FlexiCapture. Is it as flexible as it is called?
 Experience shows that the FlexiCapture product is known to ordinary users outside the company very little (“Is this the Unified State Examination?”), Despite the fact that it is used in many large organizations. You can put up with it, considering that the product is not for the end user, but corporate. And you can periodically talk about it all that will not only be useful to those who are already familiar with it, but also hints to people far from the product that Flex is not just 4 letters in the name.
Experience shows that the FlexiCapture product is known to ordinary users outside the company very little (“Is this the Unified State Examination?”), Despite the fact that it is used in many large organizations. You can put up with it, considering that the product is not for the end user, but corporate. And you can periodically talk about it all that will not only be useful to those who are already familiar with it, but also hints to people far from the product that Flex is not just 4 letters in the name.Our partners from the Novosibirsk company ATAPI Software shared their techniques for handling various complex cases. This is a set of specific practical advice that we hope will be useful to you. In addition, each of these stories is similar to a Zen koan — it helps to reveal the true nature of FlexiCapture in all its diversity.
When processing custom tables, be as serene as a lotus flower
The main purpose of ABBYY FlexiCapture is to extract certain data from documents and enter them into the information system. In Russia, most of the documents are unified, so usually it does not cause difficulties. Unfortunately, this cannot be said about foreign documents — say, European invoices — and some Russian forms are “annealed” as well as their foreign counterparts. Often there are cases when the necessary information in the tables is not clearly defined, for example, like this:

')
Here in the table there are two lines with the description of commodity items. If the automatic method is used to recognize such a document, the item number (the leftmost field) will fall into a separate column and will be recognized correctly, but the quantity and article fields (the third column) will fall into the same column, although in our table these are different fields. In addition, a lot of unnecessary textual information can get into the columns - this will create problems during verification.
You can divide the desired data into separate fields using the functionality of the repeating group. In Flexilayout Studio we create an element of the type “repeating group” (Repeating Group). Each instance of the group will correspond to the row of the table, within the region of which the search is already organized using simple elements (such as Static Text, Character String, Region, etc.). In turn, the area of each line can also be allocated with the help of a repeating group that precedes the search for information directly.
This is perhaps the best solution for such cases. However, we must not forget that in addition to the actual recognition, we need to bring the data from this not quite standard table to the usual tabular form:

Why do you need it? Verification operators are easier to process data when they are presented in a table. In addition, it often happens that standard and non-standard tables are sent for verification one after another, and if you make a separate template for each case, it will be difficult for the operator to switch from one way of presenting data to another - therefore he will inevitably start making mistakes.
And one moment. The following example shows that it is not very convenient to represent complex non-standard tables in the form of a repeating group in an interface — such a representation takes up a lot of space.
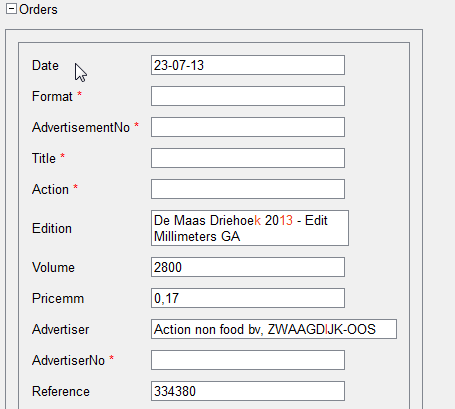
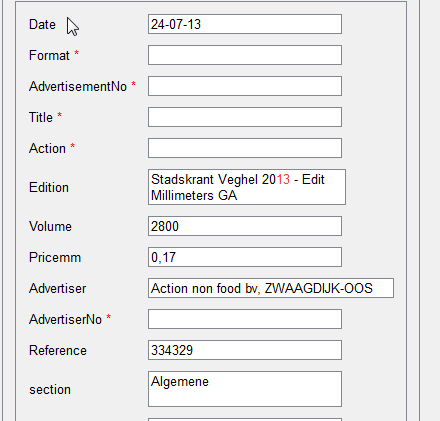
Compare this with the representation of similar data in a table:

As we see, in this form (as a table), data takes up much less space, and the operator has the opportunity to check documents faster - without wasting time scrolling.
To speed up the verification process and make it uniform, we use the following approach:
- At the level of flexible description, we search for the necessary data using a repeating group, thus finding the regions of individual rows. Then, within the region of each line, we extract the required fields.
- Next, create a dummy table with the same number of rows as in the repeating group. A dummy table is a table that is superimposed in an arbitrary region, that is, it is present on the data form, but not tied to a specific document image.
- In the FlexiCapture project, in the document definition settings, we write a simple script rule — it will copy the values from the fields that the system finds in the repeating group into the corresponding columns of the table.
- The fields themselves on the data form can be hidden, since all information will now be stored and displayed in a table.
Avoid grazing the tiger by improving tabular data recognition.
When working with tables, a developer's karma is a large number of different text "garbage" in data cells. For example, we need to extract the numerical value of the OKVED code and the date of entering the information in the Unified State Register of Legal Entities from the following table:

If you make a simple table, then a textual description of the type of activity (“Renting your own real estate”) will fall into the code cell, which will need to be deleted either by the developer using a script or manually by the operator each time. In addition, blots, notes, stamps, signatures, etc. may also fall into the region of the table.
To prevent such extra information from interfering with recognition, we can filter these objects at the level of a flexible description — set the rules by which the system will automatically find them and ignore them during recognition. In the case of our example, it will suffice to configure the “ignore” of all text objects with Russian letters and brackets.
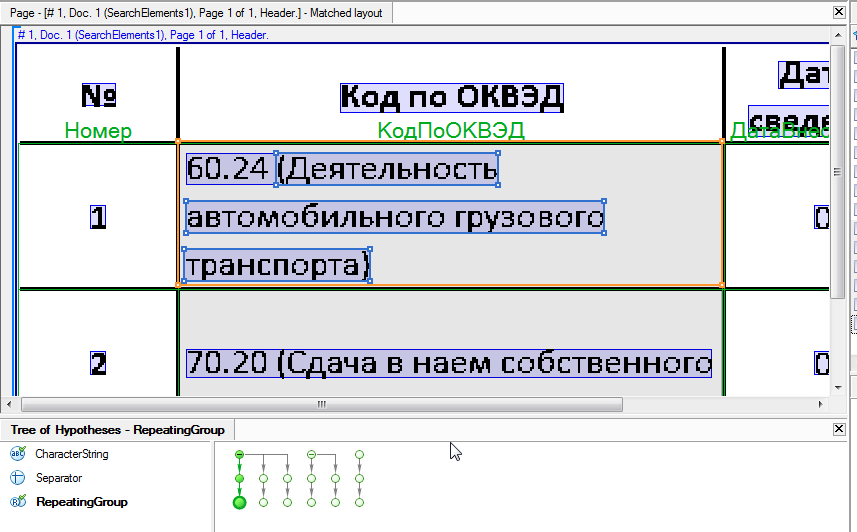
As you can see in the figure below, in FlexiCapture 10 this field will be excluded from the recognition area (rectangles with gray hatching).

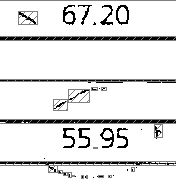
Or you can go from the opposite - first, using the repeating group, find only the data we need (numeric codes), and then exclude all text or other image objects from the “OKVED code” column that are distinct from the code itself from recognition.
Examples of such approaches are presented in the picture below: on the left we excluded the fixed text of the MACHINE REAMER 600 by the first method, and on the right - all but the numbers by the second method:

Set up a variation field recognition - let the mirror of the mind separate the beautiful from the not so
It so happens that the format of the same field is very different in the same type of documents. For example, in foreign invoices can be found as ordinary black text on a white background, and white text on a black background. We can see a similar situation in the forms of various questionnaires, questionnaires, etc.


But it also happens that the template is one, but in reality the documents are mixed up for recognition - in some the data is imprinted on the printer, and in others written by a person in the so-called handwritten way.


Not less incidents causes a different data format in the same fields. If one document contains the date in the format February 23, 2006, and the other - on 24/11/08, the person will understand, and it is advisable for the program to specify different settings for this field.


All of these cases can cause problems with recognition. ABBYY FlexiCapture allows you to create two separate fields and set them to different recognition settings: inverted or plain text, typed or handwritten, recognition in the common frame or drawing a separate frame for each character. Then, when processing each document, the operator manually selects the correct option for the field.
But you can still slightly improve the recognition process. The first option is to process documents in different types of packages. But this is also quite inconvenient, since it is necessary to separate documents at the scanning stage, and the operators may eventually get confused about where to send which document. Why load the operator with extra work, when the program can cope with this task?
We used the following algorithm. In the place where we should have the desired text, we create three fields:
- the first is a hidden field from the user that recognizes plain text,
- the second is also a hidden field that recognizes the text as inverted,
- the third is the field visible to the user, in which the operator is submitted for verification to one of the recognition results that the system evaluates to be the best.
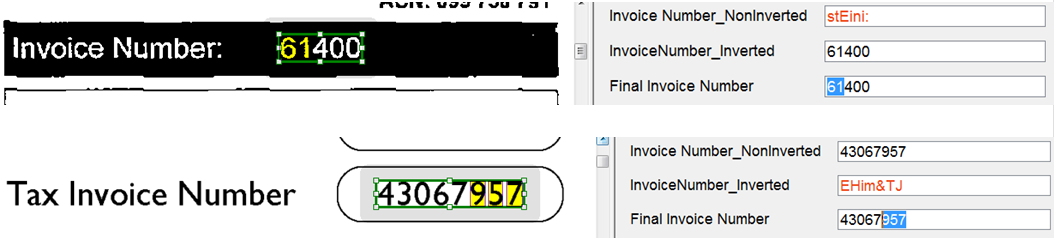
The system can choose the best result, for example, based on the number of so-called “suspicious characters” (Suspicious Symbols) - to do this, create a script rule that passes the field value with the least number of “suspicious characters” as a result of recognition.
A similar approach with three fields and the choice of the best recognition option can be used for cases of different markup or typed / handwritten text in one field.
How to return everything to a single: the allocation of the fractional part of numbers
It would seem, what problem can be with fractions? The same numbers and commas. But sometimes fractional separators are not recognized or disappear during scanning, which can lead to unpleasant consequences. For example, the total amount in a paper invoice is one, and in the electronic one another (in it there appear a couple of extra zeros). This happens, for example, when processing documents sent by fax, recognizing old documents or from documents with poor print quality.

FlexiCapture is not very difficult to solve this problem.
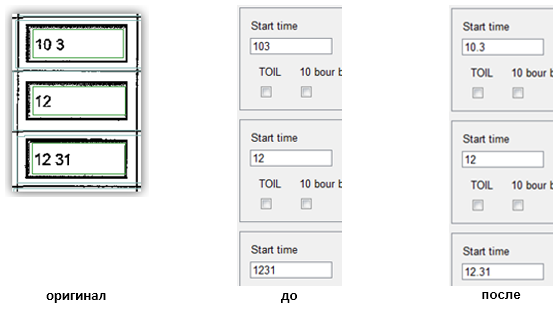
Usually the number of digits in the fractional part varies from 0 to 2. To understand whether there is a separator in the recognized text, we need:
- Calculate the distance between the last and last but one characters in a string. To do this, from the x coordinates of the right border of the penultimate character subtract the x coordinate of the left border of the last symbol. It will be S 1

- If the number of characters in a string is two: compare S 1 with a certain coefficient, if S 1 is greater than this value, then you need to add a separator.
- If the number of characters in a line is more than two, then it is necessary to calculate the distance S 2 between 2 and 3 characters from the end of the line.
- Calculate ratios S 1 / S 2 and S 2 / S 1
If one of the relations is greater than the coefficient, for example, 1.5, then insert a separator between the corresponding characters.
This solution was applied in one of our projects in Australia. Below is an example of the original image and the recognition results - with our "improved" and without it.
In the invoice, by the way, the recognition result is quite easy to check by checksum. If in the recognized document the value of the field "Total" converges with the sum of the table - it means that you can verify the recognition result without operator participation. Comparison of the amount with figures in the amount in words, if there is one in the document, can also help.
To automate the selection of coefficients, it is possible to analyze the average distance between characters in a line, the relationship between height and width of characters, etc., but as a rule, it is easier to choose coefficients experimentally, or by using the “spear” method. The time you spend on selecting these coefficients is calculated in minutes - while the verification operator can save this time of working hours.
Under the gaze of the Buddha and flowers bloom on the iron tree. What if you need a full text document layer
We already wrote, ABBYY FlexiCapture is needed to extract and save specific data from the fields: numbers, counterparties, etc., the full text of the document, as a rule, does not interest anyone. But it also happens that it is necessary in one stream to extract data from the fields for some documents and recognize the text entirely for others.
The ability to extract the entire text of a document as a text file may be needed, for example, to index the contents of a document in various search engines, both for general use and for internal companies.
Such a need has arisen at the Novosibirsk City Hall, which processed the documents of the authorities - orders, decrees and orders. They needed not only the fields from the “header” of the document by which the document was indexed in the archive, but also the results of full-text recognition, so that they could then find the document by keyword from the main part.
FlexiCapture has long been able to customize the export of recognized documents to PDF with a text layer. But the reality is that many external information systems are not able to search for PDF documents. Moreover, as regards the Novosibirsk archive, which has been storing data since the beginning of the 1920s, many of the original paper sources that we saw were rather shabby, faded pages typed on a typewriter. It can be expected that the results of automatic recognition for such files may not be very high quality. At the same time, it is the text content of such an archival document, and not its cap, that can be very important. Therefore, it would be good to have the opportunity in FlexiCapture at the stage of checking important data (in our case, it was the order number, date, etc.) and also check the results of full-text recognition.
The solution was found. In FlexiLayout Studio (we have already written about this tool for creating flexible descriptions) you can create a flexible description of a document, which will allow, in addition to meaningful structured data, to extract the entire text layer of the document. This is done very simply - for example, using a repeating group that contains all the lines of a document.
If necessary, this text layer can even be checked at the FlexiCapture verification station. Also, the text can be copied, indexed and exported to text formats. In the final PDF-document, we get a higher-quality result of recognition of the text layer, since this result will be verified by the operator.
Below is a screenshot from the ABBYY FlexiCapture verification page. As we see, now you can work not only with fields, but with all the text in the document.

Thank you for your patience , there are only 3 sentences left.
We have brought several engineering lifehacks that we hope will help you in working with our product.
If you have something to add - you have solved some other non-standard problem with FlexiCapture - we will be glad to read about it in the comments.
Tatyana Ganzhina, ABBYY Russia
with the active support of the specialists of ATAPI Software.
Source: https://habr.com/ru/post/236271/
All Articles