GitHub's CSS
[Approx. Transl.]: I bring to your attention a translation of the article by Mark Otto, the developer of GitHub, a former developer of Twitter, the creator of the most famous CSS framework Bootstrap. In this article, he talks about the internal structure of CSS projects GitHub.
I was always interested in the details of the development process of other products, especially their guidelines and approach to using CSS. Considering my propensity for details of someone else's CSS code, I decided to write about the approach to CSS in GitHub.
As mentioned above, we use SCSS. This choice was made even before I began to participate in the development, but I agree with it (despite the fact that Bootstrap is written in LESS). Our SCSS is compiled and connected using the Rails asset pipeline and Sprockets (for now). More will be described below.
')
What about LESS, or Stylus, or ...? I don't think GitHub will ever switch to LESS. We would not like to change something in this regard, as there are no obvious advantages.
Why preprocessor? Our internal framework includes a set of variables (such as fonts and company colors) and impurities (mainly for prefixes) that make writing code faster and easier. We are not currently using Autoprefixer , but we should do it. So we could negate all our existing impurities. I hope we will do it soon.
We also do not use source maps, but this will change soon. (For those who do not know, source maps allow you to see in the debugger which of the original SCSS files include a specific set of styles, as opposed to compiled and minified files. They are amazing.)
We use the SCSS tools in a rather limited way. We have variables to define colors, impurities, color functions, math functions, and nesting levels. We do not need to iterate over classes, create global settings or something like that. I like the simplicity that we have.
Typically, the CSS architecture is BEM or OOCSS. We tend to OOCSS, but we don’t have a holistic approach. Our basic rules are:
A few weeks ago we did not use code analyzers. We had several common agreements, but each developer had his own style, and the formatting of each of us was somewhat unique. At the moment, each build goes through the process of analyzing SCSS code and crashes if:
CSS describes a class that is not used in the app / views / templates.
The same selector is used several times (since they must always be combined).
The basic formatting rules are violated (nesting limit, line breaks between sets of rules, etc.)
In general, there are a few rules that allow us to keep our code base tidy enough. They do not take into account discrepancies in the style of commenting or architecture, but this is exactly what each team needs. And each of us can offer and improve something.
The GitHub CSS project consists of 2 files: github and github2. This division was added a few years ago to solve the problem of working with IE, which limits the number of selectors to 4.095 per file. This limitation applies to IE 9 and lower. Because the GitHub requirement is at least IE9, we have to split the files.
As of today, our 2 files consist of approximately 7000 selectors. How does this compare to other sites?
This data was collected using cssstats.com. This is a small tool that looks at your CSS from an angle from which most people, including me, usually do not. We also have graphs in GitHub that we use for our own purposes.
In GitHub, CSS and JavaScript is enabled using Sprockets and require. We store both of our CSS packages in separate directories inside app / assets / stylesheets. This is how it looks like:
We connect our dependencies (Primer is our internal framework) and then load all the files from the scss directory. What will be the order of connection decides Sprockets (it seems to me that the alphabetical). The ease with which we can connect our style sheets (by simply prescribing require_directory) is amazing. But this approach has its drawbacks.
The order of styles is important. Because of the use of Sprockets, we sometimes have specific problems. This is because new files can be added to any package at any time. Depending on the file name, new styles may appear in different places in compiled CSS.
In addition, using Sprocket, you do not have immediate and automatic access to global variables and impurities in your SCSS files. This means that you have to import them explicitly at the beginning of each file that refers to a variable or admixture.
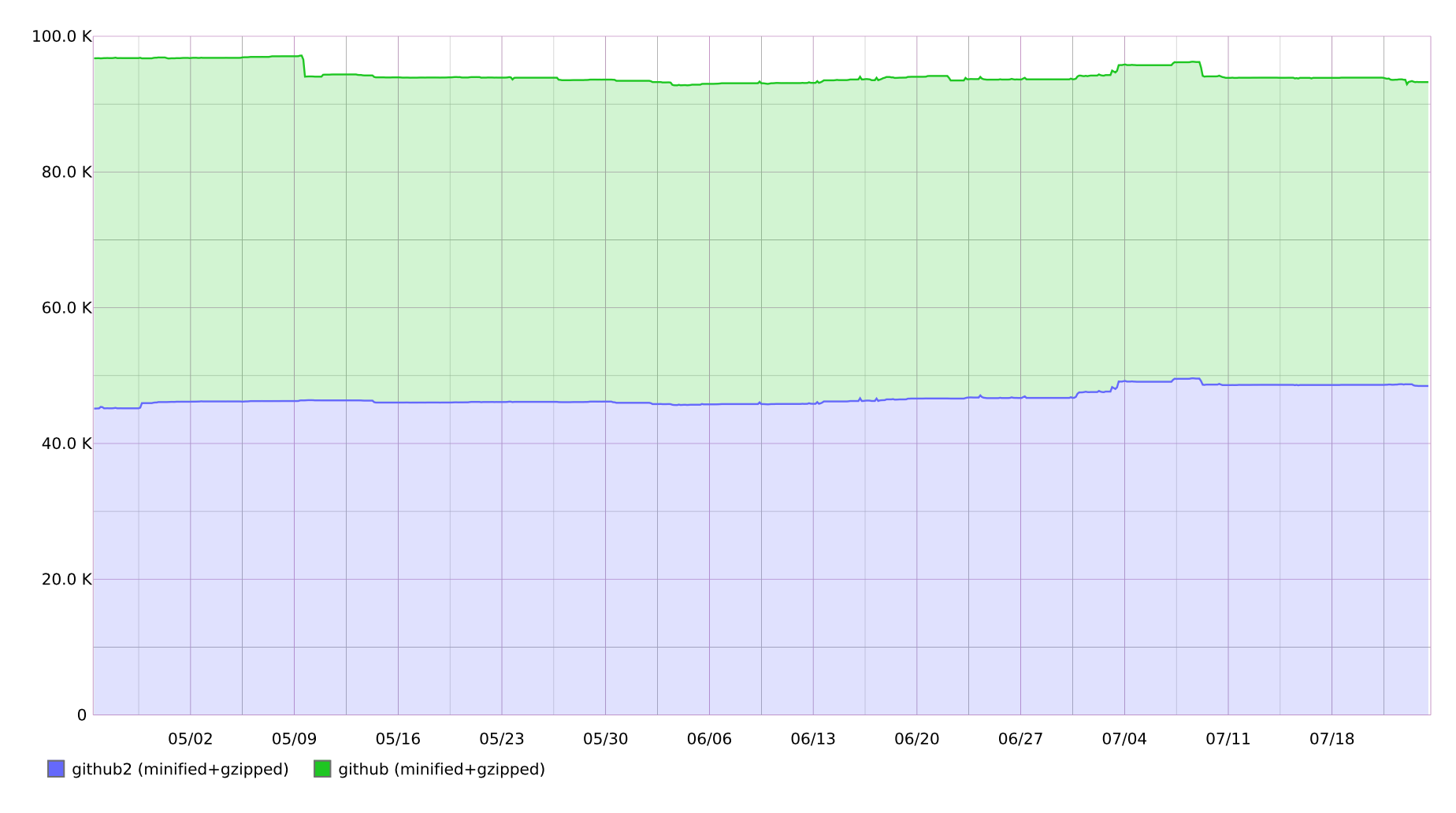
We have a huge number of schedules for monitoring the work of sites and our API. In particular, we track some interesting statistics on the frontend. For example, the size of our two CSS packages for the last 3 months:
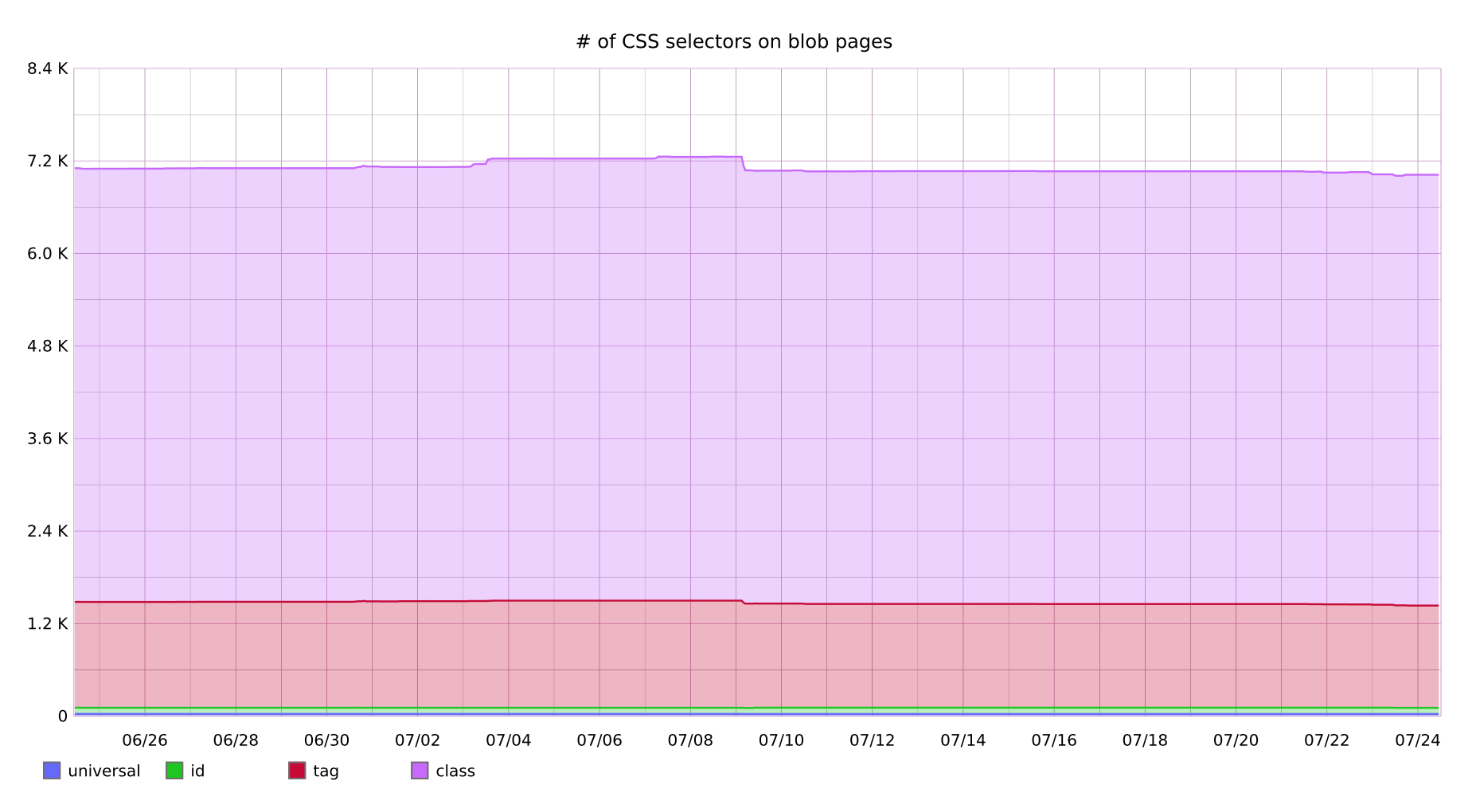
We also track the number of selectors on the page. We are still faced with the task of reducing the number of selectors by tag.
Since we regularly update our CSS and do this many times every day, we have to constantly flush the caching of our fairly large files. So far, we have not made much progress in optimizing the size of these files and limiting cache drops, but we have already begun to think about it more seriously. It would be nice to have a basic package that rarely changes, and a minor, honestly variable.
When I worked on Twitter, we had 2 packages (not sure if this is still the case), the main and additional ones. Basically, all the styles that were required to display the first tweet as quickly as possible were described. Everything else was stored in the extra. Given the love of GitHub for everything fast, this is exactly what we plan to consider in the near future. Currently, the division into files is random.
As a rule, we do not deal with selector performance. We know about bad practices - big nesting, the use of selectors by id and element, etc., but we are not trying to optimize it in a nutshell. The only exception is the diff page. Due to the extensive markup required to render diffs, we avoid attribute selectors, such as [class ^ = "octicon"]. If you use them too often, these attribute selectors can put the browser (and did it).
For the curious, Jon Rohan, the developer of GitHub, gave an excellent report on CSS performance on GitHub, which reveals these problems.
Speaking of documentation, we did an excellent job on it, but are still working on making improvements to it. We publicly posted our CSS guide and all our basic rules for writing CSS. We also posted examples of most of our components. It is assembled with the help of KSS, a style-guides generator.
Our documentation is not perfect, but it helps people find and use what they want. In addition, this is a great way to show recruits how we work to accelerate their infusion into the development process (as was the case with me about 2 years ago).
I referred to Primer earlier, but for those who do not know, I will explain: Primer is our internal framework, which contains styles and components used both in public and in our internal projects. It includes:
We use it on GitHub.com, Gist and several internal applications. As a rule, if something can be used in another application, we include it in the Primer. Most of the components of Primer are documented in our guide.
In our projects there is a certain amount of legacy code, and CSS is included in it. In contrast to opsor projects with strict versioning rules, we often score on it. We decide to remove part of the code in two cases:
The CSS refactoring process in GitHub itself is not unique. We find the bad code, delete it, and roll it out as quickly as possible. Delete code can any team member. A lot of cool developers join our team, but we also have nerds who are watching what can be removed and what is not.
If you have questions about this article, Bootstrap, GitHub or something else, ask on Twitter or my repository for feedback.
I was always interested in the details of the development process of other products, especially their guidelines and approach to using CSS. Considering my propensity for details of someone else's CSS code, I decided to write about the approach to CSS in GitHub.
Some facts
An overview of our current CSS state:
- As a preprocessor, we use SCSS.
- We have over 100 separate source files of styles that we compile before rolling out to sales.
- Sources are compiled into 2 separate CSS files (to avoid problems with the maximum number of selectors for IE <10).
- These 2 files weigh about 90 kb in total.
- We do not use any special "CSS architecture".
- We chose pixels to determine the size, but still we have some em-s.
- We use Normalize.css, mixed with several of our own styles to reset properties.
Preprocessor
As mentioned above, we use SCSS. This choice was made even before I began to participate in the development, but I agree with it (despite the fact that Bootstrap is written in LESS). Our SCSS is compiled and connected using the Rails asset pipeline and Sprockets (for now). More will be described below.
')
What about LESS, or Stylus, or ...? I don't think GitHub will ever switch to LESS. We would not like to change something in this regard, as there are no obvious advantages.
Why preprocessor? Our internal framework includes a set of variables (such as fonts and company colors) and impurities (mainly for prefixes) that make writing code faster and easier. We are not currently using Autoprefixer , but we should do it. So we could negate all our existing impurities. I hope we will do it soon.
We also do not use source maps, but this will change soon. (For those who do not know, source maps allow you to see in the debugger which of the original SCSS files include a specific set of styles, as opposed to compiled and minified files. They are amazing.)
We use the SCSS tools in a rather limited way. We have variables to define colors, impurities, color functions, math functions, and nesting levels. We do not need to iterate over classes, create global settings or something like that. I like the simplicity that we have.
Architecture
Typically, the CSS architecture is BEM or OOCSS. We tend to OOCSS, but we don’t have a holistic approach. Our basic rules are:
- Avoid unnecessary attachments
- Use (single) dashes when naming classes
- Write as little as possible so as not to cause confusion.
- I’ll write about my preferred CSS architecture in another article. At the moment I am describing the GitHub approach, which, although not ideal, serves its purpose well enough.
Code analysis
A few weeks ago we did not use code analyzers. We had several common agreements, but each developer had his own style, and the formatting of each of us was somewhat unique. At the moment, each build goes through the process of analyzing SCSS code and crashes if:
CSS describes a class that is not used in the app / views / templates.
The same selector is used several times (since they must always be combined).
The basic formatting rules are violated (nesting limit, line breaks between sets of rules, etc.)
In general, there are a few rules that allow us to keep our code base tidy enough. They do not take into account discrepancies in the style of commenting or architecture, but this is exactly what each team needs. And each of us can offer and improve something.
Two packages
The GitHub CSS project consists of 2 files: github and github2. This division was added a few years ago to solve the problem of working with IE, which limits the number of selectors to 4.095 per file. This limitation applies to IE 9 and lower. Because the GitHub requirement is at least IE9, we have to split the files.
As of today, our 2 files consist of approximately 7000 selectors. How does this compare to other sites?
- Bootstrap v3.2.0 - less than 1,900 selectors
- Twitter - less than 8,900 selectors
- NY Times - less than 2,100 selectors
- SoundCloud - only under 1,100 selectors (Edited: I previously talked about 7,400, but this was old SoundCloud)
This data was collected using cssstats.com. This is a small tool that looks at your CSS from an angle from which most people, including me, usually do not. We also have graphs in GitHub that we use for our own purposes.
Connection via Sprockets
In GitHub, CSS and JavaScript is enabled using Sprockets and require. We store both of our CSS packages in separate directories inside app / assets / stylesheets. This is how it looks like:
/ * = require primer / basecoat / normalize = require primer / basecoat / base = require primer / basecoat / forms = require primer / basecoat / type = require primer / basecoat / utility = require_directory ./shared = require_directory ./_plugins = require_directory ./graphs = require primer-user-content / components / markdown = require primer-user-content / components / syntax-pygments = require primer / components / buttons = require primer / components / navigation = require primer / components / behavior = require primer / components / alerts = require primer / components / tooltips = require primer / components / counter = require example-select-menu = require octicons = require_directory. * /
We connect our dependencies (Primer is our internal framework) and then load all the files from the scss directory. What will be the order of connection decides Sprockets (it seems to me that the alphabetical). The ease with which we can connect our style sheets (by simply prescribing require_directory) is amazing. But this approach has its drawbacks.
The order of styles is important. Because of the use of Sprockets, we sometimes have specific problems. This is because new files can be added to any package at any time. Depending on the file name, new styles may appear in different places in compiled CSS.
In addition, using Sprocket, you do not have immediate and automatic access to global variables and impurities in your SCSS files. This means that you have to import them explicitly at the beginning of each file that refers to a variable or admixture.
Performance
We have a huge number of schedules for monitoring the work of sites and our API. In particular, we track some interesting statistics on the frontend. For example, the size of our two CSS packages for the last 3 months:
We also track the number of selectors on the page. We are still faced with the task of reducing the number of selectors by tag.
Since we regularly update our CSS and do this many times every day, we have to constantly flush the caching of our fairly large files. So far, we have not made much progress in optimizing the size of these files and limiting cache drops, but we have already begun to think about it more seriously. It would be nice to have a basic package that rarely changes, and a minor, honestly variable.
When I worked on Twitter, we had 2 packages (not sure if this is still the case), the main and additional ones. Basically, all the styles that were required to display the first tweet as quickly as possible were described. Everything else was stored in the extra. Given the love of GitHub for everything fast, this is exactly what we plan to consider in the near future. Currently, the division into files is random.
As a rule, we do not deal with selector performance. We know about bad practices - big nesting, the use of selectors by id and element, etc., but we are not trying to optimize it in a nutshell. The only exception is the diff page. Due to the extensive markup required to render diffs, we avoid attribute selectors, such as [class ^ = "octicon"]. If you use them too often, these attribute selectors can put the browser (and did it).
For the curious, Jon Rohan, the developer of GitHub, gave an excellent report on CSS performance on GitHub, which reveals these problems.
Documentation
Speaking of documentation, we did an excellent job on it, but are still working on making improvements to it. We publicly posted our CSS guide and all our basic rules for writing CSS. We also posted examples of most of our components. It is assembled with the help of KSS, a style-guides generator.
Our documentation is not perfect, but it helps people find and use what they want. In addition, this is a great way to show recruits how we work to accelerate their infusion into the development process (as was the case with me about 2 years ago).
Primer
I referred to Primer earlier, but for those who do not know, I will explain: Primer is our internal framework, which contains styles and components used both in public and in our internal projects. It includes:
- Normalize
- Global styles for box-sizing, typography, links, etc.
- Navigation elements
- Forms
- Nets
- Custom select element
We use it on GitHub.com, Gist and several internal applications. As a rule, if something can be used in another application, we include it in the Primer. Most of the components of Primer are documented in our guide.
Refactoring
In our projects there is a certain amount of legacy code, and CSS is included in it. In contrast to opsor projects with strict versioning rules, we often score on it. We decide to remove part of the code in two cases:
- Manually we find places that look similar, but are described by different HTML or CSS code. In this case, we simply combine them.
- Run the script that looks for classes in the CSS code that are missing in the views. (Now we have automated this process by including it in our tests).
The CSS refactoring process in GitHub itself is not unique. We find the bad code, delete it, and roll it out as quickly as possible. Delete code can any team member. A lot of cool developers join our team, but we also have nerds who are watching what can be removed and what is not.
Questions?
If you have questions about this article, Bootstrap, GitHub or something else, ask on Twitter or my repository for feedback.
Source: https://habr.com/ru/post/235701/
All Articles