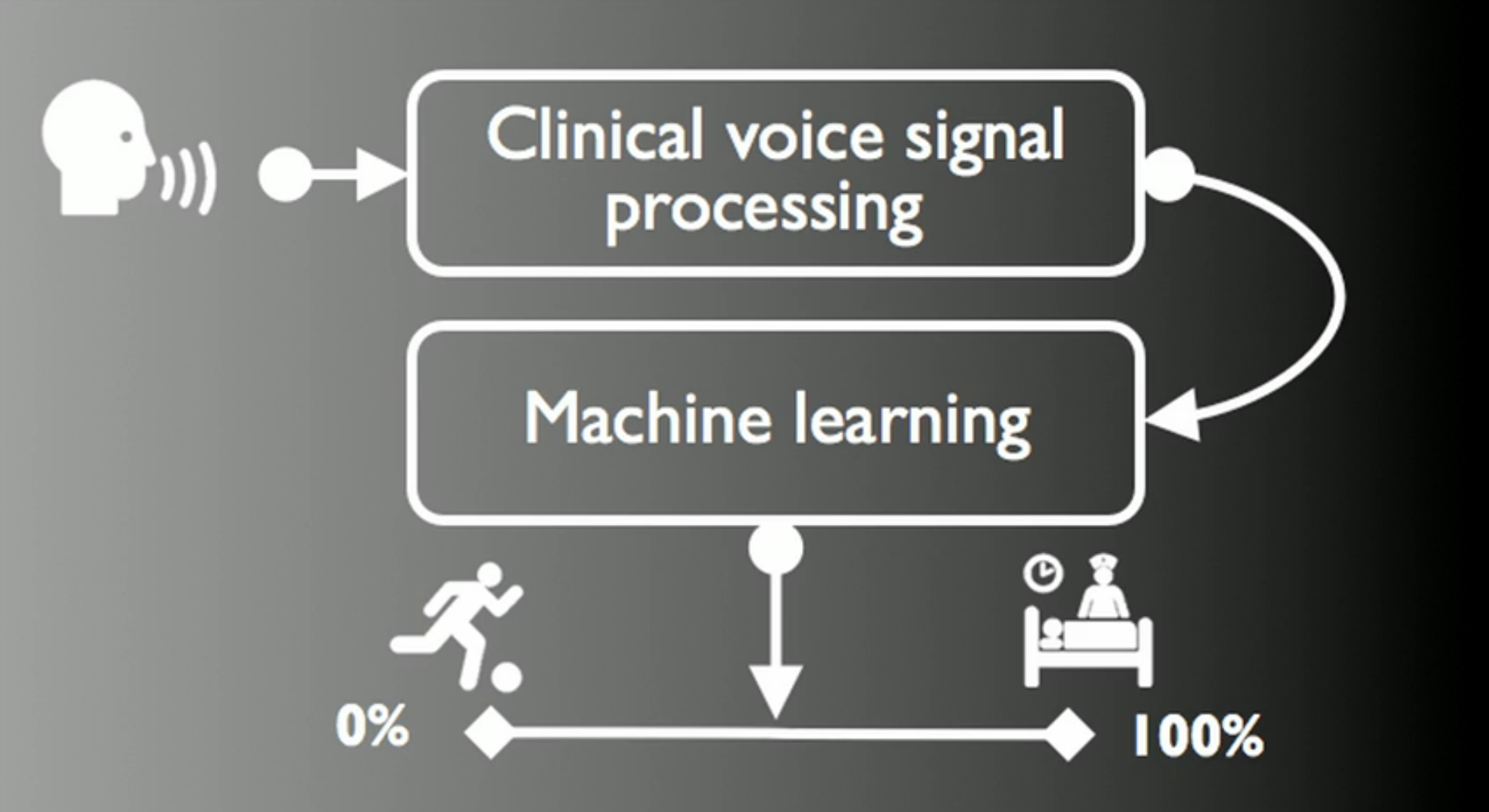
Clinical speech signal processing and machine learning. Part 1
From the speech of Max Little (founder of PVI) at the TED conference in 2012.
Hello, Habrahabr. This series of articles will be devoted to the consideration of the possibility and the construction of Open Source universal analyzer speech disorders.
This article will tell about the Parkinson Voice Initiative project, dedicated to the early diagnosis of Parkinson's disease by voice (recognition success is 98.6 ± 2.1% in 30 seconds over a telephone conversation).
A comparison will be made of the accuracy of the feature selection algorithms used in it (VO) - Feature Selection Algorithm - LASSO, mRMR, RELIEF, LLBFS.
')
The battle between Random Forest (RF) and Supported Vector Machine (SVM) for the title of the best analyzer in this kind of applications.
Start
Reading articles on speech synthesis and recognition, I found mention of the fact that during a disease the voice changes. Having checked the obviousness of the fact that I was not the first to guess how to use speech recognition to diagnose diseases (the first clinicians identified some features - features as early as the 40s of the last century, recording on tape, and then manually analyzing), followed Google's links. One of the first pointed to the project PVI .

After watching the founder’s speech at the 2012 TED conference (Russian subtitles are available from Irina Zhandarova ), I found the necessary arguments in favor of such a project for myself, for doctors and patients, and, I hope, for programmers.
Until 2012, there was no Parkinson's disease biomarker, but rather it exists to determine developmental dynamics rather than primary diagnosis. In addition, the question of their availability, price, time for obtaining the result and labor intensity remains open.

An excerpt from the TED 2012 presentation (subtitles in Russian by Irina Zhandarova).
Arguments
| Special features | Neurologist | Voice check |
|---|---|---|
| Non invasive | + | + |
| Use of existing infrastructure | + | + |
| Accuracy | + | + |
| Remoteness | + | |
| Ability to use non-professional | + | |
| High speed of getting results | + | |
| Very low cost | + | |
| Scalability | + |
It also allows you to frequently check for the presence of the disease.
Remarkably, I thought, you can easily make the same analyzers for other diseases, clicked on the Science tab and saw what this analyzer began to do in 2006. The development period has somewhat reduced the level of enthusiasm, but did not discourage desire.
Why this site does not give medical advice if they have such an accurate analyzer?
There are several possible reasons for this (they are suitable for any disease analyzer):
- Legal regulation. They will have to take responsibility in order to give medical advice;
- They are not sure that they have collected enough data;
- False positive and false negative definitions of the disease;
- The disease may not be of such severity that speech disorder begins to manifest itself (that is, it may develop later);
- Finally, some symptoms do not appear at all on the severity of a certain number of people (people recover or die earlier);
- Still existing similarities with some diseases (for example, for this project, this Essential Tremor is another kind of tremor than with Parkinson's Disease).
Apparently, the data are available to doctors and researchers who can properly evaluate them.
The growth rate of the unique recordings of people's voices can be seen below. The data for 2012 (8 years after the start of the program) based on Max Little @ MaxALittle on Twitter shows that the number of people taking the test depends more on media coverage and social networks, like everywhere else.
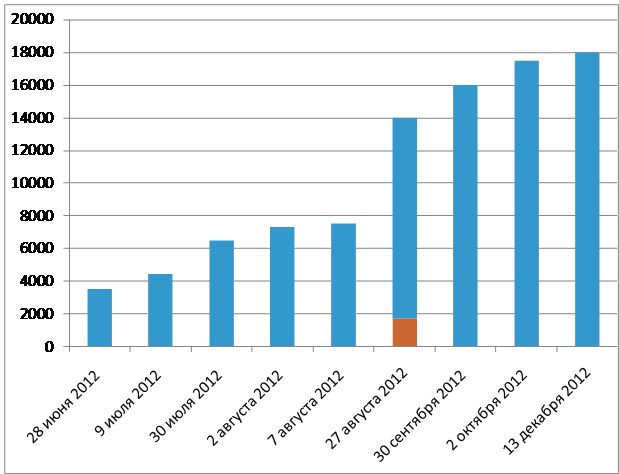
The upper border of the column is the total number of voice test passed on the PVI project. On August 27, data were published that 1700 of the 14,000 signatories (approximately 12% are sick with Parkinson) are a red bar.
In memory of Aaron Schwarz, he laid out his publications for free access, so that everyone can familiarize themselves with them, see the technical details and develop his work.
To honor Aaron Swartz memory, www.maxlittle.net/publications #pdftribute
Max Little @ MaxALittle Jan 14 2013

The founder of the Parkinson Voice Initiative project, his Erdös number is 4.
In the last study of Max Little from 2012, posted on the website - "New algorithms for processing speech signals for high-precision classification of Parkinson's Disease", 4 features of feature selection (VO) were compared. The data on the basis of which the study was conducted included 132 features and 263 records, including phonation of the control group (61 entries from 10 people) and persons with Parkinson's disease (202 entries from 33 people).
Technical details
Using all the features investigated in this work, SVM, with 10-fold cross-validation - cross-checking (PP), repeated 100 times, showed an accuracy of 97.7 ± 2.8%, and using RF , with 10-fold cross-checking, repeated 100 times - the achieved accuracy was 90.2 ± 5.9%.
The best results, described in the literature before, reached 93.1 ± 2.9% accuracy in the classification of a sample of 22 features using the GP-EM algorithm (for genetic programming and maximization of expectations).
To improve the quality of predictions and reduce the complexity of processing speech signals in the study, it was decided to create a subset of 10 features. A comprehensive search through all possible subsets is quite expensive in computer time, so algorithms for VO were developed that offer fast, fundamental approaches to reducing the set of features.
The subsets of features in each case were selected using the PP approach, using only the training information on each iteration of the PP. They repeated the PP process as a whole 10 times, where each time the features (for each VO algorithm) appeared in the descending order of choice. Ideally, the same order should be obtained each time, but in practice this does not happen.
RELIEF
RELIEF , using a total of 10 features (out of 132) on data from 256 foundations, showed 98.6 ± 2.1% accuracy (true positive: 99.2 ± 1.8%; true negative: 95.1 ± 8.4%) with SVM and 93.5% accuracy with RF .
RELIEF is an algorithm based on determining the “weight” of a feature, which enhances the features that separate samples from different classes. This correlates with the maximization of the correcting ability of the algorithms, and was assigned to the k-Nearest-Neighbor classifier. Contrary to the mRMR algorithm (discussed below), RELIEF uses contingency as an integral part of the feature selection process.
LLBFS
The second place was taken by the LLBFS (Local Learning-Based Feature Feature Selection algorithm) selection of features based on local learning with an accuracy of 97.1 ± 3.7% (true positive: 99.7 ± 1.7%; true negative: 89.1 ± 13.9%).
LLBFS is aimed at dividing intractable combinatorial problems of HE into a set of local linear problems through local training. The initial features were assigned weights that reflect their importance for the classification problem, after which they were selected to have features with a maximum weight. LLBFS was conceived as an extension of RELIEF and is based on a nuclear estimate of the density of the distribution and the concepts of maximizing the correction feature.
Lasso
The Least Absolute Shrinkage and Selection Operator (LASSO) , a method for estimating the parameters of a linear model that has the ability to reduce dimensions, took 3rd place with an accuracy of 94.4 ± 4.4% (true positive: 97.5 ± 3.4%; true negative: 86.5 ± 14.3%).
LASSO penalizes the absolute number of coefficients established in a linear regression; this leads to the reduction of some of them to zero, which effectively shows the features associated with them. LASSO showed predictive abilities (correctly identified all the “correct” features contributing to the prediction of the response) in a sparse setting, when the features are not highly conjugated. At the same time, when the features correlate, “noisy” features (not contributing to the response) could still be selected and some useful features were thrown out to predict the result.
mRMR
Minimum Redundancy Maximum Relevance (mRMR) , (minimum redundancy - maximum relevance) ranked last among the investigated VO algorithms, with an accuracy of 94.1 ± 3.9 (true positive: 97.6 ± 3.3; true negative: 84.3 ± 13.2).
The mRMR algorithm uses a heuristic criterion to establish a balance between maximum relevance (the relationship between the strength of features and the response) and the minimum excess (relations between pairs of features). This is a greedy algorithm (based on the choice of one feature in a single pass), which focuses only on pairwise redundancy and ignores conjugacy (connections by logical connections of features to predict a response).
SVM vs. RF
In this study, the SVM took over RF . The author of the study tried to change the RF tuning parameter (the number of features among which a search should be made to build each branch of the tree), but this did not give noticeably different results for the overall RF accuracy.
Possible improvements proposed by the author of the study:
SVM and RF can be configured to output "I do not know," through the introduction of an additional class, if the possibility of attributing to other classes below a certain pre-specified trait, which will improve the accuracy of determination, and also give doctors a chance to look more closely at this case.
The next part will discuss the features on the basis of which you can get such wonderful results.
PS If you are interested in this topic and you are ready to help in the development - write, discuss.
Source: https://habr.com/ru/post/234073/
All Articles