Logbroker: collecting and supplying large amounts of data in Yandex
Hello! My name is Alexey Ozeritsky. In Yandex, I work in the development of technologies and infrastructure. Not only to our services that are used by millions of people, it is important to be able to work with really large amounts of data without failures. One of our key internal tools is Ya.Statistika, information in which is intended only for Yandex employees and moreover is a trade secret. Statistics deals with the collection, storage and processing of information (first of all logs) from Yandex services. The result of our work with it is statistical calculations for further analytics and product decision making.

One of the key components of Statistics is Logbroker, a distributed multi-directory solution for collecting and supplying data. The key features of the system are the ability to experience the disconnection of the data center, support for the semantics exactly once on the delivery of messages and support for real-time flows (seconds of delay from the occurrence of an event at the source to the reception at the receiver).
At the core of the system is Apache Kafka . Using the API, Logbroker isolates the user from Apache Kafka's raw threads, implements disaster recovery processes (including exactly once semantics) and service processes (inter-center replication, data distribution to the calculation clusters: YT, YaMR ...).
Initially, to calculate reports, Ya.Statistics used Oracle. Data was downloaded from servers and recorded in Oracle. Once a day, reports were built using SQL queries.
Data volumes grew 2.5 times a year, so by 2010 such a scheme began to fail. The database did not cope with the load, and the calculation of reports slowed down. Calculation of reports from the database was transferred to YaMR, and as a long-term storage of logs they began to use a self-written solution, which was a distributed storage, where each piece of data appeared as a separate file. The solution was simply called Archive.
')
The archive had many features of the current Logbroker. In particular, he was able to receive data and distribute data to various YaMR clusters and external users. The Archive also stored metadata and made it possible to receive samples by various parameters (time, file name, server name, log type ...). In the event of a failure or loss of data on YaMR, it was possible to recover an arbitrary piece of data from the Archive.
We still went around the servers, downloaded the data and saved them to the Archive. In early 2011, this approach began to slip. In addition to the obvious security problem (statistics servers have access to all Yandex servers), he had problems with scalability and performance. As a result, a client was written, which was installed on servers and shipped logs directly to the Archive. The client (the internal product name of the push-client) is a lightweight C program that does not use any external dependencies and supports various Linux, FreeBSD, and even Windows variants. In the course of work, the client monitors the update of data files (logs) and sends new data via the http (s) protocol.
The archive had some flaws. He didn’t worry about disconnecting the data center, because of the file organization he had limited opportunities for scaling and didn’t fundamentally support the receipt / return of data in real time. Before sending the data to the archive, it was necessary to accumulate a buffer at intervals of at least a minute, while our consumers wanted second delivery delays.
It was decided to write a new archive, based on one of the available NoSQL solutions for fault-tolerant storage.
We considered HBase , Cassandra , Elliptics . HBase was not suitable because of problems with inter-center replication. Cassandra and Elliptics did not match due to a significant performance drop during the defragmentation of the base and when adding new machines to the cluster. In principle, the restrictions on adding new machines could still be experienced, since this is an infrequent operation, but the restriction on defragmentation turned out to be significant: every day a daily data set is recorded in the archive, while the old data is deleted N days ago, that is, defragmentation would have to perform constantly.
In the end, we decided to revise our delivery architecture. Instead of a long-term repository - the Archive with a complete set of metadata and the ability to build all sorts of slices, we decided to write easy and fast short-term repository with minimal functionality for building samples.
The basis for the implementation took Apache Kafka.
Kafka implements a persistent message queue. Persistence means that data sent to Kafka continues to exist after restarting processes or machines. Each stream of the same type of messages in Kafka is represented by an entity called a topic . The topic is divided into partitions , which ensures parallel writing and reading of the topic. Kafka scales very easily: with an increase in the volume of threads, you can increase the number of topic partitions and the number of machines servicing them.
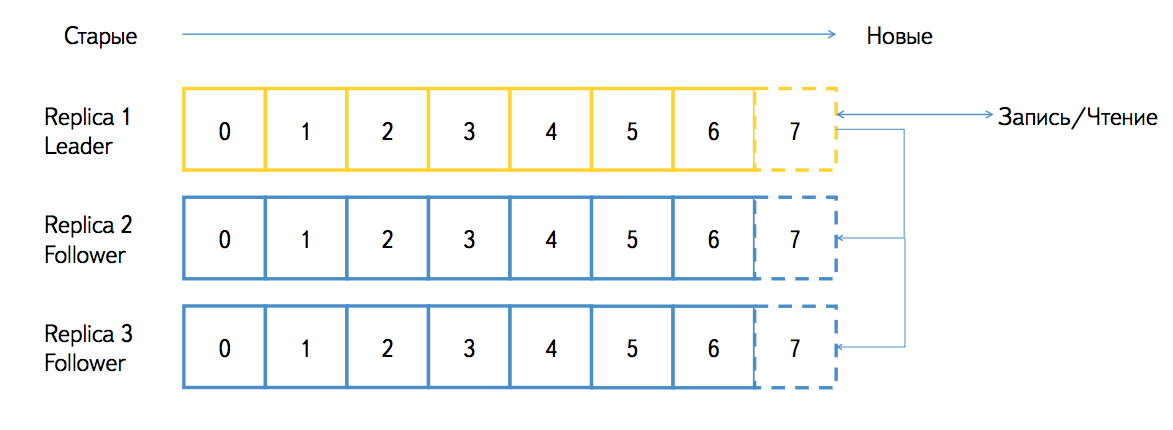
A partition can exist in several replicas and is serviced by different nodes ( brokers in Kafka terms). Replicas are of two types: leader and follower. The leader replica accepts all requests for writing and reading data, the replica follower accepts and stores the stream from the replica leader. Kafka guarantees the identity of all replicas bytes to bytes. If one of the brokers becomes unavailable, then all the replica leaders will automatically move to other brokers and the partition can still be written and read. When raising a broker, all the replicas that he served automatically become followers and catch the accumulated backlog from the replica leaders. From time to time Kafka can start the process of balancing the leaders, so in a normal situation there will not be such that some broker is overloaded with requests, and some is underloaded.
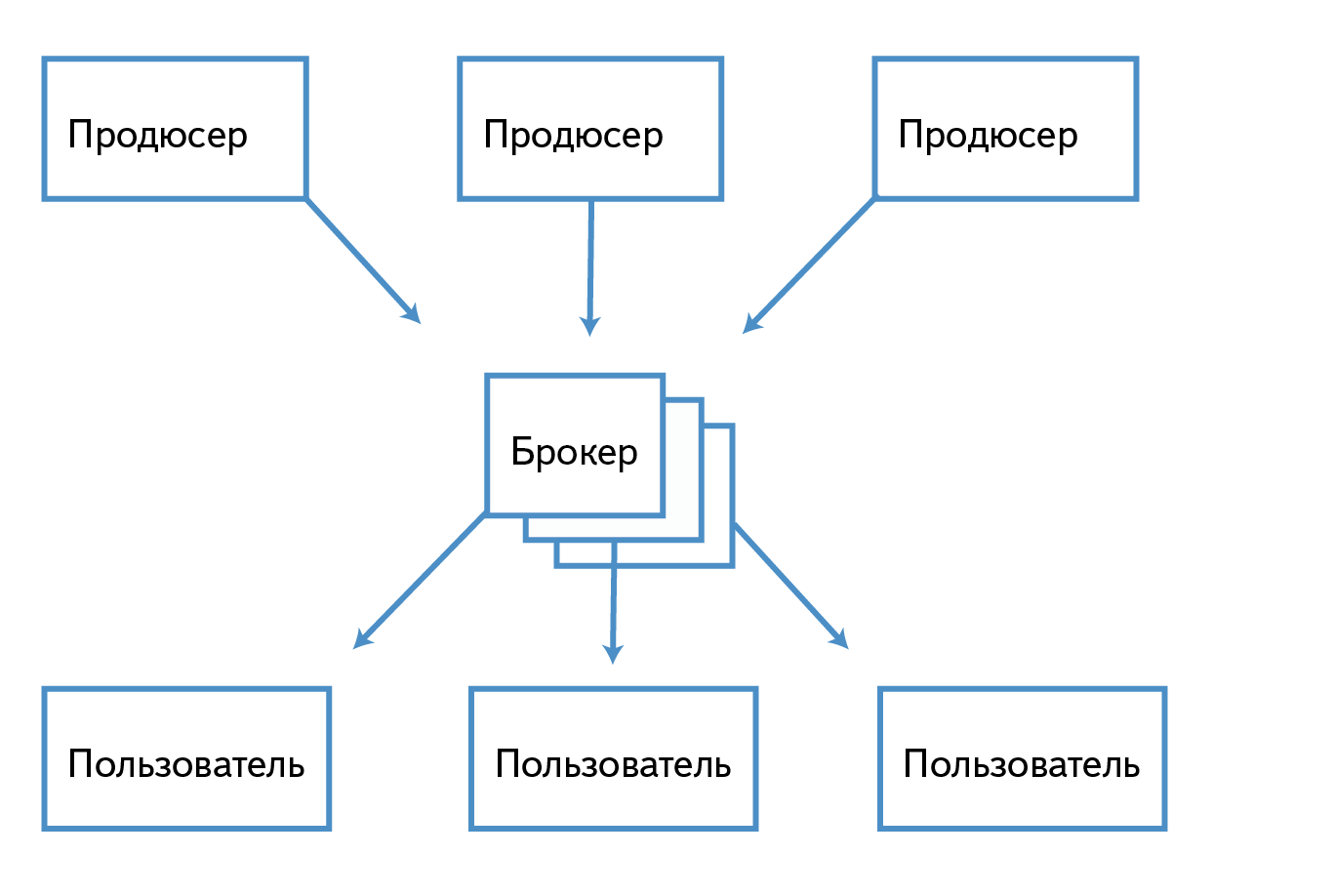
Writing to a Kafka cluster is performed by an entity called Producer, and reading by a Consumer.
A topic is a queue of similar messages. For example, if we write access logs of web servers to Kafka, then one can place nginx log entries in one topic, and apache logs in another topic. For each topic, Kafka stores a partitioned log that looks like this:
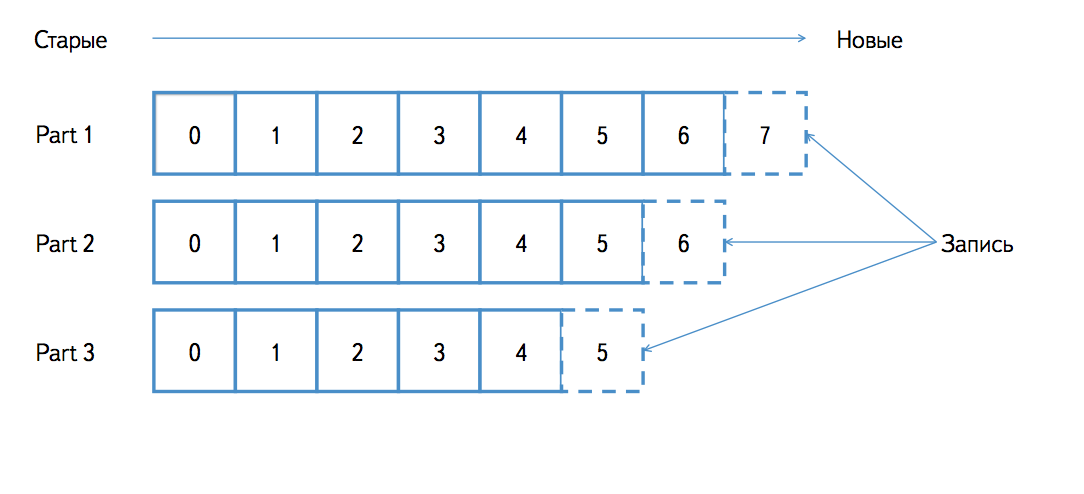
Each partition is an ordered sequence of messages, the order of the elements in which does not change; when a new message arrives, it is added to the end. Each message in the queue has a unique identifier (offset in terms of Kafka). Messages are numbered in order (1, 2, 3, ...).
Periodically, Kafka itself deletes old messages. This is a very cheap operation, since physically the partition on the disk is represented by a set of segment files. Each segment contains a continuous part of the sequence. For example, there may be segments with messages that have identifiers 1, 2, 3, and 4, 5, 6, but there cannot be segments with messages that have identifiers 1, 3, 4, and 2, 5, 6. When deleting old messages, it is simply deleted oldest segment file.
There are different semantics for message delivery: at most once — no more than one message will be delivered, at least once — at least one message will be delivered, exactly once — exactly one message will be delivered. Kafka provides at least once semantics for delivery. Duplication of messages can occur both during writing and reading. The standard Kafka producer in case of problems (disconnection before receiving the answer, time-out on sending, etc.) will re-send the message, which in many cases will lead to the appearance of duplicates. When reading messages, there can also be duplication if the fixation of message identifiers occurs after data processing and an error occurs between these two events. But in the case of reading, the situation is simpler, since the reader completely controls the process and can simultaneously record the completion of data processing and identifiers (for example, do it in a single transaction in the case of writing to the database).
Logbroker:
Initially, we made the Logbroker service fully API compatible with the old Archive, so our customers did not notice any difference when moving.
The old API had the following methods for writing:
This API almost provides the exactly-once-semantics of data delivery. How it looks on the side of Kafka.
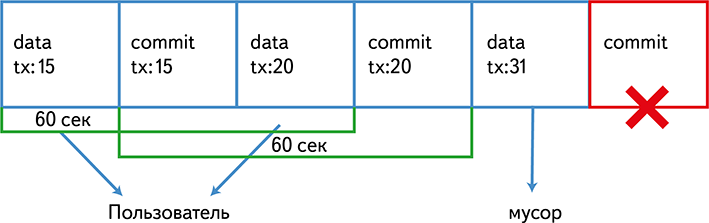
Upon request / store, we save a piece of data to a local file in temporary storage. On the / commit_request request, we write this file to Kafka, and the transaction_id is assigned to the file. On the / commit request, we write a special small commit message to Kafka that says that the file with the given transaction_id is written.
Consumer reads this stream from Kafka with a window of 60 seconds. All messages for transaction_id for which a special commit message was found, we give to the user, skip the rest.
The client's record timeout is 30 seconds, so the probability that the client recorded and sent a commit message, but then Consumer missed this message, is zero. Since the commit message is small, the probability of hanging on its record is close to zero.
After a successful launch, we wanted to make a realtime streaming delivery with strict exactly-once semantics.
Terminology of the new (rt) protocol:
The client connects to Logbroker once for each sourceId and sends data in small chunks. Logbroker writes in the message for Kafka sourceId and seqno. Moreover, each sourceId is always guaranteed to be written into the same Kafka partition.
If, for some reason, the connection is broken, the client re-creates it (possibly with another host), while Logbroker reads the partition related to the given sourceId and determines which seqno was recorded last. If chunks come from the client with seqno <= recorded, they are skipped.

Due to the reading of a partition, a session for writing data can create a tangible time, in our case, up to 10 seconds. Since this is an infrequent operation, this is not affected by the delay in delivery. We carried out read / write delivery cycle measurements: 88% of chunks from creation to reading by the consumer fit in one second, 99% - in five seconds.
We did not use the mirror from the Kafka distribution and wrote our own. The main differences:
Physically, Logbroker and Kafka processes run on the same machines. The mirroring process only works with partitions whose replicas are leaders on this machine. If the leaders on the machine have changed, then the mirroring process automatically determines this and starts to mirror other partitions.
How exactly do we determine what and where to mirror?
Suppose we have two Kafka clusters in data centers named dc1 and dc2. When the data gets into dc1, we write them to topics with the prefix dc1. For example, dc1.log1. Data in dc2 is written to topics with the prefix dc2. By prefixes, we determine which topics were originally written in this data center, and it is them that we mirror in another data center.
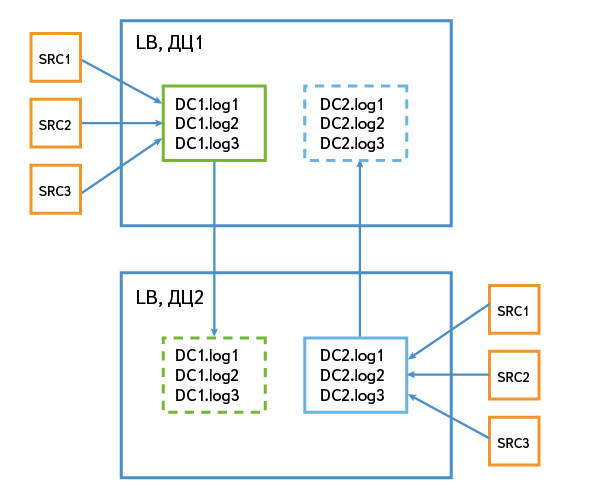
In the scheme of mirroring may be options that differ in nuances. For example, if Logbroker is in a data center with several large consumers, then it makes sense to mirror all topics from all data centers here. If Logbroker is in a data center without large consumers, it can act as a local data collector of this data center, and then send data to large installations of Logbroker.
The data mirrors the partition into the partition. During mirroring, we retain two numbers for each partition every 60 seconds: the offset of the entry in the original partition and the offset of the entry in the mirrored partition. If during the recording fails, we read the saved state and the actual sizes in the records of the original and mirrored partition, and from these numbers we determine exactly where to read the original partition.
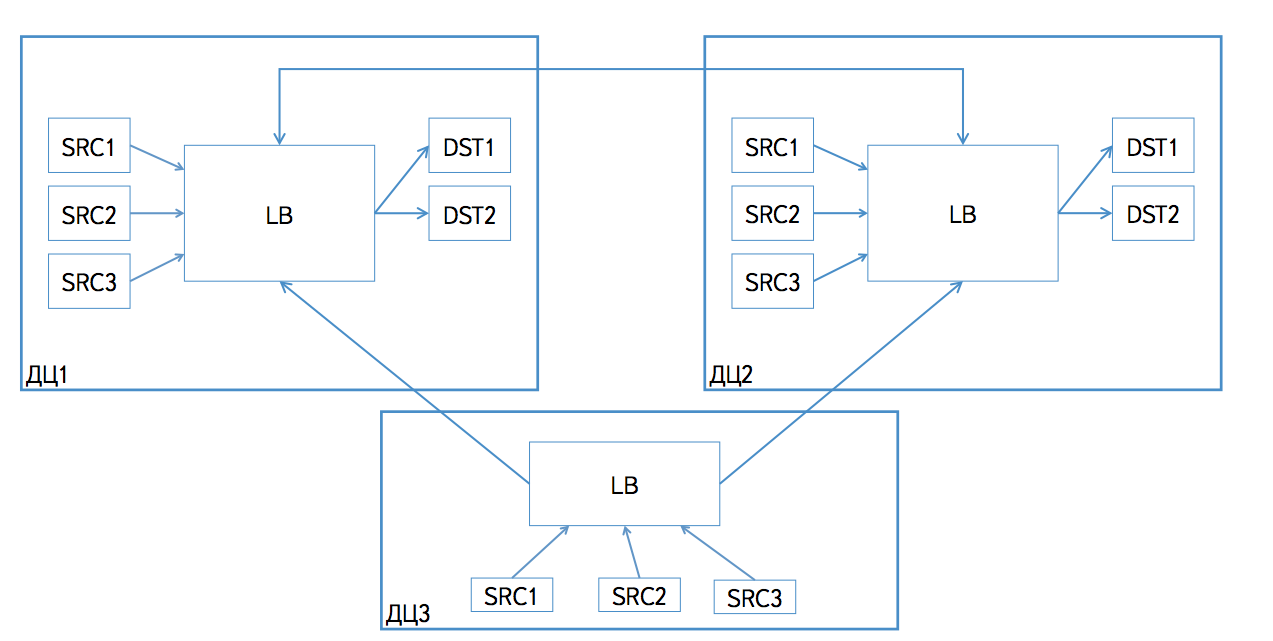
The data sources know nothing about the topology of the Logbroker installation. Logbroker itself sends the source record to the desired node. If the source is located in the data center, where there is an installation of Logbroker, then the data will be recorded into it, and the data will be transferred to other data centers using mirroring.
There are several scenarios for retrieving data from Logbroker. First, it has a division according to the type of delivery: push or pull. That is, Logbroker can send data to consumers (push-delivery), or the consumer can read the data via the http-protocol (pull-delivery). In both cases, we support two data acquisition scenarios.
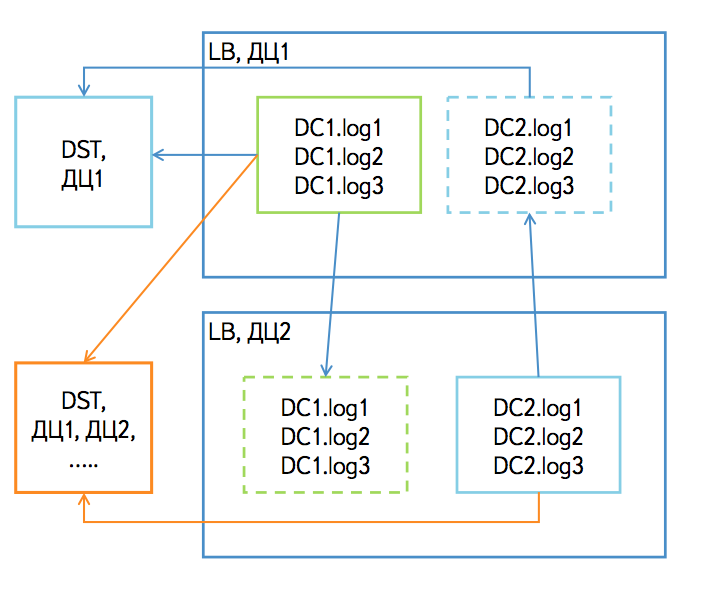
If the consumer is completely in the same data center with one of the Logbroker clusters, then he reads all the topics.
If a consumer is located in a data center where Logbroker is not represented, or if a consumer is spread over several data centers, then he reads from each data center only topics with the prefix of the data center. For example, if we read from a cluster in the dc1 data center, then we only read topics with the prefix dc1.
At first glance, it seems that you can read all topics from one data center, and if you turn it off, switch to reading the same topics in another data center. In fact, it is not. The fact is that messages in the partitions with the same name on different Kafka clusters in different data centers will have different offsets. This is due to the fact that the clusters could be started at different times and the start of mirroring was performed at different times. Our mirror provides only the immutability of the order of messages. The reader from Logbroker operates with partitions offsets, and since they will be different in another data center, the reader will either receive duplicates or will receive less data when switching.
In fact, in many cases, such a read switch will be useless. For example, we read a dc1 topic in the data center with the dc1 prefix. Suddenly the dc1 data center fell, and we want to switch to dc2 to continue reading the topic with the dc1 prefix. But since the dc1 data center has fallen, the topic with this prefix is not being written and there will simply be no new data in the dc2 data center.
Logbroker greatly simplifies the data delivery scheme. In his absence, would have to make a complex client who could send data to several places at once. A complex customer would have to constantly update to fix bugs and add support for new consumers. We now have a very simple lightweight client written in C. This client is very rarely updated. For example, some of our sources still have the old builds of 2012, which previously worked with the Archive, and are now working with Logbroker.
Centralized delivery also significantly saves inter-center traffic:
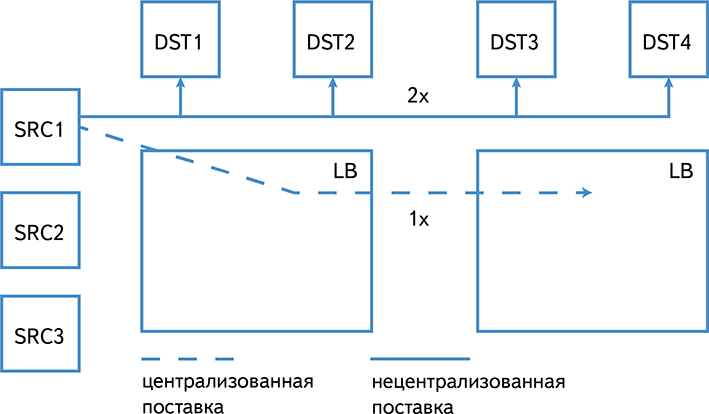
In the event of failures on receiving clusters, we can quickly and efficiently extract the missing Logbroker data. Doing the same operation on the sources themselves would be significantly more difficult.
Now Logbroker is used to deliver logs from servers. The total amount of incoming traffic an average of 60 terabytes per day. Outgoing - 3-4 times more (depending on the specific data center). Log consumers are mainly Statistics and Search clusters. There are also a number of smaller consumers who receive a small stream of only the logs they need.
Now we are working on the implementation of Logbroker as a transport bus within the company for pumping not only logs, but also binary data.
In the development process, we encountered difficulties mainly due to the dampness of Kafka. In particular, the client code turned out to be very raw. A high-level library for writing and reading data could stick for a while and also block the process. Initially, we started with this code, but then, during the development process, we wrote our asynchronous client for Kafka. Now we are thinking about the design of this client in the form of opensource library.
In contrast to the client, the server part of Kafka is written very well and is used by us almost without changes. We use small patches that we try to send to developers from time to time.
One of the key components of Statistics is Logbroker, a distributed multi-directory solution for collecting and supplying data. The key features of the system are the ability to experience the disconnection of the data center, support for the semantics exactly once on the delivery of messages and support for real-time flows (seconds of delay from the occurrence of an event at the source to the reception at the receiver).
At the core of the system is Apache Kafka . Using the API, Logbroker isolates the user from Apache Kafka's raw threads, implements disaster recovery processes (including exactly once semantics) and service processes (inter-center replication, data distribution to the calculation clusters: YT, YaMR ...).
Story
Initially, to calculate reports, Ya.Statistics used Oracle. Data was downloaded from servers and recorded in Oracle. Once a day, reports were built using SQL queries.
Data volumes grew 2.5 times a year, so by 2010 such a scheme began to fail. The database did not cope with the load, and the calculation of reports slowed down. Calculation of reports from the database was transferred to YaMR, and as a long-term storage of logs they began to use a self-written solution, which was a distributed storage, where each piece of data appeared as a separate file. The solution was simply called Archive.
')
The archive had many features of the current Logbroker. In particular, he was able to receive data and distribute data to various YaMR clusters and external users. The Archive also stored metadata and made it possible to receive samples by various parameters (time, file name, server name, log type ...). In the event of a failure or loss of data on YaMR, it was possible to recover an arbitrary piece of data from the Archive.
We still went around the servers, downloaded the data and saved them to the Archive. In early 2011, this approach began to slip. In addition to the obvious security problem (statistics servers have access to all Yandex servers), he had problems with scalability and performance. As a result, a client was written, which was installed on servers and shipped logs directly to the Archive. The client (the internal product name of the push-client) is a lightweight C program that does not use any external dependencies and supports various Linux, FreeBSD, and even Windows variants. In the course of work, the client monitors the update of data files (logs) and sends new data via the http (s) protocol.
The archive had some flaws. He didn’t worry about disconnecting the data center, because of the file organization he had limited opportunities for scaling and didn’t fundamentally support the receipt / return of data in real time. Before sending the data to the archive, it was necessary to accumulate a buffer at intervals of at least a minute, while our consumers wanted second delivery delays.
It was decided to write a new archive, based on one of the available NoSQL solutions for fault-tolerant storage.
We considered HBase , Cassandra , Elliptics . HBase was not suitable because of problems with inter-center replication. Cassandra and Elliptics did not match due to a significant performance drop during the defragmentation of the base and when adding new machines to the cluster. In principle, the restrictions on adding new machines could still be experienced, since this is an infrequent operation, but the restriction on defragmentation turned out to be significant: every day a daily data set is recorded in the archive, while the old data is deleted N days ago, that is, defragmentation would have to perform constantly.
In the end, we decided to revise our delivery architecture. Instead of a long-term repository - the Archive with a complete set of metadata and the ability to build all sorts of slices, we decided to write easy and fast short-term repository with minimal functionality for building samples.
The basis for the implementation took Apache Kafka.
Technical details
Kafka implements a persistent message queue. Persistence means that data sent to Kafka continues to exist after restarting processes or machines. Each stream of the same type of messages in Kafka is represented by an entity called a topic . The topic is divided into partitions , which ensures parallel writing and reading of the topic. Kafka scales very easily: with an increase in the volume of threads, you can increase the number of topic partitions and the number of machines servicing them.
A partition can exist in several replicas and is serviced by different nodes ( brokers in Kafka terms). Replicas are of two types: leader and follower. The leader replica accepts all requests for writing and reading data, the replica follower accepts and stores the stream from the replica leader. Kafka guarantees the identity of all replicas bytes to bytes. If one of the brokers becomes unavailable, then all the replica leaders will automatically move to other brokers and the partition can still be written and read. When raising a broker, all the replicas that he served automatically become followers and catch the accumulated backlog from the replica leaders. From time to time Kafka can start the process of balancing the leaders, so in a normal situation there will not be such that some broker is overloaded with requests, and some is underloaded.
Writing to a Kafka cluster is performed by an entity called Producer, and reading by a Consumer.
A topic is a queue of similar messages. For example, if we write access logs of web servers to Kafka, then one can place nginx log entries in one topic, and apache logs in another topic. For each topic, Kafka stores a partitioned log that looks like this:
Each partition is an ordered sequence of messages, the order of the elements in which does not change; when a new message arrives, it is added to the end. Each message in the queue has a unique identifier (offset in terms of Kafka). Messages are numbered in order (1, 2, 3, ...).
Periodically, Kafka itself deletes old messages. This is a very cheap operation, since physically the partition on the disk is represented by a set of segment files. Each segment contains a continuous part of the sequence. For example, there may be segments with messages that have identifiers 1, 2, 3, and 4, 5, 6, but there cannot be segments with messages that have identifiers 1, 3, 4, and 2, 5, 6. When deleting old messages, it is simply deleted oldest segment file.
There are different semantics for message delivery: at most once — no more than one message will be delivered, at least once — at least one message will be delivered, exactly once — exactly one message will be delivered. Kafka provides at least once semantics for delivery. Duplication of messages can occur both during writing and reading. The standard Kafka producer in case of problems (disconnection before receiving the answer, time-out on sending, etc.) will re-send the message, which in many cases will lead to the appearance of duplicates. When reading messages, there can also be duplication if the fixation of message identifiers occurs after data processing and an error occurs between these two events. But in the case of reading, the situation is simpler, since the reader completely controls the process and can simultaneously record the completion of data processing and identifiers (for example, do it in a single transaction in the case of writing to the database).
Logbroker communication with Kafka
Logbroker:
- Isolates the Kafka internal kitchen from the user:
- turns the data stream from the client into Kafka messages;
- adds to the messages all the necessary meta-information (server name, file name, type of log ...);
- selects the most appropriate topic name.
- Provides http API for writing and reading data.
- Provides a service for automatically uploading new data to YT and YaMR clusters.
- Provides inter-centric replication of data between Kafka clusters.
- Provides infrastructure around Kafka:
- configuration service (watchdog, shooting disks, rebalancing disks, forced removal of segments);
- metrics, graphite integration (http://graphite.wikidot.com/) ;
- scripts to monitor.
Initially, we made the Logbroker service fully API compatible with the old Archive, so our customers did not notice any difference when moving.
The old API had the following methods for writing:
- / store (data record),
- / commit_request (transaction commit request),
- / commit (commit).
This API almost provides the exactly-once-semantics of data delivery. How it looks on the side of Kafka.
Upon request / store, we save a piece of data to a local file in temporary storage. On the / commit_request request, we write this file to Kafka, and the transaction_id is assigned to the file. On the / commit request, we write a special small commit message to Kafka that says that the file with the given transaction_id is written.
Consumer reads this stream from Kafka with a window of 60 seconds. All messages for transaction_id for which a special commit message was found, we give to the user, skip the rest.
The client's record timeout is 30 seconds, so the probability that the client recorded and sent a commit message, but then Consumer missed this message, is zero. Since the commit message is small, the probability of hanging on its record is close to zero.
After a successful launch, we wanted to make a realtime streaming delivery with strict exactly-once semantics.
Terminology of the new (rt) protocol:
- sourceId - unique source identifier (for example, it can correspond to a file on a specific host);
- seqno - unique (within the sourceId) identifier of the chunk, constantly increasing (for example, it can correspond to the offset in the file).
The client connects to Logbroker once for each sourceId and sends data in small chunks. Logbroker writes in the message for Kafka sourceId and seqno. Moreover, each sourceId is always guaranteed to be written into the same Kafka partition.
If, for some reason, the connection is broken, the client re-creates it (possibly with another host), while Logbroker reads the partition related to the given sourceId and determines which seqno was recorded last. If chunks come from the client with seqno <= recorded, they are skipped.
Due to the reading of a partition, a session for writing data can create a tangible time, in our case, up to 10 seconds. Since this is an infrequent operation, this is not affected by the delay in delivery. We carried out read / write delivery cycle measurements: 88% of chunks from creation to reading by the consumer fit in one second, 99% - in five seconds.
How inter-center mirroring works
We did not use the mirror from the Kafka distribution and wrote our own. The main differences:
- a large number of read and send buffers are not created, as a result, we consume significantly less memory and can work with a large number of partitions (in our production now there can be up to 10,000);
- the partition is guaranteed to be mirrored one to one, and the messages are not mixed;
- Mirroring guarantees exactly-once-semantics: no duplicates or loss of messages.
Physically, Logbroker and Kafka processes run on the same machines. The mirroring process only works with partitions whose replicas are leaders on this machine. If the leaders on the machine have changed, then the mirroring process automatically determines this and starts to mirror other partitions.
How exactly do we determine what and where to mirror?
Suppose we have two Kafka clusters in data centers named dc1 and dc2. When the data gets into dc1, we write them to topics with the prefix dc1. For example, dc1.log1. Data in dc2 is written to topics with the prefix dc2. By prefixes, we determine which topics were originally written in this data center, and it is them that we mirror in another data center.
In the scheme of mirroring may be options that differ in nuances. For example, if Logbroker is in a data center with several large consumers, then it makes sense to mirror all topics from all data centers here. If Logbroker is in a data center without large consumers, it can act as a local data collector of this data center, and then send data to large installations of Logbroker.
How do we provide exactly-once-semantics when mirroring?
The data mirrors the partition into the partition. During mirroring, we retain two numbers for each partition every 60 seconds: the offset of the entry in the original partition and the offset of the entry in the mirrored partition. If during the recording fails, we read the saved state and the actual sizes in the records of the original and mirrored partition, and from these numbers we determine exactly where to read the original partition.
Inter-data center delivery architecture
The data sources know nothing about the topology of the Logbroker installation. Logbroker itself sends the source record to the desired node. If the source is located in the data center, where there is an installation of Logbroker, then the data will be recorded into it, and the data will be transferred to other data centers using mirroring.
There are several scenarios for retrieving data from Logbroker. First, it has a division according to the type of delivery: push or pull. That is, Logbroker can send data to consumers (push-delivery), or the consumer can read the data via the http-protocol (pull-delivery). In both cases, we support two data acquisition scenarios.
If the consumer is completely in the same data center with one of the Logbroker clusters, then he reads all the topics.
If a consumer is located in a data center where Logbroker is not represented, or if a consumer is spread over several data centers, then he reads from each data center only topics with the prefix of the data center. For example, if we read from a cluster in the dc1 data center, then we only read topics with the prefix dc1.
At first glance, it seems that you can read all topics from one data center, and if you turn it off, switch to reading the same topics in another data center. In fact, it is not. The fact is that messages in the partitions with the same name on different Kafka clusters in different data centers will have different offsets. This is due to the fact that the clusters could be started at different times and the start of mirroring was performed at different times. Our mirror provides only the immutability of the order of messages. The reader from Logbroker operates with partitions offsets, and since they will be different in another data center, the reader will either receive duplicates or will receive less data when switching.
In fact, in many cases, such a read switch will be useless. For example, we read a dc1 topic in the data center with the dc1 prefix. Suddenly the dc1 data center fell, and we want to switch to dc2 to continue reading the topic with the dc1 prefix. But since the dc1 data center has fallen, the topic with this prefix is not being written and there will simply be no new data in the dc2 data center.
Why do we need such an entity as Logbroker? Why it is impossible to immediately send data from sources to all consumers?
Logbroker greatly simplifies the data delivery scheme. In his absence, would have to make a complex client who could send data to several places at once. A complex customer would have to constantly update to fix bugs and add support for new consumers. We now have a very simple lightweight client written in C. This client is very rarely updated. For example, some of our sources still have the old builds of 2012, which previously worked with the Archive, and are now working with Logbroker.
Centralized delivery also significantly saves inter-center traffic:
In the event of failures on receiving clusters, we can quickly and efficiently extract the missing Logbroker data. Doing the same operation on the sources themselves would be significantly more difficult.
Where is Logbroker used in Yandex now?
Now Logbroker is used to deliver logs from servers. The total amount of incoming traffic an average of 60 terabytes per day. Outgoing - 3-4 times more (depending on the specific data center). Log consumers are mainly Statistics and Search clusters. There are also a number of smaller consumers who receive a small stream of only the logs they need.
Now we are working on the implementation of Logbroker as a transport bus within the company for pumping not only logs, but also binary data.
In the development process, we encountered difficulties mainly due to the dampness of Kafka. In particular, the client code turned out to be very raw. A high-level library for writing and reading data could stick for a while and also block the process. Initially, we started with this code, but then, during the development process, we wrote our asynchronous client for Kafka. Now we are thinking about the design of this client in the form of opensource library.
In contrast to the client, the server part of Kafka is written very well and is used by us almost without changes. We use small patches that we try to send to developers from time to time.
Source: https://habr.com/ru/post/239823/
All Articles