Analysis of existing approaches to face recognition
 With enviable regularity on Habré appear articles telling about those or other methods of facial recognition. We decided not just to support this wonderful topic, but to lay out our internal document, which covers, if not all, but many approaches to face recognition, their strengths and weaknesses. It was compiled by Andrei Gusak, our engineer, for young employees of the machine vision department, for educational, so to speak, purposes. Today we offer it to everyone. At the end of the article there is an impressive list of references for the most inquisitive.
With enviable regularity on Habré appear articles telling about those or other methods of facial recognition. We decided not just to support this wonderful topic, but to lay out our internal document, which covers, if not all, but many approaches to face recognition, their strengths and weaknesses. It was compiled by Andrei Gusak, our engineer, for young employees of the machine vision department, for educational, so to speak, purposes. Today we offer it to everyone. At the end of the article there is an impressive list of references for the most inquisitive. So, let's begin.
Despite the large variety of algorithms presented, one can identify the general structure of the facial recognition process:
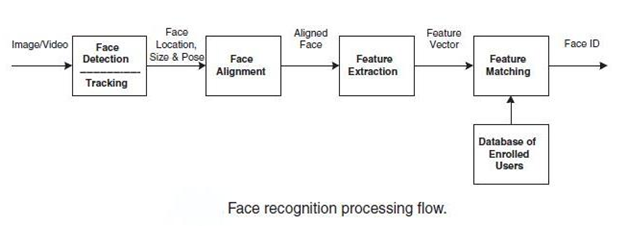
The overall processing of facial image recognition
')
At the first stage, the face is detected and localized in the image. At the stage of recognition, the image of the face is aligned (geometric and brightness), the calculation of the signs and the recognition itself is the comparison of the calculated signs with the benchmarks embedded in the database. The main difference of all the algorithms presented will be the calculation of signs and the comparison of their aggregates among themselves.
1. The method of flexible comparison on graphs (Elastic graph matching) [13].
The essence of the method is reduced to the elastic juxtaposition of graphs describing images of faces. Persons are represented as graphs with weighted vertices and edges. At the recognition stage, one of the graphs - the reference one - remains unchanged, while the other is deformed in order to best fit the first one. In such recognition systems, graphs can be either a rectangular grid or a structure formed by characteristic (anthropometric) points of a face.
but)

b)

An example of the structure of a graph for face recognition: a) a regular lattice b) a graph based on anthropometric points of the face.
At the vertices of the graph, the values of attributes are calculated; most often, the complex values of Gabor filters or their ordered sets — Gabor wavelets (Gabor lines) are used, which are computed locally in some local vertex region of the graph by convolving the brightness values of pixels with Gabor filters.

Set (bank, jet) filters Gabor

An example of a convolution image of the face with two Gabor filters
The edges of the graph are weighted by the distances between adjacent vertices. The difference (distance, discriminatory characteristic) between two graphs is calculated with the help of some price deformation function, which takes into account both the difference between the values of features calculated at the vertices and the degree of deformation of the edges of the graph.
A graph is deformed by displacing each of its vertices by a certain distance in certain directions relative to its original location and selecting its position such that the difference between the values of attributes (responses of Gabor filters) at the top of the deformed graph and the corresponding top of the reference graph is minimal. This operation is performed alternately for all the vertices of the graph until the smallest total difference between the signs of the deformable and reference graphs is reached. The value of the price function of deformation in such a position of the deformable graph will be a measure of the difference between the input face image and the reference graph. This “relaxation” deformation procedure should be carried out for all reference persons included in the database of the system. The result of the system recognition is the standard with the best value of the price function of deformation.

Example of deformation of a graph in the form of a regular lattice
In individual publications, 95-97% recognition efficiency is indicated, even in the presence of various emotional expressions and a change in the angle of the face to 15 degrees. However, the developers of elastic comparison systems on graphs refer to the high computational cost of this approach. For example, to compare the input face image with the 87 reference ones, it took approximately 25 seconds when working on a parallel computer with 23 transputers [15] (Note: the publication is dated 1993). In other publications on this topic, the time is either not indicated, or it is said that it is great.
Disadvantages: high computational complexity of the recognition procedure. Low manufacturability in memorizing new standards. Linear dependence of work time on the size of the database of persons.
2. Neural networks
Currently, there are about a dozen varieties of neural networks (NA). One of the most widely used options is a network built on a multi-layer perceptron, which allows you to classify the image / signal fed to the input according to the network pre-tuning / training.
Neural networks are trained on a set of training examples. The essence of learning is reduced to adjusting the weights of interneuronal connections in the process of solving an optimization problem using the gradient descent method. In the process of learning NA, the key features are automatically extracted, their importance is determined, and the relationships between them are built. It is assumed that a trained NA will be able to apply the experience gained in the learning process to unknown images at the expense of generalizing abilities.
The best results in the field of face recognition (based on the analysis of publications) were shown by the Convolutional Neural Network or the convolutional neural network (hereinafter referred to as SNS) [29-31], which is a logical development of the ideas of NA architectures like the cognitron and the neocognitron. Success is due to the possibility of taking into account the two-dimensional topology of the image, in contrast to the multilayer perceptron.
Distinctive features of the SNA are local receptor fields (provide local two-dimensional connectivity of neurons), total weights (provide detection of some features anywhere in the image) and a hierarchical organization with spatial subsampling. Thanks to these innovations, the SNA provides partial stability to scale changes, shifts, turns, angle changes and other distortions.
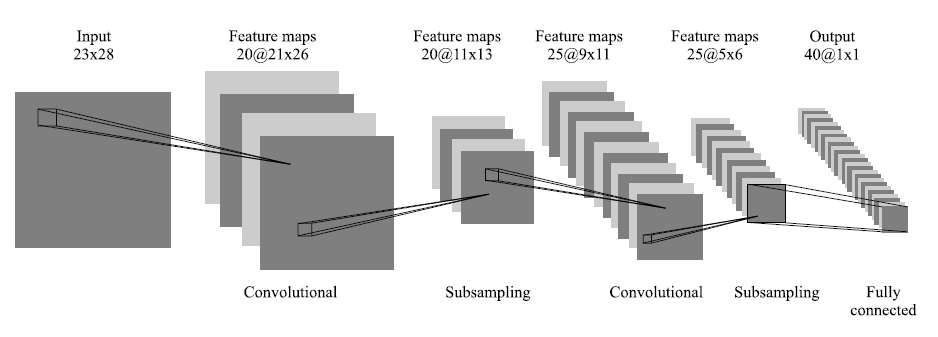
Schematic representation of the convolutional neural network architecture
Testing of the SNA on an ORL database containing images of individuals with small changes in lighting, scale, spatial turns, position, and various emotions showed 96% recognition accuracy.
The development of the SNA received in the development of DeepFace [47], which acquired
Facebook to recognize the faces of users of their social networks. All features of the architecture are closed.
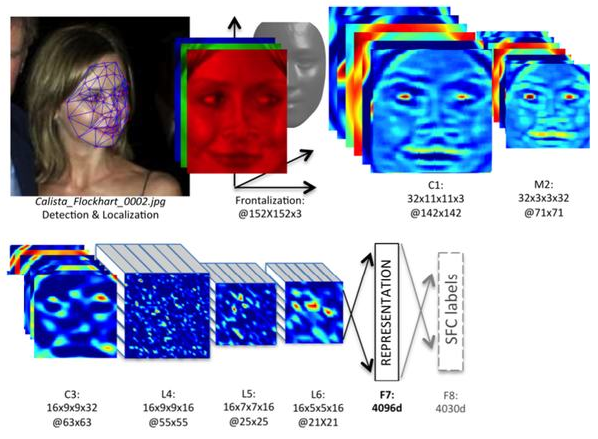
DeepFace working principle
Disadvantages of neural networks: adding a new reference person to the database requires a complete retraining of the network throughout the entire set (quite a long procedure, depending on the sample size from 1 hour to several days). Mathematical problems associated with learning: hitting the local optimum, choosing the optimal optimization step, retraining, etc. It is difficult to formalize the choice of network architecture (the number of neurons, layers, the nature of connections). Summarizing all the above, we can conclude that NA is a “black box” with difficult to interpret work results.
3. Hidden Markov models (SMM, HMM)
One of the statistical methods for face recognition are hidden Markov models (SMM) with discrete time [32–34]. The SMMs use the statistical properties of the signals and take into account their spatial characteristics directly. The elements of the model are: the set of hidden states, the set of observable states, the matrix of transition probabilities, the initial probability of states. Each has its own Markov model. When an object is recognized, Markov models generated for a given object base are checked and the maximum observed probability is searched for that the sequence of observations for a given object is generated by the corresponding model.
To date, it has not been possible to find examples of the commercial use of SMM for face recognition.
Disadvantages:
- it is necessary to select the model parameters for each database;
- The SMM does not have a distinctive ability, that is, the learning algorithm only maximizes the response of each image to its model, but does not minimize the response to other models.
4. Principal component method or principal component analysis (PCA) [11]
One of the most well-known and developed is the principal component analysis (PCA) method, based on the Karhunen-Loyev transform.
Initially, the principal component method began to be used in statistics to reduce the feature space without significant loss of information. In the problem of face recognition, it is used mainly to represent a face image with a vector of small dimension (main components), which is then compared with the reference vectors embedded in the database.
The main goal of the principal component method is to significantly reduce the dimension of the feature space in such a way that it describes as best as possible the “typical” images belonging to many individuals. Using this method, it is possible to identify various variability in a training sample of face images and describe this variability in the basis of several orthogonal vectors, which are called eigenface.
The set of eigenvectors obtained once on a training sample of face images is used to encode all other face images, which are represented by a weighted combination of these eigenvectors. Using a limited number of eigenvectors, it is possible to obtain a compressed approximation to the input face image, which can then be stored in a database as a coefficient vector that simultaneously serves as a search key in the database of persons.
The essence of the main component method is as follows. First, the entire training set of faces is transformed into one common data matrix, where each row represents one copy of the image of a person laid out in a row. All persons in the training set must be reduced to the same size and with normalized histograms.
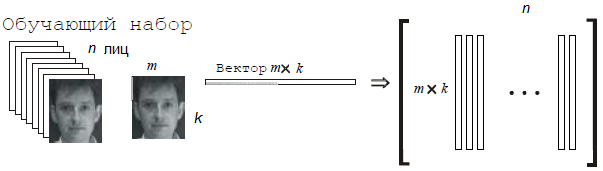
Transformations of a training set of persons into one common matrix X
Then the data is normalized and the rows are brought to the 0th mean and 1st variance, the covariance matrix is calculated. For the resulting covariance matrix, the problem of determining the eigenvalues and the corresponding eigenvectors (proper faces) is solved. Next, the eigenvectors are sorted in decreasing order of eigenvalues and only the first k vectors are left by the rule:


PCA algorithm

An example of the first ten eigenvectors (own faces) obtained on the learner set of faces
 = 0.956 *
= 0.956 *  -1.842 *
-1.842 *  +0.046
+0.046  ...
...An example of building (synthesis) of a human face using a combination of its own faces and main components
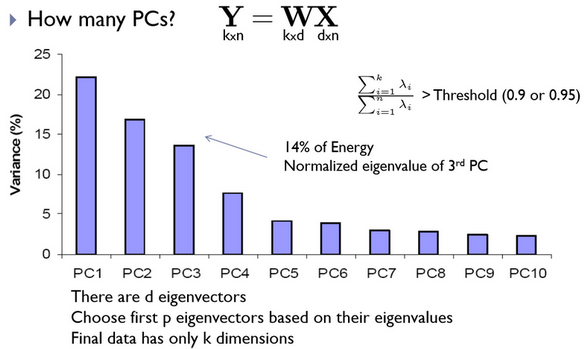
The principle of choosing the basis of the first best eigenvectors
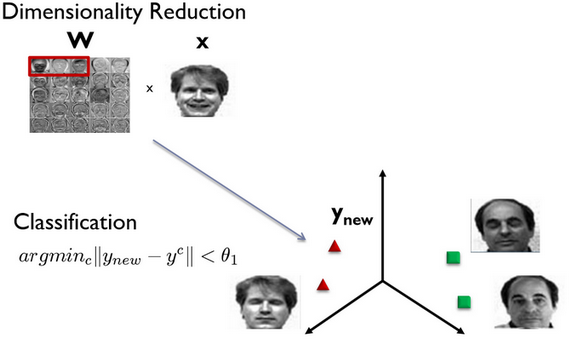
An example of mapping a face into a three-dimensional metric space, obtained from three own faces and further recognition

The method of principal components has proven itself in practical applications. However, in cases where there are significant changes in the light or facial expression on the face, the effectiveness of the method drops significantly. The thing is, the PCA chooses a subspace so as to maximally approximate the input data set, rather than discriminate between classes of individuals.
In [22], a solution to this problem was proposed using the Fisher linear discriminant (the name “Eigen-Fisher”, “Fisherface”, LDA) is found in the literature. LDA selects a linear subspace that maximizes the relationship:
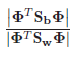
Where
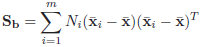
interclass scatter matrix, and

Matrix of intraclass scatter; m is the number of classes in the database.
LDA is looking for a projection of data in which classes are as linearly separable as possible (see figure below). For comparison, the PCA is looking for a data projection in which the spread across the entire database of individuals will be maximized (excluding classes). According to the results of experiments [22], under conditions of strong tank and lower shading of face images, Fisherface showed 95% efficiency compared to 53% of the Eigenface.
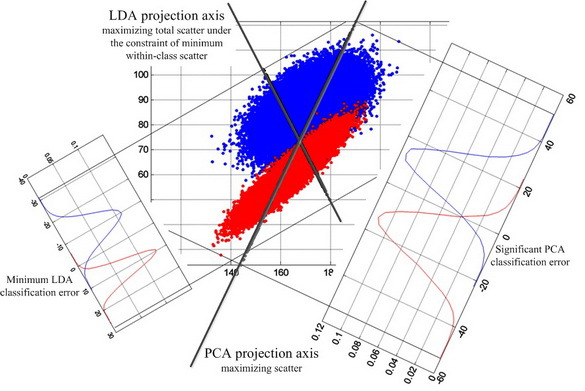
The fundamental difference in the formation of PCA and LDA projections
PCA versus LDA

5. Active Appearance Models (AAM) and Active Shape Models (ASM) ( Habra Source )
Active Appearance Models (AAM)
Active Models of Appearance (Active Appearance Models, AAM) are statistical models of images that can be adapted to a real image by various kinds of deformations. This type of model in a two-dimensional version was proposed by Tim Kuts and Chris Taylor in 1998 [17,18]. Initially, active appearance models were used to evaluate the parameters of facial images.
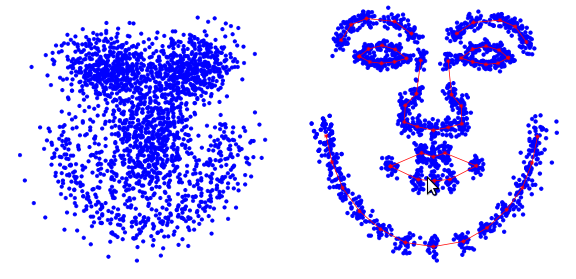
The active appearance model contains two types of parameters: parameters associated with the form (shape parameters) and parameters associated with the statistical model of image pixels or texture (appearance parameters). Before using the model must be trained on a set of pre-marked images. Image marking is done manually. Each label has its own number and determines the characteristic point that the model will have to find when adapting to a new image.

An example of a markup of a face image of 68 points forming the AAM shape.
The AAM learning procedure begins with the normalization of the shapes on the tagged images in order to compensate for differences in scale, tilt and offset. For this, the so-called generalized Procrustes analysis is used.
Coordinates of face shape points before and after normalization
Of the total set of normalized points, the main components are then selected using the PCA method.
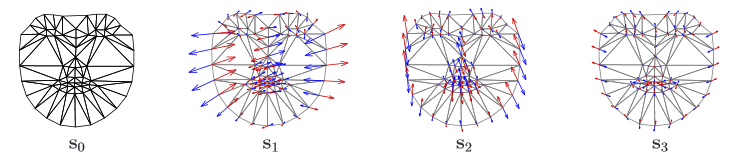
The model of the AAM form consists of a triangulation lattice s0 and a linear combination of displacements si with respect to s0
Further, a matrix is formed from pixels inside the triangles formed by points of the shape, such that each column contains the pixel values of the corresponding texture. It is worth noting that the textures used for learning can be either single-channel (grayscale) or multi-channel (for example, RGB color space or another). In the case of multichannel textures, the vectors of pixels are formed separately for each of the channels, and then they are concatenated. After finding the main components of the texture matrix, the AAM model is considered trained.

The AAM appearance model consists of a base view A0, defined by pixels inside the base lattice s0 and a linear combination of offsets Ai relative to A0

An example of instantiation of AAM. Form Parameters Vector
p = (p_1, p_2, 〖..., p _m) ^ T = (- 54.10, -9.1, ...) ^ T is used to synthesize the model of the form s, and the vector of parameters λ = (λ_1, λ_2, 〖..., λ〗 _m) ^ T = (3559,351, -256, ...) ^ T for the synthesis of the appearance of the model. The resulting face model 〖M (W (x; p))〗 ^ is obtained as a combination of two models — shape and appearance.
The model is fitted to a specific face image in the process of solving an optimization problem, the essence of which is to minimize the functionality
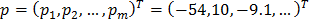
gradient descent method. The found model parameters will reflect the position of the model on a particular image.


An example of fitting a model to a specific image in 20 iterations of the gradient descent procedure.
With the help of AAM, you can simulate images of objects subject to both rigid and non-rigid deformation. AAM consists of a set of parameters, some of which represent the shape of a face, the rest define its texture. The deformation is usually understood as a geometric transformation in the form of a composition of translation, rotation and scaling. When solving the problem of localizing a face in an image, a search is made for the parameters (location, shape, texture) of AAM, which represent the synthesized image that is closest to the observed one. According to the proximity of AAM to the customized image, a decision is made whether there is a face or not.
Active Shape Models (ASM)
The essence of the ASM method [16,19,20] is to take into account the statistical relationships between the location of anthropometric points. On the available sample of images of persons taken in full face. On the image, the expert marks the location of the anthropometric points. On each image the points are numbered in the same order.
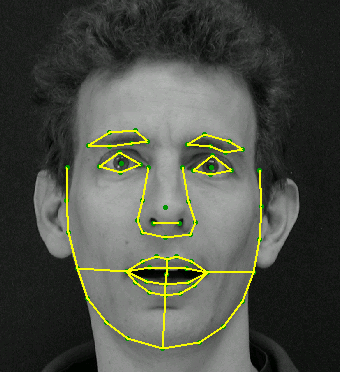

Example of a face shape using 68 points
In order to bring the coordinates on all images to a single system, so-called generalized scrolling analysis, as a result of which all points are reduced to the same scale and centered. Further, for the whole set of images, the average form and the covariance matrix are calculated. On the basis of the covariance matrix, eigenvectors are calculated, which are then sorted in descending order of the corresponding eigenvalues. The ASM model is determined by the matrix Φ and the vector of the average form s ̅.
Then any form can be described using the model and parameters:
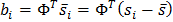
Localization of the ASM model on a new, non-training image is carried out in the process of solving an optimization problem.

a B C D)
ASM : ) ) 5 ) 10 )
AAM ASM , .
, , , (, ) . – . . 10 [1].
AAM ASM .
6. ,

( – , , 3D ).

DARPA FERET (face recognition technology).
FERET , (PCA). . ( ). , , , , 95%. , , , , 80%. , , 50%. , 50 — .
FERET [55] . , . NeoFace NEC.
( )
1. Image-based Face Recognition — Issues and Methods
2. Face Detection A Survey.pdf
3. Face Recognition A Literature Survey
4. A survey of face recognition techniques
5. A survey of face detection, extraction and recognition
6.
7.
8.
9. Face Recognition Techniques
10. .
11.
12. 2-
13. Face Recognition by Elastic Bunch Graph Matching
14. - . .
15. Distortion Invariant Object Recognition in the Dynamic Link Architecture
16. Facial Recognition Using Active Shape Models, Local Patches and Support Vector Machines
17. Face Recognition Using Active Appearance Models
18. Active Appearance Models for Face Recognition
19. Face Alignment Using Active Shape Model And Support Vector Machine
20. Active Shape Models — Their Training and Application
21. Fisher Vector Faces in the Wild
22. Eigenfaces vs. Fisherfaces Recognition Using Class Specific Linear Projection
23. Eigenfaces and fisherfaces
24. Dimensionality Reduction
25. ICCV 2011 Tutorial on Parts Based Deformable Registration
26. Constrained Local Model for Face Alignment, a Tutorial
27. Who are you – Learning person specific classifiers from video
28.
29. Face Recognition A Convolutional Neural Network Approach
30. Face Recognition using Convolutional Neural Network and Simple Logistic Classifier
31. Face Image Analysis With Convolutional Neural Networks
32. . -
33.
34. Face Detection and Recognition Using Hidden Markovs Models
35. Face Recognition with GNU Octave-MATLAB
36. Face Recognition with Python
37. Anthropometric 3D Face Recognition
38. 3D Face Recognition
39. Face Recognition Based on Fitting a 3D Morphable Model
40. Face Recognition
41. Robust Face Recognition via Sparse Representation
42. The FERET Evaluation Methodology For Face-Recognition Algorithms
43.
44. Design, Implementation and Evaluation of Hardware Vision Systems dedicated to Real-Time Face Recognition
45. An Introduction to the Good, the Bad, & the Ugly Face Recognition Challenge Prob-lem
46. - . Diploma
47. DeepFace Closing the Gap to Human-Level Performance in Face Verification
48. Taking the bite out of automated naming of characters in TV video
49. Towards a Practical Face Recognition System Robust Alignment and Illumination by Sparse Representation
50.
51.
52. -
53.
54. Overview of the Face Recognition Grand Challenge
55. Face Recognition Vendor Test (FRVT)
56. SURF
Source: https://habr.com/ru/post/238129/
All Articles