Recognition of Russian language for call centers and paranoids
When you call the call center, you are attentively listening to, and sometimes answering, not only the operator and comrade major, but also the robot analyst . This clever robot is able to recognize the right keywords in your speech, but also to produce full-text speech recognition, and on the basis of all this, draw far-reaching conclusions.

It is possible to analyze records both on the fly (which is rarely done) and after the fact, for example, searching for specific calls for analysis by a living person. I have worked with several software and hardware solutions for this, and now I will share my experience.
')

Automatic recognition is already beginning to cope with the Russian language, with the exception of some particularly difficult cases
I’ll note right away - yes, these decisions can be combined with the definition of a specific person using a “voice fingerprint”, but this is a slightly different story and I will not dwell on this here.
There are 4 vectors by which speech recognition is currently developing:
Everything is quite familiar here. You call the air carrier. There they took out the woman, shoved the machine gun. The machine asks you what city you are from. You answer, the software tries to transcribe the sounds and morphemes. And compares the result with the base of possible answers.
Successful event:
Unsuccessful case:
Difficult case:
So, as you can see, the basis is a system of synonyms for the main words-answers, as well as a certain set of meta-words that are responsible for managing the dialogue. Each word has many voice synonyms: “aha”, “ord”, “aha” and so on. Depending on the particular logic system used (several different ones), the robot somehow evaluates the context, makes an assessment of the plausibility of the answer from the base sample, expands the sample if necessary, and tries to build hypotheses based on the communication history. In a more complicated case, sentence analysis is used to determine which words mean what. For example, when asked where to fly, the user can answer: “From Moscow to sunny Magadan”. Here there are at least three cities - Moscow, Sunny and Magadan. Analysis of the proposal based on the recognized prepositions will help to predict that Sunny and Magadan is more important. Then the robot can, for example, make a request to an external base and try to add context: if there are no direct flights Moscow-Sunny, then Magadan will be chosen. But taking into account the errors of all these methods, the robot will still ask whether it is there.
Most successfully such IVR are used by banks. For example, a similar dialogue is possible:
In about a minute of recording your voice, you can create a unique “fingerprint” corresponding to your ID in the database. Recognition is performed on the first-second phrase, about 8-15 seconds of your speech. In addition to verifying the fact that you are you, you can also search the database of fingerprints.
Large banks almost every single use of this method as a means of additional user identification for non-critical operations, and as a froder filter. For good, the bank should have fraud calls, and if one of the known intruders is ringing, the operator sees a special warning based on a comparison of his voice with marks in the database. It is possible to retrospectively analyze all call center records to search for records of a specific person (accuracy, however, is low, in the base of 1000 calls you will have to listen to about 30 to find the one you need). All the details are here .
Depending on your emotional state, the frequency of certain sounds in speech (percussion, nasal, etc.), as well as the pitch of some vowels, actually changes. For the most part, the algorithms for determining the emotional state are closed. Their accuracy is not very high, so, I repeat, one of the few practical applications is to know the condition in which the client called 10 times before. In the Russian market, the analysis of emotions is used in addition to speech analytics, to more accurately determine the emotional - “bad” or “good” calls.
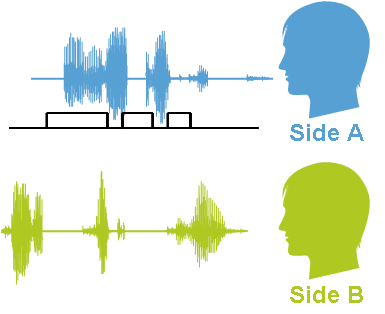
The first task is to divide the dialogue into two channels: inbound and outbound. This can be solved by means of a call center (writing from two different sources) or by post-processing, for example, using the Speaker Separation technology. After this preparation, you can already consider each of the parts separately.
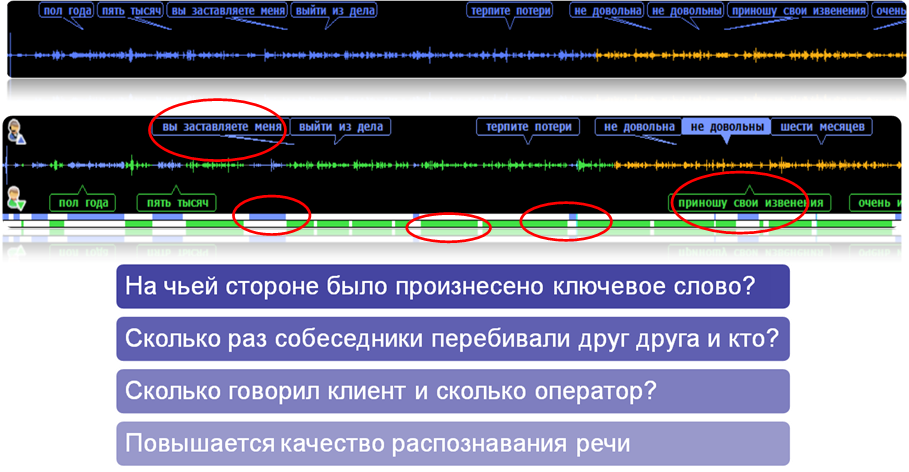
Suppose at the entrance - 400 thousand call records for this month. Before that, hands estimated less than 1% of calls.
You have the following tasks:
So, for the first case, it is enough just to put the “vents” in all variations of pronunciation into the search base. The robot will parse the speech and look for such occurrences. The problem of parasite words is solved in the same way, we search and count. Similarly, the new counter on the name of the product, the level of questions for which we need to evaluate. Revealing silence is the basic functionality; even there is almost no need to configure it.
Customer satisfaction is a bit more complex. There is a dictionary of about 500 "bad" and as many good words. There are words that can fall into both categories depending on the context, for example, Russian mat and derivatives. They can both praise and praise, and scold, while the words will be the same. Depending on the system, the robot starts to evaluate the context in different ways. For example, if the word “thank you” was next to it, the overall positive assessment will most likely be assigned. Even if it was sarcasm.
Trend detection works in a similar way. A robot can search for certain formalizable patterns on the basis of speech analytics.

An illustration of how a manager can see calls by type. Blue - standard calls. Yellow - problems with the quality of the employee. Red - missed sale. Green - positive feedback. Purple is a customer at risk.
As for the last point, individual KPIs that are monitored are configured for operators. If the value of one of these indicators deviates to the “bad” side or zone, then this may serve as an indicator that the operator is not well versed in one of the topics. Or, for example, you can identify best practices and techniques (for example, for sale or collection activities). And on the basis of this information to adjust the existing learning mechanisms. With well-designed work with KPI, operators can “compete” in productivity (both with other operators and with themselves). In my experience, operators who see their work in numbers tend to work better.
If 75% of calls with an assessment of customer satisfaction were selected correctly with no more than 5% of false positives, this is considered a great success in a number of categories, for example, when you need to identify some complex emotional tasks. On some segments like searching for one particular word, the accuracy will be 85% -95% with a minimum of false ones. Under the conditions of noisy lines, the statistics can be like this: about 60% of the true calls fall into the sample, of which about 5–10% of false positives. But given that you have 400,000 calls, for statistics it is still quite accurate. Actually, even if the system selects only 30% of the calls that interest you and skip the remaining 70%, you will be able to find an operator with a love of slang, and make up the ratio of negative-positive reviews on specific products.
The specific error depends on the call center equipment, the accuracy of setting tasks for fuzzy search, the class of recognition system and the audience of callers.
Why such a big error?
One of the system manufacturers stated this:
• Automating the process of searching for appeals by specified parameters and keywords.
• Reproduction of the appeal with the ability to go to the time of the key phrase.
• Identify the causes of customer complaints and complaints.
• Identification of operators requiring additional training.
• Identify best practices used by operators.
• Receive alerts in case of appeals with specified selection conditions.

In my practice there were the following tasks:

The general principle of the search keywords
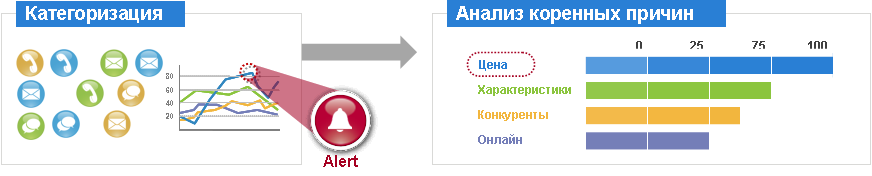
And categorization by them
When the call center is not less than 100 operators - otherwise it is easier to sort the calls by hand.
At the same time, post-analytics is not demanding on the infrastructure - you can at least upload FTP, from where the robot will take records for analysis and display the result in the web interface. Nevertheless, there are a number of requirements for codecs and the quality of saving records.
I can’t give a payback assessment, because everyone’s tasks are different and distributed in different directions from security to marketing. According to customer reviews and estimates of some vendors for a spherical QC in vacuum - from one to two.
Tweaking one of the systems
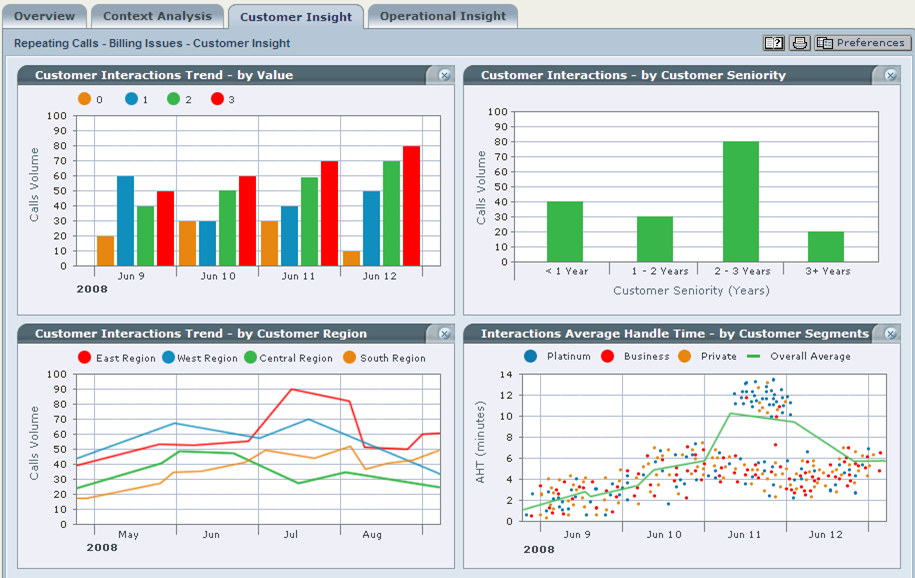
An example of the result of the retrospective analysis of calls in 2008
The toolkit of speech analytics systems (all vendors known to me) allows us to highlight words and phrases that are most often used in the considered section of calls. I recall using such systems, we have the opportunity to consider the entire volume of calls from different angles: sample by a group of operators, by call duration, by call subject, by silence, by client’s speech volume and many other data sections. Thus, we can identify significant trends in various areas of the CC.
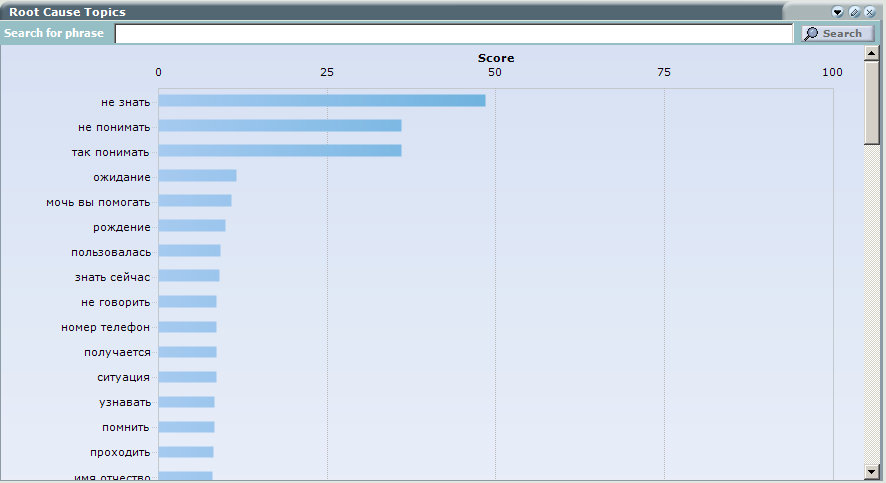
At the same time, there are additional tools that allow you to understand the causes of calls and figure out what's what - these are tools that build a correlation between words. Simply put, I choose the word of interest to me, and the system shows me with which other words and phrases it is most often used. In some cases, the system searches for not only statistical coincidences, but also tries, and, accordingly, one can understand the reasons for appeals to CC and sort them to find the right meaning, that is, to build clear sentences. A user of the system can easily determine the causes of calls to the CC and carry out further analysis (Root Cause Analysis).
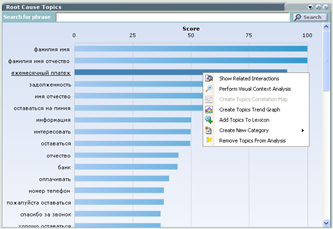
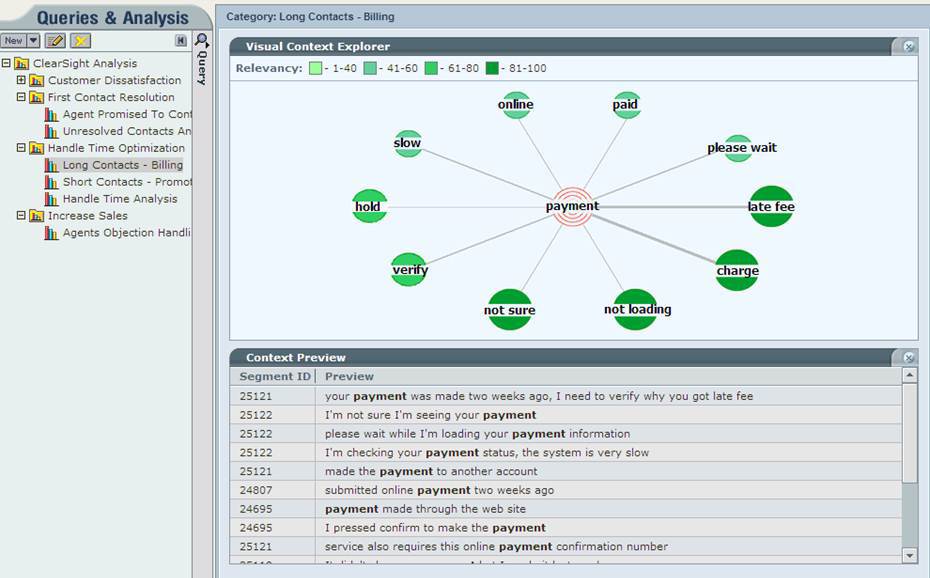
Example of determining the cause of calls to clarify the monthly payment on the loan:
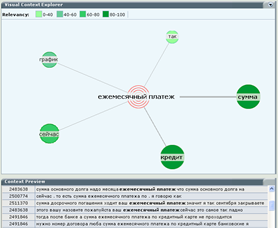
Or here you can see that users have some problems with making payments:
For IVR and speech analytics, in most cases installation of a PAK is required on site. Hardware and software are configured on average for 2 weeks. About a month or two documents are signed, rules are formulated, legal aspects of voice processing are coordinated, systems are integrated - for example, with CRM and so on.
The same post-analytics service is available in our cloud environment. You can upload records to our data center, where the robot will process them and issue reports. The terms are the same, only minus two weeks for iron. New tasks (with already solved organizational issues) are usually driven into the analytics in a day or two.
By languages - on average, modern systems support about 10 of the most popular languages of the world, plus the main European languages not included in this list. Russian, of course, too.
If you have questions about specific sites, I’m ready to answer in the comments or by mail DVelikanov@croc.ru.
Glory to the robots!
It is possible to analyze records both on the fly (which is rarely done) and after the fact, for example, searching for specific calls for analysis by a living person. I have worked with several software and hardware solutions for this, and now I will share my experience.
')
Automatic recognition is already beginning to cope with the Russian language, with the exception of some particularly difficult cases
I’ll note right away - yes, these decisions can be combined with the definition of a specific person using a “voice fingerprint”, but this is a slightly different story and I will not dwell on this here.
4 main directions
There are 4 vectors by which speech recognition is currently developing:
- Natural recognition for voice service (IVR) systems is almost like iOS and Android voice assistants. With about the same accuracy.
- Analytics of negotiations (analysis of thousands of calls in search of some trends).
- Recognition and identification by voice (the same "voice fingerprint", which you leave in almost every bank).
- And the analysis of emotions, allowing to understand that something is wrong. Usually, now the analysis of emotions happens in the same way after the fact and works together with the rest of the recognition engines. But some vendors (not leading ones) offer the option “on the fly”, however, usually this is a separate technology that is not particularly tied to other business processes.
IVR
Everything is quite familiar here. You call the air carrier. There they took out the woman, shoved the machine gun. The machine asks you what city you are from. You answer, the software tries to transcribe the sounds and morphemes. And compares the result with the base of possible answers.
Successful event:
Robot: Tell me, what city are you in?
User: Moscow.
// What the robot recognized: maaskva.
// There is a voice synonym in the database: Maskva.
// The result of “Maaskva” by the distance of Damerau-Levenshteyn is closest to the synonym “Maskva”. No extension required.
// In the base city corresponding to this synonym: Moscow.
Robot, joyfully: You are in Moscow!
Unsuccessful case:
Robot: Tell me, what city are you in?
User: Go.
// What the robot recognized: psholka.
// The database has voice synonyms for the cities of Pushkin and Pushchino.
// The result of “psholka” is far from all options. The sample is extended to extended place names.
// The sample expands to standard questions for the answering machine regardless of the question.
// In the extended sample there is no option for such a word.
// The history of communication is still empty.
Robot, sad: Please repeat the city where you are.
Difficult case:
Robot: Tell me, what city are you in?
User: In the Urals.
// What the robot recognized: in science.
// In the base of the standard selection there are no suitable options.
// The first part is similar to a preposition or an interjection, the synonym “in ralis” and its derivatives are simultaneously launched.
// In the base of the standard selection there are no suitable options.
// Sample expands to place names.
// In the extended sample there is “Ural” and its derivative voice synonyms.
Robot, sad: Please repeat the city where you are.
User: Zavyaliha, brother.
// The robot breaks the long message into parts and starts looking for each one.
// The cities are located: Zaviliha, Bratsk, Brother-Nive.
// The robot looks into the story: there is the Urals. It is assumed that one toponym corresponds to the location of another. Ural is compared with each city, the closest of all - Zavyaliha. The theory is marked as the most probable.
Robot, puzzled: are you in Zavilikha?
User: Definitely!
// This is a separative question. We are looking for synonyms for "yes" and "no." Then, each synonym word is evaluated by its vocal synonyms, such as “adnazdachna”. A search in the sample indicates that the client agrees with the theory of the robot.
Robot, satisfied: What city are you going to?
User: And where can I fly today?
So, as you can see, the basis is a system of synonyms for the main words-answers, as well as a certain set of meta-words that are responsible for managing the dialogue. Each word has many voice synonyms: “aha”, “ord”, “aha” and so on. Depending on the particular logic system used (several different ones), the robot somehow evaluates the context, makes an assessment of the plausibility of the answer from the base sample, expands the sample if necessary, and tries to build hypotheses based on the communication history. In a more complicated case, sentence analysis is used to determine which words mean what. For example, when asked where to fly, the user can answer: “From Moscow to sunny Magadan”. Here there are at least three cities - Moscow, Sunny and Magadan. Analysis of the proposal based on the recognized prepositions will help to predict that Sunny and Magadan is more important. Then the robot can, for example, make a request to an external base and try to add context: if there are no direct flights Moscow-Sunny, then Magadan will be chosen. But taking into account the errors of all these methods, the robot will still ask whether it is there.
Most successfully such IVR are used by banks. For example, a similar dialogue is possible:
Robot: Can I help you?
User: Hello. And where is your closest ATM to Smolino Lake?
Robot: Specify, please, are you in Chelyabinsk?
User: Yeah, on Novorossiysk.
Robot: The nearest ATM to you is on the street such and such, the house such and such.
Voice Identification
In about a minute of recording your voice, you can create a unique “fingerprint” corresponding to your ID in the database. Recognition is performed on the first-second phrase, about 8-15 seconds of your speech. In addition to verifying the fact that you are you, you can also search the database of fingerprints.
Large banks almost every single use of this method as a means of additional user identification for non-critical operations, and as a froder filter. For good, the bank should have fraud calls, and if one of the known intruders is ringing, the operator sees a special warning based on a comparison of his voice with marks in the database. It is possible to retrospectively analyze all call center records to search for records of a specific person (accuracy, however, is low, in the base of 1000 calls you will have to listen to about 30 to find the one you need). All the details are here .
Emotion Analytics
Depending on your emotional state, the frequency of certain sounds in speech (percussion, nasal, etc.), as well as the pitch of some vowels, actually changes. For the most part, the algorithms for determining the emotional state are closed. Their accuracy is not very high, so, I repeat, one of the few practical applications is to know the condition in which the client called 10 times before. In the Russian market, the analysis of emotions is used in addition to speech analytics, to more accurately determine the emotional - “bad” or “good” calls.
Speech analytics
The first task is to divide the dialogue into two channels: inbound and outbound. This can be solved by means of a call center (writing from two different sources) or by post-processing, for example, using the Speaker Separation technology. After this preparation, you can already consider each of the parts separately.
Suppose at the entrance - 400 thousand call records for this month. Before that, hands estimated less than 1% of calls.
You have the following tasks:
- Some operators say "windows" instead of "Windows". Such slang does not suit you: you need to understand who it is, and once again explain.
- It would be good to constantly monitor the use of parasitic words by operators and automatically count them in calls.
- There was an advertising campaign - you need to understand how many times people mentioned a new product, cellular tariff or other product when making calls. The robot counts them, marketers orgasm.
- Silence is revealed. Silence for more than 5 seconds is a sign of some difficulty in the process (for example, the operator loads something in himself). In this case, you can check later that the service is so slow.
- It would be good to evaluate the level of customer satisfaction.
- It would be great to learn how to count the FCR (an indicator that measures the number of calls resolved from the first call to the CC).
- And also to increase the efficiency of the operators - using speech analytics, you can automatically train operators with spaces on specific topics.
So, for the first case, it is enough just to put the “vents” in all variations of pronunciation into the search base. The robot will parse the speech and look for such occurrences. The problem of parasite words is solved in the same way, we search and count. Similarly, the new counter on the name of the product, the level of questions for which we need to evaluate. Revealing silence is the basic functionality; even there is almost no need to configure it.
Customer satisfaction is a bit more complex. There is a dictionary of about 500 "bad" and as many good words. There are words that can fall into both categories depending on the context, for example, Russian mat and derivatives. They can both praise and praise, and scold, while the words will be the same. Depending on the system, the robot starts to evaluate the context in different ways. For example, if the word “thank you” was next to it, the overall positive assessment will most likely be assigned. Even if it was sarcasm.
Trend detection works in a similar way. A robot can search for certain formalizable patterns on the basis of speech analytics.
An illustration of how a manager can see calls by type. Blue - standard calls. Yellow - problems with the quality of the employee. Red - missed sale. Green - positive feedback. Purple is a customer at risk.
As for the last point, individual KPIs that are monitored are configured for operators. If the value of one of these indicators deviates to the “bad” side or zone, then this may serve as an indicator that the operator is not well versed in one of the topics. Or, for example, you can identify best practices and techniques (for example, for sale or collection activities). And on the basis of this information to adjust the existing learning mechanisms. With well-designed work with KPI, operators can “compete” in productivity (both with other operators and with themselves). In my experience, operators who see their work in numbers tend to work better.
Errors
If 75% of calls with an assessment of customer satisfaction were selected correctly with no more than 5% of false positives, this is considered a great success in a number of categories, for example, when you need to identify some complex emotional tasks. On some segments like searching for one particular word, the accuracy will be 85% -95% with a minimum of false ones. Under the conditions of noisy lines, the statistics can be like this: about 60% of the true calls fall into the sample, of which about 5–10% of false positives. But given that you have 400,000 calls, for statistics it is still quite accurate. Actually, even if the system selects only 30% of the calls that interest you and skip the remaining 70%, you will be able to find an operator with a love of slang, and make up the ratio of negative-positive reviews on specific products.
The specific error depends on the call center equipment, the accuracy of setting tasks for fuzzy search, the class of recognition system and the audience of callers.
Why such a big error?
- Because the line noise.
- Wind and other background sounds make it difficult to recognize. If you make a voice imprint for identification, you can even with a child screaming against the background, then it’s not so easy to make out the words.
- With a narrow band characteristic of some PBXs and old cellular codecs, it is almost impossible to distinguish between "C" and "F". We have to connect the morphemic analysis, which gives rise to even more hypotheses at a low level.
- Russian language is very poorly typed. Relying on the composition of the proposal for the construction of hypotheses is quite difficult.
- Meaning is often highly dependent on intonation. The vocabulary word “Aha” and “Of course” - it can be “Aha, of course!”, Which is a negation. Not everyone can talk to robots.
- In the case of IVR, the user does not always immediately understand what he is talking to the answering machine. Hence - various complex constructions and explanations for a couple of minutes.
- And there are also different stresses and pronunciations.
- For the time being, no one has set the task of recognition system developers to work in profile with the Dagestan or Finnish accent.
- When compressing files for recording in the call center itself, it is also possible to introduce new distortions (this applies to post-analytics).
Real application
One of the system manufacturers stated this:
• Automating the process of searching for appeals by specified parameters and keywords.
• Reproduction of the appeal with the ability to go to the time of the key phrase.
• Identify the causes of customer complaints and complaints.
• Identification of operators requiring additional training.
• Identify best practices used by operators.
• Receive alerts in case of appeals with specified selection conditions.
In my practice there were the following tasks:
- It was necessary to identify the result of the promotion in the spirit of “Bring five caps”. The increase in calls to the call center had to be compared with the number of references to the stock in free form. About 60% of calls were selected correctly, which, knowing the error, allowed to make an assessment.
- In one company the name was changed. Some operators used the old habit, it was necessary to wean. Found and weaned. Within the framework of the same task, it was checked that the operator greets each client and represents. The robot checked for the presence of a fuzzy greeting pattern at the beginning of the conversation.
- The bank operator had a script offering three new services. The interest in them had to be weighed for different groups of clients and, as a result, only one optimal proposal was left for each group. Rather difficult task, which used the mechanism for assessing satisfaction, described above. The error, naturally, is high, but for statistical analysis followed by listening to a few hundred calls was enough. The customer is satisfied, before they had to listen to 4-5 thousand calls.
- It was necessary to scatter calls to destinations in order to assess the load of operators. Roughly speaking, claims, product comparisons, vacancies, and so on. Dictionary for each topic, general contextual rules - and more. Accuracy is about 65%, which is enough for statistics.
- It was necessary to identify delays in the business processes of state-owned companies. 37% of calls were with long silence. After that, we began to analyze the linguistic nests before silence and immediately after, the ranking of the most important keywords was compiled. Each nest came down to some trend related to the process or product. Because of the wide scope of the task, we focused on the minimum false positives, and only about 30% of calls got into the sample, where we were able to recognize everything exactly. The absolute number of calls was unimportant, it was necessary to find the reason. It turned out that the delays were in the block “card operations”, “credit”, and “early repayment”. There was a problem in the process (there was no quick way to do this operation) and in the service (it was loaded for about 9 seconds instead of the required 3 seconds). Corrected. Continued to monitor the silence to improve service. The specific business task is to reduce customer service time by searching and optimizing the longest processes.
The general principle of the search keywords
And categorization by them
When does it make sense to implement such systems?
When the call center is not less than 100 operators - otherwise it is easier to sort the calls by hand.
At the same time, post-analytics is not demanding on the infrastructure - you can at least upload FTP, from where the robot will take records for analysis and display the result in the web interface. Nevertheless, there are a number of requirements for codecs and the quality of saving records.
I can’t give a payback assessment, because everyone’s tasks are different and distributed in different directions from security to marketing. According to customer reviews and estimates of some vendors for a spherical QC in vacuum - from one to two.
Tweaking one of the systems
An example of the result of the retrospective analysis of calls in 2008
The toolkit of speech analytics systems (all vendors known to me) allows us to highlight words and phrases that are most often used in the considered section of calls. I recall using such systems, we have the opportunity to consider the entire volume of calls from different angles: sample by a group of operators, by call duration, by call subject, by silence, by client’s speech volume and many other data sections. Thus, we can identify significant trends in various areas of the CC.
At the same time, there are additional tools that allow you to understand the causes of calls and figure out what's what - these are tools that build a correlation between words. Simply put, I choose the word of interest to me, and the system shows me with which other words and phrases it is most often used. In some cases, the system searches for not only statistical coincidences, but also tries, and, accordingly, one can understand the reasons for appeals to CC and sort them to find the right meaning, that is, to build clear sentences. A user of the system can easily determine the causes of calls to the CC and carry out further analysis (Root Cause Analysis).
Example of determining the cause of calls to clarify the monthly payment on the loan:
Or here you can see that users have some problems with making payments:
Implementation
For IVR and speech analytics, in most cases installation of a PAK is required on site. Hardware and software are configured on average for 2 weeks. About a month or two documents are signed, rules are formulated, legal aspects of voice processing are coordinated, systems are integrated - for example, with CRM and so on.
The same post-analytics service is available in our cloud environment. You can upload records to our data center, where the robot will process them and issue reports. The terms are the same, only minus two weeks for iron. New tasks (with already solved organizational issues) are usually driven into the analytics in a day or two.
By languages - on average, modern systems support about 10 of the most popular languages of the world, plus the main European languages not included in this list. Russian, of course, too.
If you have questions about specific sites, I’m ready to answer in the comments or by mail DVelikanov@croc.ru.
Summary
Glory to the robots!
Source: https://habr.com/ru/post/235565/
All Articles