Monitoring system of active network equipment of the federal network
At the time of writing, I came to the conclusion that it is almost impossible to explain the whole technical part on this topic in one post, and maybe nobody needs it. Therefore, I decided to make this post an overview of my work. The purpose of the post is to show how not using additional funding from the company and by drawing a couple of virtual servers you can build an effective monitoring environment for the active equipment of a large network in a large company.
If you are interested in the topic of network monitoring or have a desire to compare my work with what you have, I invite you under cat.
In a small “home” network, the task of monitoring the network can be solved using any of the available free monitoring platforms. However, when it comes to a large enterprise with a large number of nodes, everything is not so transparent. And the main problem is the lack of physical resources and the lack of a system adapted to your requirements. The situation is slightly better with paid products, but paid systems rarely enter into business expenses for monitoring of some kind .
')
Control system
The skeleton of the entire monitoring system will be a control system that allows the mouse to make changes, remove or add new nodes or connections.
When developing the whole system, the following requirements were taken into account:
- Minimal tuning / reconfiguration on active equipment;
- Processing a large amount of traffic on netflow;
- The ability to explore in detail any network activity;
- Immediate update on incidents. Whether it is a channel drop or a large channel load;
- Ability to modify modules or reports for all possible selections;
- Enable the minimum amount of infrastructure;
- As little as possible, write the functionality yourself.
The infrastructure was tried differently until the current configuration was reached. I will not describe all the tested options, so as not to stretch the post.
The bottom line is: Two virtual servers running CentOS 6.
One for control and display system. 2 processors, 4GB of RAM, 250GB disk.
The second one performing the functions of a netflow collector. 2 processors, 4GB of RAM 150GB disk.
Server configuration is quite standard, apache web server with php + mysql .
Cactus
For the control system was selected Cactus . What attracted the cactus:
- The lack of complex code in the WEB display (no flash, aciveX and other active components, which gives the advantage of using on mobile devices);
- Simple and clear structure of the database, to which you can easily bind your functionality;
- Many plug-ins specifically for monitoring active equipment;
- Built-in SNMP support;
- RRDTool as a source for charts (hello zabbiksu);
- there is no client part.
Installing a Cactus does not pose any difficulty. There is a lot of information on this topic on the Internet, and of course, official documentation is the best one.
Setup also does not require deep IT knowledge. The Devices page adds devices, specifies the type of SNMP and authorization. Bind standard templates.
Devices
SNMP configuration
Templates
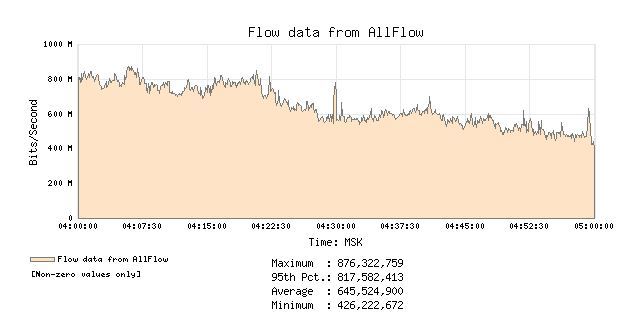
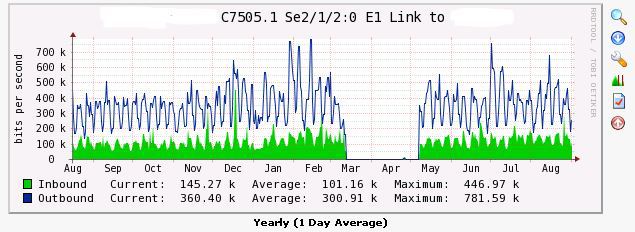
After the device is polled by the cactus, it is possible to create a graph based on data from the SNMP from a specific network interface or another sensor, whether it is the mains voltage at the PBI or the processor load at the switch.
Graph selection
Plug-ins to cactus to work with active equipment
Netflow
The main ideas are reports based on netflow flows. So, the first flowview plugin we need. A very simple plugin allows you to configure sources of flow in a graphical mode.
flowview config
As well as make samples based on flow of flows and build automatic reports on a schedule.
flowview schedules
Syslog and traps
I used two plugins to collect and analyze traps and syslog from Cisco.
This is camm and syslog.
camm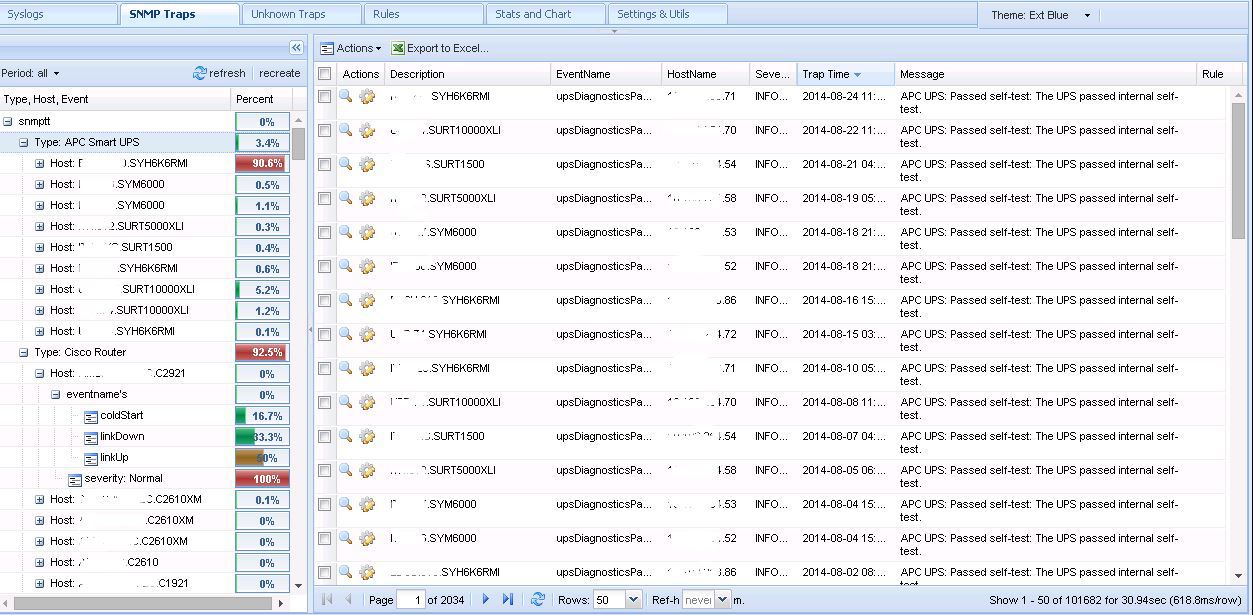
The first one impressed me with filters and the ability to create rules for events (for example, I received messages on corporate events in the corporate jabber).
camm rule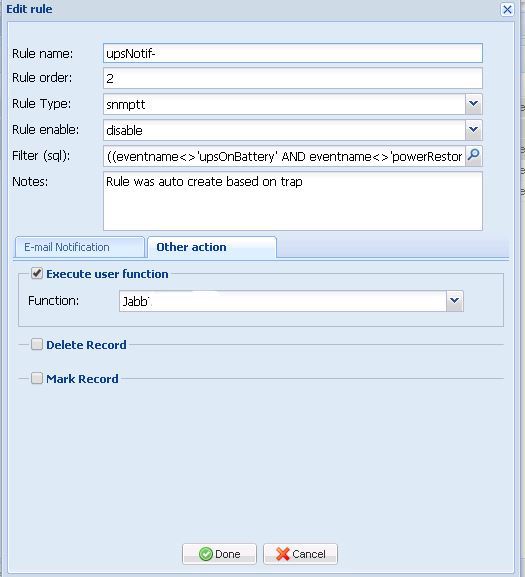
It is also very convenient grouping based on the MIB and the database of the cactus itself.
camm group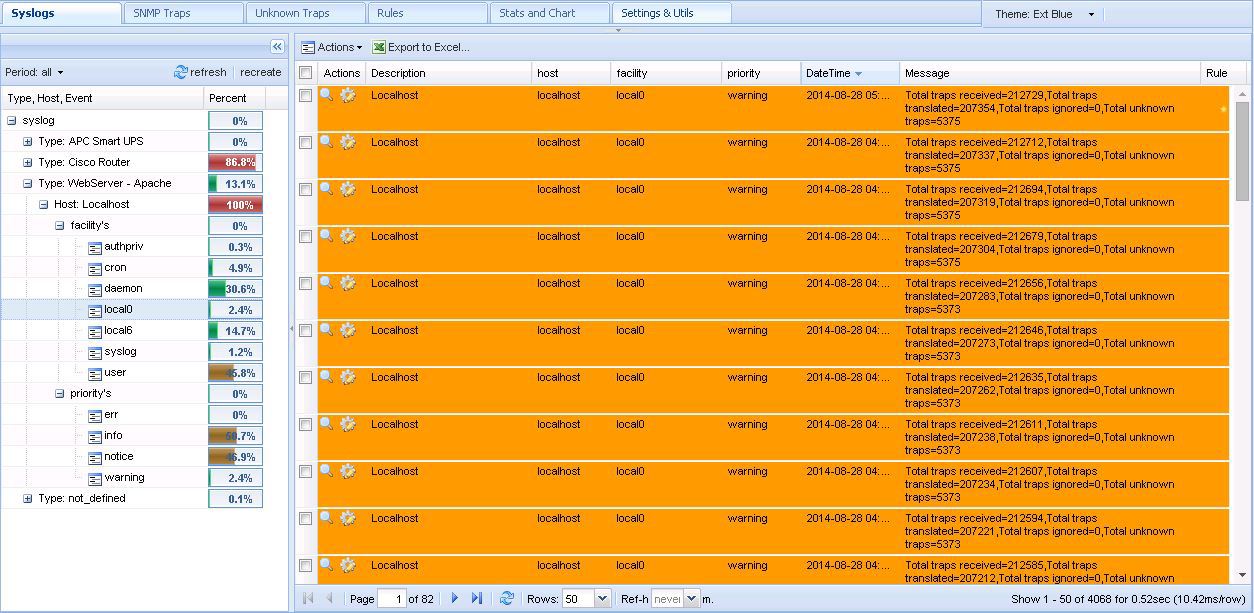
The second creates an autonomous database with a very transparent structure, to which I tied a functional written independently, but more on that later.
Network maps
Weathermap is the last plugin I use to monitor networks. He is beautiful and simple. Data is taken from the RRD database of the cactus itself, and the editor is similar to Paint.
Channels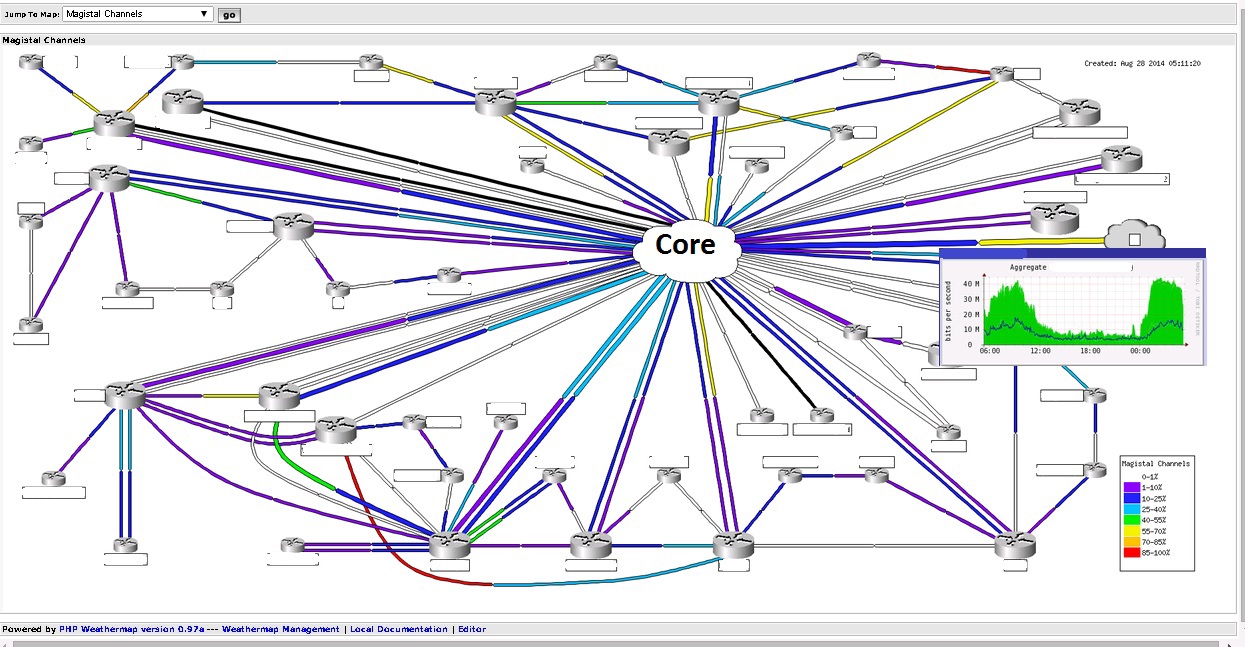
Allows you to graphically display the load of communication channels. So and possible problems with the channel.
A piece of weathermap configuration file.
Weathermap config example
NODE C7606.1 LABEL C7606.1 LABELOFFSET N INFOURL /cacti/graph.php?rra_id=all&local_graph_id=3691 OVERLIBGRAPH /cacti/graph_image.php?rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300&local_graph_id=3691 ICON images/Router_PU2.png POSITION 1132 180 NODE C7609#1 LABEL C7609#1 LABELOFFSET N INFOURL /cacti/graph.php?rra_id=all&local_graph_id=3366 OVERLIBGRAPH /cacti/graph_image.php?rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300&local_graph_id=3366 ICON images/Router_PU2.png POSITION 795 180 # regular LINKs: LINK C7606.1-C7609#1 INFOURL /cacti/graph.php?rra_id=all&local_graph_id=347 OVERLIBGRAPH /cacti/graph_image.php?local_graph_id=347&rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300 TARGET /var/www/cacti/rra/c7606_1_traffic_in_403.rrd NODES C7606.1:N20 C7609#1:N50 BANDWIDTH 40M LINK C7606.2-C7609#2 INFOURL /cacti/graph.php?rra_id=all&local_graph_id=340 OVERLIBGRAPH /cacti/graph_image.php?local_graph_id=340&rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300 TARGET /var/www/cacti/rra/c7606_1_traffic_in_396.rrd NODES C7606.1:N10 C7609#1:N50 BANDWIDTH 40M NetFlow setup
As our software collector, flow-tools will be used. This software can not only capture traffic, but also analyze it. Also, on the basis of this package, quite a few GUIs are written to display the collected information in a human form.
I was going to manage the flow-capture component from the flowview cactus plugin , so after installing the flow-tools , you need to copy the service launch script from the plugin folder to our init.d on the server.
Why all this fuss with the control system? Is it easier to fix the config manually and score? But it was not there. The number of devices of the order of 500 pieces with a very large amount of traffic. If you put all the flow in one folder, retrieving data for one hour of traffic will take more than 2 hours, this is unacceptable.
It was decided to separate the streams from each device into a separate folder so that the selection took place in a specific folder with the necessary traffic. Means flow-capture is done by exploding streams from devices on ports. Which means each device needs to be configured with a unique flow return port?
This is also unacceptable, so a simple little samplicator program comes to the rescue of solving this problem. The essence of the work is as follows: it accepts incoming UDP packets, sorts them according to the source address and transmits them to the selected port. And this means that we set up the equipment configuration on one port, and already on the server itself we distribute the flows on the ports.
Config syntax: Source / Mask: Destination1 / Port [Destination2 / Port] and example:
samplicate.conf
10.20.0.0/255.255.0.0
10.20.30.252/255.255.255.252:10.20.0.108/2057 0/2057
10.20.30.4/255.255.255.252:10.20.0.108/2058 0/2058
10.20.30.160/255.255.255.255:10.20.0.108/2059 0/2059
10.20.30.252/255.255.255.252:10.20.0.108/2057 0/2057
10.20.30.4/255.255.255.252:10.20.0.108/2058 0/2058
10.20.30.160/255.255.255.255:10.20.0.108/2059 0/2059
Flow collected, with horror we watch the speed of filling our disks. How can I see all this now?
There are many ways you can generate reports manually through the same flow-tools package. But not all users of the system can do this, and even those who can, must sweat to write a human report.
I turned to another great project FlowViewer .
When I dug it up and started using it, there was version 3.3 or something like that, 2006. While I figured out the 3rd version, the project suddenly came to life and began to develop, the 4th version was just brilliant, compared to the 3rd. At the time of this writing, the current version is 4.4 (I use 4.1).
At its core, it almost completely duplicates the flowview Cactus plug-in, but I liked the plug-in only with the existing schedule, its work on sampling is unstable, the filters are not complete, and there is no necessary aggregation. And architecturally the entire flow is stored on the second server, which means FlowViever is happy to be placed on the second server and provides beautiful graphics and samples with traffic.
flowviewer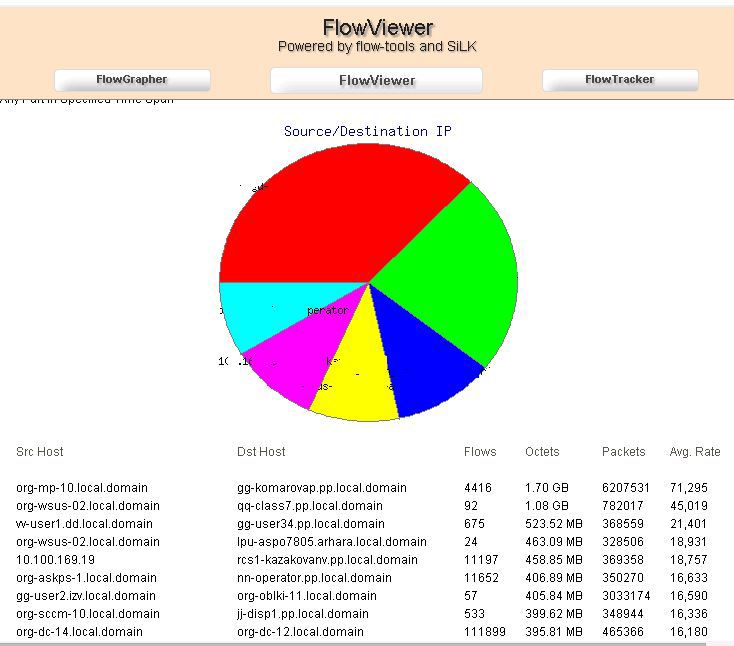
SNMP Traps
Flows with a flow are very good and tempting, but it is impossible to use them to alert about problems. Only for analysis after the problem has been fixed.
Well, the most accessible notification method is SNMP traps. Receiving SNMP traps from 500 devices in one list is not a very pleasant task, you will lose important information at the moment. It is clear that you need to do some kind of filter. There was no ready-made solution to satisfy my requirements. But it does not matter, remembering the craving for programming at the institute decided to write the trap analyzer itself.
The technology for obtaining a filtered list is as follows: when receiving a trap, the monitoring server receives ( snmptrapd ) it, analyzes ( snmptt ) in accordance with the loaded MIB specifications and immediately puts it into the database.
snmptt.conf
mysql_dbi_enable = 1
mysql_dbi_host = localhost
mysql_dbi_port = 3306
mysql_dbi_database = cacti
mysql_dbi_table = plugin_camm_snmptt
mysql_dbi_table_unknown = plugin_camm_snmptt_unk
mysql_dbi_table_statistics = plugin_camm_snmptt_stat
mysql_dbi_username = cacti
mysql_dbi_password = cacti
mysql_ping_on_insert = 1
mysql_ping_interval = 300
mysql_dbi_host = localhost
mysql_dbi_port = 3306
mysql_dbi_database = cacti
mysql_dbi_table = plugin_camm_snmptt
mysql_dbi_table_unknown = plugin_camm_snmptt_unk
mysql_dbi_table_statistics = plugin_camm_snmptt_stat
mysql_dbi_username = cacti
mysql_dbi_password = cacti
mysql_ping_on_insert = 1
mysql_ping_interval = 300
There is no sense in intercepting this processing, because you have to somehow start your own stack of events. This is of no use to us, especially the database to which the ladders fall into ours is filled with information about the devices (names, ports, links), which Cactus collects by means of the SNMP survey.
An attractive option is to take events from the base, link them with the existing base for informativeness. Armed with a notebook, I began to invent logic. There were no special problems with it, problems arose when sampling data from the database. Which began to take 30 seconds. About any efficiency here it is not shala. The theory of database optimization, query optimization, indexes, plans, and smart advice from my companion (a specialist in super-large databases) did their job.

The main idea is to filter Up / Down traps, in the description of which there are interface names (Eth, Serial, Gi, E), by identifiers and source we look for data in the table with SNMP. At the output we get a beautiful line, when , where and where the link fell.
MySQL Select: Channel Status
Select MAX(sd.id), sd.id_channel, sd.`status`, sd.diff, MAX(sd.date) as 'date', MIN(sd.date2) as 'date2', SUM(UNIX_TIMESTAMP(sd.date)-UNIX_TIMESTAMP(sd.date2)) as 'time', MAX(sd.id_trap) as 'id_trap', `host`.description, channel_list.ch_name from ( SELECT a.id, a.id_channel, a.`status`, UNIX_TIMESTAMP(NOW())-UNIX_TIMESTAMP(a.date) as 'diff', a.date, (select CASE cs2.`status` WHEN a.`status` THEN null ELSE cs2.`date` END from custom_status AS cs2 where cs2.id_channel = a.id_channel and cs2.date = (select MAX(cs.date) from custom_status cs where cs.date < a.date and cs.id_channel = a.id_channel ) LIMIT 1 ) as 'date2', a.id_trap FROM custom_status AS a JOIN (SELECT t.id_channel, MAX(t.date) AS max_date FROM custom_status t GROUP BY t.id_channel) AS b ON b.id_channel= a.id_channel) sd INNER JOIN channel_list ON channel_list.id = sd.id_channel INNER JOIN `host` ON channel_list.hostname = `host`.hostname where sd.`status` = 'linkUp' AND sd.date between DATE_SUB(CURDATE(),INTERVAL MOD(DAYOFWEEK(CURDATE())-2,7)+7 DAY) AND DATE_ADD(CURDATE(), INTERVAL MOD(7 - (DAYOFWEEK(CURDATE()) - 1), 7)-6 DAY) GROUP BY sd.id_channel,sd.`status` ORDER BY date desc" All data from the database are made in a readable form in the form of html pages.
Info from traps
Samples from the database receiving different conditions, form different plates of reports.
Detail info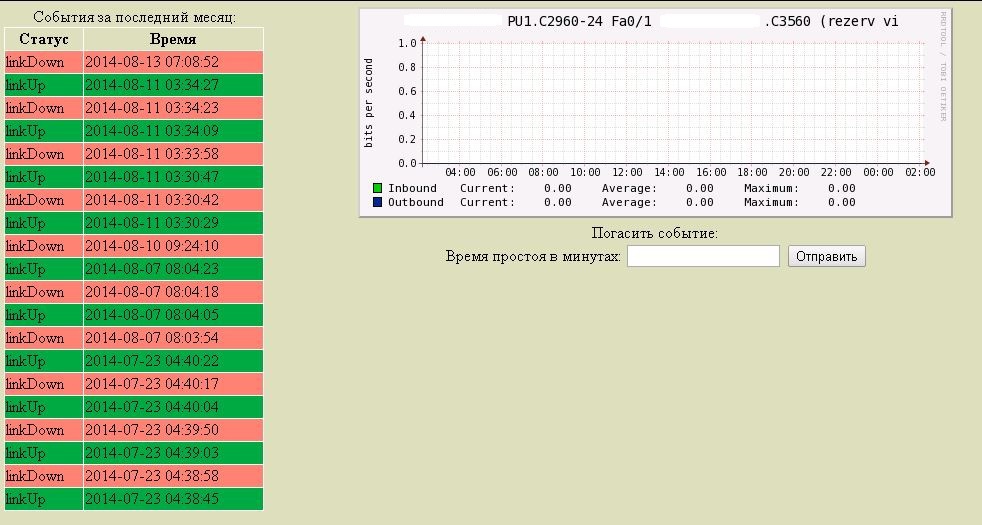
I thank the reader who mastered all my confused narration. Partly due to the fact that the system has been working for more than a year without me. Much has been forgotten, something has lost its meaning. But monitoring is still working, collecting data and providing samples already without my support.
All data, screenshots and configs are depersonalized. Any matches are random.
Source: https://habr.com/ru/post/235459/
All Articles