Identify search engine ranking algorithms
Food for brain
When you work for some time in the field of SEO, sooner or later you involuntarily visit thoughts about what formulas search engines use to put the site in search results higher or lower. Everyone knows that this is all kept in the deepest secrecy, and we, optimizers, know only what is written in the recommendations for webmasters, and on some resources dedicated to the promotion of sites. And now think for a second: what if you had a tool that reliably, with an accuracy of 80-95% would show what needs to be done on the page of your site, or on the site as a whole, in order for a specific query your site was in first place in the issue, or on the fifth, or simply on the first page. Moreover, if this tool could with the same accuracy determine which position of the issue will be taken if you perform certain actions. And as soon as the search engine would introduce changes in its formula, change the importance of one or another factor, then one could immediately see what exactly was changed in the formula. And this is only a small fraction of the information you could get from such a tool.
So, this is not an advertisement for the next promotion service, and this is not the provision of a specific formula for ranking websites by search engines. I want to share my theory, for the implementation of which I have neither the means, nor the time, nor sufficient knowledge of programming and mathematics. But I know for sure that even those who have all this have it, it may take even 1 month to implement this, perhaps 1-1.5 years.
Theory
So, the theory is to find out which factor affects the position more or less than another factor by pointing the finger to the sky. It's very difficult to tell all this on my fingers, so I had to make a table that more or less reflects what I want to convey.
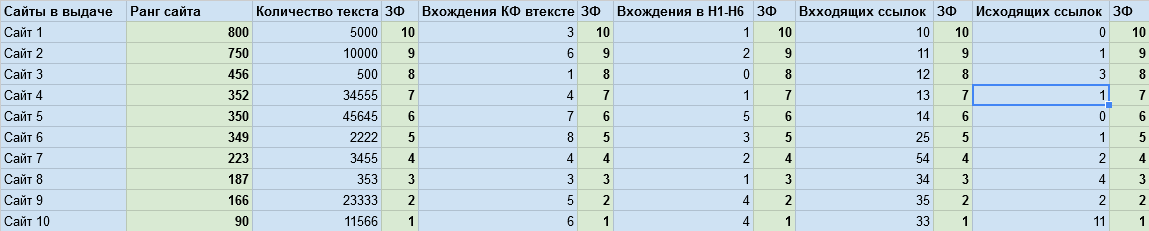
')
Have you looked at the table? Now to the point. We take any key phrase, no matter what, we enter into the search engine and from the issue we take the first 10 sites, this will be our experimental ones. Now we need to do the following: write the code, which will be at random to change the significance of the factors ( ZF in the table) ranking, until our programm arranges sites in such a way that they exactly match the search engine results. That is, we need to repeat the search engine ranking algorithm using a custom method. The significance of the factors themselves can only be defined as positive neutral or negative.
Now, in order of the table and factors. Conditionally each factor is assigned a value from 1 to 800 (approximately). Since it is reliably known that, for example, Yandex has ranking factors somewhere close to this number. Roughly speaking, our maximum number will be how many ranking factors we know for sure. Two factors cannot have the same number, that is, each factor has a unique value. There is a separate column for each factor in the table, and there are a lot of them, physically I will not be able to put everything on one picture.
Now the question is how to calculate the page rank? Very simple: to start simple math, if the factor positively affects, we add the rank of the factor to the page rank, if negative, we add 0. You can complicate, make 3 options and add, for example, subtract the rank of the factor from the page rank, if this factor is critical For example, coarse spam key phrases.
We get about this algorithm for calculating the rank of the page. Take it for ( PR ), and take the factor as ( F ) and then:
PR = Take the first factor If F1 is positive, then do PR + F1, if F1 is negative, then do PR - F1, if F1 is neutral, then do nothing, then check F2, F3, F4 and so on, until factors run out.
And the selection to produce in such a way that each factor would try each value of rank. That is, to try every factor in each value.
The whole complexity consists in taking into account all the influencing factors, up to the amount of text on the page and the TIC of the site where the link to our experimental page is located, and the complexity is not even in accounting for this information, but in collecting it. Because manually collecting all this information is unrealistic, you need to write all kinds of parsers so that our program collects all this data automatically.
The work is very large and complex and requires a certain level of knowledge, but just imagine what opportunities it will open after implementation. I will not go into all the subtleties of calculations and the influence of factors, I don’t like a lot of writing, it’s easier for me to explain to a person directly.
Now, some will say that there will be a lot of coincidences in different variations. Yes, it will, but if you take not the first page, but, for example, the first 50 pages? How many times will the probability of a miss be reduced then?
There is still a difficulty in the fact that we simply will have nowhere to take some factors, for example, we will not be able to take into account behavioral factors. Even if all the sites from the issue will be under our control, we will not be able to do this, because most likely the way the user behaves at the issue is taken into account, hence the second unknown in our equation, besides the position itself.
What will this software give us after implementation? No, it will not give the exact formula of the search engine, but it will definitely show which of the factors influences the ranking more strongly and which one is not significant at all. And during promotion we will be able to substitute the page of our site in this formula, with our own parameters, and even before starting its promotion, we will see what position the page will be on for a specific query after the search engine takes into account all the changes.
In general, this is a very complex topic, and very useful information for the mind, because it makes you think, enough, for example, the power of one computer to make such calculations? And if that's enough, how long will it take for example? If the result is not satisfactory, then the formula can somehow be complicated, changed, until 100% accurate results are obtained on 100 pages of output. Moreover, for the purity of the experiment, it is possible to connect about 100 different sites and implement a non-existent key phrase on them, and then follow the same key phrase and track the algorithm. There are lots of options. Need to work.
Source: https://habr.com/ru/post/237415/
All Articles