Coachman, do not drive horses or why fast backup is not always good?
Recently, Veeam announced a new feature in the upcoming update of its main product, the whole essence of which is to prevent the application from running too fast. It sounds at least strange, so I suggest trying to figure out why it is necessary to artificially reduce the speed of creating a backup, when the voice of the mind actively insists on the opposite.
And, since “they start to dance from the stove”, we will look at the situation from the very beginning - with the principles underlying virtual backups, we dig a little inside and reveal one obvious problem that about 90% of administrators of virtual environments do not take into account. Also note that to simplify the narration, descriptions of all functions will be given on the basis of the VMware hypervisor functionality, as the most transparent and documented.
The main idea lies in reducing the load on the storage system where the production system is located, since uncontrolled activity often leads to an excessive increase in delays in performing I / O operations, and this causes unpleasant consequences:
• Application performance inside guest OS drops to critical lows and even lower
• The collapse of cluster structures, such as DAG, SQL always on, etc.
• Guest OS may simply lose the system disk.
And many other, most incredible at first glance things related to performance degradation at the storage level.
It's no secret that backup virtual environments are based on snapshots. This alpha and omega allows you to achieve two very important goals: the consistency of the file structure on the disks of the virtual machine and the protection of the files of the disks themselves for a period of backup.
')
After successfully stopping disk operations and creating snapshots, you can proceed directly to saving VM disks. You can do this in different ways:
• You can pick up a file by contacting the host directly via the LAN stack. This method always works, but it is always very slow (unless the entire backup infrastructure is built on 10G links).
• A better option is to temporarily attach the drive to another machine and download it from there. In this case, the data will be obtained directly from the storage, through the I / O stack. Copy speed in this case, other things being equal, will be better by at least an order of magnitude.
• And the fastest, but also the most expensive option is to pick up the file directly from the SAN, receiving all the necessary metadata from the hypervisor. In this case, the copy speed can be higher by two orders of magnitude and three. Everything depends only on the connection between the SAN and the storage location of the backup.
But no matter what option you use, after the disk copying is completed, it is time to perform the reverse operation - all changes that occurred with the virtual machine during backup and accumulated in snapshot should be consolidated with the original disk, after which the snapshot can be safely removed, and VM will continue to work as if nothing had happened.
And here two very important nuances emerge, to which few people pay attention, until they face their manifestations.
Snapshot consolidation is a very difficult procedure in terms of the load on the host storage system and is directly dependent on the speed (performance) of the storage. This time. And two - this operation has the highest priority at the hypervisor level, since nothing is more important than the integrity of information, and it is difficult to argue with that.
By adding the first to the second, you can easily conclude that if during the consolidation of the snapshot a heartbeat request arrives at the cluster VM, the hypervisor can easily postpone its transfer (placing in a temporary buffer) if it considers that the answer to this request takes an unacceptable amount of time and can lead to mismatch consolidation operations.
At this moment we will have three opinions:
• From a guest OS point of view, everything is fine. It works, and the fact that the hypervisor freezes it a little is not even noticeable at its level. But it is worth noting that there are exceptions, and, as described at the beginning of the article, the OS can lose touch with its disks. Including the system with all the consequences.
• From a hypervisor point of view, everything is just fine. He diligently removes snapshots, and requests that go to the VM, at his discretion, puts into his buffer or into the so-called Helper snapshot, in order to later send this VM data. The integrity of the data is guaranteed, everyone is dancing.
• But on the cluster at this point panic. A member of the cluster (or even several participants) has already missed several surveys, and it is time to start a quorum recalculation, or even completely report that the cluster is more dead than alive. In any case, the situation is very unpleasant.
If someone wants to test their cluster, I want to warn you that you should not create snapshots, count to ten and immediately delete it. Snapshot has to live, buildmuscle ... grow in volume and only then it needs to be consolidated. Otherwise, the test does not make sense. You can estimate the time required for a proper experiment in a simple way: through the Datastore Browser, download vmdk VM files. The time it takes for such an operation will be 99% correct.
Some clients, after having DAG collapsed again after a three-day backup mailbox server located on the Late Paleolithic storage system, are very fond of accusing us of all mortal sins, referring to the obvious connection - the cluster collapsed during backup, which means the backup software is to blame. But, unfortunately, all the facts described in this article are confirmed by VMware itself. In an article placed in their KB, it is written in black and white - during consolidation of a snapshot, a loaded VM may stop responding to requests from outside. Typical consequences of this are a BSOD with a message about the loss of the system disk; if a VM was part of a cluster, then it is excluded from it, the cluster decays, or in the best case, you will simply see a very strong performance degradation (although this can be relatively successfully addressed by increasing RAM). And in the best practices it is not recommended to store snapshot for more than two days.
For our part, we also collected a selection of information on this topic in our HF article .
Obviously, the bottleneck in this process is the internal speed of the storage system. Even in the morning it seemed that we had just a great drive, and by the evening we were forced to turn off production to reduce the load on the story, in the hope that this time it would be possible to remove the forgotten month ago, which had grown to hundreds of gigabytes (and VM performance dropped to a critical point).
At the beginning, a frontal attack option was tested - a parameter was introduced that directly limited the number of operations with storage systems. But this method had too many disadvantages inherent in static systems. And sometimes it came to a shot in the foot - young pioneers who love to keep backups on the same storage system where the VMs are located can reveal all possible ways to make backup even slower, and bring the host to panic.
Therefore, in the new version it was decided to completely abandon such a model and move on to dynamic processing of current I / O delays. At the global settings of the application, it looks like this:
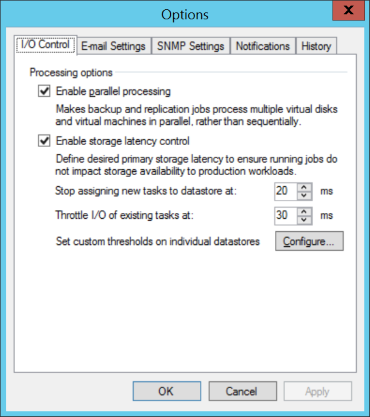
Moreover, it should be noted that in addition to the global settings, you can set your own parameters for each specific data storage or volume, in the case of working with Hyper-V. But this is a licensing issue.
So consider the same proposed combination of parameters.
“ Stop assigning new tasks to datastore at: ” If during backup we see that the delay (IOPS latency) value has exceeded the allowed threshold, the VBR server will not create new file transfer streams until the storage performance returns to the acceptable level. Or simply put, we will not try to squeeze all the juice out of the storage, if it is heavily loaded enough.
“ Throttle I / O of existing tasks at: ” - is used if the backup task is already running, and there is a delay when accessing the disk caused by external load. For example, if during a backup, a SQL server starts up on one of the machines, creating an additional load on the same storage system, the VBR server will artificially reduce its own disk access rate so as not to interfere with the production system. When performance returns to the previous level, the VBR server will also automatically increase the data transfer rate. This item somehow complements the previous one. If, as a first measure, we simply cease to create additional workload, working at a certain steady-state level, then the second measure is reducing the intensity of operations already underway in favor of production systems.
An example of how these parameters are fulfilled is perfectly visible on this screenshot:
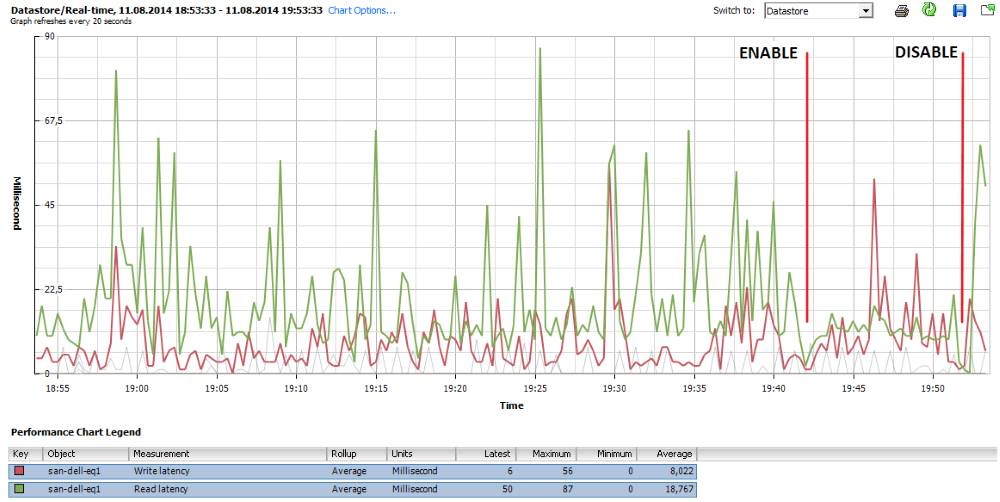
At the very beginning of the graph, the repository is in a state of “rest”, i.e. normal operating procedures occur. At 6:55 pm, a backup task was activated, which caused the expected increase in delays in read / write operations with pronounced peaks reaching 80 msec. Around 7:42 pm, the control mechanism was activated (the Enable checkbox), and, as we can see, the average value of read operation delays (green graph) is kept at 20 ms and grows only when the control mechanism is disabled (Disable mark).
I note that the default values of the thresholds of 20 and 30 ms are not taken from the ceiling, but as a result of the evaluation of monitoring data from many of our customers who kindly agreed to provide them. Thus, these values are perfect for most virtual environments.
Perhaps on this I will finish the description of this function. I tried to make it as accessible as possible, but if there are more questions, I will be happy to continue in the comments or through the PM.
Also do not hesitate to ask questions about our other products or their individual functions. I will try to answer everyone, but if I don’t succeed briefly, I’ll make a separate article.
And, since “they start to dance from the stove”, we will look at the situation from the very beginning - with the principles underlying virtual backups, we dig a little inside and reveal one obvious problem that about 90% of administrators of virtual environments do not take into account. Also note that to simplify the narration, descriptions of all functions will be given on the basis of the VMware hypervisor functionality, as the most transparent and documented.
The main idea lies in reducing the load on the storage system where the production system is located, since uncontrolled activity often leads to an excessive increase in delays in performing I / O operations, and this causes unpleasant consequences:
• Application performance inside guest OS drops to critical lows and even lower
• The collapse of cluster structures, such as DAG, SQL always on, etc.
• Guest OS may simply lose the system disk.
And many other, most incredible at first glance things related to performance degradation at the storage level.
How we got to this
It's no secret that backup virtual environments are based on snapshots. This alpha and omega allows you to achieve two very important goals: the consistency of the file structure on the disks of the virtual machine and the protection of the files of the disks themselves for a period of backup.
')
After successfully stopping disk operations and creating snapshots, you can proceed directly to saving VM disks. You can do this in different ways:
• You can pick up a file by contacting the host directly via the LAN stack. This method always works, but it is always very slow (unless the entire backup infrastructure is built on 10G links).
• A better option is to temporarily attach the drive to another machine and download it from there. In this case, the data will be obtained directly from the storage, through the I / O stack. Copy speed in this case, other things being equal, will be better by at least an order of magnitude.
• And the fastest, but also the most expensive option is to pick up the file directly from the SAN, receiving all the necessary metadata from the hypervisor. In this case, the copy speed can be higher by two orders of magnitude and three. Everything depends only on the connection between the SAN and the storage location of the backup.
But no matter what option you use, after the disk copying is completed, it is time to perform the reverse operation - all changes that occurred with the virtual machine during backup and accumulated in snapshot should be consolidated with the original disk, after which the snapshot can be safely removed, and VM will continue to work as if nothing had happened.
And here two very important nuances emerge, to which few people pay attention, until they face their manifestations.
Snapshot consolidation is a very difficult procedure in terms of the load on the host storage system and is directly dependent on the speed (performance) of the storage. This time. And two - this operation has the highest priority at the hypervisor level, since nothing is more important than the integrity of information, and it is difficult to argue with that.
By adding the first to the second, you can easily conclude that if during the consolidation of the snapshot a heartbeat request arrives at the cluster VM, the hypervisor can easily postpone its transfer (placing in a temporary buffer) if it considers that the answer to this request takes an unacceptable amount of time and can lead to mismatch consolidation operations.
At this moment we will have three opinions:
• From a guest OS point of view, everything is fine. It works, and the fact that the hypervisor freezes it a little is not even noticeable at its level. But it is worth noting that there are exceptions, and, as described at the beginning of the article, the OS can lose touch with its disks. Including the system with all the consequences.
• From a hypervisor point of view, everything is just fine. He diligently removes snapshots, and requests that go to the VM, at his discretion, puts into his buffer or into the so-called Helper snapshot, in order to later send this VM data. The integrity of the data is guaranteed, everyone is dancing.
• But on the cluster at this point panic. A member of the cluster (or even several participants) has already missed several surveys, and it is time to start a quorum recalculation, or even completely report that the cluster is more dead than alive. In any case, the situation is very unpleasant.
If someone wants to test their cluster, I want to warn you that you should not create snapshots, count to ten and immediately delete it. Snapshot has to live, build
Mom, well, I'm not guilty
Some clients, after having DAG collapsed again after a three-day backup mailbox server located on the Late Paleolithic storage system, are very fond of accusing us of all mortal sins, referring to the obvious connection - the cluster collapsed during backup, which means the backup software is to blame. But, unfortunately, all the facts described in this article are confirmed by VMware itself. In an article placed in their KB, it is written in black and white - during consolidation of a snapshot, a loaded VM may stop responding to requests from outside. Typical consequences of this are a BSOD with a message about the loss of the system disk; if a VM was part of a cluster, then it is excluded from it, the cluster decays, or in the best case, you will simply see a very strong performance degradation (although this can be relatively successfully addressed by increasing RAM). And in the best practices it is not recommended to store snapshot for more than two days.
For our part, we also collected a selection of information on this topic in our HF article .
How we decided to fight it
Obviously, the bottleneck in this process is the internal speed of the storage system. Even in the morning it seemed that we had just a great drive, and by the evening we were forced to turn off production to reduce the load on the story, in the hope that this time it would be possible to remove the forgotten month ago, which had grown to hundreds of gigabytes (and VM performance dropped to a critical point).
At the beginning, a frontal attack option was tested - a parameter was introduced that directly limited the number of operations with storage systems. But this method had too many disadvantages inherent in static systems. And sometimes it came to a shot in the foot - young pioneers who love to keep backups on the same storage system where the VMs are located can reveal all possible ways to make backup even slower, and bring the host to panic.
Therefore, in the new version it was decided to completely abandon such a model and move on to dynamic processing of current I / O delays. At the global settings of the application, it looks like this:
Moreover, it should be noted that in addition to the global settings, you can set your own parameters for each specific data storage or volume, in the case of working with Hyper-V. But this is a licensing issue.
So consider the same proposed combination of parameters.
“ Stop assigning new tasks to datastore at: ” If during backup we see that the delay (IOPS latency) value has exceeded the allowed threshold, the VBR server will not create new file transfer streams until the storage performance returns to the acceptable level. Or simply put, we will not try to squeeze all the juice out of the storage, if it is heavily loaded enough.
“ Throttle I / O of existing tasks at: ” - is used if the backup task is already running, and there is a delay when accessing the disk caused by external load. For example, if during a backup, a SQL server starts up on one of the machines, creating an additional load on the same storage system, the VBR server will artificially reduce its own disk access rate so as not to interfere with the production system. When performance returns to the previous level, the VBR server will also automatically increase the data transfer rate. This item somehow complements the previous one. If, as a first measure, we simply cease to create additional workload, working at a certain steady-state level, then the second measure is reducing the intensity of operations already underway in favor of production systems.
An example of how these parameters are fulfilled is perfectly visible on this screenshot:
At the very beginning of the graph, the repository is in a state of “rest”, i.e. normal operating procedures occur. At 6:55 pm, a backup task was activated, which caused the expected increase in delays in read / write operations with pronounced peaks reaching 80 msec. Around 7:42 pm, the control mechanism was activated (the Enable checkbox), and, as we can see, the average value of read operation delays (green graph) is kept at 20 ms and grows only when the control mechanism is disabled (Disable mark).
I note that the default values of the thresholds of 20 and 30 ms are not taken from the ceiling, but as a result of the evaluation of monitoring data from many of our customers who kindly agreed to provide them. Thus, these values are perfect for most virtual environments.
Conclusion
Perhaps on this I will finish the description of this function. I tried to make it as accessible as possible, but if there are more questions, I will be happy to continue in the comments or through the PM.
Also do not hesitate to ask questions about our other products or their individual functions. I will try to answer everyone, but if I don’t succeed briefly, I’ll make a separate article.
Source: https://habr.com/ru/post/237137/
All Articles