Increase disk subsystem performance in the next release of the XenServer hypervisor

Transfer. The original article is available on the Xen blog .
The author is Felipe Franciosi .
The latest test builds of XenServer Creedence Alpha are notable for their increased disk subsystem performance compared to XenServer 6.2 (see the details in Marcus Granado's blog - Performance Improvements in Creedence ). In general, the improvements are related to the introduction of a new disk subsystem architecture - tapdisk3. We will describe this technology of organizing virtual storage, as well as present and explain the results of experiments in which the performance of approximately 10Gb / s is achieved by a single host with connected cluster storage.
A few months ago, I wrote about the project Karcygwins, which included a series of experiments and studies aimed at studying the features of disk I / O. We focused on the case where a load is generated by one VM with one virtual disk. In particular, we were interested in understanding the nature of additional costs (overhead) for virtualization, especially on devices with low latencies, for example, modern SSDs. By comparing the different ways of virtualizing disk I / O available to the user (that is, blktap and blktap2), we were able to explain where and why additional costs arise, as well as how to significantly reduce them. More information about the project Karcygwins can be found at the link.
From this point on, we expanded the range of studies for cases with a more complex load structure. We were especially interested in the joint load from several VMs, which completely loaded the storage. We studied the features of the tapdisk3 subsystem developed for XenServer by Thanos Makatos. Tapdisk3 is written to simplify the architecture and bring it fully into user space, and this, in turn, leads to a significant increase in performance.
')
There are two major differences between tapdisk2 and tapdisk3. The first is the way tapdisk connects to the disk I / O subsystem: the old tapdisk accesses the blkback and blktap2 devices inside the hypervisor, and the new one directly to the paravirtual driver inside the VM. The second is the method by which the guest VM and the hypervisor exchange data: the old tapdisk uses access to the displayed memory pages in the VM memory and then copies them to the address space of the hypervisor, while the second uses a copy-on-access technology (grant copy).
All other modifications are necessary in order to make such a change in architecture possible. Most of them affect the level of control of virtual machines (control plane). To do this, we changed the control stack (xapi) so that it maintains constant communication with the tapdisk module. Because of these changes (and also because of some others related to how tapdisk3 is processing incoming data), the way the virtual disk is represented in the hypervisor's memory has changed. Since tapdisk3 has not yet been officially released, other changes are possible in the future.
To measure the performance achieved within tapdisk3, we chose the fastest server and fastest storage available to us.
- Dell PowerEdge R720 Platform
- 64 GB RAM
- Intel Xeon E5-2643 v2 @ 3.5 GHz processor
- 2 sockets, 6 cores per socket, hyperthreading = 24 pCPU
- Turbo Frequency - 3.8 GHz
- The hypervisor CPU scheduler is switched to “Performance” mode (by default, it is set to “On Demand” to save power). Rachel Berry (Rachel Berry) in her blog described the work scheduler in more detail.
- The BIOS is set to Performance per Watt (OS), the Maximum C-State mode is set to 1
- 4 x Micron P320 PCIe SSD (175 GB each)
- 2 x Intel 910 PCIe SSD (400 GB each)
- Each of them is represented as 2 SCSI devices of 200 GB each (total - 4 devices and 800 GB in total)
- 1 x Fusion-io ioDrive2 (785 GB)
After installing XenServer Creedence with build number 86278 (about 5 numbers older than XenServer Creedence Alpha 2 ) and Fusion-io drives, we created a storage on each available device. It turned out 9 storage and approximately 2.3 TB of free space. On each storage we created 10 virtual disks in RAW format of 10 GB each. We connected each virtual disk with its virtual machine, choosing disks “in a circle,” as shown in the diagram below. Ubuntu 14.04 (x86_64 architecture, 2 logical CPUs not rigidly tied to real, 1024 MB of RAM) was chosen as the guest OS. We also passed 24 logical CPUs to the hypervisor and decided not to associate them with real ones (in the XenServer 6.2.0 CTX139714 article, the methodology for linking logical CPUs to real ones is described in more detail).

First, we measured the aggregate channel performance between the hypervisor and the virtual machine, if the disks are connected in the standard way tapdisk2 <-> blktap2 <-> blkback. To do this, we forced one virtual machine to send 10-second write requests to all of its disks at the same time, and then calculated the total amount of data transferred. Request size ranged from 512 bytes to 4 MB. After that, we increased the number of virtual machines to 10, and then changed the write requests with read requests. The result is shown in the graphs below:


Measurements have shown that virtual machines are not able to access the disk at a speed of more than 4 Gb / s. Then we repeated the experiment using tapdisk3. The result has clearly improved:


In the case of writing, the aggregate throughput of the disk subsystem for all VMs reaches 8 Gb / s, in the case of reading - 10 Gb / s. From the graph it follows that in some cases the performance of tapdsik3 is greater than the performance of tapdisk2 approximately 2 times per write and 2.5 times per read.
To understand why tapdisk3 is so superior to tapdisk2 in performance, you should first consider the virtual storage subsystem architecture, which is used by para-virtual VMs and hypervisor. We will focus on the components that XenServer and a regular VM running Linux use. However, it should be borne in mind that the information outlined below is also relevant for VMs running Windows, if this OS uses the installed para-virtual drivers.
As a rule, a guest VM running Linux loads a driver called blkfront when it starts. From the point of view of the guest VM, this is a regular block device. The difference is that instead of interacting with real hardware, blkfront communicates with the blkback driver in the body of the hypervisor via shared memory and the event channel, which is used to transfer interrupts between domains.
Applications inside the guest OS initiate read or write operations (via libc, libaio, etc.) of files or directly block devices. Operations are ultimately translated into requests for block devices and are transmitted by blkfront through randomly selected memory pages in the guest's address space. Blkfront, in turn, provides the hypervisor with access to these pages in such a way that blkback can read and write to them. This type of access is called “granting access to the displayed memory pages” (grant mapping).
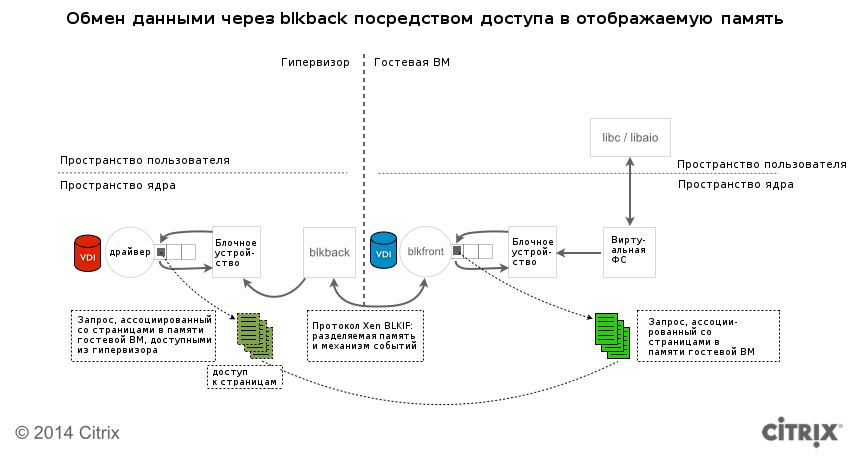
Despite the fact that the Xen Project developer community is campaigning to improve the scalability and performance of the mechanism for accessing the displayed pages, there is still a lot of work because the system is complex and has several limitations, especially regarding sharing access to storage from several VMs. The most notable recent change is a patch set by Matt Wilson to improve the locking mechanism and better performance.
To reduce the additional cost of allocating and freeing memory for each request in the access mechanism for the displayed pages, Roger Pau Monne implemented the blkback / blkfront protocol with an innovation called “persistent grant”. Such access can be used if both domains (hypervisor and VM) support it. In this case, blkfront provides blkback with access to a permanent page set, and both drivers use this set as long as they can.
The downside is that blkfront cannot indicate which pages will be associated with the request received from the block level device of the guest VM. In any case, it has to copy the data from the request to this set before sending the request to blkback. However, even if we take into account this copying operation, access to permanent addresses remains a good method for increasing scalability while simultaneously I / O from several VMs.

Both of the above changes are fully implemented in the hypervisor kernel space. However, we do not take into account that the request to the block level of the hypervisor contains a link to pages in the guest address space. This can cause a race condition when using network storage, such as NFS, and possibly iSCSI: if the network packet (which contains a pointer to the exchange page) is queued for retransmission and the transfer of the original packet is received, the hypervisor can resubmit incorrect data or even crash, because the exchange page may either contain incorrect data or be released altogether.
To avoid problems, XenServer copies pages to the hypervisor instead of using them directly. This feature first appeared in the blktap2 driver and the tapdisk2 component, along with technologies for allocating space on demand (thin-provisioning) and moving VM disks between storage systems (Storage Motion). Within this architecture, blktap2 copies pages before transferring them to tapdisk2 to ensure the secure operation of network storage. For the same reason, blktap2 provides the hypervisor with a full-featured block device for each virtual disk, regardless of its nature (including thin-provisioned thin-provisioning disks hosted on NFS storage).

As we see from the results of the above measurements, this technology has limitations. It is good for various types of classic storage, but demonstrates poor performance when working with modern storage media, such as SSD disks connected directly to the server via a PCIe bus. To take into account recent changes in data storage technology, XenServer Creedence will contain a new component - tapdisk3, which uses another method of memory access - grant copy.
Starting with the 3.x kernel version as the hypervisor domain (dom0) and the advent of the access device (gntdev), we have accessed the pages of other domains directly from the hypervisor's user space. This technology is implemented in tapdisk3 and uses the gntdev device, as well as the evtchn event channel, to exchange data directly with the blkfront.
Copying on access is much faster than just granting access to permanent addresses, and then copying. With this access, most of the operations are performed inside the Xen Project Hypervisor core, in addition, the presence of data in the address space of the hypervisor domain is ensured for the secure operation of network storage. Also, since the logic is implemented entirely in user space, the inclusion of additional functionality (such as thin-provisioning, snapshots, or Storage Motion) does not create any particular difficulties. To provide the hypervisor access to the block device, the corresponding virtual machine disk (for copying the disk and other operations) we connect tapdisk3 to blktap2

Last (but not least), what we wanted to write about: a sophisticated reader may ask why XenServer does not use the capabilities of qemu-qdisk, which implements the technology of accessing permanent addresses in user space? The fact is that, to ensure the safe operation of network storage (including access to permanent addresses, in which the request to the storage refers to pages in the memory of the guest VM), qemu-qdisk clears the O_DIRECT flag when accessing virtual disks. This causes the data to be copied to the hypervisor domain cache, which ensures secure access to the data. Thus, access to permanent addresses in this case leads to redundant copying and delays in servicing requests. We believe that copying on access is a better alternative than qemu-qdisk.
Source: https://habr.com/ru/post/234201/
All Articles