 htb rate 50kbit ceil $CEIL_IN_BULK prio 7 # $TC qdisc add dev $DEV_IFB_LAN parent 1:10 handle 10: sfq perturb 10 $TC qdisc add dev $DEV_IFB_LAN parent 1:20 handle 20: sfq perturb 10 $TC qdisc add dev $DEV_IFB_LAN parent 1:30 handle 30: sfq perturb 10 $TC qdisc add dev $DEV_IFB_LAN parent 1:40 handle 40: sfq perturb 10 $TC qdisc add dev $DEV_IFB_LAN parent 1:50 handle 50: sfq perturb 10 $TC qdisc add dev $DEV_IFB_LAN parent 1:80 handle 80: sfq perturb 10 # ip, $TC filter add dev $DEV_IFB_LAN parent 10: protocol ip handle 110 flow hash keys dst divisor 512 $TC filter add dev $DEV_IFB_LAN parent 20: protocol ip handle 120 flow hash keys dst divisor 512 $TC filter add dev $DEV_IFB_LAN parent 30: protocol ip handle 130 flow hash keys dst divisor 512 $TC filter add dev $DEV_IFB_LAN parent 40: protocol ip handle 140 flow hash keys dst divisor 512 $TC filter add dev $DEV_IFB_LAN parent 50: protocol ip handle 150 flow hash keys dst divisor 512 $TC filter add dev $DEV_IFB_LAN parent 80: protocol ip handle 180 flow hash keys dst divisor 512 # TC_A_F="$TC filter add dev $DEV_IFB_LAN parent 1:" # , $TC_A_F prio 10 protocol ip u32 match ip protocol 6 0xff \ match u8 0x05 0x0f at 0 \ match u16 0x0000 0xffc0 at 2 \ match u8 0x10 0xff at 33 \ flowid 1:10 # ack < 64b $TC_A_F prio 1 protocol ip u32 match ip protocol 1 0xff flowid 1:10 # icmp $TC_A_F prio 1 protocol ip u32 match ip protocol 6 0xff match ip sport 53 0xffff flowid 1:10 # dns $TC_A_F prio 1 protocol ip u32 match ip protocol 17 0xff match ip sport 53 0xffff flowid 1:10 # dns $TC_A_F prio 2 protocol ip u32 match ip protocol 17 0xff match ip tos 0x68 0xff flowid 1:20 # voip $TC_A_F prio 2 protocol ip u32 match ip protocol 17 0xff match ip tos 0xb8 0xff flowid 1:20 # voip $TC_A_F prio 2 protocol ip u32 match ip protocol 6 0xff match ip sport 8000 0xffff flowid 1:20 # icecast $TC_A_F prio 3 protocol ip u32 match ip protocol 6 0xff match ip sport 22 0xffff flowid 1:30 # ssh $TC_A_F prio 3 protocol ip u32 match ip protocol 6 0xff match ip sport 3389 0xffff flowid 1:30 # rdp $TC_A_F prio 3 protocol ip u32 match ip protocol 6 0xff match ip sport 5222 0xffff flowid 1:30 # jabber c2s $TC_A_F prio 3 protocol ip u32 match ip protocol 6 0xff match ip sport 5223 0xffff flowid 1:30 # jabber c2s $TC_A_F prio 3 protocol ip u32 match ip protocol 6 0xff match ip sport 5269 0xffff flowid 1:30 # jabber s2s $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 80 0xffff flowid 1:40 # http $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 443 0xffff flowid 1:40 # https $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 143 0xffff flowid 1:40 # imap $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 993 0xffff flowid 1:40 # imaps $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 25 0xffff flowid 1:40 # smtp $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 465 0xffff flowid 1:40 # smtps $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 587 0xffff flowid 1:40 # smtps $TC_A_F prio 4 protocol ip u32 match ip protocol 6 0xff match ip sport 21 0xffff flowid 1:40 # ftp $TC_A_F prio 5 protocol ip u32 match ip protocol 6 0xff match ip sport 20 0xffff flowid 1:50 # ftp And the final chord: we redirect traffic from egress disciplines venet0 and eth1 interfaces to the ifb-device
# DEV_LAN => DEV_IFB_LAN (ifb0) $TC qdisc add dev $DEV_LAN root handle 1: prio # $TC filter add dev $DEV_LAN parent 1: prio 1 protocol ip u32 match ip src 192.168.8.253/32 action pass # ip . $TC filter add dev $DEV_LAN parent 1: prio 1 protocol ip u32 match ip src 192.168.254.0/24 action pass # vz- . # , ingress DEV_LAN, egress DEV_IFB_LAN (ifb0) $TC filter add dev $DEV_LAN parent 1: prio 2 protocol ip u32 match u32 0 0 action mirred egress redirect dev $DEV_IFB_LAN # DEV_VENET -> DEV_IFB_LAN (ifb0) $TC qdisc add dev $DEV_VENET root handle 1: prio # $TC filter add dev $DEV_VENET parent 1: prio 1 protocol ip u32 match ip src 192.168.8.0/24 action pass # vz- # , ingress DEV_VENET, egress DEV_IFB_LAN (ifb0) $TC filter add dev $DEV_VENET parent 1: prio 2 protocol ip u32 match u32 0 0 action mirred egress redirect dev $DEV_IFB_LAN That's all. I want to believe that the solution I have outlined will help someone, and will encourage someone to improve it.
Source: https://habr.com/ru/post/239949/
All Articles