Setting up PostgreSQL monitoring in Zabbix

PostgreSQL is a modern, dynamically developing database with a very large set of features that allow you to solve the widest range of tasks. Using PostgreSQL usually refers to a very critical segment of IT infrastructure that is associated with data processing and storage. Considering the special place of the DBMS in the infrastructure and the degree of criticality of the tasks assigned to it, the question arises of monitoring and proper control over the work of the DBMS. In this regard, PostgreSQL has extensive internal means of collecting and storing statistics. Collected statistics allows you to get a pretty detailed picture of what is happening under the hood in the process of the DBMS functioning. These statistics are stored in special system tables-views and are constantly updated. By performing regular SQL queries in these tables, you can get a variety of data about databases, tables, indexes, and other DBMS subsystems.
Below I describe the method and means for monitoring PostgreSQL in the Zabbix monitoring system. I like this monitoring system because it provides ample opportunities for the implementation of the most custom monitoring of various systems and processes.
Monitoring will be built on the basis of SQL queries to statistics tables. The queries themselves are in the form of an additional configuration file for the zabbix agent, in which SQL queries are wrapped in a so-called. UserParameters - user monitoring parameters. Zabbix user parameter is a great way that allows you to customize monitoring for non-standard things, such things in our case will be PostgreSQL operation parameters. Each user parameter consists of two elements: Key name and Command . The key name is a unique name that does not overlap with other key names. A command is the actual command-action that the zabbix agent must perform. In the extended version, various parameters can be passed to this command. In a zabbiks configuration, it looks like this:
UserParameter=custom.simple.key,/usr/local/bin/simple-script UserParameter=custom.ext.key[*],/usr/local/bin/ext-script $1 $2 Thus, all requests for PostgreSQL statistics are psql client requests wrapped in user parameters.
Strengths:
- minimum requirements for configuring the observed node - in the simplest case, we add the config and restart the zabbix agent (a complex case involves donning access rights to PostgreSQL);
- PostgreSQL connection settings, as well as thresholds for triggers, are performed via macro variables in the web interface - this way you do not need to climb into triggers and create a pattern in case of different threshold values for different hosts (macros can be assigned to a host);
- a wide range of data collected (connections, transaction time, statistics on databases and tables, streaming replication, etc.);
- low-level detection for databases, tables, and stand-by servers.
Weak sides:
- a lot of observed parameters, maybe someone wants to disable something.
- depending on the PostgreSQL version, things will not work. In particular, this concerns replication monitoring, since Some functions are simply not available in older versions. It was written with an eye on version 9.2 and higher.
- some things also require the presence of installed pg_stat_statements and pg_buffercache extensions - if the extensions are not installed, some of the parameters will not be available for monitoring.
Monitoring capabilities:
- information on the volume of allocated and recorded buffers, checkpoints and recording time in the process of checkpoints - pg_stat_bgwriter
- General information on shared buffers - pg_buffercache extension is required here. I also want to note that requests for these statistics are resource intensive, which is reflected in the documentation for the extension, so depending on the needs, you can either increase the polling interval or turn off the parameters altogether.
- general information on the service - uptime, response time, cache hit ratio, average request time.
- information on client connections and query / transaction execution time - pg_stat_activity .
- database size and summary statistics for all databases (commits / rollbacks, read / write, temporary files) - pg_stat_database
- table statistics (read / write, number of service tasks such as vacuum / analyze) - pg_stat_user_tables , pg_statio_user_tables .
- streaming replication information (server status, number of replicas, lag with them) - pg_stat_replication
- other things (number of rows in the table, the existence of a trigger, configuration parameters, WAL logs)
Additionally, it is worth noting that to collect statistical data, it is necessary to include the following parameters in postgresql.conf:
track_activities - includes command tracking (queries / statements) by all client processes;
track_counts - includes collecting statistics on tables and indexes;
Installation and configuration.
Everything you need to configure is in the Github repository.
# git clone https://github.com/lesovsky/zabbix-extensions/ # cp zabbix-extensions/files/postgresql/postgresql.conf /etc/zabbix/zabbix_agentd.d/ Further, it should be noted that to execute requests from the agent, it is necessary that the appropriate access is defined in the pg_hba configuration — the agent must be able to establish connections with the postgres service to the target database and execute the requests. In the simplest case, you need to add the following line to pg_hba.conf (for different distributions, the file location may be different) - we allow connections from the name of postgres to the mydb database from localhost.
host mydb postgres 127.0.0.1/32 trust It’s unforgettable that after changing pg_hba.conf, the postgresql service needs to reload (pg_ctl reload). However, this is the easiest option and not entirely secure, so if you want to use a password or a more complex access scheme, then once again carefully read pg_hba and .pgpass .
')
So, the configuration file is copied, it remains to load it into the main configuration, make sure that there is an Include line in the main agent configuration file in the path specified where the additional configuration files are located. Now we restart the agent, after which we can check the work by performing the simplest check - we use pgsql.ping and in square brackets we specify the connection options to postgres, which will be transferred to the psql client.
# systemctl restart zabbix-agent.service # zabbix-get -s 127.0.0.1 -k pgsql.ping['-h 127.0.0.1 -p 5432 -U postgres -d mydb'] If you have correctly registered the access, then the service response time in milliseconds will return to you. If an empty string is returned, then there is a problem with accessing pg_hba. If the ZBX_NOTSUPPORTED string is returned - the configuration did not load, check the agent configuration, paths to Include and rights set to the configuration.
When the verification command returns the correct answer, it remains to download the template and upload it to the web interface and assign it to the target host. You can also download the template from the repository (postgresql-extended-template.xml). After importing, you need to go to the template macro settings tab and configure them.

Below is a list and brief description:
- PG_CONNINFO are the connection parameters that will be transferred to the psql client when the request is executed. This is the most important macro because defines the parameters for connecting to the postgres service. The default string is more or less universal for any cases, but if you have several servers and each server has different settings, then the hosts in the zabbiks can define a macro with the same name and set an individual value for it. When performing a check, the host macro takes precedence over the template macro.
- PG_CONNINFO_STANDBY is the connection parameters that will be transferred to the psql utility when executing a request to the stanby server (definition of replication lag).
- PG_CACHE_HIT_RATIO is the trigger threshold for the percentage of successful cache hits; the trigger will work if the percentage of hit is below this mark;
- PG_CHECKPOINTS_REQ_THRESHOLD - threshold for checkpoint on demand
- PG_CONFLICTS_THRESHOLD - threshold value for conflicts that occurred when executing queries on standby servers;
- PG_CONN_IDLE_IN_TRANSACTION - threshold value for connections that opened a transaction and do nothing at the same time (bad transactions);
- PG_CONN_TOTAL_PCT - threshold value for the percentage of open connections to the maximum possible number of connections (if 100%, then all connections terminated);
- PG_CONN_WAITING - the threshold for blocked requests that are waiting for the completion of other requests;
- PG_DATABASE_SIZE_THRESHOLD - threshold value for database size;
- PG_DEADLOCKS_THRESHOLD - threshold value for deadlocks (fortunately they are resolved automatically, but you should be aware of their presence, because this is direct evidence of poorly written code);
- PG_LONG_QUERY_THRESHOLD - threshold value for query execution time; the trigger will be triggered if there are requests whose execution time is greater than this mark;
- PG_PING_THRESHOLD_MS - threshold value for service response time;
- PG_SR_LAG_BYTE - threshold for replication lag in bytes;
- PG_SR_LAG_SEC — threshold value for replication lag in seconds;
- PG_UPTIME_THRESHOLD - uptime threshold value, if uptime is below the mark, the service has been restarted;
From the text of the triggers it should be clear why these threshold values are needed:
- PostgreSQL active transaction to long - a long transaction or request is fixed;
- PostgreSQL cache hit ratio too low - a very low cache hit rate;
- PostgreSQL deadlock occured - deadlock fixed;
- PostgreSQL idle in transaction connections to high - many connections in idle in transaction state;
- PostgreSQL idle transaction to long - a long transaction is fixed in the state idel in transaction;
- PostgreSQL number — a request or transaction is pending;
- PostgreSQL recovery conflict occured - a conflict was detected during recovery on a replica;
- PostgreSQL required checkpoints occurs to frequently - checkpoints happen too often;
- PostgreSQL response to long - long response time;
- PostgreSQL service not running - the service is not running;
- PostgreSQL service was restarted - the service was restarted;
- PostgreSQL total number of connections to high - the total number of connections is too large and is approaching max_connections;
- PostgreSQL waiting transaction to long - the request or transaction is in a waiting state;
- PostgreSQL database {#DBNAME} to large - the size of the database is too large;
- PostgreSQL streaming lag between {HOSTNAME} and {#HOTSTANDBY} to high - the replication lag between servers is too high.
Low Level Discovery Rules
- PostgreSQL databases discovery - detection of existing databases with the ability to filter by regular expressions. At detection the schedule about the sizes is added;
- PostgreSQL database tables discovery - detection of existing tables in the observed database with the ability to filter by regular expressions. Be careful with the filter and add only those tables that you are really interested in, because this rule generates 21 parameters for each table found. When detected, charts are added about sizes, scans, line changes, and reading statistics.
- PostgreSQL streaming stand-by discovery - detection of connected replicas. At detection the schedule with a replication lag is added.
Available graphics, if we talk about graphics, I tried to group the observed parameters, while not overloading the graphics with an excessively large number of paramters. So the information from pg_stat_user_tables is separated into 4 graphs.
- PostgreSQL bgwriter - general information about what is happening with the buffers (how much is allocated, how much and how is recorded).
- PostgreSQL buffers - general information on the status of shared buffers (how many buffers, how many are used, how many "dirty" buffers).
- PostgreSQL checkpoints - information on ongoing checkpoints.
- PostgreSQL connections - information on client connections.
- PostgreSQL service responce - service response time and average query execution time.
- PostgreSQL summary db stats: block hit / read - read from cache and from disk.
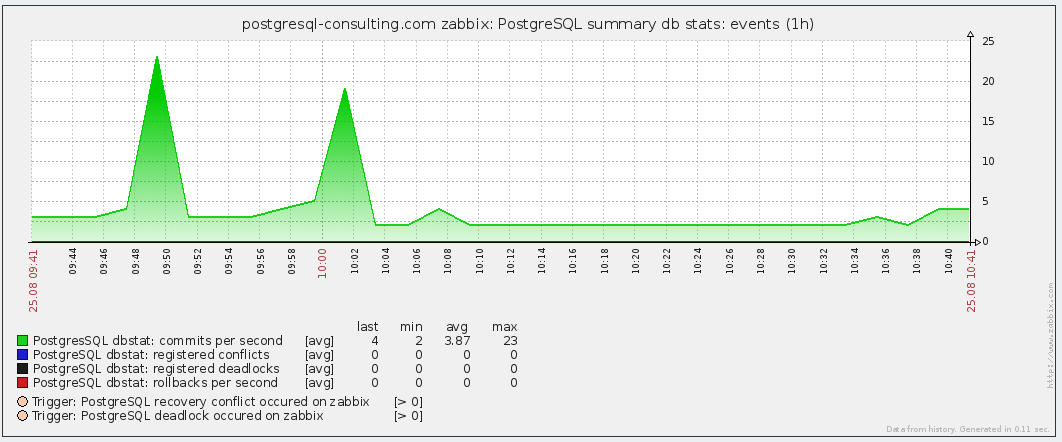
- PostgreSQL summary db stats: events - events in the database (deadlocks, conflicts, commits, rollbacks).
- PostgreSQL summary db stats: temp files - information on temporary files.
- PostgreSQL summary db stats: tuples - general information on row changes.
- PostgreSQL transactions - query execution time.
- PostgreSQL uptime - uptime and cache hit percentage.
- PostgreSQL write-ahead log - information on the WAL log (recording volume and number of files).
- PostgreSQL: database {#DBNAME} size - information on changing the size of the database.
- PostgreSQL table {#TABLENAME} maintenance - table maintenance operations (autovacuum, autoanalyze, vacuum, analyze).
- PostgreSQL table {#TABLENAME} read stats - statistics for reading from the cache disk.
- PostgreSQL table {#TABLENAME} rows - change in rows.
- PostgreSQL table {#TABLENAME} scans - information on scanning (sequential / index scans).
- PostgreSQL table {#TABLENAME} size - information on the size of tables and their indexes.
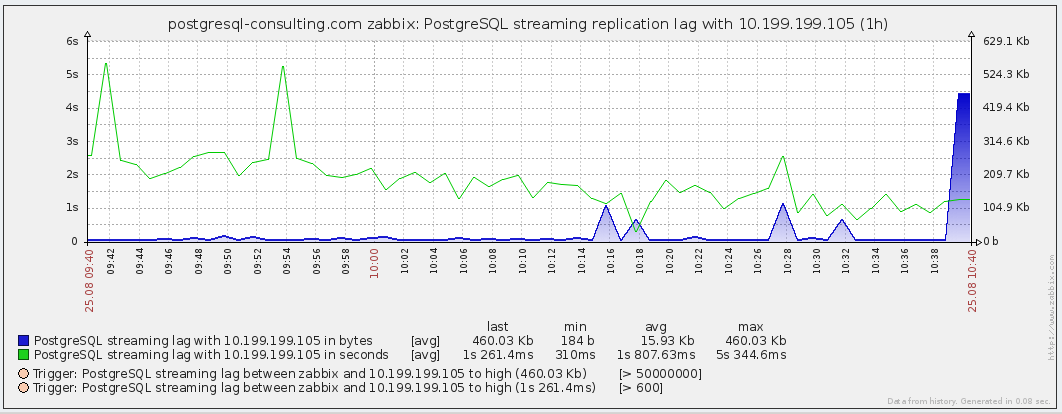
- PostgreSQL streaming replication lag with {#HOTSTANDBY} - the size of the replication lag with replica servers.
Finally, a few sample graphics:
Here, as we can see, temporary files are regularly created in the database, you should look for the culprit in the log and review work_mem.

Here, events taking place in the database - commits / rollbacks and conflicts / deadlocks - everything is alright here in general.
Here the status of streaming replication with one of the servers is the lag time in seconds and bytes.
And the final graph is the service response time and average request time.

That's all, thank you all for your attention!
Source: https://habr.com/ru/post/234481/
All Articles