What is the use of ZooKeeper for admins and developers. Yandex Workshop
Hello! My name is Andrey Stepachev. At the end of last year, I spoke to my colleagues with a short story about what ZooKeeper is and how it can be used. The report was originally designed for a wide range of audiences and can be useful for developers and administrators who want to figure out how it all works.
Let's start with the story of the appearance of ZooKeeper. First, as you know, Google wrote the Chubby service to manage their servers and their configuration. At the same time solved the problem with distributed locks. But Chubby had one peculiarity: in order to capture the locks, it was necessary to open the object, then close it. Performance suffered from this. Yahoo considered that they needed a tool with which they could build various systems for their cluster configurations. This is the main purpose of ZooKeeper - storage and configuration management of certain systems, and locks turned out as a by-product. As a result, the whole system was created to build various primitive synchronizations with client code. In ZooKeeper itself, there are no obvious concepts for such queues, all this is implemented on the side of client libraries.
It should be noted that the protocol used by Zookeeper is called ZAB, links to the protocol descriptions are given at the end of the article.
')
The basis of ZooKeeper is a virtual file system, which consists of interconnected nodes, which represent the combined concept of a file and directory. Each node of this tree can simultaneously store data and have subordinate nodes. In addition, there are two types of nodes in the system: there are so-called persistent nodes that are saved to disk and never disappear, and there are ephemeral nodes that belong to a particular session and exist as long as it exists.
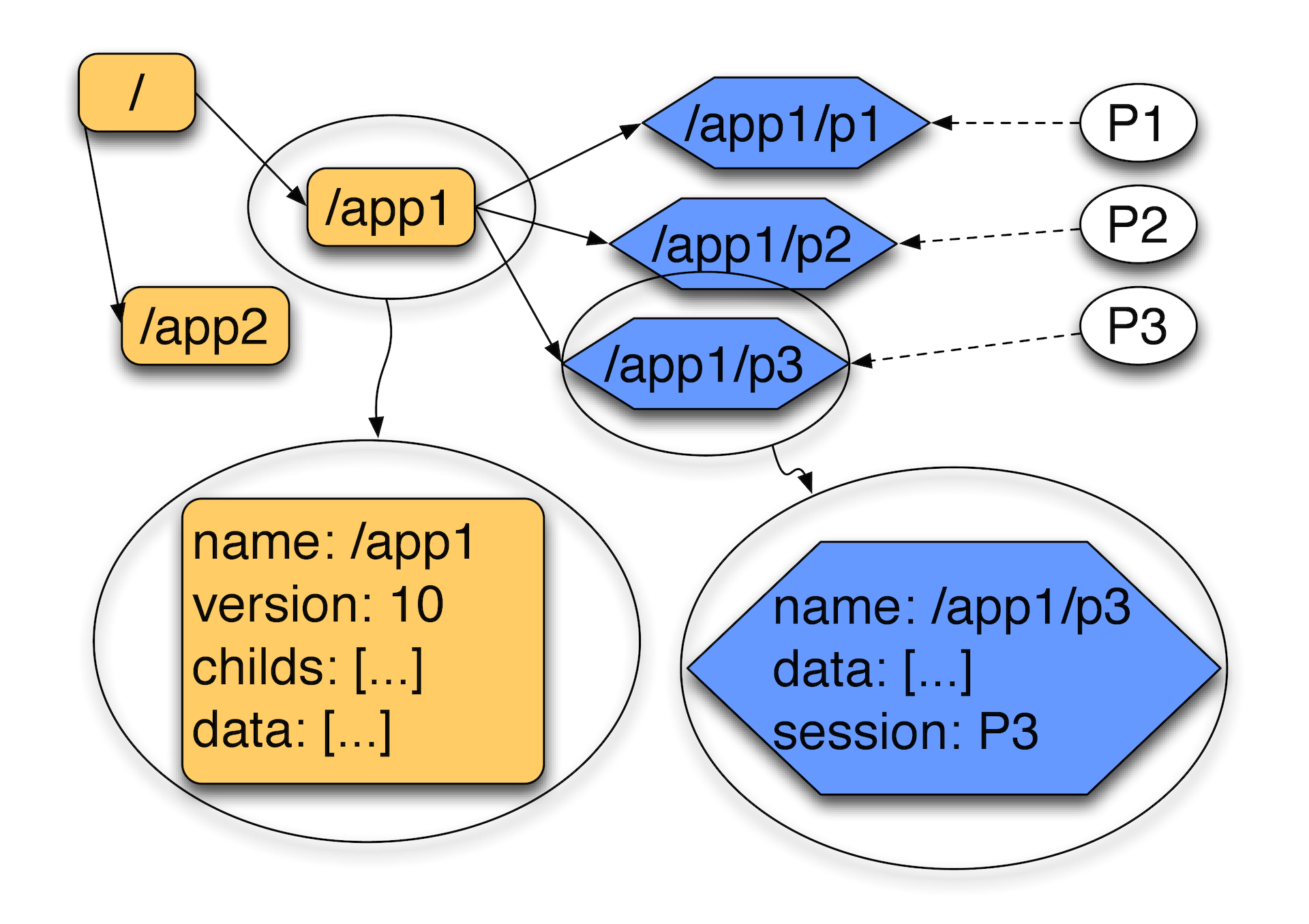
In the picture, the letters P are marked customers. They establish sessions — active connections to the ZooKeeper server, within which heartbeat packets are exchanged. If during one third of the timeout we did not hear the heartbeat, after two thirds of the timeout, the client library will join the other ZooKeeper server until the session on the server has had time to disappear. If the session disappears, the ephemeral nodes (indicated in blue in the diagram) disappear. They usually have an attribute that indicates which session owns them. Such nodes can not have children, it is strictly an object in which you can save some data, but you can not make dependent.
The ZooKeeper developers thought that it would be very convenient to have it all in the form of a file system.
The second basic thing for ZooKeeper is the so-called synchronous implementation of recording and FIFO processing of messages. The idea is that the entire sequence of commands in ZooKeeper is strictly ordered, i.e. This system supports total ordering.
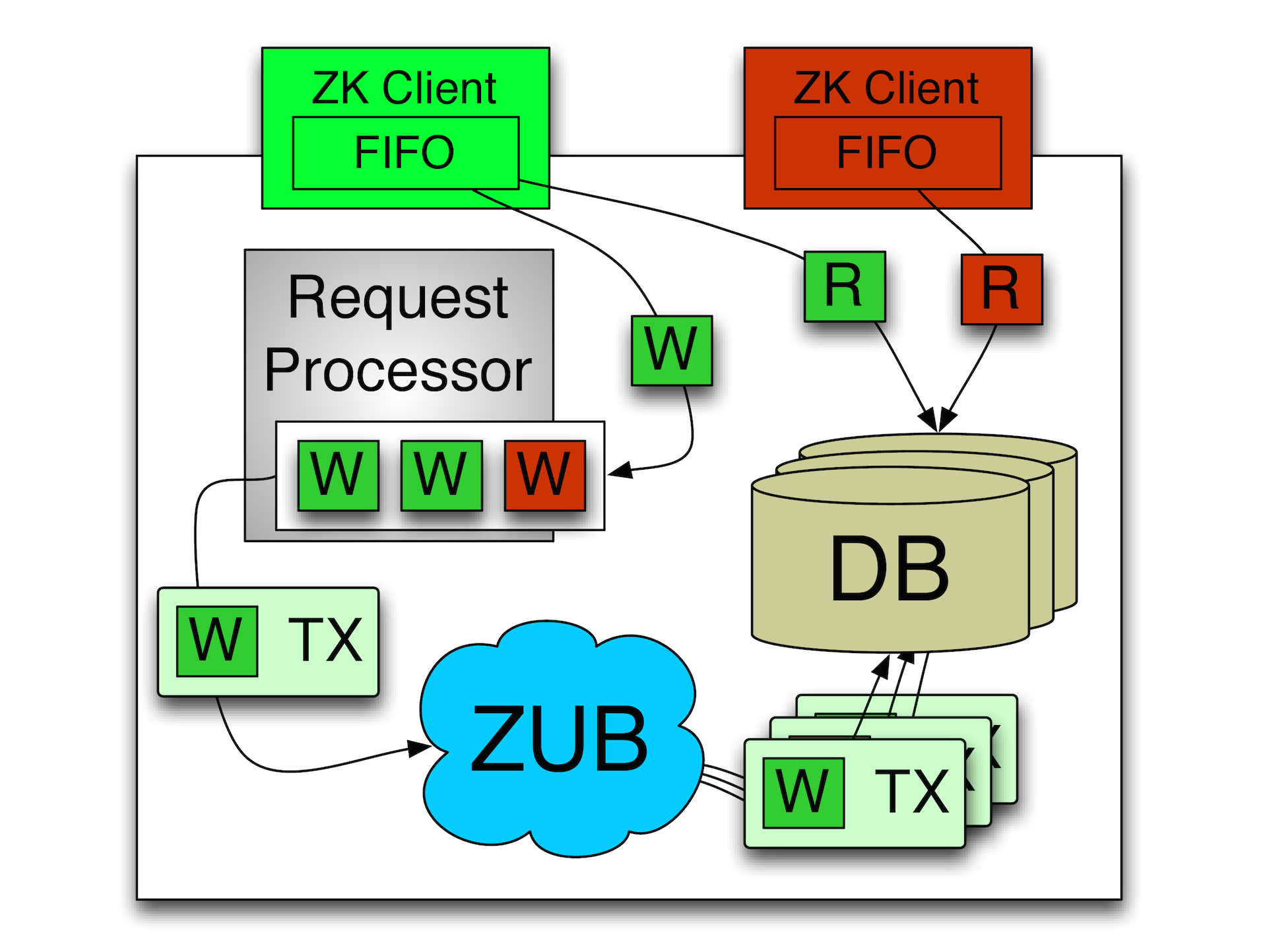
All operations in ZooKeeper turns into this idempotent operation. If we want to change some kind of node, then we create a record that we have changed it, while remembering the version of the node that was and will be. Due to this, we can receive the same message many times, while we will know exactly at what point you can apply it. Accordingly, any recording operations are carried out strictly sequentially in one stream, in one server (master). There is a leader who is selected between several typewriters, and only he performs all the operations for writing. Readings can occur from the replica. In this case, the client runs a strict sequence of its operations. Those. if he sent the write and read operation, the write will be executed first. Even though the read operation could be performed without blocking, the read operation will be performed only after the previous write operation has been completed. Due to this, it is possible to implement predictable asynchronous systems with ZooKeeper. The system itself is mainly focused on asynchronous operation. The fact that client libraries implement a synchronous interface is for the convenience of the programmer. In fact, the high performance of ZooKeeper ensures precisely asynchronous operation, as it usually happens.
How does all this work? There is one leader plus a few followers. Changes are applied using a two-phase commit. The main thing that ZooKeeper is focused on is that it works on TCP plus total ordering. In general, the ZAB protocol (ZooKeeper Atomic Broadcast) is a simplified version of Paxos , which, as you know, is experiencing message reordering, able to deal with it. ZAB does not know how to deal with this, it is initially focused on a completely ordered stream of events. There is no parallel processing, but often it is not required, because the system is focused more on reading than on writing.
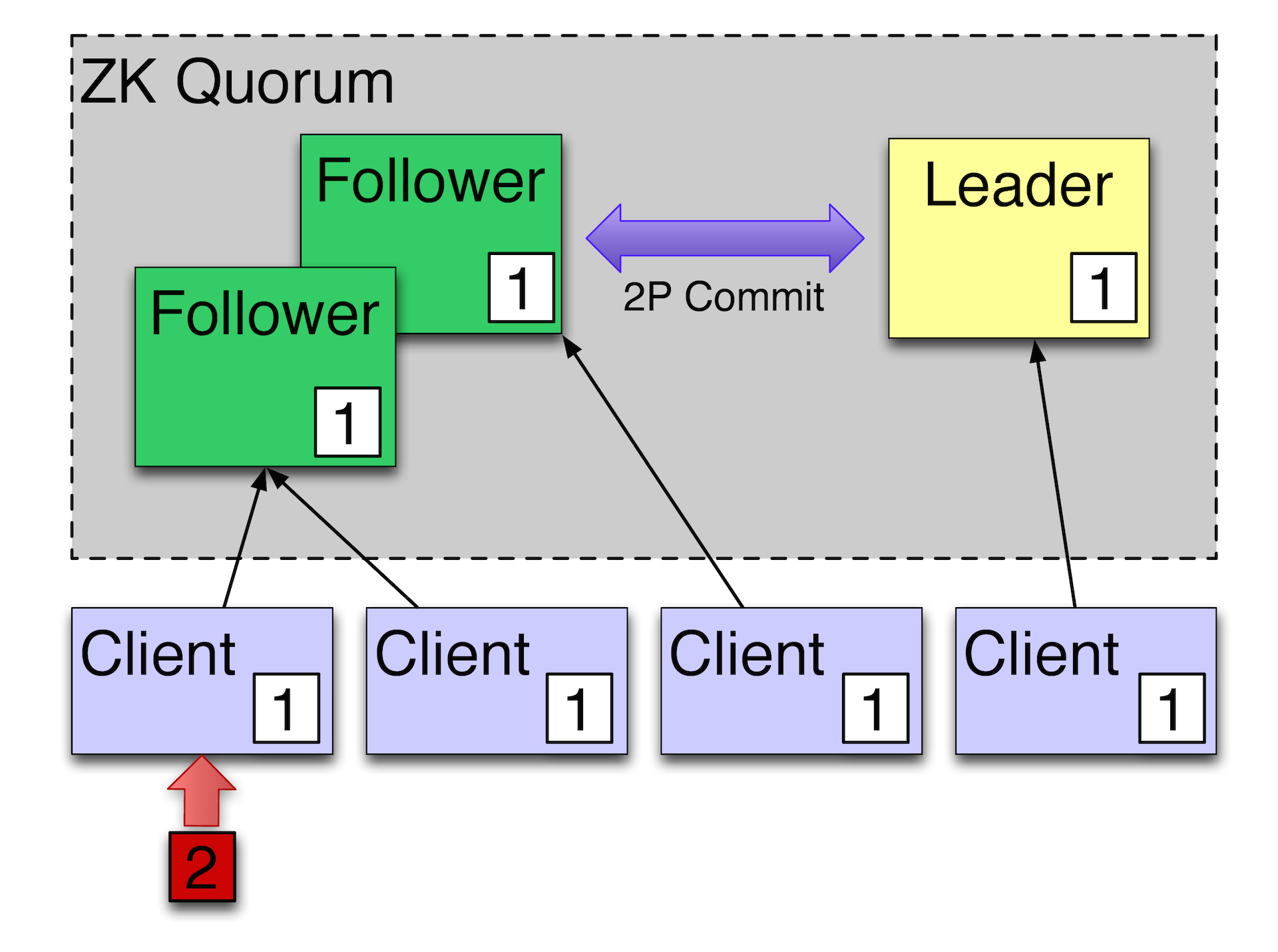
For example, we have such a cluster, there are customers. If customers now do the reading, they will see the value that the followers are now seeing, believe that now the value of a certain field is now 1. If we write 2 in some client, the follower will perform the operation through the leader and receive a new state as a result.

For the leader to be considered successful, the leader needs at least 2 of 3 machines to confirm that they have reliably saved these data. Imagine that we have this follower, which is from 1, now, for example, in some Amsterdam or other remote DC. He is behind the rest of the followers. Consequently, the local machines will already see 2, and that remote follower, if the client reads from it before the follower has time to catch up with the master, he will see a lagging value. In order for it to read the correct value, you need to send a special command so that ZooKeeper is forcibly synchronized with the master. Those. at least at the time of execution of the sync command, it will be known for sure that we received the state rather fresh in relation to the master. This is called slow read. Usually we read very quickly, but if everyone uses slow reading, it is clear that the entire cluster will always be read from the master. Accordingly, there will be no scaling. If we read quickly, allow ourselves to lag behind, then we can scale to read quite well.
Recipes of use
Configuration management
The first and most basic application is configuration management. We write some settings in Zookeper, for example, the URL of the connection with the base or just a flag that prohibits or allows some service inside our cluster to work. Accordingly, cluster members subscribe to the configuration section and monitor its modifications.
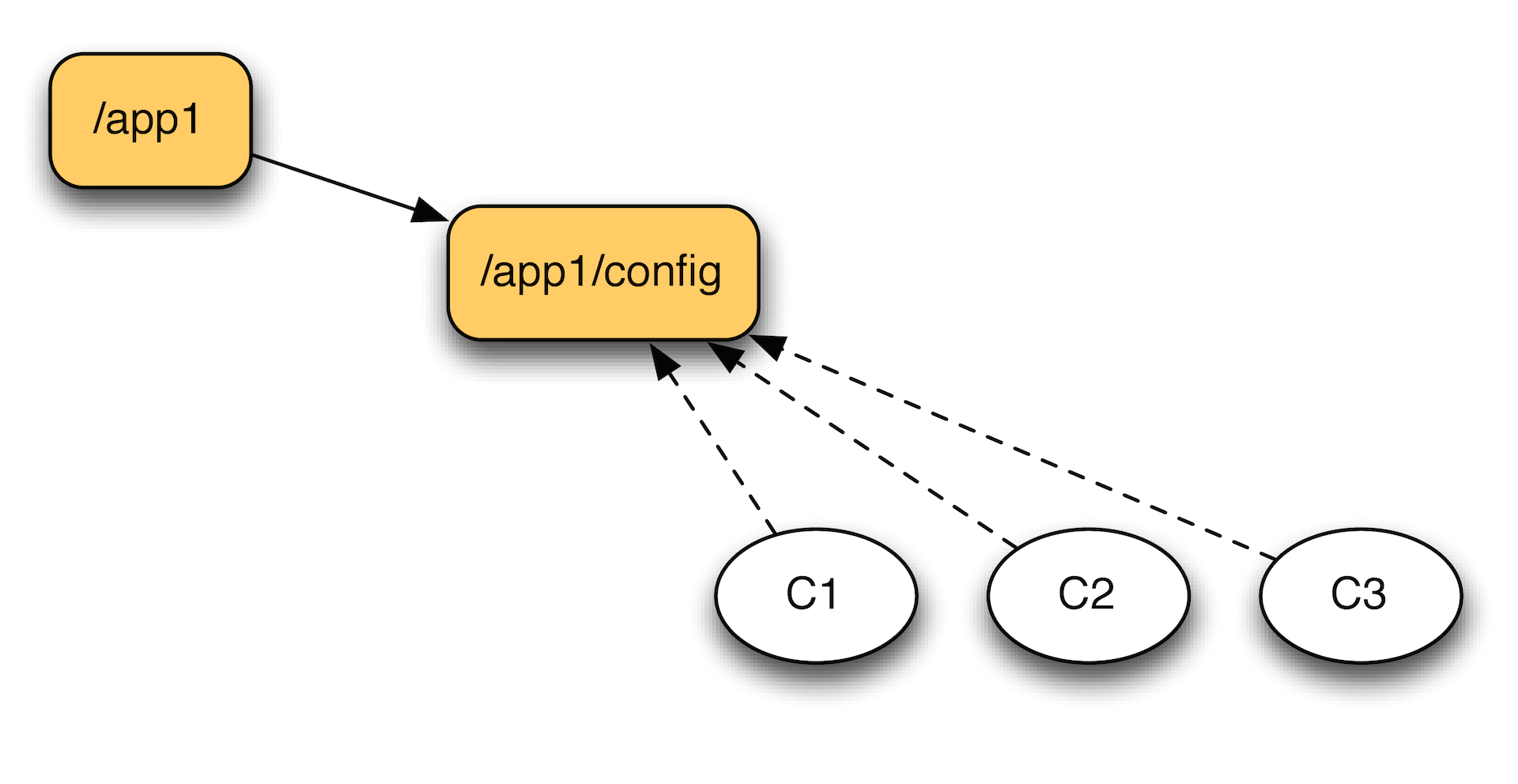
If they have recorded a change, they can read it and somehow react to it. Due to the so-called. ephemeral nodes can be tracked, for example, whether the machine is still alive. Or get a list of active machines. If we have a set of workers, then we can register each of them. And in the zukiper we will see all the machines that are really in touch. Due to the presence of the timestamp of the last modification or the list of sessions, we can even predict how far behind our machines are. If we see that the car starts to approach the timeout, you can take some action.
Rendezvous
Another option - the so-called rendezvous. The idea is that there is a way for the workers and the dealer who gives them tasks.
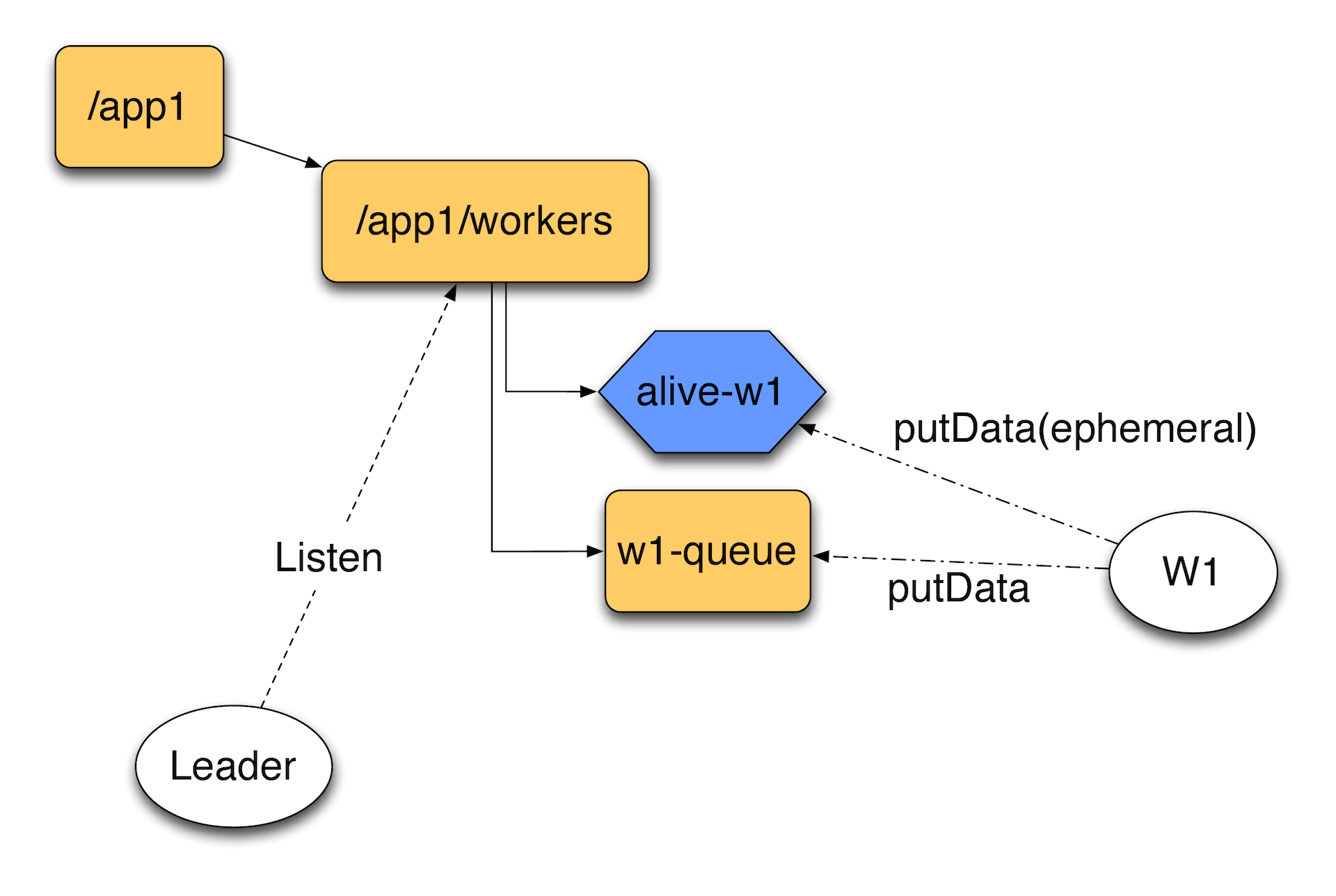
We do not know in advance how many workers we have, they can connect and disconnect, we do not control this process. To do this, you can create a directory of workers. And when we have a new worker, he registers an ephemeral node, which will report that the worker is still alive, and, for example, his own catalog, where tasks for him will fall. The leader will track the workers directory. He will notice if one of the workers falls off at some point. Having discovered this, he can, for example, transfer tasks from the queue to another worker. Thus, we can build on ZooKeeper an easy task processing system.
Locks
Suppose a client has come. He creates an ephemeral node. Here you need to make a reservation that in addition to the usual ZooKeeper there are sequential nodes. To them at the end can be attributed to some atomically growing sequence.
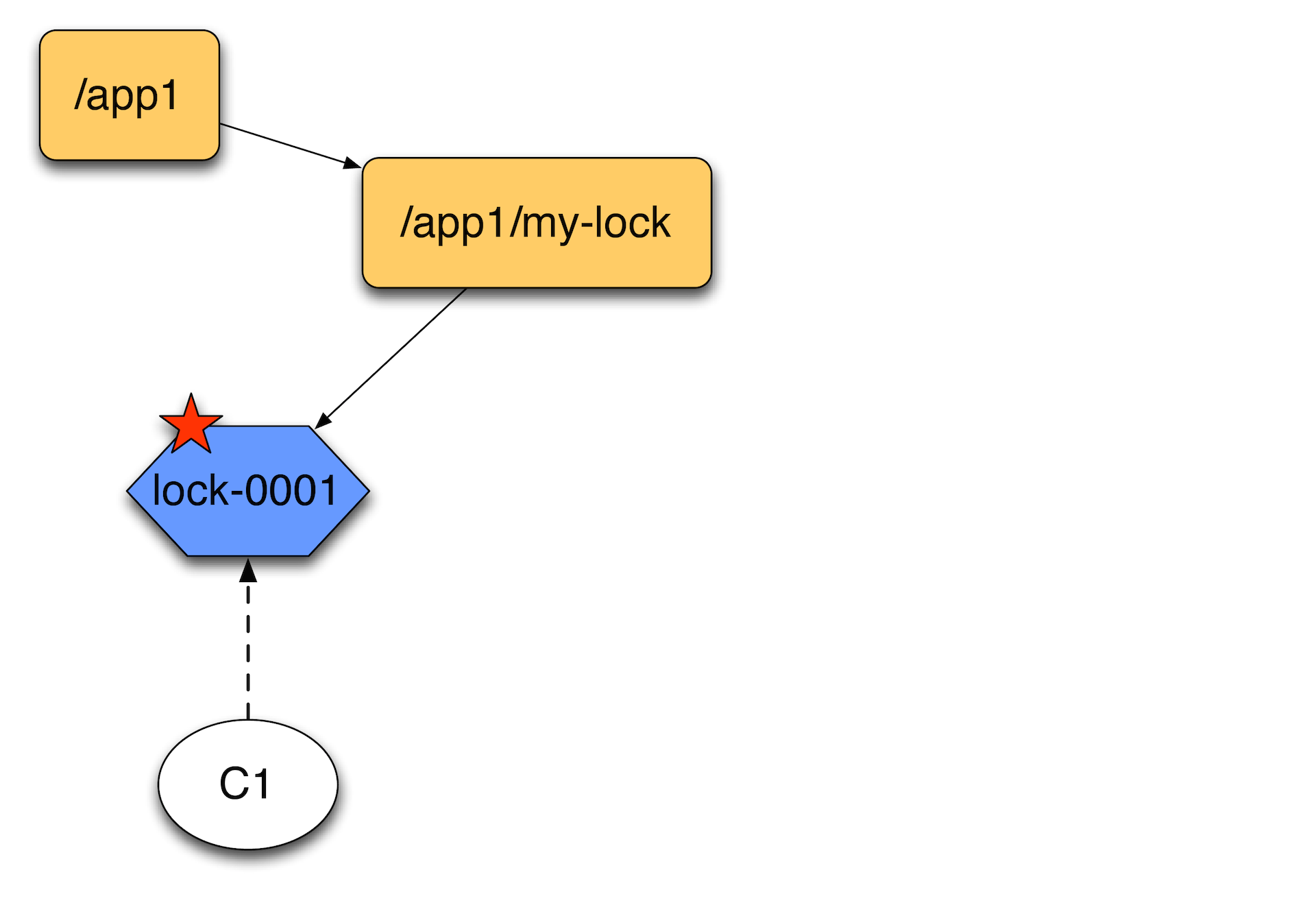
The second client, coming to create another ephemeral node, receives a list of children and sorting them out, looking to see whether he is the first. He sees that he is not the first, hangs up the event handler at first and waits for him to disappear.
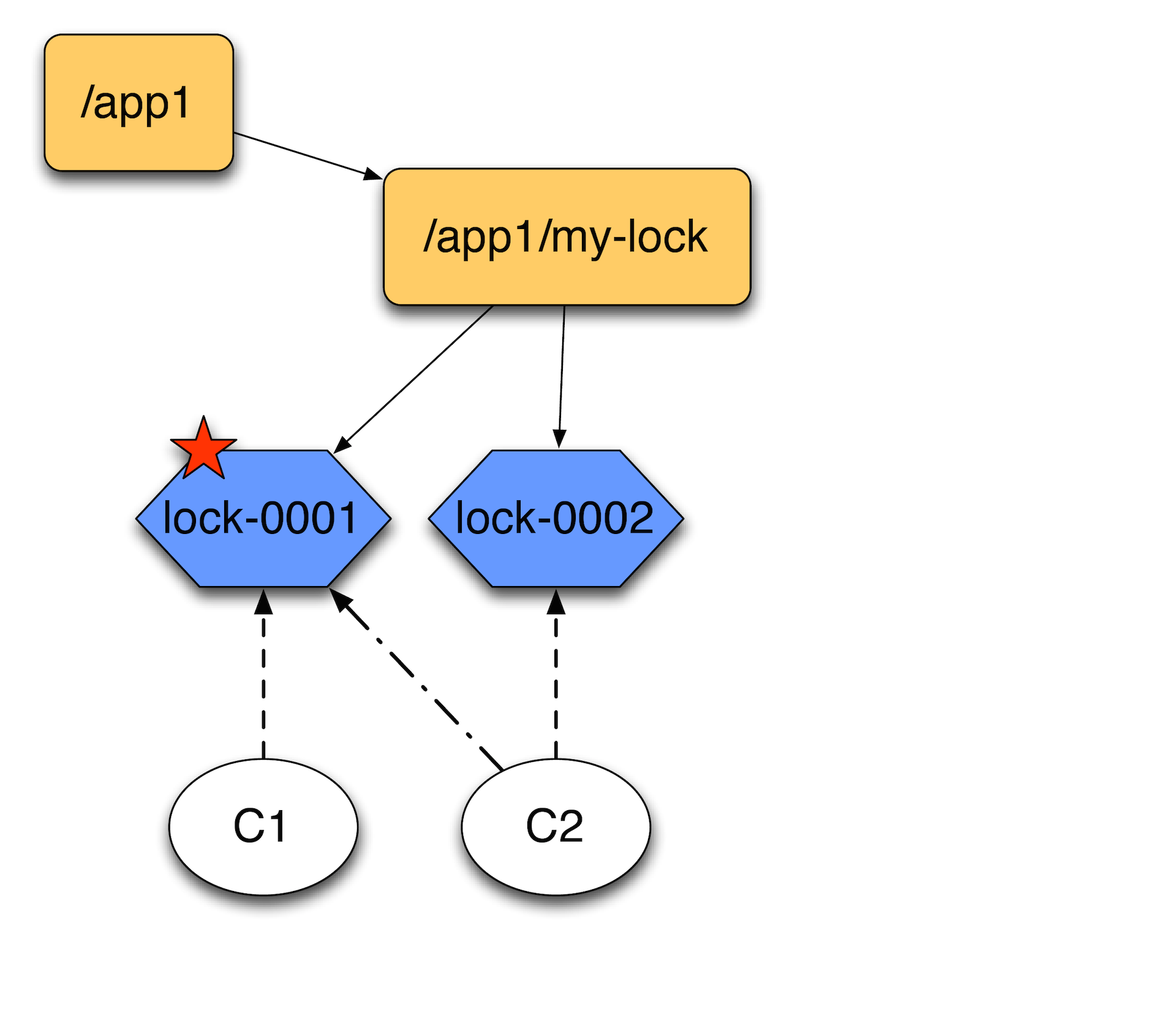
Why it is not necessary to hang up on the my-lock directory and wait when everything disappears there? Because if you have a lot of cars trying to block something, then when lock – 0001 disappears, you will have a storm of notifications. The wizard will simply be busy sending notifications about one particular lock. Therefore, it is better to link them in this way - one after another, so that they follow only the previous node. They line up in a chain.
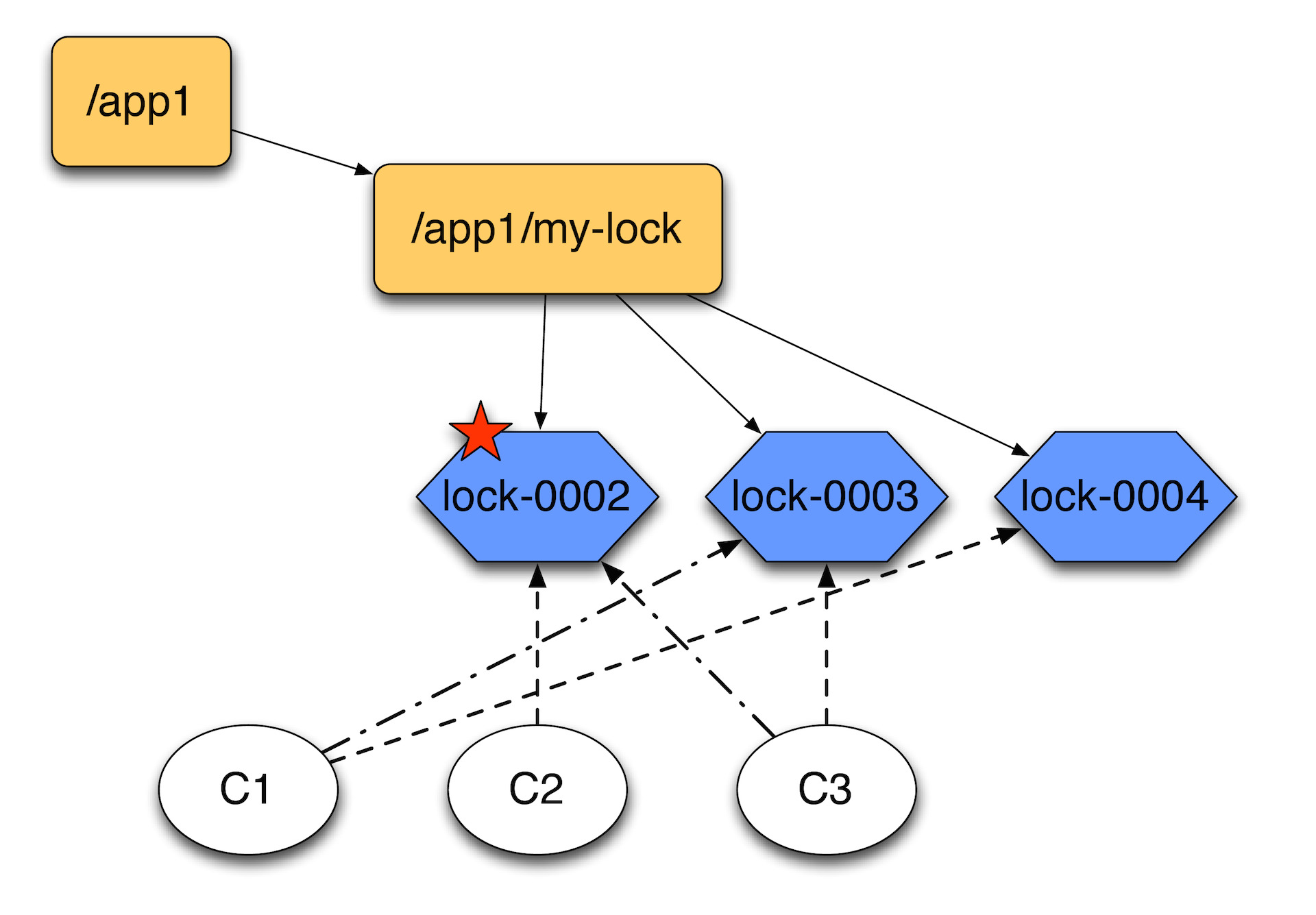
When the first client releases the lock, deletes this entry, the second client sees it and believes that he now owns the lock, because there is nobody ahead. At the expense of the sequence, no one in front of him guaranteed to climb. Accordingly, if the first client comes again, he will create a node at the end of the chain.
Performance
The graph below shows the write to read ratio along the x axis. It is noticeable that with the increase in the number of write operations in percentage terms, the performance sags heavily.
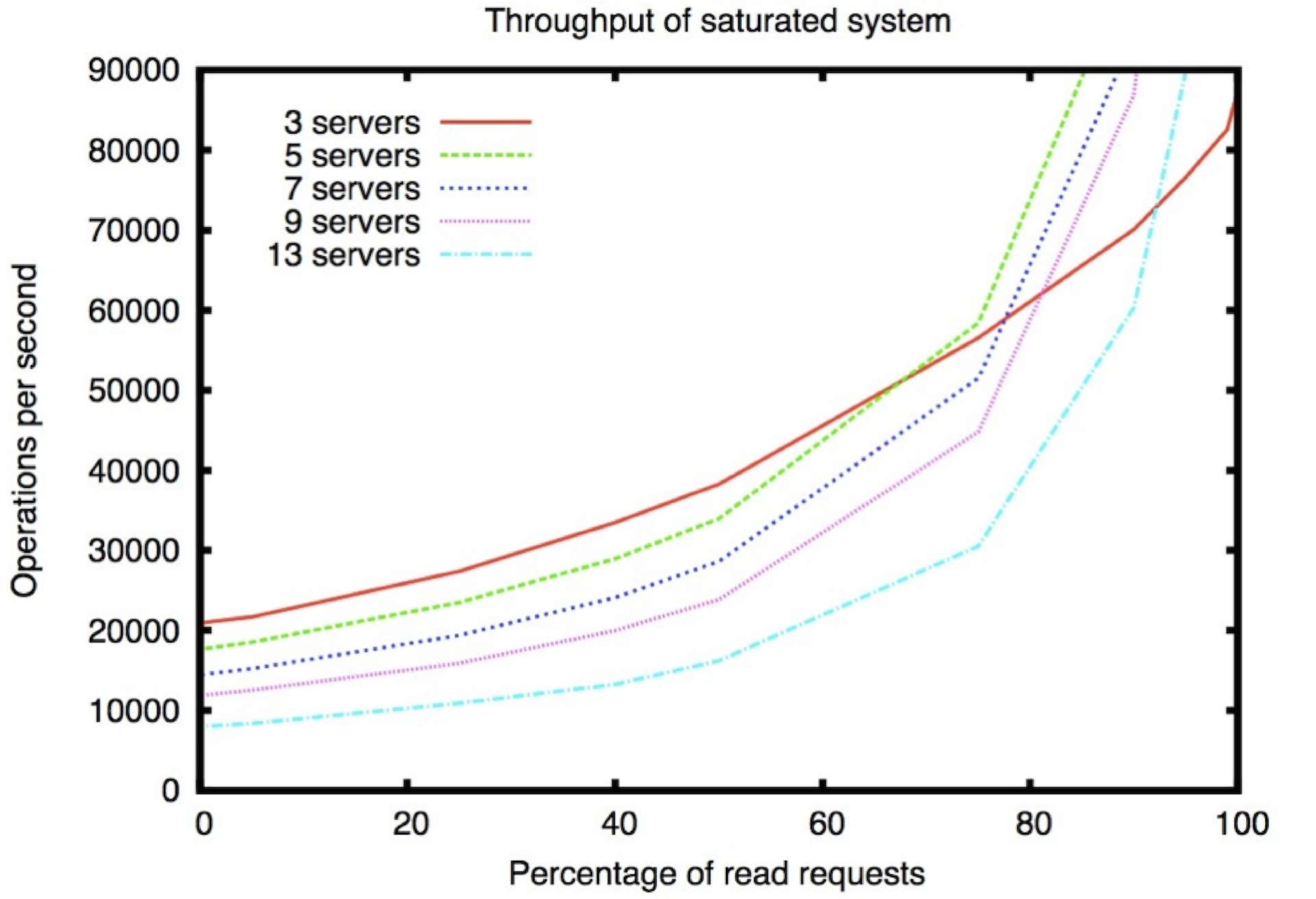
These are the results of work in asynchronous mode. Those. operations are sent by 100. If they were sent one by one, the numbers along the y axis should be divided by 100. You can grow better by reading. In ZooKeeper, in addition to the ability to build a quorum of, say, five machines that will guarantee data preservation, you can also make non-voting machines that act as repeaters: they simply read the events, but do not participate in the recording themselves. Due to this, it turns out the advantage in writing.
| Servers | 100% reads | 0% reads |
| 13 | 460k | 8k |
| 9 | 296k | 12k |
| 7 | 257k | 14k |
| five | 165k | 18k |
| 3 | 87k | 21k |
The table above shows how adding servers affects reading and writing. It can be seen that the reading speed grows with the number, and if we increase the recording quorum, the performance drops.
In the picture below you can see how ZooKeeper reacts to various failures. The first case - the loss of a replica. The second is the loss of a replica to which we are not attached.
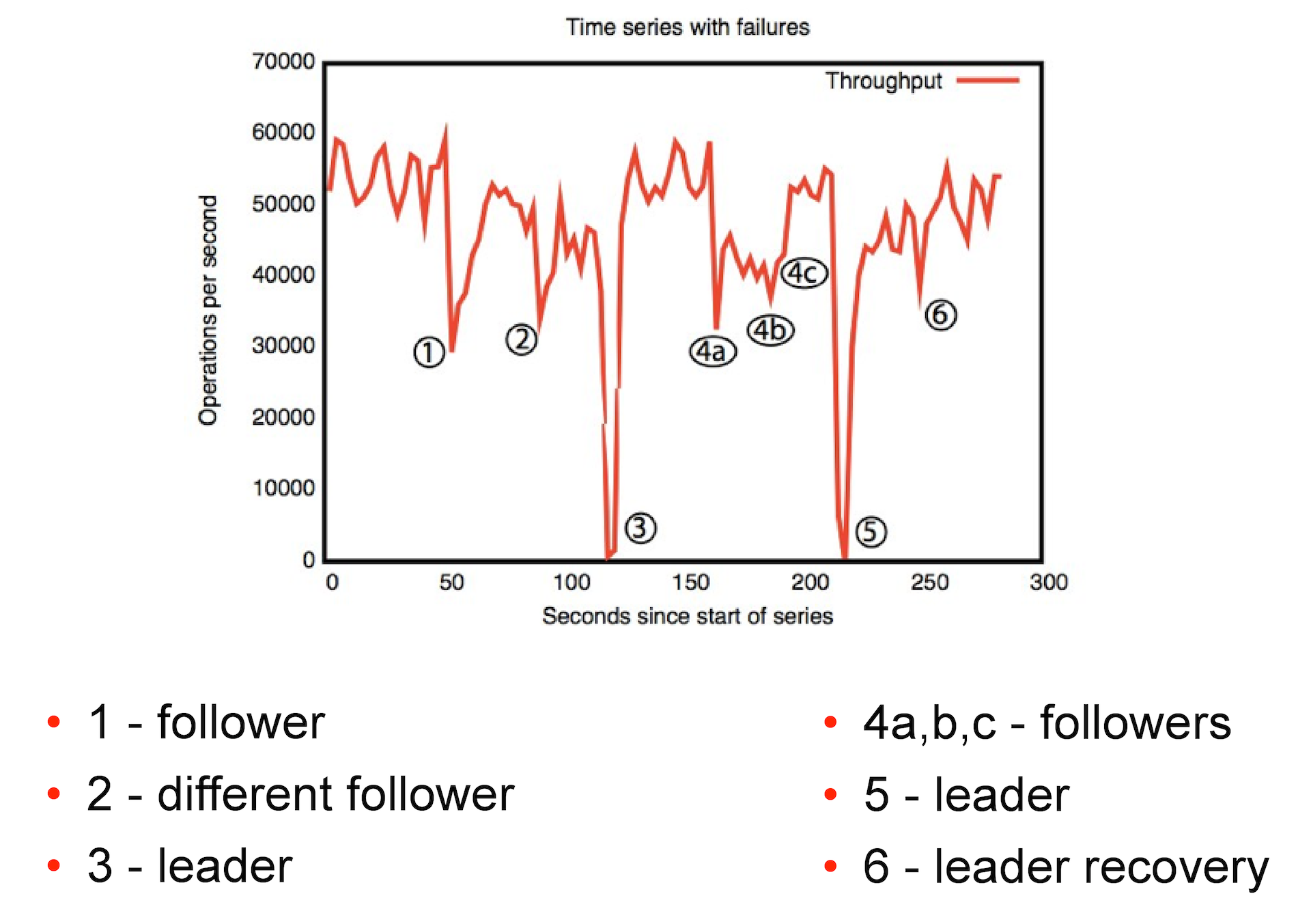
The fall of the leader for the zukiper conditionally critical. With a good network, ZooKeeper can restore it in about 200 ms. Sometimes a leader can be selected and a few minutes. And at this moment if we try to lock lock, any attempts to write without an active leader will not lead to anything, we will have to wait for it to appear.
Delays
| severs / workers | 3 | five | 7 | 9 |
| one | 776 | 748 | 758 | 711 |
| ten | 1831 | 1831 | 1572 | 1540 |
| 20 | 2470 | 2336 | 1934 | 1890 |
The time in the table above is in nanoseconds. Accordingly, the speed of reading ZooKeeper close to in-memory-databases. In fact, this is a cache that always reads from memory. In general, ZooKeeper database is always in memory. The recording goes something like this: ZooKeeper writes a log of events, it is reset to disk according to the tick settings, and periodically the system makes a snapshot of the entire database. Accordingly, if the base is too large or the disks are too busy, the delays can be compared with the timeout. This test simulates the creation of a certain configuration: we have 1 kilobyte of data, first there is one synchronous create, then an asynchronous delete, it all repeats 50,000 times.
References:
ZAB protocol - original document
ZAB analysis and its implementation in ZK, slightly more human language than the original
Source: https://habr.com/ru/post/234335/
All Articles