Asynchronous multithreaded pool of Perl workers

In the work of a web service, and indeed of many other systems, there is often a need to perform various background tasks. To do this, write scripts - workers - who take a list of existing tasks and begin to perform them - with some speed and in some sequence.
It is clear, well, when all tasks are performed quickly and without delay.
')
To speed up the execution of tasks, it is desirable to solve two problems:
- Teach the worker not to wait for the execution of each individual stage of the task (asynchrony)
- To teach a worker to perform several tasks simultaneously (multithreading) (disclaimer: in fact, the term “multithreading” is used here to mean “multiprocessing”)
In this article, we will look at an implementation option for a worker that is both asynchronous and multithreaded.
AnyEvent module
For programming in asynchronous mode in Perla there is an excellent AnyEvent module.
Just in case, you should say that AnyEvent is actually a wrapper over other low-level asynchronous modules. As DBI is a wrapper and universal interface to different databases, so AnyEvent is a wrapper and universal interface to various implementations of asynchronous engines.
AnyEvent has a huge number of various extensions, including an extension for writing multi-threaded applications - the AnyEvent :: Fork :: Pool module.
The AnyEvent :: Fork :: Pool module provides an easy way to create a pool of workers who will handle tasks in asynchronous multithreaded mode.
Script
Consider the anyevent_pool.pl script:
#!/usr/bin/perl use strict; use warnings; use AnyEvent::Fork::Pool; # my $mod = 'Worker'; # my $sub = 'work'; # my $cpus = AnyEvent::Fork::Pool::ncpu 1; # my $pool = AnyEvent::Fork ->new ->require ($mod) ->AnyEvent::Fork::Pool::run( "${mod}::$sub", # :: - init => "${mod}::init", # ::init - max => $cpus, # idle => 0, # load => 1, # ); # for my $str (qw{q2 rtr4 ui3 asdg5}) { $pool->($str, sub { print "result: @_\n"; }); }; AnyEvent->condvar->recv; Despite its small size, this script is a complete asynchronous multi-threaded application.
We analyze it in parts.
Variables
# my $mod = 'Worker'; # my $sub = 'work'; These variables define a link between the pool and the code that will execute specific background tasks. The pool is one for all, and the tasks may be different. These variables tell the pool which code (which function from which module) you want to run to perform a specific task.
For example, you might have a Text module for text processing, and in a module, functions length and trim. And you can also have an Image module, in which there can be resize and crop functions. Pula is completely indifferent to what your functions do and how they work. You just need to tell the pool what module they are in and what they are called, and the pool will execute them.
Important! The module of the worker does not need to be connected in the script through the use Worker. The pool itself automatically loads the module of the worker, you only need to correctly specify the name of the module in the variable.
Number of Cores
# my $cpus = AnyEvent::Fork::Pool::ncpu 1; For multithreaded tasks, it is desirable to know how many cores are in the system. It is desirable that the number of threads that you will run is equal to the number of cores. If there are less threads, some cores will be idle in vain, if there will be more threads, some threads will get in the queue and instead of acceleration you will get dispatching losses.
If for some reason the number of cores could not be determined, then the value specified manually will be used. In this case, it is 1.
Pool
# my $pool = AnyEvent::Fork ->new ->require ($mod) ->AnyEvent::Fork::Pool::run( "${mod}::$sub", # :: - init => "${mod}::init", # ::init - max => $cpus, # idle => 0, # load => 1, # ); Explanation of the parameters:
- The work function of the worker must always be specified by the first parameter. This is the same function of that module that we specified in the first two "tuning" variables $ mod and $ sub. This is the only required parameter.
- init - If your worker needs initialization, then in this parameter you can specify the name of the initialization function. In this case, the name of the function is indicated as “init”, since this is the usual name for such a function, but, in principle, you can specify any other name.
- max - This parameter sets the number of threads that the pool will start. It is here that you should specify the previously determined number of cores in the system (but if you want, you can specify any number if you know what you are doing).
- idle - here you can see the number of workers who will wait “at a low start”. The greater this number (but not more than the max parameter), the faster the pool will react to the new incoming task, but the more there will be no useless waiting (and resource-consuming) processes.
- load - How many tasks will be given to each worker without waiting for the previous ones to be executed. The value strongly depends on the situation - in some cases less is better, in some better more. Other things being equal, greater importance should increase the efficiency of the pool (wholesale - cheaper).
There are also other options that I do not consider here. They are highly specific and rarely required. A complete list of parameters can be found in the module documentation.
Task setting pool
# for my $str (qw{q2 rtr4 ui3 asdg5}) { $pool->($str, sub { print "result: @_\n"; }); }; An arbitrary number of parameters can be passed to the pool, but the last parameter should be a callback. Callback is an anonymous function that will be called after the worker has completed the task. The results of the work of the worker will be transferred to this function.
In other words - this function is the recipient of the results of the function $ sub. All that $ sub returns will be passed as arguments to the callback function. Conventionally, this relationship can be written something like this - "callback ($ sub)".
In our case, the callback function simply prints everything it receives.
The $ str variable is, in fact, the very task that the worker must perform. In our case, this is just one line (more precisely, 4 lines, launched in a loop). The lines here have no deep meaning, I just called the cat to walk on the keyboard.
Depending on the situation, instead of a line, there can be anything, such as the file name, the record identifier in the database, a mathematical expression, a link to a complex data structure ... in short, anything. Pula no matter what it is, he does not handle this value. The pool simply transfers this value to the worker, but he should already know what to do with it.
Run engine
AnyEvent->condvar->recv; This line tells the AnyEvent module to start the event engine and continue to work endlessly.
At this point, the script will loop. The given example has no way to stop and exit an infinite task processing loop. The issue of conditional exit from the AnyEvent loop is more general, and here I want to consider only the special case of using the pool. About the conditional exit from the cycle you can read here .
Self worker
Now the question arises - where, in fact, is the worker himself? Where is the code that executes the actual work?
This code is placed in a separate module, which we specified in the $ mod variable.
Here is the code for the Worker module:
package Worker; use strict; use warnings; my $file; sub init { open $file, '>>', 'file.txt'; my $q = select($file); $|=1; select($q); return; } sub work { my ($str) = @_; for (1..length($str)) { print $file "$$ $str\n"; sleep 1; }; return $str, length($str); } 1; As you can see, in the module there are two functions - init and work.
The init function initializes the worker. In our case, the function opens the log file, which will later display the results of the work function work. As mentioned above, the init function is optional; in our case, I made it just for clarity.
The work function is the main function. This is the same work function that was specified in the $ sub variable. It is in this function that all the work related to the performance of a specific task is performed.
In our case, the function performs the simplest work — it calculates the length of the string. For a more visual demonstration of the work of the worker, I added a second-delay cycle to the function, which displays the line to the log as many times as there are letters in the line.
Please note - the function returns two values - the string itself and its length. It is these two values that will be transferred to the callback specified at the stage of problem statement for the pool (and in the callback, as mentioned above, these values will be simply printed).
That's the whole code.
Start the pool
Now let's run our pool and see what happens:

Here we see the results of the pool. You may notice that the order of output of the results is different from the order of the lines specified in the loop in the script. The reason is clear - the strings have different lengths, so workers handle strings with different speeds. The simpler the task - the faster it is executed.
Now let's look not just at the results, but also at the work process of the workers. To do this, run tail for the log file in the second window:
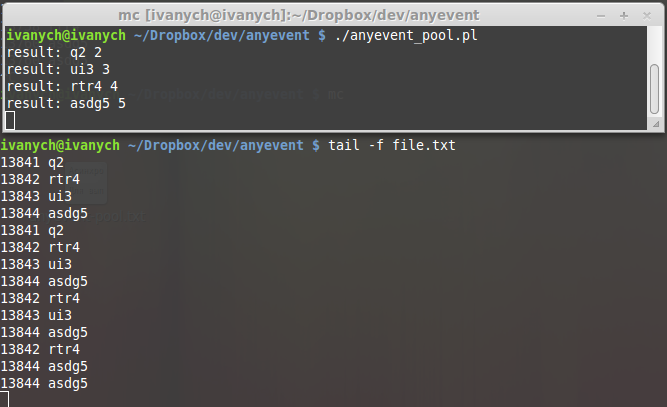
Please note - the results of the work are mixed, as the tasks are performed simultaneously. The process identifiers are visible on the left - we see that 4 processes are involved. I have 4 cores in the system, so all 4 tasks are performed simultaneously.
And finally, let's look at the process table:

This is the process tree of our pool.
The first in the list is the script, then the pool manager (yes, there can be several pools), then the pool manager, and finally the workers.
If you do not be lazy and compare the identifiers of the processes, then you can see that the identifiers of the workers coincide with the identifiers in the log file.
Literature
Source: https://habr.com/ru/post/234835/
All Articles