JSOC: the experience of the young Russian MSSP
As part of the corporate blog, I would like to launch a series of articles about our young (but, nevertheless, very bright) initiative in the field of information security - the JSOC (Jet Security Operation Center) - a commercial center for monitoring and responding to incidents. In the articles I will try to do less self-promotion and pay more attention to practice: our experience and the principles of building a service. Nevertheless, this is my first "habro-experience", and therefore do not judge strictly.
I don’t really want to tell why a large Russian company is needed at all (there are too many different articles and studies on this subject written). But statistics is another matter, and it is a sin not to remember about it. For example:
If we add to this another 3-4 news headlines on the relevant topic, then the idea that security needs to be monitored and information security incidents to identify and analyze is absolutely logical and understandable.
What do security experts advise on this issue? Of course, make the SIEM solution the core of an existing or under construction SOC. This will solve several problems at once:
There are several levels of SOC-SOMM maturity (Security Operations Maturity Model):

Fig. 1 - SOMM Levels
Unfortunately, most companies, having taken the first step on the way to their own incident monitoring center, stop there. According to HP estimates, 24% SOC in the world do not reach level 1, and only 30% SOC correspond to the base (2) level. Statistics of the distribution of SOMM levels depending on the business area of companies, collected in 13 countries of the world (including Canada, USA, China, UK, Germany, South Africa, etc.) is as follows:
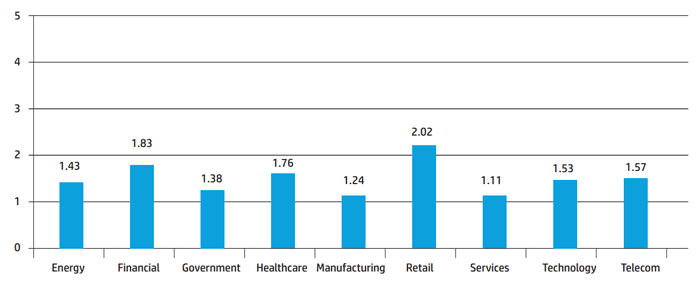
Fig. 2 - Distribution of SOMM levels by business area
')
At the same time, almost all large Russian companies passed through the implementation of large-scale SIEM solutions. Did they manage to build effective SOC `s? Unfortunately, most often not: today we know the experience of only four successful SOC launches in Russia.
And, as a rule, when starting to build your own SOC, everyone faces three facets of one problem.
First, with a quantitative shortage of personnel for a variety of reasons: from personnel shortage and the lack of specialized universities to the difficulty of acquiring the required competencies. De facto, within the framework of the it-security unit, today there are 4–5 people who carry out the entire cycle of work to ensure the security of a company (from administering protective equipment to regular risk analysis and developing a strategy for the development of the subject matter in the company). Naturally, with such a load, it is almost impossible to devote the proper time to SOC tasks.
The second point is related to the impossibility of building an effective monitoring process with internal SLAs. In addition to the need to allocate personnel, the launch of SOC usually entails the creation in the it-security unit of a full-time shift shift, working on an extended working day or around the clock. And this is from 2 to 5 new staff units. At the same time, the allocation of personnel is directly related to the need for continuous monitoring of personnel turnover (extremely rarely IB specialists are ready to work in the night shift), building processes and internal quality control of the work performed.
Well, the third point is not to mention the need not only to handle emerging incidents, but also to constantly “tune” and adjust the system to changing infrastructure or emerging security threats. And this, regardless of the chosen instrument, is a very time-consuming task for the analyst, requiring you to keep your finger on the pulse. And the presence of a person engaged in clean analytics and SOC development is a great luxury (even for a large company).
Estimating the need for creating SOC on the market together with the described nuances led us first to the idea and then to actually build our own commercial SOC.
Naturally, starting SOC, we first of all faced the question: “What kind of SIEM solution should be made the core of our system”? Responding to it, we have formed a list of requirements for the system being created. In particular, it should:
We stopped our choice on the flagship product in the SIEM - HP ArcSight class (and, despite various difficulties in the life of the system, we never regretted our choice). Technologically, JSOC is no longer just HP ArcSight. SIEM `s core gradually acquired various useful features: traffic monitoring, ips \ ids, vulnerability assessment, etc. At the same time, we have accumulated a large number of scripts, add-ons and our own developments, integrated with our own Security Intelligence solution (JiVS), which is:
As a result, we have formed such protection profiles / lines for identifying incidents with customer companies, such as:
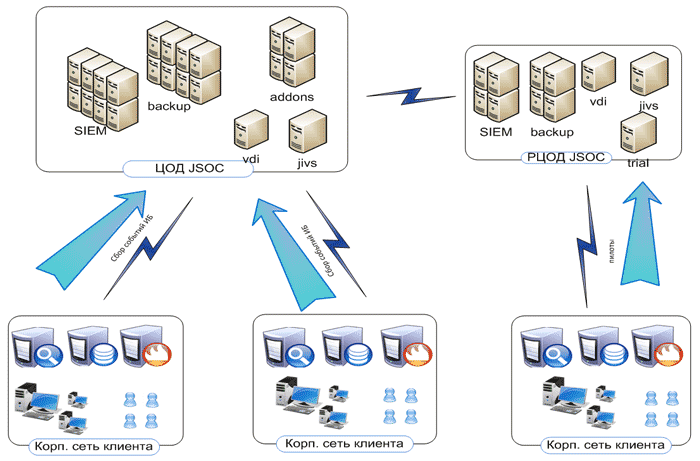
Fig. 3 - JSOC service infrastructure
After the selection of the main technological platform, it was necessary to solve the problems of creating the infrastructure and determine the location of the location. The experience of our Western colleagues shows that the target accessibility of the architecture should be at least 99.5% (and with maximum cataclysm resistance). At the same time, the question of geography remained fundamental: collocation is possible only within the borders of the Russian Federation, which excluded for us the possibility of using popular western providers. Natural questions of providing information security infrastructure at all levels of access were superimposed here, and we, by and large, have no choice left: we turned to the team of our ITC. As part of a large colocation for our JSOC, we specifically identified a fragment where we were able to deploy our architecture, while at the same time tightening up the security profiles that already exist within the ETSC. The IT infrastructure is deployed in the Tier 3 data center of our company, and its availability rates are 99.8%. As a result, we were able to reach the target indicators of the availability of our service and received substantial freedom of action in the work and adaptation of the system for ourselves.
At the initial launch of the service, the JSOC team consisted of 3 people: two monitoring engineers closing the time interval from 8 to 22 hours, and one analyst / administrator who was involved in the development of the rules. The SLA for the service, indicated to the clients, was also quite mild: the reaction time to the detected incident was up to 30 minutes, the time for analysis, preparation of analytical information and informing the client was up to 2 hours. But, after the first months of work, we made some very significant conclusions:
In practice, all these conclusions resulted in the creation within the framework of the Information Security Company Jet Infosystems a separate structural unit focused on a three-tier model for ensuring each of the tasks: both monitoring and resolving incidents, and administering protection. Now the division has more than 30 people, has a formed structure (see. Fig. 4) and includes:

Fig. 4 - JSOC Organizational Structure
This organizational structure allowed us to reach the following SLA targets:
At the moment, we serve already 12 clients and solve the tasks facing us to ensure their information security. These are the results of the first one and a half years of JSOC.
I hope this material did not seem to you too marketing. In future articles we plan to cover topics such as:
To be continued ...;) dryukov
SOC - prerequisites
I don’t really want to tell why a large Russian company is needed at all (there are too many different articles and studies on this subject written). But statistics is another matter, and it is a sin not to remember about it. For example:
- in a company of from 1 to 5 thousand people during the year fixed:
- 90 million security events;
- 16,865 events with suspicion of the incident;
- 109 real IS incidents;
- total losses from IS incidents in 2013 amounted to $ 25 billion;
- a large company uses at least 15 dissimilar protection tools, not more than 7 of them conduct active log analysis to detect incidents.
If we add to this another 3-4 news headlines on the relevant topic, then the idea that security needs to be monitored and information security incidents to identify and analyze is absolutely logical and understandable.
What do security experts advise on this issue? Of course, make the SIEM solution the core of an existing or under construction SOC. This will solve several problems at once:
- to close the incidents recorded by other systems independently, within the framework of one single core incident management;
- get a convenient tool to search for necessary events, investigate incidents, store the collected data;
- identify statistical deviations and slowly developing incidents by analyzing large intervals and amounts of information from specific remedies;
- compare and correlate data from different systems, and, as a result, build complex chains of incident detection scenarios, “enrich” information in the logs of some systems with data from others.
Some common methodology
There are several levels of SOC-SOMM maturity (Security Operations Maturity Model):
Fig. 1 - SOMM Levels
Unfortunately, most companies, having taken the first step on the way to their own incident monitoring center, stop there. According to HP estimates, 24% SOC in the world do not reach level 1, and only 30% SOC correspond to the base (2) level. Statistics of the distribution of SOMM levels depending on the business area of companies, collected in 13 countries of the world (including Canada, USA, China, UK, Germany, South Africa, etc.) is as follows:
Fig. 2 - Distribution of SOMM levels by business area
')
SOC in-house: issues
At the same time, almost all large Russian companies passed through the implementation of large-scale SIEM solutions. Did they manage to build effective SOC `s? Unfortunately, most often not: today we know the experience of only four successful SOC launches in Russia.
And, as a rule, when starting to build your own SOC, everyone faces three facets of one problem.
First, with a quantitative shortage of personnel for a variety of reasons: from personnel shortage and the lack of specialized universities to the difficulty of acquiring the required competencies. De facto, within the framework of the it-security unit, today there are 4–5 people who carry out the entire cycle of work to ensure the security of a company (from administering protective equipment to regular risk analysis and developing a strategy for the development of the subject matter in the company). Naturally, with such a load, it is almost impossible to devote the proper time to SOC tasks.
The second point is related to the impossibility of building an effective monitoring process with internal SLAs. In addition to the need to allocate personnel, the launch of SOC usually entails the creation in the it-security unit of a full-time shift shift, working on an extended working day or around the clock. And this is from 2 to 5 new staff units. At the same time, the allocation of personnel is directly related to the need for continuous monitoring of personnel turnover (extremely rarely IB specialists are ready to work in the night shift), building processes and internal quality control of the work performed.
Well, the third point is not to mention the need not only to handle emerging incidents, but also to constantly “tune” and adjust the system to changing infrastructure or emerging security threats. And this, regardless of the chosen instrument, is a very time-consuming task for the analyst, requiring you to keep your finger on the pulse. And the presence of a person engaged in clean analytics and SOC development is a great luxury (even for a large company).
Estimating the need for creating SOC on the market together with the described nuances led us first to the idea and then to actually build our own commercial SOC.
Platform Selection
Naturally, starting SOC, we first of all faced the question: “What kind of SIEM solution should be made the core of our system”? Responding to it, we have formed a list of requirements for the system being created. In particular, it should:
- allow physically and logically to separate the accumulated data for different resource pool (in our case - for different customers) with the possibility of separation of access rights;
- allow building the most complex chains and interrelations between events, using various reference books and events to supplement the incident with important information. At the same time, we needed a framework for building our own logic for identifying incidents rather than rules and scenarios already written;
- to have the possibility of writing and developing integration buses both in the direction of source systems (and here maximum flexibility in writing connectors to target systems / directories is of key importance) and api for bundling with external incident management, reporting and visualization systems;
- allow customization of internal resources for changing SOC tasks. In particular, the creation of an internal profile of monitoring sources, maintaining and customizing their incident management, etc. (By the way, these surveys will be the subject of a separate article).
We stopped our choice on the flagship product in the SIEM - HP ArcSight class (and, despite various difficulties in the life of the system, we never regretted our choice). Technologically, JSOC is no longer just HP ArcSight. SIEM `s core gradually acquired various useful features: traffic monitoring, ips \ ids, vulnerability assessment, etc. At the same time, we have accumulated a large number of scripts, add-ons and our own developments, integrated with our own Security Intelligence solution (JiVS), which is:
- a tool for high-level search for anomalies at the client and tracking general trends in activities and incidents;
- control system and visualization of our performance of SLA to the customer;
- an effective visual dashboard and reporting system for customer business management.
As a result, we have formed such protection profiles / lines for identifying incidents with customer companies, such as:
- attacks on external web resources of the company;
- unauthorized access to systems and applications;
- comprehensive security of business applications;
- virus and malware activity on the company's network, including heuristic detection of zero-day viruses;
- violation of the policy of using remote access to the company's network;
- Illegitimate actions of users when accessing the Internet and working with external devices;
- anomalies in the authentication and use of accounts;
- and other categories of incidents depending on the company's infrastructure, its internal IS policies and the means of protection used.
Infrastructure
Fig. 3 - JSOC service infrastructure
After the selection of the main technological platform, it was necessary to solve the problems of creating the infrastructure and determine the location of the location. The experience of our Western colleagues shows that the target accessibility of the architecture should be at least 99.5% (and with maximum cataclysm resistance). At the same time, the question of geography remained fundamental: collocation is possible only within the borders of the Russian Federation, which excluded for us the possibility of using popular western providers. Natural questions of providing information security infrastructure at all levels of access were superimposed here, and we, by and large, have no choice left: we turned to the team of our ITC. As part of a large colocation for our JSOC, we specifically identified a fragment where we were able to deploy our architecture, while at the same time tightening up the security profiles that already exist within the ETSC. The IT infrastructure is deployed in the Tier 3 data center of our company, and its availability rates are 99.8%. As a result, we were able to reach the target indicators of the availability of our service and received substantial freedom of action in the work and adaptation of the system for ourselves.
Team
At the initial launch of the service, the JSOC team consisted of 3 people: two monitoring engineers closing the time interval from 8 to 22 hours, and one analyst / administrator who was involved in the development of the rules. The SLA for the service, indicated to the clients, was also quite mild: the reaction time to the detected incident was up to 30 minutes, the time for analysis, preparation of analytical information and informing the client was up to 2 hours. But, after the first months of work, we made some very significant conclusions:
- The monitoring shift must necessarily work in the 24 * 7 mode. Despite the significantly smaller number of incidents in the evening and at night, the most important and critical events (the launch of DDoS attacks, the final phases of slow attacks on penetration through the outer perimeter, malicious actions of counterparties, etc.) occur all the same at night and by the time of the start of the morning shift already lose their relevance.
- The time to resolve a critical incident should not exceed 30 minutes. Otherwise, the chances of preventing it or minimizing damage significantly catastrophically fall.
- To ensure the required time for analysis, a full-fledged toolkit for its investigation should be prepared for each incident: active channels with filtered target events for analysis, trends showing statistical changes in suspicious activities and targeted analytical reports to quickly analyze activities and make operational decisions.
- The administration team for the protection of our customers should be separated from the monitoring and incident detection team. Otherwise, the risk of the influence of the human factor in the chain “made changes to the configuration — recorded the incident in fact — indicated a false response” could have a significant effect on the quality of our service.
In practice, all these conclusions resulted in the creation within the framework of the Information Security Company Jet Infosystems a separate structural unit focused on a three-tier model for ensuring each of the tasks: both monitoring and resolving incidents, and administering protection. Now the division has more than 30 people, has a formed structure (see. Fig. 4) and includes:
- 2 duty shifts that work 24 * 7: one is engaged in monitoring and analysis of incidents, the other - the system administration;
- dedicated development team, abstracted from operational activities within our customers, and allowing us to maintain the relevance of the service and threat monitoring profile.
Fig. 4 - JSOC Organizational Structure
This organizational structure allowed us to reach the following SLA targets:
| Jet Security Operation Center Parameters | Base | Advanced | Premium | |
|---|---|---|---|---|
| Service time | 8 * 5 | 24 * 7 | 24 * 7 | |
| Incident Detection Time (min) | Critical Incidents | 15-30 | 10-20 | 5-10 |
| Other incidents | up to 60 | up to 60 | up to 45 | |
| The time of basic diagnosis and informing the customer (min) | Critical Incidents | 45 | thirty | 20 |
| Other incidents | up to 120 | up to 120 | up to 90 | |
| The time of issue of recommendations on counteraction | Critical Incidents | up to 2 h | up to 1.5 h | up to 45 min |
| Other incidents | up to 8 h | up to 6 h | up to 4 h | |
At the moment, we serve already 12 clients and solve the tasks facing us to ensure their information security. These are the results of the first one and a half years of JSOC.
I hope this material did not seem to you too marketing. In future articles we plan to cover topics such as:
- SOC availability: what it is, what it is made of and how to measure it;
- How far the path from the correlation rule in the SIEM to the working incident detection scenario is;
- Organizational issues: what to teach and not to teach SOC specialists;
- A little practice on the analysis of incidents.
To be continued ...;) dryukov
Source: https://habr.com/ru/post/233885/
All Articles