On the road to professional use of modern OCR. Understanding FineReader
 I develop the technologies used in ABBYY's text recognition products. The most famous product (or rather, the product family) using these technologies is FineReader.
I develop the technologies used in ABBYY's text recognition products. The most famous product (or rather, the product family) using these technologies is FineReader.What do I mean by "technology"
Sometimes all technological modules (parts of the program that are invisible to the user) together are called “recognition engine” (“engine” - from the English “Engine”), which is not quite right - they perform not only character recognition, but also a bunch of other actions, more about which below .
What does the program FineReader?
Now, any of the desktop FineReader options can do everything independently, from receiving an image from a scanner, camera or from a finished file to outputting the processing result to a file or to a specified application, so that the person remains behind the scenes. The program itself “recognizes” everything that is needed (in quotes, since the program determines the location of the text, tables, pictures, OCRit detected areas with the displayed text, forms a document that saves in the desired format with the specified settings)
A couple of screenshots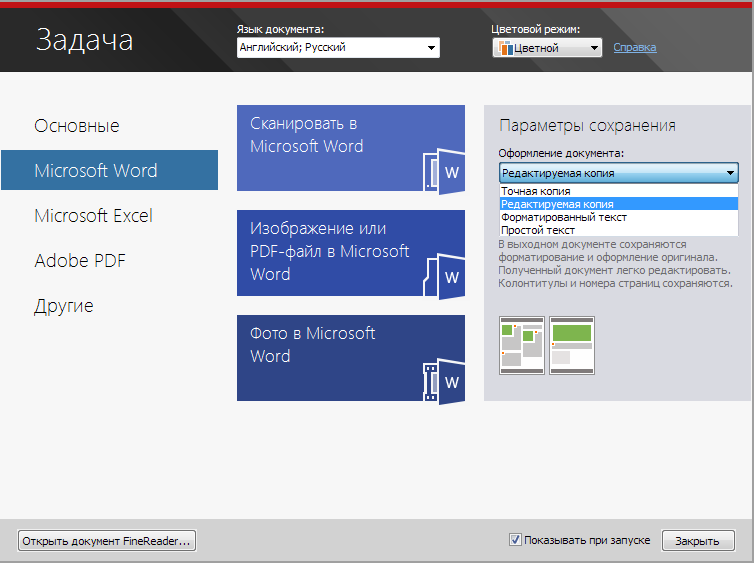
')
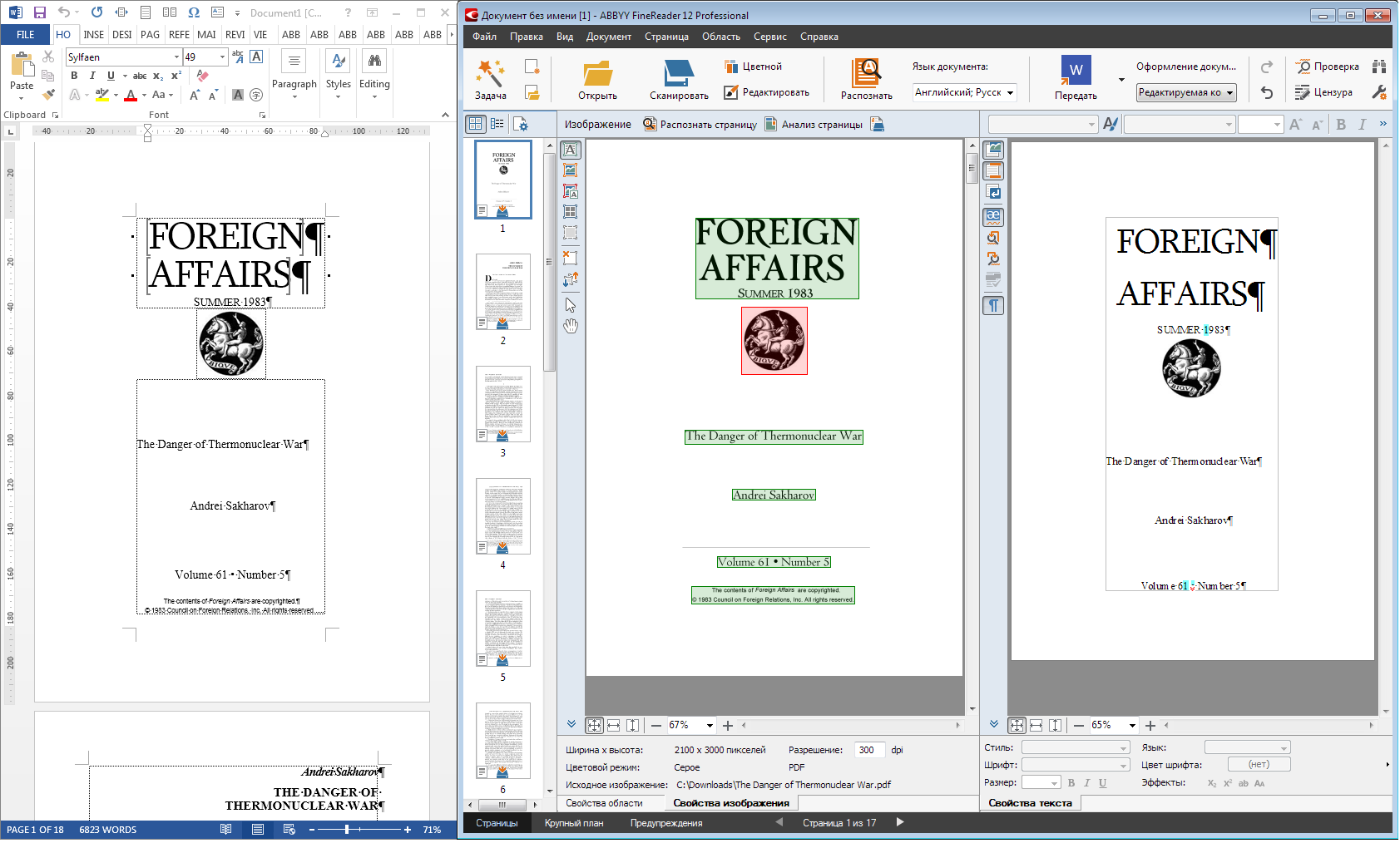
')
What does the user do?
 Usually almost nothing - first orders the work, and then takes it. Sometimes the user is not satisfied with something as a result of automatic processing, but in such cases, the typical user humbly thinks "No luck ..."
Usually almost nothing - first orders the work, and then takes it. Sometimes the user is not satisfied with something as a result of automatic processing, but in such cases, the typical user humbly thinks "No luck ..."Unfortunately, not everyone knows that besides the “Task” window, which is also shown at startup, there are other ways to manage the program. They help with the help of human intelligence to overcome the shortcomings and limitations (sometimes fundamental) of the artificial intelligence program.
How to learn to do this? There are several ways that can be combined if necessary:
- read the “ Quick Start Guide ”, “ Complete User Guide ”, online help to the program - there are of course many letters there, but almost all of them are written in the case.
- read to the end of this article. There are much fewer letters in it, besides, the author promises to save the reader from the fear of the program and to awaken his interest in experiments,
- experimenting with the program (the only item you can't do without) - even the demo version allows you to try everything you need in actual operation.
Where to begin?
You need to start with the habit of saving the result of the work not only as a document in the target format, but also as a FineReader document containing the results of the work done. This allows you to work with a large document not for several hours at a time in one approach, but when it is convenient and as many times as you like, return to the recognized and read document for experimenting with storage settings and so on. All actions with the FineReader document are collected in the File menu.
Pictures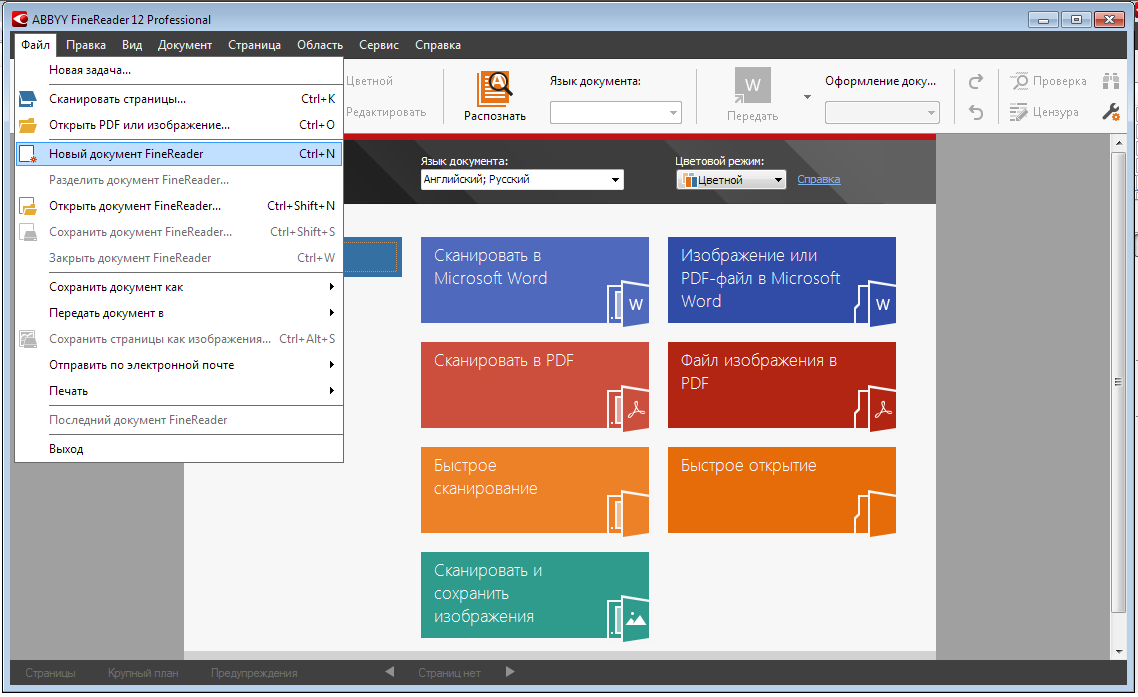
There is nothing more practical than a good theory, or what “recognition” consists of
 Looking at the laconic names of tasks, for example, “Scan to PDF”, it is difficult to imagine how much everything happens in the interval between “Scan” and “PDF” (that is, in the place of one letter “in”). Let's see how much.
Looking at the laconic names of tasks, for example, “Scan to PDF”, it is difficult to imagine how much everything happens in the interval between “Scan” and “PDF” (that is, in the place of one letter “in”). Let's see how much.The task of “converting documents from a raster representation into an editable one” (not just “recognition”) includes the following main steps:
- Getting the original single or multi-page image (from a scanner, camera or as a file), converting it into a special internal representation (to simplify and speed up further operations). In any case, the image processing subsystem is used, which understands a variety of external formats for both reading and writing.
- Image preparation (correction of different types of distortions, separation of book turns into separate pages - all this is turned on / off in settings) is also performed by the image processing subsystem . Learn about some elements of this process a little more can be in this post .
- Segmentation, or “page layout analysis,” when it is decided where and what is needed and not needed to be recognized, is performed by the Analysis subsystem .
- Recognition (finally) - performs the Recognizer subsystem (surprise!), It generates lines consisting of fragments (future words), consisting of characters without formatting (there is not even a division into paragraphs, there are only lines). Some amount of information about the details of the work of the recognizer has already been written on Habré by my colleague. And if you are really interested in technical details, then it would not be superfluous to mention that the recognizer in its work uses, among other things, the morphology subsystem . In this post, you can learn how to correctly use the mentioned subsystem of morphology and the Recognition with Learning mechanism , which makes it possible to better recognize decorative fonts or symbols that FineReader does not know anything about (sometimes it happens).
- Synthesis of a document (it has two stages - a page, called immediately after the recognition of a separate page, and a document one that works after all the pages are processed) - this is where the structure and all characteristics of the recognized text, except for character codes, generating a holistic document, are executed is performed by Synthesis . In this post, you can try to realize the difficult fate of those who write those hundreds of hundreds of heuristics that allow you to make the recognized document as close as possible to the original.
- Viewing and editing images of pages, structure of areas, recognition results - performs the shell of the program and the subsystem Editor in its composition (FineReader.exe executable file is a shell). In the shell, you can see and edit a significant part of the information generated during processing (starting with the block structure). Of course, not all information available for user editing is accessible by various subsystems — primarily because displaying all the entities found by automatics, their properties and interrelationships would cause an insane complication of the user interface.
- Saving the finished document to numerous external formats is performed by the Export subsystem (of which I and my colleagues are engaged in the development).
Subsystems operating before export do not know the output format / saving option. Therefore, when a document is synthesized, several of its representations are created at once, which may be required by all export formats / options, and the shell can show them in the same way as the export results will be displayed in the target applications. This creates a lot of difficulties in the development, because too close interconnection of the designated subsystems leads to the complication of the division of responsibility in the "border areas" when the bug / feature lies somewhere between the subsystems. But we are still coping :)
Why so many modules (subsystems)?
For a start, it should be noted that only the main ones are listed, and not all. The scanning subsystem, for example, was not written for a day or two, but for many months, and even possibly years. However, let us return to the question indicated above.
First, the project “Recognition Technologies” and many complex products based on it have been developed for several decades by large groups of people - their work simply needs to be divided organizationally and technologically into parts in order to develop each more or less independently - of course, having described the interfaces in detail and the rules of interaction between the modules so that the output of the previous module in the chain is connected to the input of the next one.
Secondly, some products can use not all of the listed processing steps (and the subsystems implementing them), but only some. For example, the Recognizer module has its own submodules for processing printed and handwritten text, and its “printed” submodule also has its own sub - modules for processing languages with complex writing. A similar situation is with the barcode recognition module and the codecs of some image formats - some products do without them.
What is the result and why does the user need?
 Not being puzzled in time with this issue, one can remain dissatisfied with even the completely correct OCR result in the narrow sense - when all the letters are found and correctly recognized, but in general, as a result, something saddens.
Not being puzzled in time with this issue, one can remain dissatisfied with even the completely correct OCR result in the narrow sense - when all the letters are found and correctly recognized, but in general, as a result, something saddens.I will list some of the popular FineReader usage scenarios with features of each script.
Converting an archive of image documents into electronic form, with the maximum preservation of the appearance of pages, but adding the ability to search and copy small fragments of text.
This script usually uses saving the processed document to PDF with a visible image of the page (not always completely original, but as close as possible to it) and adding “invisible” recognized text that can be searched, selected and copied in PDF viewers. In our jargon, this mode of saving to PDF is called “Text under the image”, it is most popular, but this is only one of 4 modes of saving to PDF (for the rest I’ll dwell more on the article on saving). Connoisseurs of the DjVu format can also use the same save mode.
An important advantage of the “Text under Image” mode is that it requires minimal knowledge about the structure of the text to be saved, tying the characters to the desired places of the resulting page simply by coordinates on the original image. Therefore, it does not matter if the tables were not automatically detected correctly in the original (lounging on a bunch of text areas), or the text was a little illogical to stand out in text areas - in the resulting PDF there is everything or almost everything, if only the characters are correctly recognized and gathered into words.
Creating a document in the format of any of the popular text editors (Microsoft Word or OpenOffice / LibreOffice Writer), more or less similar to the original - for later editing and / or reusing significant fragments in new documents.
When saving to RTF and DOCX (for Word) and ODT (for Writer) formats, 4 saving modes are supported, differing in the balance “precise saving of the form <-> ease of editing and copying content”. I will write more about their differences, but the general requirement for a rational type of processing result is the rationality of marking all elements of a document in FR - areas and their properties.
Creating an e-book based on the scanned paper book.
In many ways similar to the previous one, but due to the simplified model of the document in e-book formats, the limitations of their editing and display tools after FineReader, sometimes it requires more attention to some trifles.
And why do I know that now?
As you probably already guessed, the understanding of these logical, but still not obvious moments would allow users to bring the result of FineReader to the ideal (from the point of view of the user) state with minimal labor costs. In the next part of the post, I will give specific recommendations for solving typical user problems, but for now let's get back to work.
Source: https://habr.com/ru/post/239531/
All Articles