Stay Journey. Part 1

In the previous materials we looked at the placement of the program in memory - one of the central concepts relating to the execution of programs on computers. Now we turn to the call stack — the workhorse of most programming languages and virtual machines. We are expected to get familiar with amazing things like closure functions, buffer overflows and recursion. However, everything has its time - at the beginning you need to get a basic idea of how the stack works.
The stack is so important, because thanks to it any function “knows” where to return control after completion; the function, in turn, is the basic building block of the program. In general, the programs are internally rather simple. A program consists of functions; functions can call other functions; in the course of their work, any function pushes data onto the stack and removes them from there. If you want the data to continue to exist after the function is completed, then the space for them is allocated not in the stack, but in the heap. The above applies equally to programs written in relatively low-level C, as well as to interpreted languages like JavaScript and C #. Knowledge of these things is sure to come in handy - and if you have to debug the program, and if you happen to be fine tuning the performance, and just to understand what is there, it is still going on inside the program.
So, let's begin. As soon as we call a function, a stack frame is created for it in the stack . A stack frame contains local variables as well as arguments that were passed by the calling function. In addition, the frame contains service information that is used by the called function to return control to the calling function at the right time. The exact contents of the stack and its layout in memory may vary depending on the processor architecture and the calling convention used. In this article, we consider the stack on the x86 architecture with the convention of the call, adopted in the C language ( cdecl ). The figure above shows a stack frame located at the top of the stack.
')
Three processor registers are immediately apparent. The stack pointer , esp , is intended to point to the top of the stack. Close to the top there is always an object that was added to the stack, but not yet removed from there . Similarly, in real life things are with a stack of plates or a stack of $ 100 bills.
The address stored in the esp register changes as objects are added and removed from the stack, but it always points to the last object added and not yet removed from the stack. Many processor instructions change the value of the esp register as a side effect of its execution. Implementing work with a stack without esp would be problematic.
In the case of Intel processors, exactly as with many other architectures, the stack grows in the direction of smaller memory addresses . Therefore, the tip, in this case, corresponds to the smallest address in the stack, which stores the valid data used: in our case it is the local_buffer variable. I think it should be clear what the arrow from esp to local_buffer means . Here everything is, as they say, in the case - the arrow points exactly to the first byte occupied by local_buffer , and this corresponds to the address that is stored in the esp register.
Next on the queue is another register used to track the positions in the stack - the ebp register - the base pointer or the base pointer of the stack frame . This register is intended to indicate the position in the stack frame. Thanks to the ebp register, the current function always has a sort of reference point for accessing arguments and local variables. The address stored in the register changes when the function starts or stops execution. We can quite simply address any object in the stack frame as an offset from ebp , as shown in the figure.
Unlike esp , manipulations with the ebp register are carried out mainly by the program itself, and not by the processor. Sometimes you can achieve performance gains by simply abandoning the standard use of the ebp register — some compiler flags are responsible for this. The Linux kernel is an example of where this technique is used.
Finally, the eax register is traditionally used to store the data returned by the calling function — this statement holds true for most types supported in C.
Now let's break down the data contained in the stack frame. The figure shows the exact byte content of the frame, with the direction of the growth of addresses from left to right - this is what we usually see in the debugger. And here is the drawing itself:

The local variable local_buffer is an array of bytes representing a null-terminated ASCII string; such strings are the unchanged attribute of all C programs. The string size is 7 bytes, and, most likely, it was obtained as a result of keyboard input or reading from a file. In our array can be stored 8 bytes and, therefore, one byte remains unused. The value of this byte is unknown . The fact is that data is added and removed from the stack, and in this “endless dance of adding and removing operations” you can never know in advance what the memory contains until you write to it . The C compiler does not burden itself with initializing the stack frame with zeros. Therefore, the data contained there are not known in advance and are to some extent random. How much blood drank this compiler behavior from programmers!
We go further. local1 is a 4-byte integer, and the figure shows the contents of each byte. It seems that this is a big number - just look at all these zeros after the eight, but here our intuition has served us a disservice.
Intel processors use direct byte order (literally "spiky"), and this means that the numbers are stored in memory starting from the low byte . In other words, the least significant byte is stored in the memory cell with the lowest address. In figures and diagrams, bytes of multibyte numbers are traditionally depicted in order from left to right. In the case of direct byte order, the least significant byte will be displayed in the leftmost position, which differs from the usual way of representing and writing numbers.
It is nice to know that all this “pointed / blunt” terminology goes back to Jonathan Swift's “Gulliver's Travels”. Just as the people of Liliput cleaned the egg from the sharp end, Intel processors also handle numbers starting from the low byte.
Thus, the variable local1 actually stores the number 8 (yes, just like the number of octopus tentacles). As for param1 , there is a two in the second octet from the beginning, so the result is the number 2 * 256 = 512 (we multiply by 256, because each octet is in the range from 0 to 255). param2 stores the number 1 * 256 * 256 = 65536.
The service information of the stack frame includes two components: the address of the stack frame of the calling function (in the figure — saved ebp) and the instruction address to which control must be transferred upon completion of this function (in the picture — return address). This information makes it possible to return control, and therefore, the further execution of the program as if there was no call.
Now let's look at the process of "birth" stack frame. The stack does not grow in the direction that people normally expect to see , and at first it can be confusing. For example, to increase the stack by 8 bytes, the programmer subtracts 8 from the value stored in the esp register. Subtraction is a strange way to increase something. Funny, isn't it!
Take for example a simple C program:
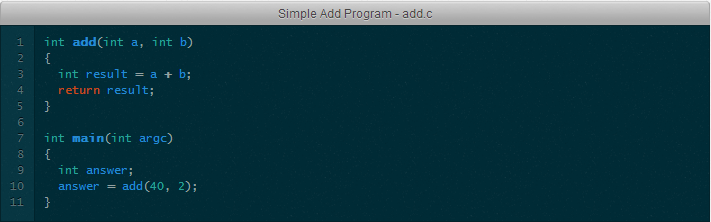
Suppose the program is run without parameters on the command line. When executing a “shared” program in Linux, the first thing control gets is the code contained in the standard C library. This code will call the main () function of our program, and, in this case, the variable argc will be equal to 0 ( in fact, the variable will be equal to “1”, which corresponds to the parameter - the name under which the program is launched, but for simplicity, let's omit this moment now ). When the main () function is called, the following happens:
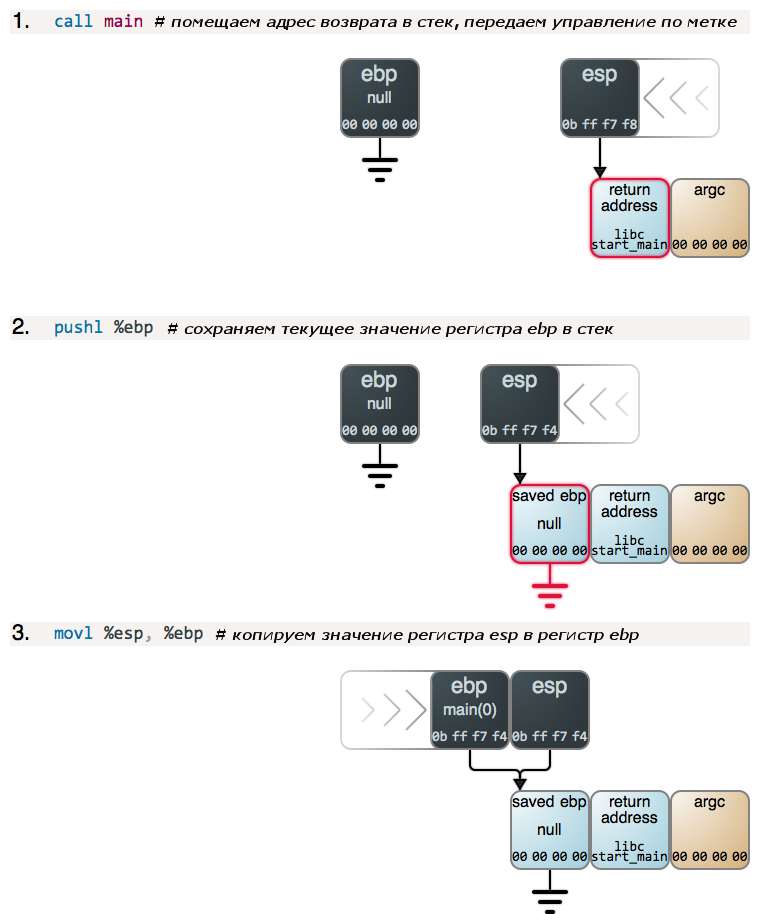
Step 2 and 3, as well as 4 (described below) correspond to a sequence of instructions, which is called a “prologue” and occurs in almost any function: the current value of the ebp register is placed on the stack, then the value of the esp register is copied to the ebp register, which actually creates new stack frame. The prolog of the function main () is the same as the other functions, with the only difference that at the beginning of the program execution the ebp register contains zeros.
If you look at what is in the stack under argc , you will see some more data - a pointer to the name string under which the program was launched, pointers to parameter strings sent via the command line (the traditional C array of argv ), and also pointers to environment variables and directly these variables themselves. However, at this stage it is not particularly important for us, so we continue to move towards calling the add () function:
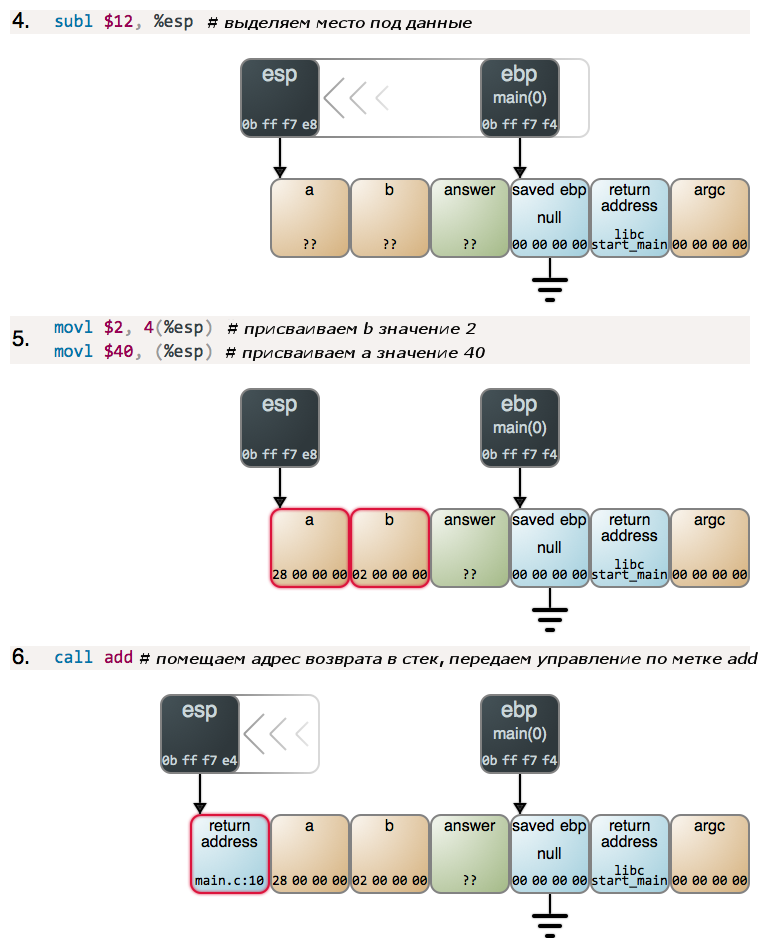
The main () function first subtracts 12 from the current value in the esp register to allocate the desired place and then assigns values to the variables a and b . The values stored in memory are shown in the figure in hexadecimal form and with direct byte order - as in any debugger. After assigning the values, the main () function calls the add () function, and it starts executing:

The further, the more interesting! We have another prologue, but now we can clearly see how the sequence of stack frames in the stack turns out to be organized in a linked list, and the ebp register stores a link to the first element of this list. Here, based on this, stack tracing in debuggers and Exception objects of high-level languages are implemented. Let's pay attention to the situation, typical for the beginning of the function execution, when the ebp and esp registers point to the same place. And once again, we’ll recall that in order to build the stack, we subtract from the value stored in the esp register.
It is important to note the following: when copying data from the ebp register to memory, a seemingly incomprehensible change in the byte storage order occurs. The fact is that for registers there is no such thing as “byte order”. In other words, considering the register, we cannot say that there are “senior or junior addresses” in it. Therefore, debuggers show the values stored in registers in the most convenient form for human perception: from more significant to less significant numbers. Thus, having the standard notation "left-to-right" and "little-endian" machine, it gives the deceptive impression that as a result of the operation of copying from the register into the memory, the bytes changed the order to the opposite. I wanted the picture shown in the drawings to be as close to reality as possible - hence such drawings.
Now that the hardest part is behind us, we add:
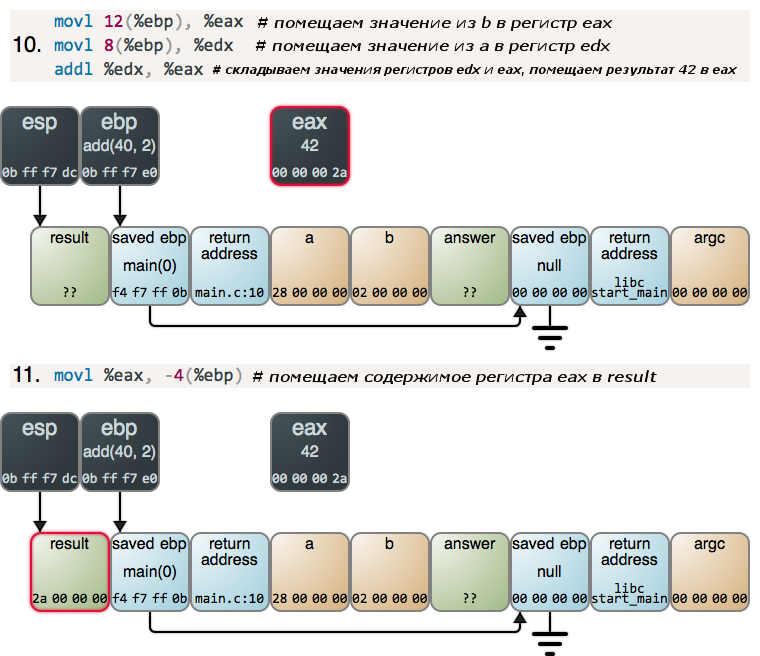
Here we have an unknown register to help with the addition, but in general, nothing special or surprising. The add () function does the howling work and, from this moment on, all actions in the stack will be performed in the reverse order. But we will tell about this some other time.
Anyone who has finished reading these lines deserves a gift for endurance, so I am presenting with great geeky pride to you this unified scheme with all the steps described above.
It’s not all that difficult, you just have to sort it out. By the way, small squares help me a lot . Without "small squares" in computer science in general anywhere. I hope my drawings allowed me to make a clear picture of what is happening, on which both the growth of the stack and the changes in the memory contents are intuitively simply shown. On closer inspection, our software is not so different from a simple Turing machine.
This concludes the first part of our journey through the stack. In future articles, we are waiting for new immersions in the "byte" wilds, after which we will look at what high-level programming languages can build on this foundation. See you next week.
Material prepared by employees of the company Smart-Soft
smart-soft.ru
Source: https://habr.com/ru/post/234239/
All Articles