We automate assembly of system
Peter Lukhin
Most people who learn about automatic assembly for the first time probably treat it with caution: excessive labor costs for its organization and maintenance are quite real, and instead they are offered only a phantom improvement in the development efficiency in the future. Those who know it firsthand are more optimistic, because they know that a number of problems when working with their system are much easier to avoid while they are not yet formed than when it is too late to change everything.
So how can auto assembly be so interesting, what possibilities can be realized with its help and what results can be achieved? Let's try to figure it out.
')

However, before examining it in detail, it is necessary to stipulate the following: the topic of assembly automation is quite extensive and there are a large number of articles on how to implement this or that task. At the same time, there is little where you can read, how to set it up in your home, with all the subtleties of the organization and a description of potential opportunities. Therefore, in this article I wanted to consider the automatic assembly from this point of view. If someone is interested in how this or that stage is actually implemented, then, if possible, links to additional materials or names of programs that can be used for this will be listed for each of them.
When developing software, one often encounters the fact that the time from making corrections to the source code to getting to the user strongly depends on many factors. To do this, you must first assemble the code in the form of libraries, then verify that they work, after which you install the installers and test the product after they are installed — all of these actions cannot be performed instantly; therefore, the timing of their implementation is determined by how they will be pass.
On the one hand, all the above steps sound quite reasonable: indeed, why give the user a product that will contain errors. However, in practice, the situation is aggravated by a constant lack of time and resources: error corrections should be published as soon as possible, but at the same time those responsible for the quality of the product or its assembly are very busy in other work on it where their presence is more necessary.
Therefore, periodically part of the steps for issuing corrections is skipped (for example, the compliance of the code with the design standard is not checked) or not fully implemented (for example, only the fact of error correction, but not its possible impact on other system functionality) is checked. As a result, the user gets either not well-tested or partially inoperative solution, and developers will subsequently have to deal with it and it is not known how long they will need it.
However, such problem situations can, if not bypass, then at least reduce their influence. Note that most of the steps are quite monotonous and more importantly, they are well algorithmizable. And, therefore - if you shift their execution to automation, then they will take less time and the chance to make a mistake when they are done or not to do something necessary is also minimized.
In order for the program to comply with all the requirements placed on it, you must first write them down in a form that will be understandable to the computer. Developers are engaged in similar transformation - as a result of their work and the source code appears. Depending on the approach used, it can be executed either immediately or after the compilation. One of the useful properties of such a view is that different people have the opportunity to modify the system independently of each other without direct communication throughout the development time. Unlike oral speech, the code is easier to work with, it is better preserved, and you can keep a history of changes for it. At the same time, a single design style and code structuring allows developers to think in a similar way, which also has a positive effect on the collaboration performance.
To simplify the storage of the source code and the work with it by many people, various version control systems are also helpful. For example, they include TFS, GIT or SVN. Their use in projects allows to reduce losses from such problems as:
With such centralized storage of the source code and its timely updating, you can not only not worry about any part of it being lost (provided that the storage itself is guaranteed), but more interestingly, it is possible to perform actions on it in automatic order.
Depending on the version of the storage system used, the way to launch them may differ: for example, periodic according to a predetermined schedule, or when making changes to the data itself. Usually, such automated sequences of actions are used to check the quality of the code without human intervention and the layout of the installers for transmission to users, so they are often simply called automatic assemblies.
A simple script that runs the operating system scheduler could serve as the basis for organizing their launch, tracking code changes and publishing the results, but it is better if a more specialized program does this. For example, when using TFS, a TFS Build Server might be a smart choice. Or you can use universal solutions like, for example: TeamCity, Hudson or CriuseControl.
What actions can be automated? In fact, they can be listed quite a lot:
This is only a part of what could really come in handy in your project - in fact, there are many such points.
But what exactly can be automated when there is only the source code of the program, even if it is stored centrally? Not much, since in this case it is possible to analyze only its files, which imposes its own limitations: either use only the simplest checks, or search and use third-party static code analyzers, or write your own. However, in this situation, you can benefit:
The results of this assembly stage can be interpreted differently: some of the checks are purely informational in nature (for example, statistics), the other indicates possible problems in the long term (for example, code design or static analyzer comments), the third one - to pass the assembly to whole (for example, the lack of files in the right places). Also, do not forget that the checks still take some time, sometimes significant, so in each case, you should prioritize: what is more important for you - the mandatory passing of all checks or the fastest response from the later stages of the assembly.
As can be seen from the above tasks of this stage, most of them are rather superficial (for example, collecting statistics or checking for files), therefore, to implement them, it will be easier to write your own utilities or scripts for testing, rather than look for ready-made ones. The other one, on the contrary, allows analyzing the internal logic of the code itself, which is much harder, therefore, it is preferable to use third-party solutions for this. For example, for static analysis you can try to connect: PVS-Studio, Cppcheck, RATS, Graudit, or look for something in other sources ( http://habrahabr.ru/post/75123/ , https://ru.wikipedia.org / wiki / Static_analysis_code ).
However, processing information about source files for an assembly is usually not its immediate goal. Therefore, the next step is to compile the program code into a set of libraries that implement the logic of operation described in it. If it will not be possible to execute it, then with automatic assembly this fact will become clear soon after its launch, and not after a few days, when the assembled version is required. Especially well the effect is observed when the assembly starts immediately after the publication of inoperative code, obtained as a result of combining several edits.
A little running ahead, I want to note another fact. It lies in the fact that the more additional logic you implement in the build process, the longer it will be executed, which is not surprising. Therefore, it would be a logical step to organize them so that they are executed only for code that has actually changed. How this can be done: most likely, the code of your product is not a single inseparable entity - if so, then either your project is still quite small, or it is a tightly intertwined bundle of interconnections that worsen the process of its understanding not only to outsiders, but also to the developers themselves .
To do this, the project should be divided into separate independent modules: for example, server application, client application, shared libraries, external assembled components. The more such modules, the more flexible will be the development and further deployment of the system, but you should not get carried away and break too much - the smaller such parts will be, the more organizational problems will have to be solved when you make changes to several of them at the same time.
What are these problems? Splitting a project into independent modules implies that it is not necessary to make changes to the others for the normal development of one of them. For example, if you need to change the way information is received from the user in the graphical interface of the client application, then there is absolutely no need to make changes to the server code. This means that it would be a reasonable solution to limit those involved in the client only to the source code related to it, and replace all modules related to the modules used by them with their ready and tested versions in the form of assembled libraries. Accordingly, what advantages will we get in this case:
As a result, the assembly will take place much faster than if it consistently collected and tested all the components, which means that it will be possible to quickly find out whether errors were introduced by current fixes or not. However, for such benefits you will have to pay additional overhead for the organization of work with the modular structure of the system:
Implement the partitioning of the system into modules can be different. Someone is enough to divide the code into several independent projects or solutions, someone prefers to use sub-modules in the GIT or something similar. However, what method of organization would you choose: whether it is one sequential build or optimized for working with modules - as a result of compiling the code you will receive a set of libraries with which you can already work in principle, and also, which is a more interesting fact - which you can test in automatic mode.
When there is a need to write any program, then immediately the question arises - how to check that the assembled version meets all the requirements. Well, if their number is small - in this case, you can view everything and base your decision on the result of their verification. However, this is usually not at all the case - there are so many possible ways to use the program that it is difficult to even describe everything, not something to check.
Therefore, another test method is often taken as a reference — the system is considered to have passed it if it successfully passes fixed scenarios, that is, predefined predefined sequences of actions selected as the most common among users when working with the system. The method is quite reasonable, because if the errors are still found in the released version, then those that interfere with most people will be more critical, and manifesting only occasionally in rarely used functionality will turn out to be of lower priority.
How, then, is testing performed in this case: the system ready for deployment is passed to testers for one purpose - so that they try to go through all the predefined scenarios of working with it and inform the developers if they have encountered any errors and whether something was found not directly related to scripts. At the same time, such testing may take several days, even if there are several testers.
The errors found and observations made during testing have the most direct effect on the time it is held: if errors are not found, then it will be needed less, if vice versa, they can significantly increase it due to the long definition of conditions for the reproduction of errors or ways to circumvent them, so that you could test the rest of the scripts. Therefore, a good option would be the one in which the testing would have as few comments as possible, and it could have ended faster without losing the quality of the test.
Part of the errors that can be introduced into the source code reveals the process of its compilation. But he does not guarantee that the program will work stably and fulfill all the requirements for it. Errors, which in principle can be contained in it, can be divided according to the complexity of their identification and correction into the following categories:
Typically, checks at this level are implemented using unit tests and integration tests. Ideally, for each method of the program there should be a set of certain checks, but it is often problematic to do this: either because of the dependence of the code being checked on the environment in which it is to be performed, or because of the extra effort required to create and maintain them.
However, if you allocate sufficient resources to build and maintain the infrastructure of the automatic testing of the libraries you collect, you can ensure that low-level errors are detected before the version gets to the testers. And this in turn means that they will rarely stumble upon obvious program errors and crashes and, therefore, check the system faster without loss of quality.
After the build passes the library testing stage, the following can be said about the resulting system:
Thus, it turns out that at this stage a sufficiently large number of errors have already been swept aside, so the following actions can be taken with this fact in mind. What can be done next:
Here it is worth mentioning the priorities. What is more important for your system: its performance or compliance with the accepted rules of development? The following options are possible:
However, it should be understood that, in any case, the assembly should be understood to be successfully completed only during the passage of all its stages - prioritization in this case speaks only about what should be emphasized in the first place. For example, the documentation assembly can be brought out to the stage after the installers are assembled, so that they can be obtained as early as possible, and also so that if they cannot be formed, the documentation does not even attempt to assemble.
To build documentation in .NET projects it is very convenient to use the program SandCastle (article about using: http://habrahabr.ru/post/102177/ ). It is possible that for other programming languages you can also find something similar.
After going through the testing phase of libraries, there are two main areas for further building performance. And if one of them is to check its compliance with certain technical requirements or to assemble documentation, the other is to prepare a version for distribution.
The internal organization of the development of the system is usually of little interest to the end user, since all that matters to him is whether he can install it on his computer, whether it will update correctly, whether it will provide the declared functionality and whether there will be any additional problems when using it .
Therefore, to achieve this goal, it is necessary to obtain from the set of disparate libraries what can be transferred to it. However, their successful formation still does not mean that everything is in order - they can and should be tested again, but this time, trying to perform actions not as a computer, but as the user himself performed them.
There are quite a few ways to build installers: for example, you can use the standard installer project in Visual Studio or create it in InstallShield. About many other options you can read on IXBT ( http://www.ixbt.com/soft/installers-1.shtml , http://www.ixbt.com/soft/installers-2.shtml , http: // www .ixbt.com / soft / installers-3.shtml ).
It is possible to check the performance of the system in different ways: first, during the testing of libraries, individual nodes are checked, the final decision is made by testers.However, there is an opportunity to further simplify their work - try to automatically walk through the main chains of working with the system and perform all the actions that the user could perform in real use.
Such automatic testing is often referred to as interface, because during its execution, everything that ordinary people would have on a computer screen: window display, handling mouse-hover events, typing text into input fields, and so on. On the one hand, this gives a high degree of verification of the system’s performance - the main scenarios and requirements for it are described in the users' language and therefore can be written in the form of automated algorithms, however, additional difficulties appear here:
Summing up all these remarks, we can come to the following conclusion: interface testing will help to ensure that all the test requirements are met exactly as they were formulated, and all checks, even despite the time costs, will be performed faster than if they were performed by testers. . However, you have to pay for everything: in this case, you will have to pay labor for maintaining the infrastructure of interface tests, and be prepared for what they often do not pass.
If such difficulties do not stop you, then it makes sense to pay attention to the following tools with which you can organize interface testing: for example, TestComplete, Selenium, HP QuickTest, IBM Rational Robot or UI Automation.
What is the result in the end? In the presence of a centralized source code repository, it is possible to run automatic assemblies: according to a schedule or at the time of making changes. In this case, some set of actions will be performed, the results of which will be:
Thus, we can say the following: automatic assembly allows you to remove a huge layer of work from the developers and testers of the system, and all this will be done without user intervention in the background. You can submit your corrections to the central repository and know that after some time everything will be ready for the transfer of the version to the user or for final testing and not worry about all intermediate steps - or at least find out that the edits were incorrect , As soon as possible.
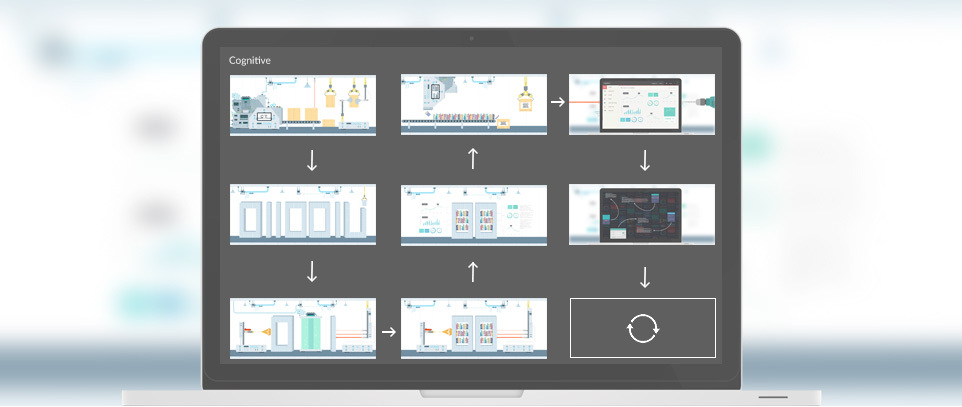
Finally, I would like to touch on what is called continuous integration. The main principle of this approach is that after making corrections, you can as soon as possible find out whether the changes lead to errors or not. In the presence of an automatic assembly, it is quite simple to do this, because it alone is almost what this principle implements - its only bottleneck is the transit time.
If we consider all the stages, as they were described above, it becomes clear that some of their components on the one hand take quite a long time (for example, static code analysis or documentation assembly), and on the other, they manifest themselves only in the long term. Therefore, it would be reasonable to redistribute parts of an automatic assembly so that what is guaranteed to prevent the release of the version (the impossibility of compiling code, falling in tests) would be checked as soon as possible. For example, you can first build libraries, run tests over them and get installers, and postpone static code analysis, documentation assembly and interface testing to a later time.
As for the errors that occur during assembly work, they can be divided into two groups: critical for it and non-critical. The first can be attributed to those stages, the negative result of which would make it impossible to run the next ones. For example, if the code is not compiled, then why run the tests, and if they did not pass, then there is no need to collect documentation. Such an early interruption of assembly processes allows you to complete them as early as possible so as not to overload the computers on which they are running. If the negative result of the stage is also the result (for example, the design of the code not according to the standard does not prevent the installers from being given to the user), then it makes sense to take this into account upon further study, but do not stop the assembly.
As described above, a fairly large number of actions during the assembly of the system can be shifted to automation: the fewer monotonous tasks people will perform, the more effective their work will be. However, for completeness of the article, the theoretical part alone would not be enough - if you don’t know if all this is feasible in practice, then it’s not clear how much effort it will take to set up the automatic assembly yourself.
This article was not written from scratch. For several years, our company has repeatedly had to deal with the problems of optimizing the efficiency of developing and testing software products. As a result, the most frequent of them were brought together, summarized, supplemented by ideas and considerations and decorated in the form of an article. At the moment, automatic assemblies are most actively used in the development and testing of the EF EVFRAT electronic document management system. From a practical point of view, how exactly the principles described in the article are implemented when it was created might be quite useful for reference, but it would be better to write a separate article on this topic than to try to complement the current one.
Most people who learn about automatic assembly for the first time probably treat it with caution: excessive labor costs for its organization and maintenance are quite real, and instead they are offered only a phantom improvement in the development efficiency in the future. Those who know it firsthand are more optimistic, because they know that a number of problems when working with their system are much easier to avoid while they are not yet formed than when it is too late to change everything.
So how can auto assembly be so interesting, what possibilities can be realized with its help and what results can be achieved? Let's try to figure it out.
')
Part 0: Instead of an introduction
However, before examining it in detail, it is necessary to stipulate the following: the topic of assembly automation is quite extensive and there are a large number of articles on how to implement this or that task. At the same time, there is little where you can read, how to set it up in your home, with all the subtleties of the organization and a description of potential opportunities. Therefore, in this article I wanted to consider the automatic assembly from this point of view. If someone is interested in how this or that stage is actually implemented, then, if possible, links to additional materials or names of programs that can be used for this will be listed for each of them.
When developing software, one often encounters the fact that the time from making corrections to the source code to getting to the user strongly depends on many factors. To do this, you must first assemble the code in the form of libraries, then verify that they work, after which you install the installers and test the product after they are installed — all of these actions cannot be performed instantly; therefore, the timing of their implementation is determined by how they will be pass.
On the one hand, all the above steps sound quite reasonable: indeed, why give the user a product that will contain errors. However, in practice, the situation is aggravated by a constant lack of time and resources: error corrections should be published as soon as possible, but at the same time those responsible for the quality of the product or its assembly are very busy in other work on it where their presence is more necessary.
Therefore, periodically part of the steps for issuing corrections is skipped (for example, the compliance of the code with the design standard is not checked) or not fully implemented (for example, only the fact of error correction, but not its possible impact on other system functionality) is checked. As a result, the user gets either not well-tested or partially inoperative solution, and developers will subsequently have to deal with it and it is not known how long they will need it.
However, such problem situations can, if not bypass, then at least reduce their influence. Note that most of the steps are quite monotonous and more importantly, they are well algorithmizable. And, therefore - if you shift their execution to automation, then they will take less time and the chance to make a mistake when they are done or not to do something necessary is also minimized.
Part 1: Code
In order for the program to comply with all the requirements placed on it, you must first write them down in a form that will be understandable to the computer. Developers are engaged in similar transformation - as a result of their work and the source code appears. Depending on the approach used, it can be executed either immediately or after the compilation. One of the useful properties of such a view is that different people have the opportunity to modify the system independently of each other without direct communication throughout the development time. Unlike oral speech, the code is easier to work with, it is better preserved, and you can keep a history of changes for it. At the same time, a single design style and code structuring allows developers to think in a similar way, which also has a positive effect on the collaboration performance.
To simplify the storage of the source code and the work with it by many people, various version control systems are also helpful. For example, they include TFS, GIT or SVN. Their use in projects allows to reduce losses from such problems as:
- Receiving several variants of the same code when editing a file with several people
- The loss of the source code of any important component during the move or due to the forgetfulness of one of the employees
- Search the author of the functionality in which an error was found or in which it is necessary to make improvements
With such centralized storage of the source code and its timely updating, you can not only not worry about any part of it being lost (provided that the storage itself is guaranteed), but more interestingly, it is possible to perform actions on it in automatic order.
Depending on the version of the storage system used, the way to launch them may differ: for example, periodic according to a predetermined schedule, or when making changes to the data itself. Usually, such automated sequences of actions are used to check the quality of the code without human intervention and the layout of the installers for transmission to users, so they are often simply called automatic assemblies.
A simple script that runs the operating system scheduler could serve as the basis for organizing their launch, tracking code changes and publishing the results, but it is better if a more specialized program does this. For example, when using TFS, a TFS Build Server might be a smart choice. Or you can use universal solutions like, for example: TeamCity, Hudson or CriuseControl.
Part 2: Code Testing
What actions can be automated? In fact, they can be listed quite a lot:
- Layout of installers - it is usually the system itself that is interesting to users of the system, and not how it was written or compiled, which means that they should be able to install it
- Update generation - if your system supports the update technology, then a good option would be not only to get full-fledged installers, but also a set of incremental patches to quickly switch from one version to another
- System testing - users should receive only those versions that are stable and implement the required functionality, so they need to be checked, and some of the checks can be passed on to automation.
- Documentation - this action may be useful, as if you give the external API of the system to third-party developers, and in internal development, because the larger the system and the more code it contains, the fewer people who know it thoroughly
- Version compatibility check - if we compare different versions of the libraries we collect, we can notice in time when the external API available in each module undergoes changes: if something in it ceases to be visible from the outside - the modules or programs using it may be incompatible with the new version; and vice versa - an excessive number of functions not registered in the API documentation suggests that either they need to be added to it or hidden from prying eyes
- Checking the adopted rules and standards - when the code is designed in the same way, then any of the system developers will be able to navigate freely in it. If, when searching for something, it is not found in the expected place or is recorded in a non-standard form, then even if the search is found or thoughtful, additional time will be spent on this, which could have been avoided.
- Testing the assembly itself is quite unpleasant when, after a long use of the automatic assembly, it becomes apparent that it did not exactly what it was intended for: for example, not all tests were started due to the fact that they were not found, or were not performed in it assembling the documentation of a rarely used module that was suddenly urgently needed
This is only a part of what could really come in handy in your project - in fact, there are many such points.
But what exactly can be automated when there is only the source code of the program, even if it is stored centrally? Not much, since in this case it is possible to analyze only its files, which imposes its own limitations: either use only the simplest checks, or search and use third-party static code analyzers, or write your own. However, in this situation, you can benefit:
- You can check the presence of files or directories, their naming methods, nesting rules: this is unlikely to be useful to most developers, but sometimes there are similar situations
- Analyze the contents of the source code files to verify compliance with accepted standards: for example, for some time it was common to place a multi-line comment describing the functionality and indicating the author at the beginning of each file
- Check compliance with the requirements for files by external applications: for example, if you plan to run tests in the future, you need to make sure that the file containing their description is set up correctly and tests can detect the libraries being checked when they start.
- Static code analysis - when developers make mistakes in the program due to carelessness, there are cases in which such flaws are not detected even by tests and only a close examination of the source code helps to find them. External analyzers allow to detect such situations automatically, which greatly simplifies the development
- Collection of various statistics: the number of lines in the code files, whether there are completely coincident pieces of functions, the most editable files are not the most important information, but sometimes it gives an opportunity to look at the project a little differently
The results of this assembly stage can be interpreted differently: some of the checks are purely informational in nature (for example, statistics), the other indicates possible problems in the long term (for example, code design or static analyzer comments), the third one - to pass the assembly to whole (for example, the lack of files in the right places). Also, do not forget that the checks still take some time, sometimes significant, so in each case, you should prioritize: what is more important for you - the mandatory passing of all checks or the fastest response from the later stages of the assembly.
As can be seen from the above tasks of this stage, most of them are rather superficial (for example, collecting statistics or checking for files), therefore, to implement them, it will be easier to write your own utilities or scripts for testing, rather than look for ready-made ones. The other one, on the contrary, allows analyzing the internal logic of the code itself, which is much harder, therefore, it is preferable to use third-party solutions for this. For example, for static analysis you can try to connect: PVS-Studio, Cppcheck, RATS, Graudit, or look for something in other sources ( http://habrahabr.ru/post/75123/ , https://ru.wikipedia.org / wiki / Static_analysis_code ).
Part 3: Build
However, processing information about source files for an assembly is usually not its immediate goal. Therefore, the next step is to compile the program code into a set of libraries that implement the logic of operation described in it. If it will not be possible to execute it, then with automatic assembly this fact will become clear soon after its launch, and not after a few days, when the assembled version is required. Especially well the effect is observed when the assembly starts immediately after the publication of inoperative code, obtained as a result of combining several edits.
A little running ahead, I want to note another fact. It lies in the fact that the more additional logic you implement in the build process, the longer it will be executed, which is not surprising. Therefore, it would be a logical step to organize them so that they are executed only for code that has actually changed. How this can be done: most likely, the code of your product is not a single inseparable entity - if so, then either your project is still quite small, or it is a tightly intertwined bundle of interconnections that worsen the process of its understanding not only to outsiders, but also to the developers themselves .
To do this, the project should be divided into separate independent modules: for example, server application, client application, shared libraries, external assembled components. The more such modules, the more flexible will be the development and further deployment of the system, but you should not get carried away and break too much - the smaller such parts will be, the more organizational problems will have to be solved when you make changes to several of them at the same time.
What are these problems? Splitting a project into independent modules implies that it is not necessary to make changes to the others for the normal development of one of them. For example, if you need to change the way information is received from the user in the graphical interface of the client application, then there is absolutely no need to make changes to the server code. This means that it would be a reasonable solution to limit those involved in the client only to the source code related to it, and replace all modules related to the modules used by them with their ready and tested versions in the form of assembled libraries. Accordingly, what advantages will we get in this case:
- The assembly of a specific module will not assemble the dependent components related to it if no changes were made to them.
- There is no need to check the quality of the internal logic of the operation of dependent modules, since they are already considered to be sufficiently tested.
As a result, the assembly will take place much faster than if it consistently collected and tested all the components, which means that it will be possible to quickly find out whether errors were introduced by current fixes or not. However, for such benefits you will have to pay additional overhead for the organization of work with the modular structure of the system:
- If the changes to the functionality affect several modules, rather than one, then it will be necessary to determine in which order they should be executed, and only then proceed to compile. It would be nice if such a definition could occur in automatic mode.
- The assembly of each individual module must guarantee not only its working capacity, but also ensure the working capacity of the modules dependent on it. To solve this problem, you can provide fixed interfaces that the module must implement and which will be present in each of its versions. This can be quite problematic, but in large or highly distributed projects, such work is still preferable to correcting compatibility errors that might otherwise occur.
Implement the partitioning of the system into modules can be different. Someone is enough to divide the code into several independent projects or solutions, someone prefers to use sub-modules in the GIT or something similar. However, what method of organization would you choose: whether it is one sequential build or optimized for working with modules - as a result of compiling the code you will receive a set of libraries with which you can already work in principle, and also, which is a more interesting fact - which you can test in automatic mode.
Part 4: Library Testing
When there is a need to write any program, then immediately the question arises - how to check that the assembled version meets all the requirements. Well, if their number is small - in this case, you can view everything and base your decision on the result of their verification. However, this is usually not at all the case - there are so many possible ways to use the program that it is difficult to even describe everything, not something to check.
Therefore, another test method is often taken as a reference — the system is considered to have passed it if it successfully passes fixed scenarios, that is, predefined predefined sequences of actions selected as the most common among users when working with the system. The method is quite reasonable, because if the errors are still found in the released version, then those that interfere with most people will be more critical, and manifesting only occasionally in rarely used functionality will turn out to be of lower priority.
How, then, is testing performed in this case: the system ready for deployment is passed to testers for one purpose - so that they try to go through all the predefined scenarios of working with it and inform the developers if they have encountered any errors and whether something was found not directly related to scripts. At the same time, such testing may take several days, even if there are several testers.
The errors found and observations made during testing have the most direct effect on the time it is held: if errors are not found, then it will be needed less, if vice versa, they can significantly increase it due to the long definition of conditions for the reproduction of errors or ways to circumvent them, so that you could test the rest of the scripts. Therefore, a good option would be the one in which the testing would have as few comments as possible, and it could have ended faster without losing the quality of the test.
Part of the errors that can be introduced into the source code reveals the process of its compilation. But he does not guarantee that the program will work stably and fulfill all the requirements for it. Errors, which in principle can be contained in it, can be divided according to the complexity of their identification and correction into the following categories:
- Trivial errors - these include, for example, typos in messages or minor adjustments. Often, more time is spent on delivering information to the developer than on the fix itself. Automation of checks for such errors is possible, but usually not worth it to implement
- Errors of individual parts of the code - may occur if the developer has not foreseen all possible uses of his methods, as a result of which they turn out to be inoperable or return an unexpected result. Unlike other situations, such errors may well be detected automatically - when writing, the developer usually understands how his code will be used, and therefore, can describe it in the form of checks
- Errors of interaction between parts of the code - if the development of each particular part is usually done by one person, then when there are many parts, then understanding the principles of their joint work is also some common knowledge. In this case, it is somewhat more difficult to determine all the uses of the code, however, with proper elaboration, such situations can also be arranged in the form of automatic checks, however, only for some scenarios of its operation.
- Errors of logic - they are errors of non-conformity of the program’s work with the requirements imposed on it. It is rather difficult to describe them in the form of automated checks, since they and the checks themselves are formulated in different terminology. Therefore, errors of this kind are best identified by manual testing.
Typically, checks at this level are implemented using unit tests and integration tests. Ideally, for each method of the program there should be a set of certain checks, but it is often problematic to do this: either because of the dependence of the code being checked on the environment in which it is to be performed, or because of the extra effort required to create and maintain them.
However, if you allocate sufficient resources to build and maintain the infrastructure of the automatic testing of the libraries you collect, you can ensure that low-level errors are detected before the version gets to the testers. And this in turn means that they will rarely stumble upon obvious program errors and crashes and, therefore, check the system faster without loss of quality.
Part 5: Library Analysis
After the build passes the library testing stage, the following can be said about the resulting system:
- In addition to the source code of the program, compiled libraries are also available for subsequent steps.
- There is some formal way of testing part of the functionality, and it has been successfully completed.
Thus, it turns out that at this stage a sufficiently large number of errors have already been swept aside, so the following actions can be taken with this fact in mind. What can be done next:
- For example, the assembly of documentation: the operation is not fast and is needed only for the released versions, so if there are obvious program errors, it would be rather pointless to form it
- Since all collected libraries are available for analysis, you can check the compatibility of versions: for example, make sure that all the declared external API methods are available for use and vice versa - whether something that was not specified is closed
Here it is worth mentioning the priorities. What is more important for your system: its performance or compliance with the accepted rules of development? The following options are possible:
- If getting a program by a user is more important than simplifying its support, then it makes sense to concentrate on assembling and checking installers.
- If it is important that the program always meets the stated requirements and does not have undocumented API capabilities, then the analysis of the libraries will be of higher priority.
However, it should be understood that, in any case, the assembly should be understood to be successfully completed only during the passage of all its stages - prioritization in this case speaks only about what should be emphasized in the first place. For example, the documentation assembly can be brought out to the stage after the installers are assembled, so that they can be obtained as early as possible, and also so that if they cannot be formed, the documentation does not even attempt to assemble.
To build documentation in .NET projects it is very convenient to use the program SandCastle (article about using: http://habrahabr.ru/post/102177/ ). It is possible that for other programming languages you can also find something similar.
Part 6: Building Installers and Updates
After going through the testing phase of libraries, there are two main areas for further building performance. And if one of them is to check its compliance with certain technical requirements or to assemble documentation, the other is to prepare a version for distribution.
The internal organization of the development of the system is usually of little interest to the end user, since all that matters to him is whether he can install it on his computer, whether it will update correctly, whether it will provide the declared functionality and whether there will be any additional problems when using it .
Therefore, to achieve this goal, it is necessary to obtain from the set of disparate libraries what can be transferred to it. However, their successful formation still does not mean that everything is in order - they can and should be tested again, but this time, trying to perform actions not as a computer, but as the user himself performed them.
There are quite a few ways to build installers: for example, you can use the standard installer project in Visual Studio or create it in InstallShield. About many other options you can read on IXBT ( http://www.ixbt.com/soft/installers-1.shtml , http://www.ixbt.com/soft/installers-2.shtml , http: // www .ixbt.com / soft / installers-3.shtml ).
Part 7: Interface Testing
It is possible to check the performance of the system in different ways: first, during the testing of libraries, individual nodes are checked, the final decision is made by testers.However, there is an opportunity to further simplify their work - try to automatically walk through the main chains of working with the system and perform all the actions that the user could perform in real use.
Such automatic testing is often referred to as interface, because during its execution, everything that ordinary people would have on a computer screen: window display, handling mouse-hover events, typing text into input fields, and so on. On the one hand, this gives a high degree of verification of the system’s performance - the main scenarios and requirements for it are described in the users' language and therefore can be written in the form of automated algorithms, however, additional difficulties appear here:
- : , – , , ,
- , : , , , , , , .
Summing up all these remarks, we can come to the following conclusion: interface testing will help to ensure that all the test requirements are met exactly as they were formulated, and all checks, even despite the time costs, will be performed faster than if they were performed by testers. . However, you have to pay for everything: in this case, you will have to pay labor for maintaining the infrastructure of interface tests, and be prepared for what they often do not pass.
If such difficulties do not stop you, then it makes sense to pay attention to the following tools with which you can organize interface testing: for example, TestComplete, Selenium, HP QuickTest, IBM Rational Robot or UI Automation.
Part 8: Posting Results
What is the result in the end? In the presence of a centralized source code repository, it is possible to run automatic assemblies: according to a schedule or at the time of making changes. In this case, some set of actions will be performed, the results of which will be:
- Installers and system updates are usually the main goal of the assembly, because in the end they will be passed to the user.
- Test results - automated assembly allows you to learn about a fairly large layer of errors even before the version is given to testers
- Documentation - may be useful both to the system developers themselves and those who will integrate with it.
- Compatibility Check Results - allows you to make sure that unknown to you improvements to the system will work with the new version
Thus, we can say the following: automatic assembly allows you to remove a huge layer of work from the developers and testers of the system, and all this will be done without user intervention in the background. You can submit your corrections to the central repository and know that after some time everything will be ready for the transfer of the version to the user or for final testing and not worry about all intermediate steps - or at least find out that the edits were incorrect , As soon as possible.
Part 9: Optimization
Finally, I would like to touch on what is called continuous integration. The main principle of this approach is that after making corrections, you can as soon as possible find out whether the changes lead to errors or not. In the presence of an automatic assembly, it is quite simple to do this, because it alone is almost what this principle implements - its only bottleneck is the transit time.
If we consider all the stages, as they were described above, it becomes clear that some of their components on the one hand take quite a long time (for example, static code analysis or documentation assembly), and on the other, they manifest themselves only in the long term. Therefore, it would be reasonable to redistribute parts of an automatic assembly so that what is guaranteed to prevent the release of the version (the impossibility of compiling code, falling in tests) would be checked as soon as possible. For example, you can first build libraries, run tests over them and get installers, and postpone static code analysis, documentation assembly and interface testing to a later time.
As for the errors that occur during assembly work, they can be divided into two groups: critical for it and non-critical. The first can be attributed to those stages, the negative result of which would make it impossible to run the next ones. For example, if the code is not compiled, then why run the tests, and if they did not pass, then there is no need to collect documentation. Such an early interruption of assembly processes allows you to complete them as early as possible so as not to overload the computers on which they are running. If the negative result of the stage is also the result (for example, the design of the code not according to the standard does not prevent the installers from being given to the user), then it makes sense to take this into account upon further study, but do not stop the assembly.
Part 10: Conclusion
As described above, a fairly large number of actions during the assembly of the system can be shifted to automation: the fewer monotonous tasks people will perform, the more effective their work will be. However, for completeness of the article, the theoretical part alone would not be enough - if you don’t know if all this is feasible in practice, then it’s not clear how much effort it will take to set up the automatic assembly yourself.
This article was not written from scratch. For several years, our company has repeatedly had to deal with the problems of optimizing the efficiency of developing and testing software products. As a result, the most frequent of them were brought together, summarized, supplemented by ideas and considerations and decorated in the form of an article. At the moment, automatic assemblies are most actively used in the development and testing of the EF EVFRAT electronic document management system. From a practical point of view, how exactly the principles described in the article are implemented when it was created might be quite useful for reference, but it would be better to write a separate article on this topic than to try to complement the current one.
Source: https://habr.com/ru/post/236329/
All Articles