Do not be afraid of Core Data
It has long been noticed that among many of his colleagues in the workshop there is some suspicion and even in some way hostility to Core Data, and some of the framework did not even touch. What is already there, and at the beginning of my journey of mastering the new platform, I was biased towards him, taking advantage of such comments. But do not succumb to prejudice and myths without touching the product yourself. To those of us who went “against the system”, but have not yet fully grasped the tool, I dedicate this article. Based on a small example based on the real task of developing the mobile client of our social network My World, I want to talk about some of the "underwater" stones and focus the attention of the novice developer on the important points of optimizing the use of Core Data. It is assumed that the reader already has an idea what the core elements of Core Data are for (
Our case: it is necessary to develop an application that allows you to store and structure a large amount of photos with various meta-information about them. For this we need Core Data ... and that's it.

')
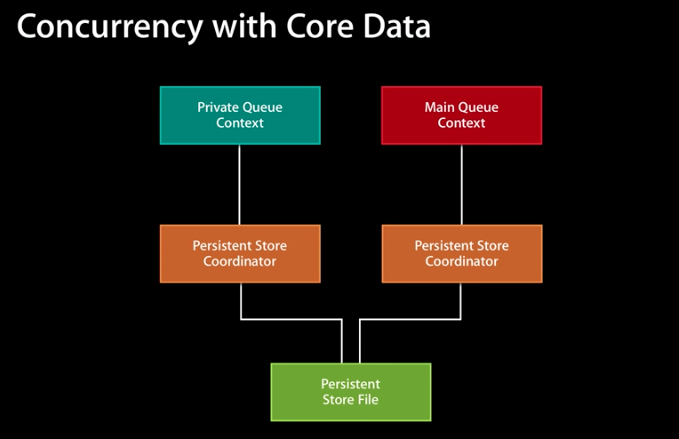
The stack is divided into two contexts; Main Context is used on the main stream for reading data; Background Context - to edit, insert and delete large amounts of data. That is, it is recommended to initially build the architecture of your application so that all changes occur in the background context, and you only perform read-only operations on the main context.
It should be noted that a lot of articles have been written on the architecture of the stacks, describing various branches of contexts. In my opinion, they only lift the threshold for the use of Core Data and only frighten novice developers from using the framework. In fact, for the 90% of applications, the above model will suffice, another 9% will be enough for one Main Context and only the rest of thehardcore players will need something more complicated.
Let's return to our application, in it we want to achieve the following goals:
-synchronize photos with the server without affect on the UI (done! Use for this Background Context in the stack);
- on the main screen show all photos sorted by date;
- on the secondary screen, group photos, where the grouping criteria is the number of likes, photos within the group are additionally sorted by date.
Let's get to the beginning to solve the problem in the forehead, create a model in which there will be only one Entity - our photo with all the meta-information:
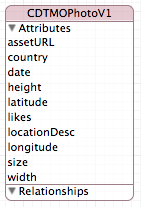
It was very simple, and if we were lazy developers, the work would have been finished on this (and someone else would have written the article :)).
For testing, we will assume that on the main screen we will need a simple

And on the additional screen, we will use all the power of

Having decided on our model, we will make a benchmark measurement of performance on the iPhone 5 for 10,000 photos. Hereinafter we will test our model for typical operations associated with our model:
All data in the tables are given in seconds, respectively, the insertion of 10,000 of our photos on the iPhone 5 will take a little less than two seconds.
Pretty good performance boost at minimal cost. Note that the time to add records has increased, this is due to the need to build an index. That is why it is important to apply the index only where it is really needed. By ticking the
Are all the juices we squeezed out of the index? You may notice that the
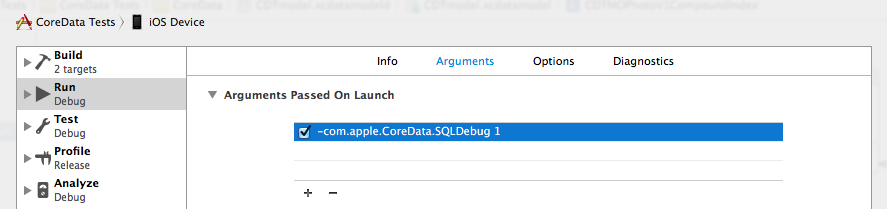
Next we need the sqlite file of the repository in its full state. If you are working with a simulator, then Xcode 6 stores the simulator's file system in the directory "~ / Library / Developer / CoreSimulator / Devices /". The name of the simulator directory corresponds to the Identifier value, which can be viewed in the device list (opened by Shitft + CMD + 2). Next, look for the directory of your application and find out the full path to the .sqlite file, which is usually placed in the Documents directory of the application. If you want to access the storage on the device, then the easiest way is to use the iExplorer application, using it as a file manager to browse the application directories on your device. From there you can copy the storage files (do not forget about the .sqlite-wal and .sqlite-shm files) to any convenient directory. All that is left to do is to connect to our repository from the console by running the command:
Now, by running our project and feeding the SQL directive " EXPLAIN QUERY PLAN " query from Core Data logs, we can find out some details of the processes occurring in sqlite. Let's see what actually happens when executing
As expected, the SQL query uses an index, which led to a significant acceleration. And what happens in
Here things are somewhat worse, the index worked only for likes , and a temporary binary tree is created to sort by date. It is easy to optimize this behavior by creating a compound index for both fields participating in the query (CAUTION: if an additional condition appears in your query, for example WHERE, with some third field, then you also need to add it to the composite index, otherwise will not be used upon request). This is done very easily in the Data Model Inspector, specifying, separated by commas, all the fields included in the composite index in the Indexes list of our Entity photo:

Let's see how the SQL query will now be processed:
You can make sure that instead of a binary tree a composite index is used, and this can not but affect the performance:

We will carry out the next test and look at the operation of the indices for such a model.

The results of this test are quite interesting. Please note that the speed of this model using the index is identical given the error of the model without it. Using the already known way to look into the depths, we can find that in both cases the index is not involved, since JOIN metadata occurs first, and only then sorts are performed in the combined table:
Bottom line: this model does not suit us.
Let's look at the test results:
The experiment was a success, we have accelerated the read operations, which are the main ones in the application up to 40% compared to the fastest flat model and up to 80% with the initial version without indices.
As you can replace, Core Data is not only a simple tool for working with data, but also a powerful tool in capable hands. Explore and experiment, and I hope that the article has opened something new for you and pushed you towards a more efficient use of Core Data in your projects. Good luck!
NSManagedObjectContext , NSPersistentStoreCoordinator , etc.) and at least superficially familiar with the API.Our case: it is necessary to develop an application that allows you to store and structure a large amount of photos with various meta-information about them. For this we need Core Data ... and that's it.
Core data stack
So, the first thing we have to do is prepare the right Core Data stack. Fortunately for us, there is a universal solution, I think the well-known Best Practice from WWDC 2013:')
The stack is divided into two contexts; Main Context is used on the main stream for reading data; Background Context - to edit, insert and delete large amounts of data. That is, it is recommended to initially build the architecture of your application so that all changes occur in the background context, and you only perform read-only operations on the main context.
It should be noted that a lot of articles have been written on the architecture of the stacks, describing various branches of contexts. In my opinion, they only lift the threshold for the use of Core Data and only frighten novice developers from using the framework. In fact, for the 90% of applications, the above model will suffice, another 9% will be enough for one Main Context and only the rest of the
Subtle moments
- Starting with iOS 7, sqlite storage, unlike previous versions, operates in WAL (Write Ahead Log) journaling mode, which allows you to perform one write operation and multiple read operations in parallel. If suddenly you support iOS 6, then it is possible to enable this mode when creating a stack coordinator in iOS 4+ versions using
NSSQLitePragmasOption, however this can be fraught with troubles. Also in iOS 6 in a stack with two coordinators, when synchronizing contexts through notification , objects in them may not be updated . Therefore, for iOS 6 it is better to use a stack with two contexts that have a common coordinator and do not bother with the journaling mode, the percentage of active devices is extremely low. - WAL also stores a time bomb in the form of broken manual migration and possible backup errors. Since the storage on the disk is organized in the form of three files: dbname.sqlite, dbname.sqlite-wal and dbname.sqlite-shm, then when organizing a manual backup, you should not forget to save them all, otherwise then you will have to wait for a very “pleasant” surprise. Apple engineers apparently forgot about the presence of a WAL file themselves, so when using the Migration Manager we can also break the base. I myself have not encountered a similar problem, you can read more here .
- Typical manuals on Core Data and a project template in Xcode suggest placing the stack directly in the
AppDelegateclass and initializing everything you need during the launch of the application. However, if in your application the work with the database is sporadic or optional (for example, it is needed only after the user is registered in the application and is not needed for guest access), it makes sense to put the stack “sideways”. For this, a separateSingletonclass will be suitable, which will be initialized directly at the moment when it is really needed. This will save a significant amount of memory and reduce the time to start the application.
Model design
Thinking through the data schema is the most important moment when working with Core Data. Correcting a mistake made during the design phase of an architecture can cost a lot of time and nerves to a developer. Ideal if the model does not change after going into battle. In reality, if you do not have to resort to manual migration through the Migration Manager and all changes are swallowed Lightweight Migration - you are well done. Give this stage as much time as possible and try to experiment with different versions of the models.Let's return to our application, in it we want to achieve the following goals:
-
- on the main screen show all photos sorted by date;
- on the secondary screen, group photos, where the grouping criteria is the number of likes, photos within the group are additionally sorted by date.
Let's get to the beginning to solve the problem in the forehead, create a model in which there will be only one Entity - our photo with all the meta-information:
It was very simple, and if we were lazy developers, the work would have been finished on this (and someone else would have written the article :)).
For testing, we will assume that on the main screen we will need a simple
NSFetchRequest , the results of which we then show in the UICollectionView :And on the additional screen, we will use all the power of
NSFetchedResultsController to form sections and sort them:Having decided on our model, we will make a benchmark measurement of performance on the iPhone 5 for 10,000 photos. Hereinafter we will test our model for typical operations associated with our model:
- Insert 10,000 objects and then save the context.
- Request of all 10,000 objects sorted by one field (date in our case)
- Using
NSFetchedResultsControllerc sorting by 2 fields and forming sections (sorting by the number of likes and date, forming sections by the number of likes) - The same controller using
fetchBatchSizeequal to 30 (estimated number of photos on the gallery screen on the phone), to evaluate the effectiveness of block sampling
All data in the tables are given in seconds, respectively, the insertion of 10,000 of our photos on the iPhone 5 will take a little less than two seconds.
| Operations \ Model Type | Model V1 |
|---|---|
| Insets (10,000 objects) | 1.952 |
| NSFetchRequest (1 sort) | 0.500 |
| NSFetchedResultsController (2 sorts) | 0.717 |
| NSFetchedResultsController (2 sorts + batchSize) | 0.302 |
Indices
Although the execution time may seem inconsequential, you should not neglect the possibility of optimization. Moreover, on older devices, operations are performed several times slower, and you should not forget about it. The first optimization is the easiest and is known to everyone - we will try to add an index for the fields that participate in the queries we form, namely date and likes :| Operations \ Model Type | Model V1 | V1 + index | Diff |
|---|---|---|---|
| Insert (10000 objects) | 1.952 | 2.193 | + 12% |
| NSFetchRequest (1 sort) | 0.500 | 0.168 | -66% |
| NSFetchedResultsController (2 sorts) | 0.717 | 0.657 | -eight% |
| NSFetchedResultsController (2 sorts + batchSize) | 0.302 | 0.256 | -15% |
Pretty good performance boost at minimal cost. Note that the time to add records has increased, this is due to the need to build an index. That is why it is important to apply the index only where it is really needed. By ticking the
Indexed checkbox in all possible fields, thinking that it will speed up your application, you are doing yourself a disservice.Are all the juices we squeezed out of the index? You may notice that the
NSFetchedResultsController "sped up" significantly less than the simple NSFetchRequest . What is the matter?Composite Indexes
Let's take a look under the hood CoreData. First of all, for this we need to enable the log for Core Data requests, by adding the "-com.apple.CoreData.SQLDebug 1" parameter to the Run scheme of our project as shown:Next we need the sqlite file of the repository in its full state. If you are working with a simulator, then Xcode 6 stores the simulator's file system in the directory "~ / Library / Developer / CoreSimulator / Devices /". The name of the simulator directory corresponds to the Identifier value, which can be viewed in the device list (opened by Shitft + CMD + 2). Next, look for the directory of your application and find out the full path to the .sqlite file, which is usually placed in the Documents directory of the application. If you want to access the storage on the device, then the easiest way is to use the iExplorer application, using it as a file manager to browse the application directories on your device. From there you can copy the storage files (do not forget about the .sqlite-wal and .sqlite-shm files) to any convenient directory. All that is left to do is to connect to our repository from the console by running the command:
sqlite3 PATH/TO/SQLITE/FILE Now, by running our project and feeding the SQL directive " EXPLAIN QUERY PLAN " query from Core Data logs, we can find out some details of the processes occurring in sqlite. Let's see what actually happens when executing
NSFetchRequest : sqlite> EXPLAIN QUERY PLAN SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZASSETURL, t0.ZCOUNTRY, t0.ZDATE, t0.ZHEIGHT, t0.ZLATITUDE, t0.ZLIKES, t0.ZLOCATIONDESC, t0.ZLONGITUDE, t0.ZSIZE, t0.ZWIDTH FROM ZCDTMOPHOTOV1INDEX t0 ORDER BY t0.ZDATE; 0|0|0|SCAN TABLE ZCDTMOPHOTOV1INDEX AS t0 USING INDEX ZCDTMOPHOTOV1INDEX_ZDATE_INDEX As expected, the SQL query uses an index, which led to a significant acceleration. And what happens in
NSFetchedResultsController : sqlite> EXPLAIN QUERY PLAN SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZASSETURL, t0.ZCOUNTRY, t0.ZDATE, t0.ZHEIGHT, t0.ZLATITUDE, t0.ZLIKES, t0.ZLOCATIONDESC, t0.ZLONGITUDE, t0.ZSIZE, t0.ZWIDTH FROM ZCDTMOPHOTOV1INDEX t0 ORDER BY t0.ZLIKES DESC, t0.ZDATE DESC; 0|0|0|SCAN TABLE ZCDTMOPHOTOV1INDEX AS t0 USING INDEX ZCDTMOPHOTOV1INDEX_ZLIKES_INDEX 0|0|0|USE TEMP B-TREE FOR RIGHT PART OF ORDER BY Here things are somewhat worse, the index worked only for likes , and a temporary binary tree is created to sort by date. It is easy to optimize this behavior by creating a compound index for both fields participating in the query (CAUTION: if an additional condition appears in your query, for example WHERE, with some third field, then you also need to add it to the composite index, otherwise will not be used upon request). This is done very easily in the Data Model Inspector, specifying, separated by commas, all the fields included in the composite index in the Indexes list of our Entity photo:
Let's see how the SQL query will now be processed:
sqlite> EXPLAIN QUERY PLAN SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZASSETURL, t0.ZCOUNTRY, t0.ZDATE, t0.ZHEIGHT, t0.ZLATITUDE, t0.ZLIKES, t0.ZLOCATIONDESC, t0.ZLONGITUDE, t0.ZSIZE, t0.ZWIDTH FROM ZCDTMOPHOTOV1COMPOUNDINDEX t0 ORDER BY t0.ZLIKES DESC, t0.ZDATE DESC; 0|0|0|SCAN TABLE ZCDTMOPHOTOV1COMPOUNDINDEX AS t0 USING INDEX ZCDTMOPHOTOV1COMPOUNDINDEX_ZLIKES_ZDATE You can make sure that instead of a binary tree a composite index is used, and this can not but affect the performance:
| Operations \ Model Type | Model V1 | V1 + index | V1 + composite index | Diff (V1) |
|---|---|---|---|---|
| Insert (10000 objects) | 1.952 | 2.193 | 2.079 | + 7% |
| NSFetchRequest (1 sort) | 0.500 | 0.168 | 0.169 | -66% |
| NSFetchedResultsController (2 sorts) | 0.717 | 0.657 | 0.331 | -54% |
| NSFetchedResultsController (2 sorts + batchSize) | 0.302 | 0.256 | 0.182 | -40% |
Entity splitting
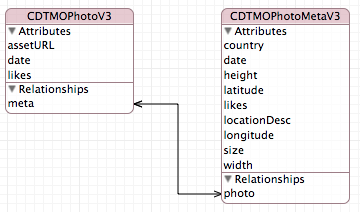
Another possibility for optimization is the creation of entities that contain only the information we need in a particular request. We see that our structure contains many minor fields that are not involved in the formation of the issuance of the initial result in our controllers. Moreover, when working with an object, Core Data completely pulls them into memory, that is, the larger the structure, the more memory is consumed (in iOS 8, an API appeared that allows you to change objects directly in the storage; the API is quite limited in use, since it imposes additional requirements for synchronization contexts). In our application, the division of our record into two suggests itself: the photo itself and the metadata for it:We will carry out the next test and look at the operation of the indices for such a model.
| Operations \ Model Type | Model V2 | V2 + index | Diff (V1 + index) |
|---|---|---|---|
| Insert (10000 objects) | 3.218 | 3.524 | + 61% |
| NSFetchRequest (1 sort) | 0.219 | 0.215 | + 28% |
| NSFetchedResultsController (2 sorts) | 0.551 | 0.542 | -18% |
| NSFetchedResultsController (2 sorts + batchSize) | 0.387 | 0.390 | + 52% |
The results of this test are quite interesting. Please note that the speed of this model using the index is identical given the error of the model without it. Using the already known way to look into the depths, we can find that in both cases the index is not involved, since JOIN metadata occurs first, and only then sorts are performed in the combined table:
sqlite> EXPLAIN QUERY PLAN SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZASSETURL, t0.ZMETA FROM ZCDTMOPHOTOV2INDEX t0 LEFT OUTER JOIN ZCDTMOPHOTOMETAINDEX t1 ON t0.ZMETA = t1.Z_PK ORDER BY t1.ZLIKES DESC, t1.ZDATE DESC; 0|0|0|SCAN TABLE ZCDTMOPHOTOV2INDEX AS t0 0|1|1|SEARCH TABLE ZCDTMOPHOTOMETAINDEX AS t1 USING INTEGER PRIMARY KEY (rowid=?) 0|0|0|USE TEMP B-TREE FOR ORDER BY Bottom line: this model does not suit us.
Normalization
We continue our experiments. We made sure that strict data normalization is not always good for Core Data. The results of the previous model were far from expected. Let's try to fix it. To do this, it is enough to duplicate our date and likes fields in the essence of the photo (without forgetting to add a composite index and a separate one for the date), thus avoiding the need for LEFT OUTER JOIN in our queries. The decision to leave or delete these fields in the essence of the metadata must be made depending on the situation. For example, if in addition you want to make a request with a rating of countries on the amount of likes of photos taken in them, then when removing these fields, we will again be faced with the need to make a JOIN, but in the other direction of communication. In our test, the properties of the entities are duplicated, and this is a completely normal occurrence for Core Data:Let's look at the test results:
| Operations \ Model Type | Model V3 | Diff (V1 + composite index) | Diff (V1) |
|---|---|---|---|
| Insert (10000 objects) | 3.861 | + 86% | + 98% |
| NSFetchRequest (1 sort) | 0.115 | -32% | -77% |
| NSFetchedResultsController (2 sorts) | 0.283 | -15% | -61% |
| NSFetchedResultsController (2 sorts + batchSize) | 0.181 | -one% | -40% |
The experiment was a success, we have accelerated the read operations, which are the main ones in the application up to 40% compared to the fastest flat model and up to 80% with the initial version without indices.
Results and fine points
- Use indexes and use them only for fields that are relevant to your queries. Do not forget about the existence of composite indices
- Experiment with different schemes, test their performance. It's very simple, because Xcode 6 has built-in support for perfomance tests.
- Do not forget to check how CoreData framework generates SQL queries using logs. With EXPLAIN QUERY PLAN , learn how sqlite digests your SQL query.
- When accessing the
NSFetchedResultsControllerresultsNSFetchedResultsControlleruse only the access method provided by the controller itself:NSManagedObject *object = [controller objectAtIndexPath:indexPath];
You should not access thefetchedObjectsarray or the NSFetchedResultsSectionInfo protocol to an array of section objects:NSManagedObject *object = [[controller fetchedObjects] objectAtIndex:index]; // NSArray *objects = [[[controller sections] objectAtIndex:sectionIndex] objects]; NSManagedObject *object = [objects objectAtIndex:index];
Why, you ask? If you usefetchBatchSizesize N, then after the request is completed, the controller will load only the first N objects into memory (or the first section if the block size is larger than the section size!). As soon as you request the first fault-object outside the loaded block or an object from another section, the controller will make a full pass through the results of your request, that is, it will perform N = number of objects / fetchBatchSize requests to the repository. This operation is about 3-4 times slower than a simple request for all items. When using access viaobjectAtIndexPaththis behavior is not observed. I would be very happy if there is someone among the readers who can shed light on such strange behavior that is not described in the documentation. - Normalization is not always the best solution for Core Data
- If from the scene in Cupertino you are told that the new iPhone is 2 times faster than the previous one ... you need to believe this, in Core Data operations these statements are confirmed almost completely. I prepared a summary file with the results, where you will also find tests iPhone 5S. In almost all the results, it is 2 times faster than its predecessor. Accordingly, on the more current iPhone 4S, these results will be about 2 times slower, not to mention even older devices. Here you will find a summary table of results, which also contains the results of the new iPhone 6.
As you can replace, Core Data is not only a simple tool for working with data, but also a powerful tool in capable hands. Explore and experiment, and I hope that the article has opened something new for you and pushed you towards a more efficient use of Core Data in your projects. Good luck!
Source: https://habr.com/ru/post/235941/
All Articles