Centrifuge - I will no longer update the page before posting a comment
Some time has passed since I wrote about Centrifuge the previous time. There have been many changes during this period. Much of what was described in earlier articles ( 1 , 2 ) has sunk into oblivion, but the essence and idea of the project remain the same - this is the server for sending real-time messages to users connected from a web browser. When an event occurs on your site, about which you need to instantly inform some of your users, you post this event in Centrifuge, and she, in turn, sends it to all interested users who subscribe to the desired channel. In its simplest form, this is shown in the diagram:
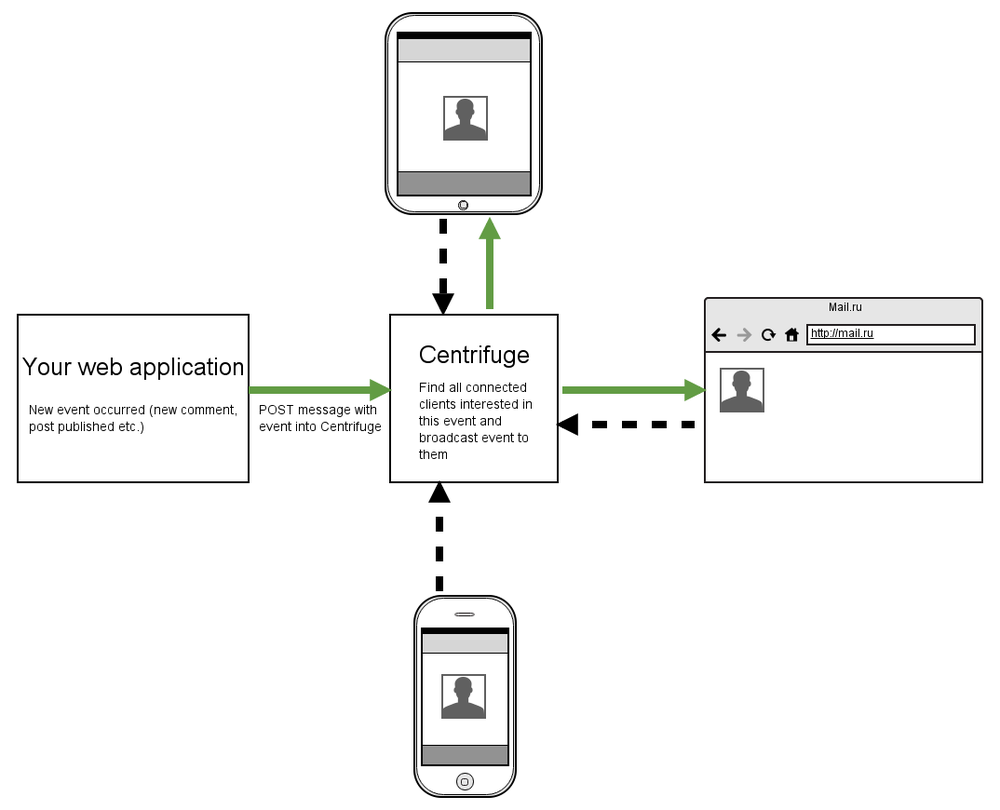
The project is written in Python using the Tornado asynchronous web server. You can use it even if the backend of your site is not written in Python. I would like to tell you that the centrifuge is at the moment.
')
Trying a project in action is a snap if you are familiar with installing Python packages. Inside virtualenv:
Run:
After that, the administrative interface of the Centrifuge process that you just launched will be available at http: // localhost: 8000 .
Especially for the article, I launched the Centrifuge instance on Heroku - habrifuge.herokuapp.com . Password - habrahabr. I hope for your honesty and prudence - the demo is in no way protected from attempts to break everything and prevent others from appreciating the project. Launched on a free dino with all the consequences. Heroku, of course, is not the best place to host this kind of applications, but for demonstration purposes it will do.
I think I will not be far from the truth if I say that Centrifuge has no analogs, at least in the open-source world of Python. Let me explain why I think so. There are plenty of ways to add real-time events to the site. From what comes to mind:
In JavaScript, there is Meteor, Derby - a completely different approach. There is also a wonderful Faye server that easily integrates with your JavaScript or Ruby backend. But this solution is for NodeJS and Ruby. The centrifuge implements the first approach listed above. The advantage of a stand-alone asynchronous server (and cloud service) is that you do not need to change the code and philosophy of the existing backend, which will inevitably happen as soon as you decide to use Gevent, for example, to patch the standard Python libraries. The approach with a separate server makes it easy and painless to integrate real-time messages into the existing backend architecture.
The disadvantage is that the output with a similar architecture results in a slightly “trimmed” real-time. Your web application must withstand HTTP requests from clients that generate events: new events are initially sent to your backend, validated, stored in the database, if necessary, and then sent to Centrifuge (at pusher.com, pubnub.com and others). However, in most cases, this restriction does not affect the tasks of the web; dynamic real-time games can suffer from this, where one client generates a very large number of events. For such cases, perhaps, we need a closer integration of real-time applications and backends, perhaps something like gevent-socketio. If the events on the site are not generated by the client, but by the backend itself, then in this case, the disadvantage voiced above does not matter.
Saying that there are no centrifuges in the open-source world of Python, I do not mean that there is no other implementation of a stand-alone server for sending messages via web sockets and polyfills to them. I just did not find any such project, fully from the box solves most of the problems of real use.
Typing in the search engine " python real-time github " you get a lot of links to examples of such servers. But! Most of these results only demonstrate an approach to solving the problem, without going deep. You are missing one process and you need to scale the application somehow - well, if the project documentation says that you need to use PUB / SUB broker for this purpose — Redis, ZeroMQ, RabbitMQ — this is true, but you will have to implement it yourself. Often, all such examples are limited to a set type class variable, to which new connection objects are added and sending a new message to all clients from this connection set.
The main purpose of the Centrifuge is to provide out of the box solution to real-use problems Let's look at some points that will have to deal more.
Of course, there are projects (again, dynamic real-time games) for which the use of web sockets is critical. The centrifuge uses SockJS to emulate web sockets in older browsers. This means browser support up to IE7 using transports such as xhr-streaming, iframe-eventsource, iframe-htmlfile, xhr-polling, jsonp-polling. For this, a wonderful implementation of SockJS server is used - sockjs-tornado .
It is also worth noting that you can also connect to the Centrifuge using “clean” web sockets - without wrapping the interaction in the SockJS protocol.
There is a JavaScript client in the repository with a simple and clear API.
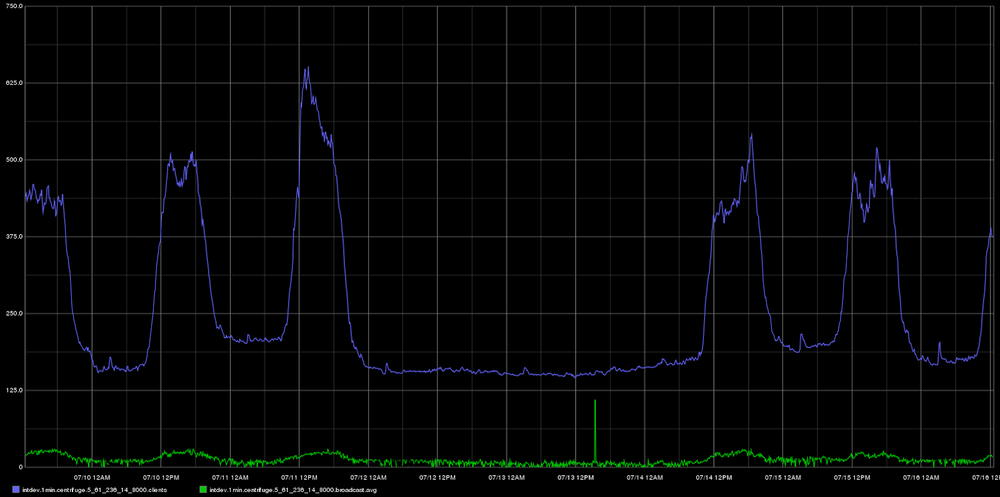
Here, by the way, is a graph from Graphite for the weekly period of Centrifuge operation used by the Mail.Ru Group intranet. The blue line is the number of active connections, the green line is the average message distribution time in milliseconds. In the middle - the weekend. :)
I would like to mention one of the recent innovations. As I told in previous articles, if a client subscribes to a private channel, the Centrifuge will send a POST request to your application, asking if a user with such an ID can connect to a specific channel. Now it is possible to create a private channel, when subscribing to which your web application will not be involved at all. Just name the channel at your convenience and at the end after the special character # write the user ID, which is allowed to subscribe to this channel. Only the user with ID 42 will be allowed to subscribe to this channel:
And you can do it like this:
This is a private channel for 2 users with ID 42 and 56.
In recent versions, the connection expiration mechanism has also been added - it is turned off by default, since it is not needed for most projects. The mechanism should be considered as experimental.
Perhaps, in the development process of the project, there were two most difficult solutions: how to synchronize the state between several processes (the simplest way was to choose - using Redis) and the problem with clients who connected to the Centrifuge before they were deactivated (banned, deleted) in web application.
The difficulty here is that the Centrifuge does not store anything at all except the settings of projects and the namespaces of projects in the permanent storage. Therefore, it was necessary to think of a way to reliably disable non-valid clients, without being able to save the identifiers or tokens of these clients, taking into account possible centrifuges and web applications downtime. This method was eventually found. However, to apply it in a real project has not yet happened, hence the experimental status. I will try to describe how the solution works in theory.
As I described earlier, in order to connect to the Centrifuge from the browser, you need to transfer, in addition to the connection address, some required parameters - the current user ID and the project ID. Also in the connection settings there must be an HMAC token generated based on the project's secret key on the backend of the web application. This token confirms the correctness of the parameters passed by the client.
The trouble is that earlier, once having received such a token, the client could easily use it in the future: subscribe to public channels, read messages from them. Fortunately, do not write (since the messages initially pass through your backend)! This is a normal situation for many public sites. Nevertheless, I was sure that an additional data protection mechanism was needed.
Therefore, among the required parameters when connecting appeared parameter
In the project settings, an option appeared that answers the question: how many seconds should a new connection be considered correct? The centrifuge periodically searches for compounds that have expired and adds them to a special list (actually set) for testing. Once a certain time interval, the Centrifuge sends a POST request to your application with a list of user IDs that need to be verified. The application responds by sending a list of user IDs that did not pass this check — these clients will be immediately forcibly disconnected from the Centrifuge, while there will be no automatic reconnect on the client side.
But not everything is so simple. There is a possibility that the “attacker”, having corrected, for example, JavaScript on the client, will instantly reconnect after being forcibly expelled. And if the
Perhaps using the scheme to understand this mechanism will be much easier:

In the previous article about Centrifuge, I told you that it uses ZeroMQ. And the comments were unanimous - ZeroMQ is not needed, use Redis, the performance of which is enough with the head. At first I thought a bit and added Redis as an optional PUB / SUB backend. And then there was this benchmark:
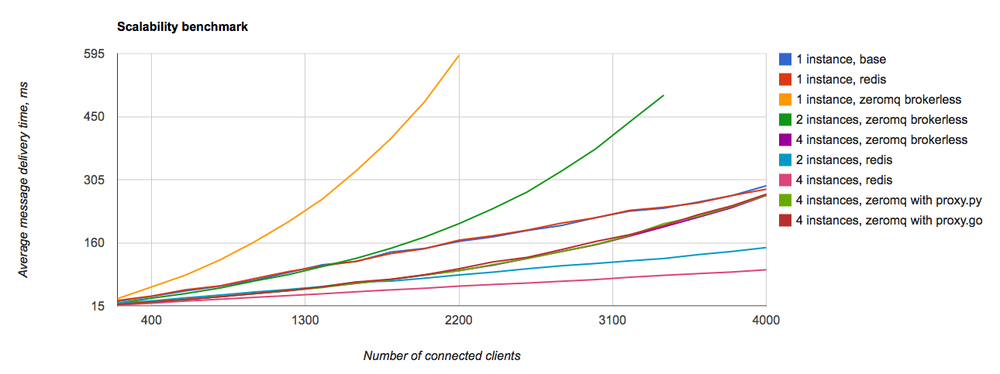
I was surprised, really. Why was ZeroMQ so much worse for my tasks than Redis? I do not know the answer to this question. Searching on the Internet, I found an article where the author also complains that ZeroMQ is not suitable for fast real-time web. Unfortunately, now I have lost the link to this article. As a result, ZeroMQ in the Centrifuge is no longer used, only 2 so-called engines remain - Memory and Redis (the first one is suitable if you run one Centrifuge instance, and Redis and its PUB / SUB are not for you).
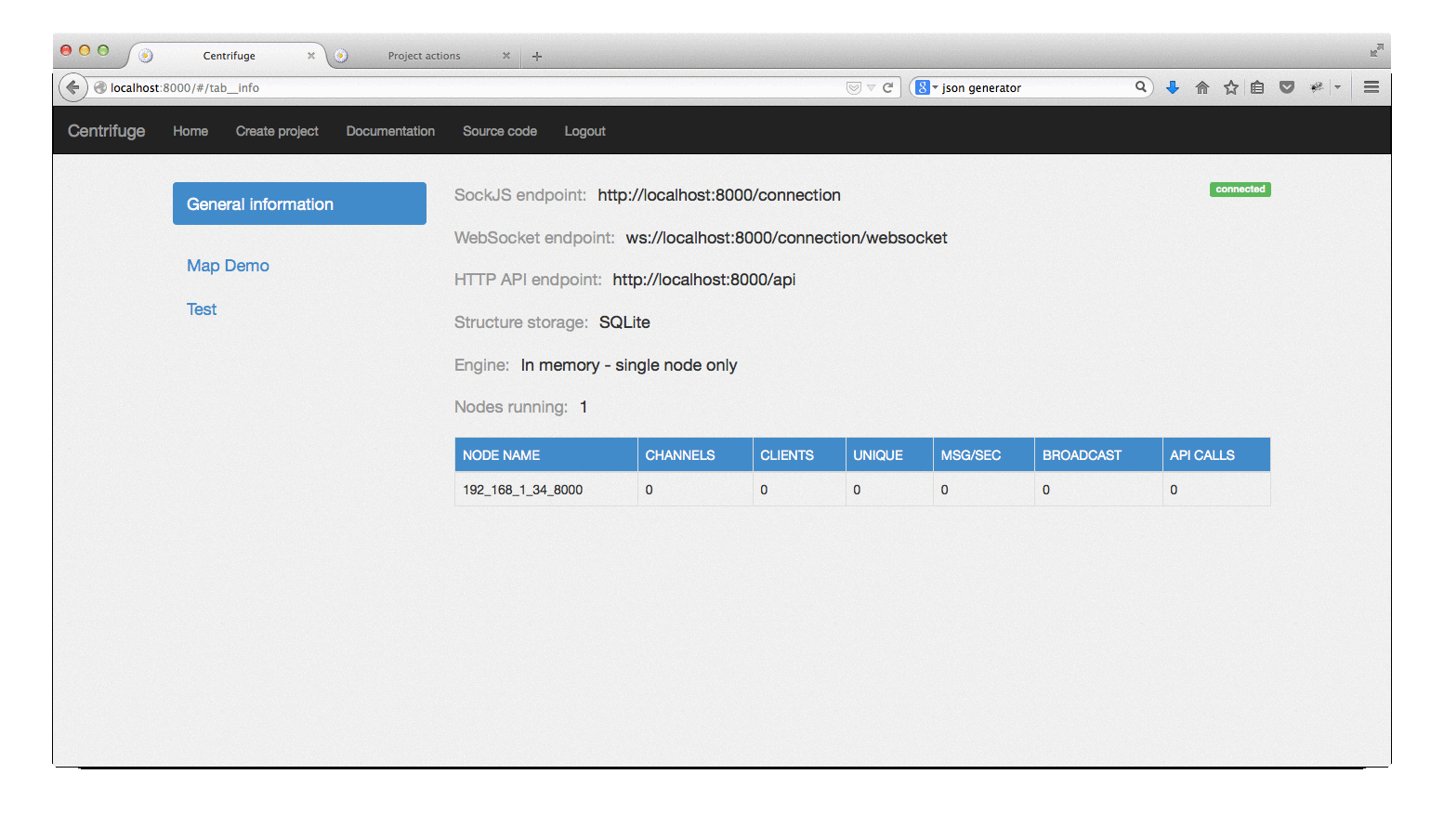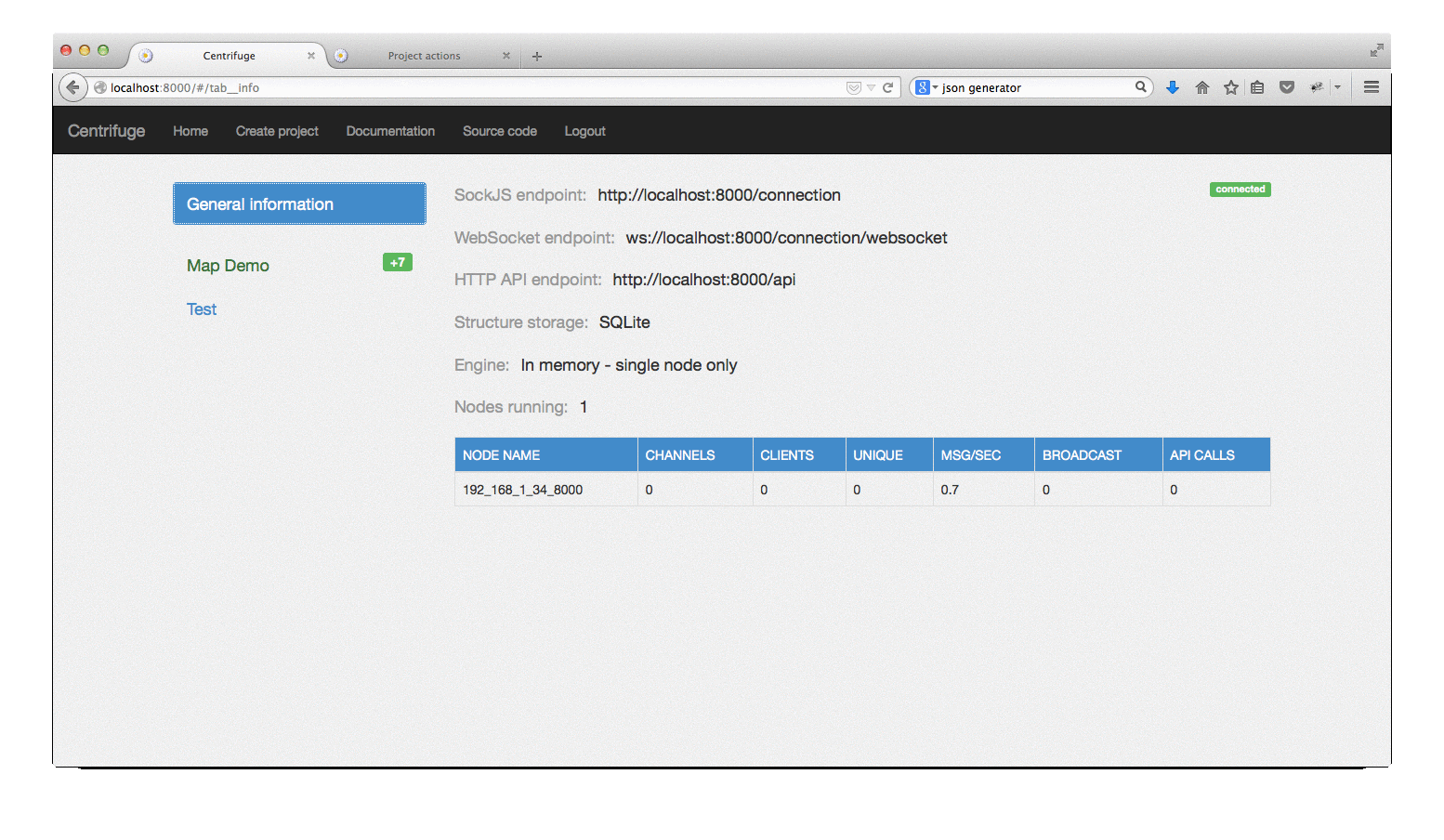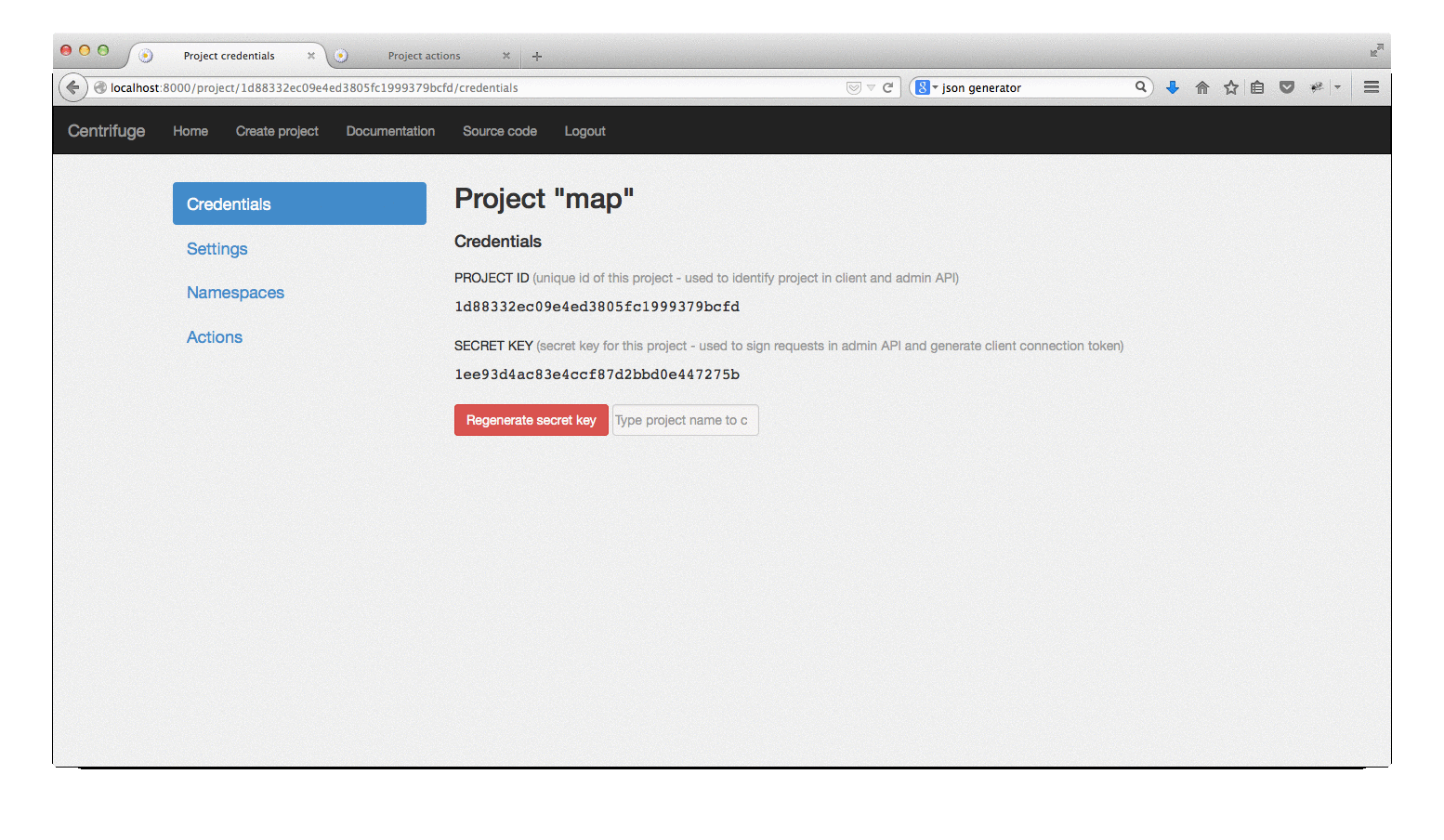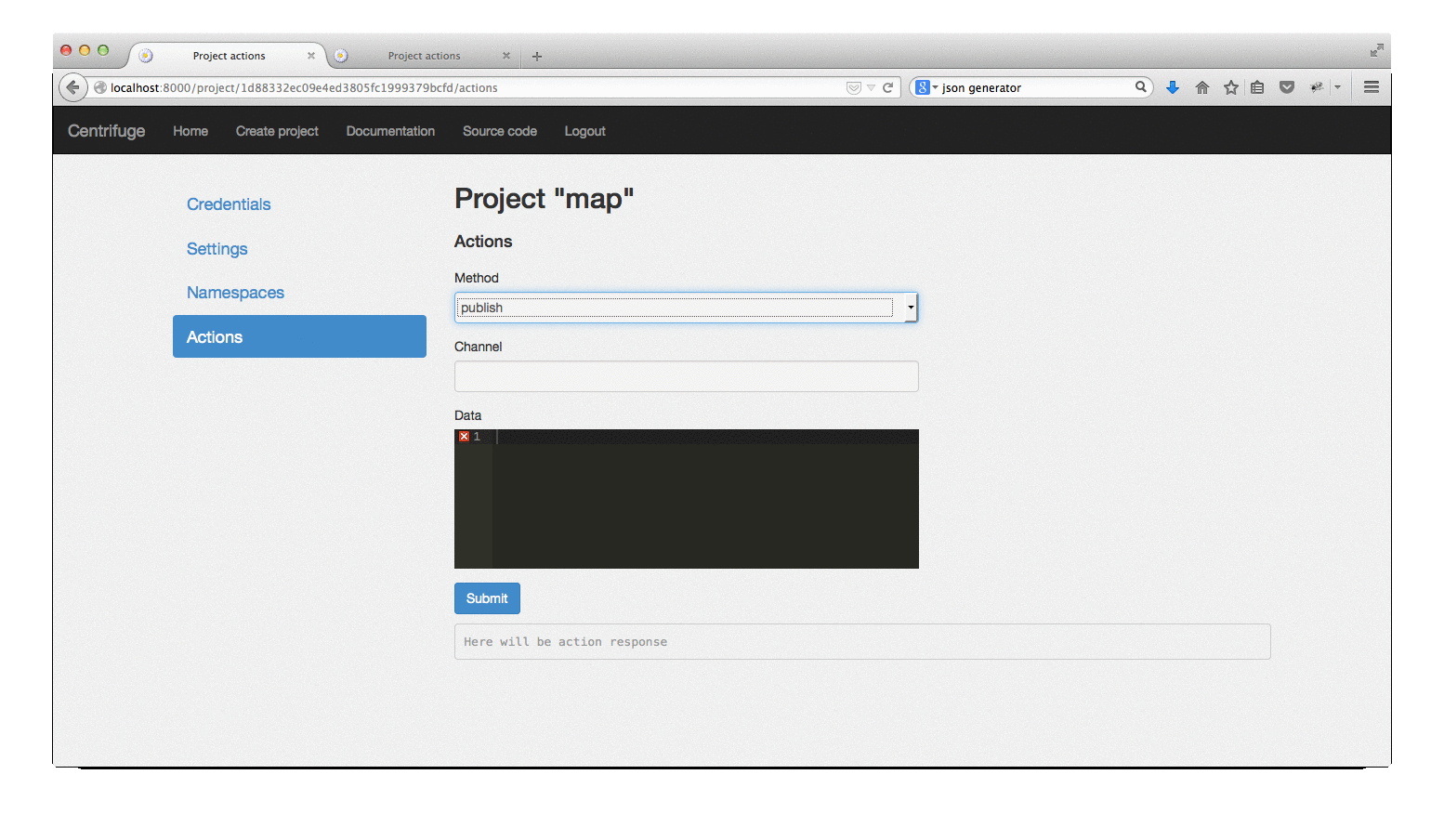
As you could see on the gif above, the web interface has not disappeared anywhere, it is still used to create projects, change settings, monitor messages in some channels. Through it, you can also send commands to the Centrifuge, for example, post a message. In general, it was before, I just decided to repeat, if you suddenly do not know.
From other changes:
As mentioned earlier in the Mail.Ru Group blog on Habré, the centrifuge is used in our corporate intranet. Real-rime messages have added usability, colors and dynamics to our internal portal. Users do not need to update the page before posting a comment (no need to update, no need to update ...) - isn't this great?
Do not wait for a guaranteed message delivery to the client. If, for example, a user opens a page, then plunges his laptop into a dream, then when he “wakes up” his machine, the connection with the Centrifuge will be re-established. But all the events that occurred while the laptop was in sleep mode will be lost. And the user needs to either update the page, or you should independently write the logic of reloading lost events from your backend. You also need to remember that almost all objects (connections, channels, message history) are stored in RAM, so it is important to monitor its consumption. One should not forget about the limits of the operating system for open file descriptors and increase them if necessary. It is necessary to think about what channel to create in a given situation - private or public, with or without history, what should be the length of this story, etc.
As I mentioned above, there are plenty of ways to add real-time to your site, you need to choose wisely, perhaps in your case, the option with a separate asynchronous server will not be more advantageous.
PS In the late spring, I attended the python developers conference in St. Petersburg, Piter Py. In one of the reports, the talk was about instant notifications to users that their task, which was performed asynchronously in Celery-worker, is ready. The speaker said that they use Tornado and web sockets for this purpose. Then followed a few questions about how it works in conjunction with Django, how it starts, what authorization ... The guys who asked those questions, if you read this article, give the Centrifuge a chance, it is great for such tasks.
The project is written in Python using the Tornado asynchronous web server. You can use it even if the backend of your site is not written in Python. I would like to tell you that the centrifuge is at the moment.
')
Trying a project in action is a snap if you are familiar with installing Python packages. Inside virtualenv:
$ pip install centrifuge Run:
$ centrifuge After that, the administrative interface of the Centrifuge process that you just launched will be available at http: // localhost: 8000 .
Especially for the article, I launched the Centrifuge instance on Heroku - habrifuge.herokuapp.com . Password - habrahabr. I hope for your honesty and prudence - the demo is in no way protected from attempts to break everything and prevent others from appreciating the project. Launched on a free dino with all the consequences. Heroku, of course, is not the best place to host this kind of applications, but for demonstration purposes it will do.
I think I will not be far from the truth if I say that Centrifuge has no analogs, at least in the open-source world of Python. Let me explain why I think so. There are plenty of ways to add real-time events to the site. From what comes to mind:
- stand alone asynchronous server;
- cloud service (pusher.com, pubnub.com);
- gevent (gunicorn, uwsgi);
- Nginx modules / extensions;
- BOSH, XMPP.
In JavaScript, there is Meteor, Derby - a completely different approach. There is also a wonderful Faye server that easily integrates with your JavaScript or Ruby backend. But this solution is for NodeJS and Ruby. The centrifuge implements the first approach listed above. The advantage of a stand-alone asynchronous server (and cloud service) is that you do not need to change the code and philosophy of the existing backend, which will inevitably happen as soon as you decide to use Gevent, for example, to patch the standard Python libraries. The approach with a separate server makes it easy and painless to integrate real-time messages into the existing backend architecture.
The disadvantage is that the output with a similar architecture results in a slightly “trimmed” real-time. Your web application must withstand HTTP requests from clients that generate events: new events are initially sent to your backend, validated, stored in the database, if necessary, and then sent to Centrifuge (at pusher.com, pubnub.com and others). However, in most cases, this restriction does not affect the tasks of the web; dynamic real-time games can suffer from this, where one client generates a very large number of events. For such cases, perhaps, we need a closer integration of real-time applications and backends, perhaps something like gevent-socketio. If the events on the site are not generated by the client, but by the backend itself, then in this case, the disadvantage voiced above does not matter.
Saying that there are no centrifuges in the open-source world of Python, I do not mean that there is no other implementation of a stand-alone server for sending messages via web sockets and polyfills to them. I just did not find any such project, fully from the box solves most of the problems of real use.
Typing in the search engine " python real-time github " you get a lot of links to examples of such servers. But! Most of these results only demonstrate an approach to solving the problem, without going deep. You are missing one process and you need to scale the application somehow - well, if the project documentation says that you need to use PUB / SUB broker for this purpose — Redis, ZeroMQ, RabbitMQ — this is true, but you will have to implement it yourself. Often, all such examples are limited to a set type class variable, to which new connection objects are added and sending a new message to all clients from this connection set.
The main purpose of the Centrifuge is to provide out of the box solution to real-use problems Let's look at some points that will have to deal more.
Polyphilli
Alone webboxes are not enough. If you do not believe, watch a speech with the saying title “Websuckets” from one of the Socket.io developers. Here are the slides . And here is the video:Of course, there are projects (again, dynamic real-time games) for which the use of web sockets is critical. The centrifuge uses SockJS to emulate web sockets in older browsers. This means browser support up to IE7 using transports such as xhr-streaming, iframe-eventsource, iframe-htmlfile, xhr-polling, jsonp-polling. For this, a wonderful implementation of SockJS server is used - sockjs-tornado .
It is also worth noting that you can also connect to the Centrifuge using “clean” web sockets - without wrapping the interaction in the SockJS protocol.
There is a JavaScript client in the repository with a simple and clear API.
Scaling
You can run several processes - they will communicate with each other using Redis PUB / SUB. I would like to note that Centrifuge does not claim to be installed inside huge sites with millions of visitors. Perhaps, for such projects you need to find another solution - the same cloud services or your own development. But for the vast majority of projects, several instances of the server behind the balancer, connected by the Redis PUB / SUB mechanism, will be more than enough. We have, for example, one instance (Redis is not needed in this case) withstands 1000 simultaneous connections without problems, the average message sending time is less than 50 ms.Here, by the way, is a graph from Graphite for the weekly period of Centrifuge operation used by the Mail.Ru Group intranet. The blue line is the number of active connections, the green line is the average message distribution time in milliseconds. In the middle - the weekend. :)
Authentication and authorization
By connecting to Centrifuge, you use symmetric encryption based on the project's private key to generate a token (HMAC). This token is validated upon connection. Also, when connected, the user ID and, if desired, additional information about it are transmitted. Therefore, Centrifuge knows enough about your users to handle connections to private channels. This mechanism is inherently very similar to JWT (JSON Web Token).I would like to mention one of the recent innovations. As I told in previous articles, if a client subscribes to a private channel, the Centrifuge will send a POST request to your application, asking if a user with such an ID can connect to a specific channel. Now it is possible to create a private channel, when subscribing to which your web application will not be involved at all. Just name the channel at your convenience and at the end after the special character # write the user ID, which is allowed to subscribe to this channel. Only the user with ID 42 will be allowed to subscribe to this channel:
news#42 And you can do it like this:
dialog#42,56 This is a private channel for 2 users with ID 42 and 56.
In recent versions, the connection expiration mechanism has also been added - it is turned off by default, since it is not needed for most projects. The mechanism should be considered as experimental.
Perhaps, in the development process of the project, there were two most difficult solutions: how to synchronize the state between several processes (the simplest way was to choose - using Redis) and the problem with clients who connected to the Centrifuge before they were deactivated (banned, deleted) in web application.
The difficulty here is that the Centrifuge does not store anything at all except the settings of projects and the namespaces of projects in the permanent storage. Therefore, it was necessary to think of a way to reliably disable non-valid clients, without being able to save the identifiers or tokens of these clients, taking into account possible centrifuges and web applications downtime. This method was eventually found. However, to apply it in a real project has not yet happened, hence the experimental status. I will try to describe how the solution works in theory.
As I described earlier, in order to connect to the Centrifuge from the browser, you need to transfer, in addition to the connection address, some required parameters - the current user ID and the project ID. Also in the connection settings there must be an HMAC token generated based on the project's secret key on the backend of the web application. This token confirms the correctness of the parameters passed by the client.
The trouble is that earlier, once having received such a token, the client could easily use it in the future: subscribe to public channels, read messages from them. Fortunately, do not write (since the messages initially pass through your backend)! This is a normal situation for many public sites. Nevertheless, I was sure that an additional data protection mechanism was needed.
Therefore, among the required parameters when connecting appeared parameter
timestamp . This is Unix seconds ( str(int(time.time())) ). This timestamp also involved in the generation of the token. That is, the connection now looks like this: var centrifuge = new Centrifuge({ url: 'http://localhost:8000/connection', token: 'TOKEN', project: 'PROJECT_ID', user: 'USER_ID', timestamp: '1395086390' }); In the project settings, an option appeared that answers the question: how many seconds should a new connection be considered correct? The centrifuge periodically searches for compounds that have expired and adds them to a special list (actually set) for testing. Once a certain time interval, the Centrifuge sends a POST request to your application with a list of user IDs that need to be verified. The application responds by sending a list of user IDs that did not pass this check — these clients will be immediately forcibly disconnected from the Centrifuge, while there will be no automatic reconnect on the client side.
But not everything is so simple. There is a possibility that the “attacker”, having corrected, for example, JavaScript on the client, will instantly reconnect after being forcibly expelled. And if the
timestamp in its connection parameters is still valid, the connection will be accepted. But on the next verification cycle, after its connection expires, its ID will be sent to the web application using the same mechanism, it will say that the user is invalid, and after that it will be disabled forever (since the timestamp has already expired). That is, there is a small gap in time during which the client has the opportunity to continue reading from public channels. But its value is configured - I think it is not at all scary if, after the actual deactivation, the user can still read messages from the channels for some time.Perhaps using the scheme to understand this mechanism will be much easier:
Depla
In the repository there are examples of real configuration files that we use for deploying Centrifuges. We run it on CentOS 6 for Nginx under the supervisor (Supervisord). There is a spec-file - if you have CentOS, then you can build rpm based on it.Monitoring
The latest version of Centrifuge has the ability to export various metrics to Graphite via UDP. Metrics are aggregated at a given time interval, à la StatsD. Above the text was just a picture with a graph from Graphite.In the previous article about Centrifuge, I told you that it uses ZeroMQ. And the comments were unanimous - ZeroMQ is not needed, use Redis, the performance of which is enough with the head. At first I thought a bit and added Redis as an optional PUB / SUB backend. And then there was this benchmark:
I was surprised, really. Why was ZeroMQ so much worse for my tasks than Redis? I do not know the answer to this question. Searching on the Internet, I found an article where the author also complains that ZeroMQ is not suitable for fast real-time web. Unfortunately, now I have lost the link to this article. As a result, ZeroMQ in the Centrifuge is no longer used, only 2 so-called engines remain - Memory and Redis (the first one is suitable if you run one Centrifuge instance, and Redis and its PUB / SUB are not for you).
As you could see on the gif above, the web interface has not disappeared anywhere, it is still used to create projects, change settings, monitor messages in some channels. Through it, you can also send commands to the Centrifuge, for example, post a message. In general, it was before, I just decided to repeat, if you suddenly do not know.
From other changes:
- MIT license instead of BSD;
- neymspeys refactoring: now it is not a separate entity and field in the protocol, but simply a prefix in the channel name, separated by a colon (
public:news); - JavaScript client improvements
- Work with JSON can now be significantly accelerated if the ujson module is additionally installed;
- organization Centrifugal on GitHub - with repositories related to the project, in addition to the Python client for Centrifuge - there is now including an example of how to deploy the project on Heroku and the first version of the adjacent library - a small wrapper for integration with Django (simplifies life with generating parameters connections, there are methods for conveniently sending messages to the Centrifuge);
- corrected / expanded documentation in accordance with the changes / additions;
- many other changes are reflected in the changelog .
As mentioned earlier in the Mail.Ru Group blog on Habré, the centrifuge is used in our corporate intranet. Real-rime messages have added usability, colors and dynamics to our internal portal. Users do not need to update the page before posting a comment (no need to update, no need to update ...) - isn't this great?
Conclusion
Like any other solution, you need to use the Centrifuge wisely. This is not a silver bullet, you need to understand that by and large it is only a message broker, whose only task is to keep connections with customers and send them messages.Do not wait for a guaranteed message delivery to the client. If, for example, a user opens a page, then plunges his laptop into a dream, then when he “wakes up” his machine, the connection with the Centrifuge will be re-established. But all the events that occurred while the laptop was in sleep mode will be lost. And the user needs to either update the page, or you should independently write the logic of reloading lost events from your backend. You also need to remember that almost all objects (connections, channels, message history) are stored in RAM, so it is important to monitor its consumption. One should not forget about the limits of the operating system for open file descriptors and increase them if necessary. It is necessary to think about what channel to create in a given situation - private or public, with or without history, what should be the length of this story, etc.
As I mentioned above, there are plenty of ways to add real-time to your site, you need to choose wisely, perhaps in your case, the option with a separate asynchronous server will not be more advantageous.
PS In the late spring, I attended the python developers conference in St. Petersburg, Piter Py. In one of the reports, the talk was about instant notifications to users that their task, which was performed asynchronously in Celery-worker, is ready. The speaker said that they use Tornado and web sockets for this purpose. Then followed a few questions about how it works in conjunction with Django, how it starts, what authorization ... The guys who asked those questions, if you read this article, give the Centrifuge a chance, it is great for such tasks.
Source: https://habr.com/ru/post/237257/
All Articles