How to implement back-to-back testing. Yandex experience
With the acceleration of development, there is a need to speed up writing autotests. Among the approaches that allow to cover with tests significant pieces of functionality in a short time is back-to-back testing. One of the most common varieties of similar testing for web services is the comparison of screenshots. We talked about how to use it in testing Yandex search. If you have a tested version of the product, then creating a set of autotests for the next versions is quite simple and it does not take much time. The main difficulty is that identical situations are reproduced in different versions of the service. For this, it is often necessary to maintain a large amount of test data in several environments.

When you think about using the back-to-back approach, the first thing that comes to mind is to make a comparison with a stable environment. But as a benchmark, it is suitable for a very limited range of products, because data in a stable and test environment often disagree. Often, making sure that a comparison with a stable environment fails, the researcher refuses to use back-to-back testing. Read under the cat about a couple of standard ways to implement this approach, which we use for the services of Yandex, and which solve many problems that arise when using a stable environment. We will also tell about their advantages and disadvantages that we discovered.
For example, consider the web service, which can be divided into frontend and backend. Its pages are formed on the basis of data received from the backend. So, if the same data comes to the two independent versions of the frontend, then they should form the same pages, which can already be compared. We achieved this in two ways:
Consider each of these methods in more detail.
')
We used this method to test the Yandex.Market partner interface ( documentation ), a web service that allows Yandex partners to manage the placement of their products on Yandex.Market, monitor the status of stores and view statistics. In fact, the entire functionality of the service is a representation of a large amount of different data. Some of the data is confidential, and most pages are hidden by the authorization procedure. Since for different types of users and stores the same page may look different, for full testing it is necessary to maintain a large set of test data covering all cases.
If we proceed from the fact that we will compare the test and stable environment, the service is absolutely not suitable for checking through screenshots. Maintaining a large set of identical data in a test and stable environment is very expensive, and for some of the pages it is simply impossible, because some store data is confidential and cannot be repeated on a test environment.
With manual checks in the test environment, data is maintained for playing all the necessary cases. Therefore, by deploying an additional environment in the service, on which we will upload stable packages, and aiming them at the test base, we will eliminate the data discrepancy and get two service instances that allow us to test it by comparing screenshots.
To start testing, you need physical or virtual machines on which the service will be deployed. Since they are required for a short time while the tests are running, we decided not to keep constantly raised instances of the service, but to receive virtual machines from the cloud and install the necessary packages on them. For this, we used a plugin for jenkins, which through openstack gets the necessary virtuals. And then, using a set of scripts, we install all the necessary packages on them and start the service. We deploy stable packages in a test environment, so the existing configuration files of the test environment are suitable for them. The whole process takes about 10 minutes.

The tests themselves were written in such a way that the user (in our case, the manual tester) sets a set of pages that he wants to test, plus some parameters, such as authorization data, role, etc. Tests read input conditions, perform some set of actions, then compare the screenshots of the page or any part of it. To compare and build a report, we use the same tool as in this post . It presents screenshots differences in a human-friendly form, which makes it easy to analyze the results of running a large number of tests.
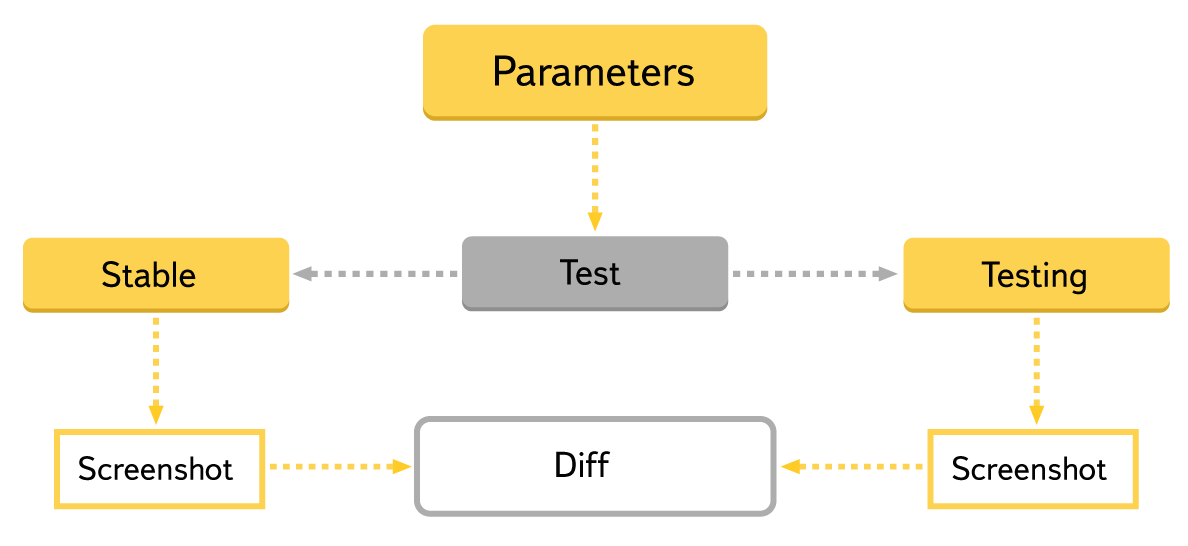
The stability of front-end checks with this approach depends on the backend operation. This can create problems, since the backend in the test environment will break from time to time - for example, due to unsuccessful builds or environmental problems. Testing in such cases will fail, even if the front-ends themselves work. But at the same time the integration is checked, because the pages are formed on the basis of the actual answers of the backend. Interaction format may vary. For example, when a block with data appears in the response of the backlog, it is necessary to build new parts of the page, the old version of the frontend will no longer be able to process this data and some of the tests will break. But if you select not the entire backend as a common part, but only the data storage, then the problem is solved, since in this case two frontend and backend bundles that have compatible versions are checked.
The tests themselves produce little action on the page. Which case will be checked is often determined by the data in the test environment. Therefore, they must be stable, and if something changes, the user of auto-tests should always be aware of this. For example, data can be copied regularly from a stable environment. This is useful, since the tester is in the same context as real users, but not all cases will be reproduced on “combat” data. Some of the functionality may be present only on the test environment, and in order to verify it, additional data will be required, which in a stable environment is simply not available yet. If they are erased when copying, then the tests of the functionality may break or stop checking the necessary cases.
In order for the test to start checking a new page, it is enough just to add it to the list and set the parameters, so the participation of the autotest developer is not required to cover new cases or support the data. Development of tests will be needed only for more complex scenarios of interaction with the page (entering values, activating pop-up windows, prompts, etc.).
All the data needed for the checks are already in the test environment. To reproduce the test results with your hands, no additional tools are required. If any element has disappeared or its position has been violated, simply open the page being checked in the test frontend.
Advantages:
Disadvantages:
We used this approach to test Yandex.Direct interfaces through which partners can manage their advertising campaigns. As in the previous case, the main part of the page functionality is the representation of a large amount of data received from the backend. The display depends on many factors, such as the type of advertising campaign, the user, etc. These factors are difficult to control. For example, information about a user comes to Direct from other services, and in order to change it, you will have to contact them. Parameters such as the type of advertising campaign can generally be changed a limited number of times per day. All this makes testing very difficult. To make the tests more stable, we decided to remove the dependence on the backend, and therefore, on data and integration with other Yandex services.
The front-end on test environments added the ability to specify the response of the backend when loading the page, that is, to build a page based on arbitrary data specified by the test. We already had the environment on which the stable package was decomposed, so it was not necessary to deploy new ones. But in order to begin to fully use the comparison of screenshots, I had to write an additional module for tests that would manage the data transmitted to the page. To store the used backend responses, we decided to take the Elliptics distributed file system. The data in it are grouped by case and type of test. For ease of management, we decided to store general information about the data in our internal wiki, so that the user of autotests can easily find out what is being checked and how to change something if necessary. In order for the service developer to easily reproduce and repair the bugs found, it was necessary to realize the ability to repeat the tests manually.
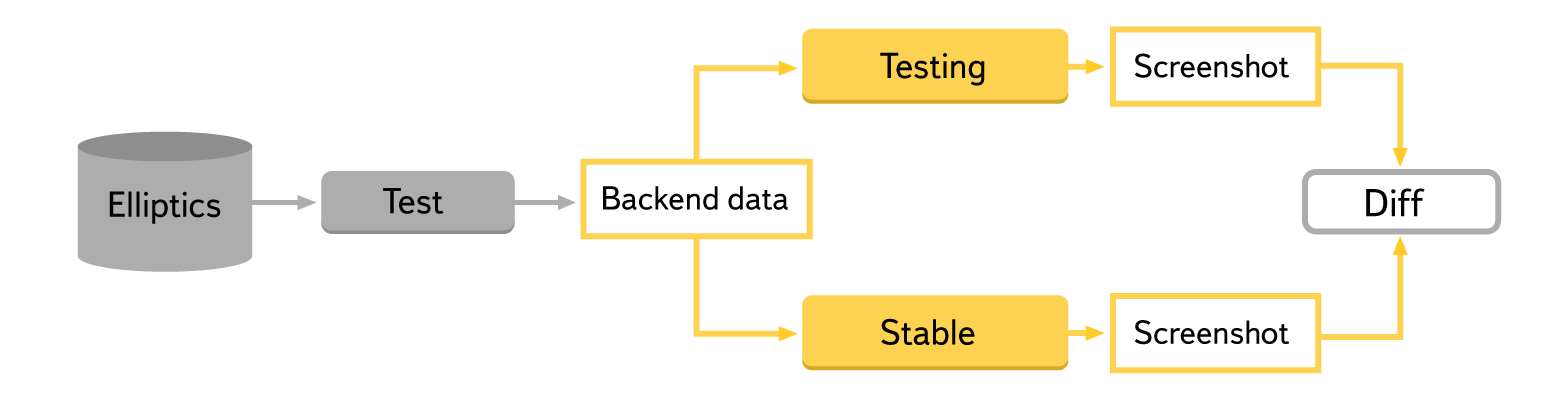
With this approach, tests become completely independent of the backend, which speeds them up and makes them more stable. To reproduce a specific situation, it is enough to send the necessary answer to the frontend, which you can save in advance or form a pattern. However, integration with the current version of the backend is not checked, it will have to be tested separately, for example, using the approach described above.
There is no need to perform many preliminary actions before the tests. To check any cases, it is not necessary to create a new campaign, conduct it through a cycle of checks, provide it with a positive balance, and so on - simply create a suitable response to the backend. It becomes possible to check cases that simply cannot be reproduced, for example, time-dependent behavior.
The response format of the backend can vary, and this makes the tests potentially vulnerable. To solve this problem, we have provided the opportunity to take the actual answer of the backend and record it in the test data storage - then it will be used in subsequent runs of tests. But for some cases this method is not suitable. If the answer of the backend was edited to reproduce the complex case, then the current answer of the backend will not work. When changing the format of the response data of such cases will have to be updated, and this will take time. To correct the test answers of the backend, you need to know the features of the implementation of the service and have certain technical skills, which makes data support more costly.
Advantages:
Disadvantages:
It is easy to see: the disadvantages of one approach become advantages in another, so it is reasonable to combine these approaches. The first method is simpler, you can start with it, it will not require additional development and support. However, the second method is more flexible; it makes it possible to reproduce difficult situations. Raising two versions over a single backend, you can get an opportunity to estimate the number of complex cases, the test run time and their stability. This will make it possible to understand whether more advanced approaches should be implemented.
In both cases considered, we used the back-to-back approach to test the frontend. But limited to the front-end is not necessary. The main difficulty with back-to-back testing is to ensure that the data in different versions of the packages match. For most products, the data is stored in some kind of storage. Separating only storage as a common part, you can get the opportunity to test the backend logic without creating additional tests. In the same way, various APIs or other services that do not include frontend can be tested.
It is very convenient to apply the approach at the very beginning of product development, when there are no autotests or too little. By quickly covering the logic of calculating and displaying the results, you can focus on more complex functionality that cannot be verified in this way — for example, saving and modifying data. Due to the fact that the product is actively changing, the results of different versions often do not coincide, which can lead to false drops in back-to-back tests. Therefore, first of all, you should provide a good report that will allow you to easily analyze the results. Especially this problem is relevant at the very beginning of product development, since many new functionality constantly appears and the appearance of the service changes dramatically.
It is indicative that testing problems with screenshots can be easily solved by improving the environment, rather than by complicating the tests, so before developing tests it is reasonable to analyze what benefits the improvement of the environment will bring, and then you may not have to write complex tests at all.
When you think about using the back-to-back approach, the first thing that comes to mind is to make a comparison with a stable environment. But as a benchmark, it is suitable for a very limited range of products, because data in a stable and test environment often disagree. Often, making sure that a comparison with a stable environment fails, the researcher refuses to use back-to-back testing. Read under the cat about a couple of standard ways to implement this approach, which we use for the services of Yandex, and which solve many problems that arise when using a stable environment. We will also tell about their advantages and disadvantages that we discovered.
For example, consider the web service, which can be divided into frontend and backend. Its pages are formed on the basis of data received from the backend. So, if the same data comes to the two independent versions of the frontend, then they should form the same pages, which can already be compared. We achieved this in two ways:
- set up both versions of the frontend on the same backend;
- passed the response we need backend directly to the frontend.
Consider each of these methods in more detail.
')
General backend
Service Description
We used this method to test the Yandex.Market partner interface ( documentation ), a web service that allows Yandex partners to manage the placement of their products on Yandex.Market, monitor the status of stores and view statistics. In fact, the entire functionality of the service is a representation of a large amount of different data. Some of the data is confidential, and most pages are hidden by the authorization procedure. Since for different types of users and stores the same page may look different, for full testing it is necessary to maintain a large set of test data covering all cases.
If we proceed from the fact that we will compare the test and stable environment, the service is absolutely not suitable for checking through screenshots. Maintaining a large set of identical data in a test and stable environment is very expensive, and for some of the pages it is simply impossible, because some store data is confidential and cannot be repeated on a test environment.
Implementation
With manual checks in the test environment, data is maintained for playing all the necessary cases. Therefore, by deploying an additional environment in the service, on which we will upload stable packages, and aiming them at the test base, we will eliminate the data discrepancy and get two service instances that allow us to test it by comparing screenshots.
To start testing, you need physical or virtual machines on which the service will be deployed. Since they are required for a short time while the tests are running, we decided not to keep constantly raised instances of the service, but to receive virtual machines from the cloud and install the necessary packages on them. For this, we used a plugin for jenkins, which through openstack gets the necessary virtuals. And then, using a set of scripts, we install all the necessary packages on them and start the service. We deploy stable packages in a test environment, so the existing configuration files of the test environment are suitable for them. The whole process takes about 10 minutes.
The tests themselves were written in such a way that the user (in our case, the manual tester) sets a set of pages that he wants to test, plus some parameters, such as authorization data, role, etc. Tests read input conditions, perform some set of actions, then compare the screenshots of the page or any part of it. To compare and build a report, we use the same tool as in this post . It presents screenshots differences in a human-friendly form, which makes it easy to analyze the results of running a large number of tests.
Using
The stability of front-end checks with this approach depends on the backend operation. This can create problems, since the backend in the test environment will break from time to time - for example, due to unsuccessful builds or environmental problems. Testing in such cases will fail, even if the front-ends themselves work. But at the same time the integration is checked, because the pages are formed on the basis of the actual answers of the backend. Interaction format may vary. For example, when a block with data appears in the response of the backlog, it is necessary to build new parts of the page, the old version of the frontend will no longer be able to process this data and some of the tests will break. But if you select not the entire backend as a common part, but only the data storage, then the problem is solved, since in this case two frontend and backend bundles that have compatible versions are checked.
The tests themselves produce little action on the page. Which case will be checked is often determined by the data in the test environment. Therefore, they must be stable, and if something changes, the user of auto-tests should always be aware of this. For example, data can be copied regularly from a stable environment. This is useful, since the tester is in the same context as real users, but not all cases will be reproduced on “combat” data. Some of the functionality may be present only on the test environment, and in order to verify it, additional data will be required, which in a stable environment is simply not available yet. If they are erased when copying, then the tests of the functionality may break or stop checking the necessary cases.
In order for the test to start checking a new page, it is enough just to add it to the list and set the parameters, so the participation of the autotest developer is not required to cover new cases or support the data. Development of tests will be needed only for more complex scenarios of interaction with the page (entering values, activating pop-up windows, prompts, etc.).
All the data needed for the checks are already in the test environment. To reproduce the test results with your hands, no additional tools are required. If any element has disappeared or its position has been violated, simply open the page being checked in the test frontend.
Advantages and disadvantages of the method
Advantages:
- low implementation costs;
- low support costs.
Disadvantages:
- test execution time depends not only on the operation of the tested service;
- stability depends on the backend;
- reproduction of some cases may be difficult.
Backend response emulation
Service Description
We used this approach to test Yandex.Direct interfaces through which partners can manage their advertising campaigns. As in the previous case, the main part of the page functionality is the representation of a large amount of data received from the backend. The display depends on many factors, such as the type of advertising campaign, the user, etc. These factors are difficult to control. For example, information about a user comes to Direct from other services, and in order to change it, you will have to contact them. Parameters such as the type of advertising campaign can generally be changed a limited number of times per day. All this makes testing very difficult. To make the tests more stable, we decided to remove the dependence on the backend, and therefore, on data and integration with other Yandex services.
Implementation
The front-end on test environments added the ability to specify the response of the backend when loading the page, that is, to build a page based on arbitrary data specified by the test. We already had the environment on which the stable package was decomposed, so it was not necessary to deploy new ones. But in order to begin to fully use the comparison of screenshots, I had to write an additional module for tests that would manage the data transmitted to the page. To store the used backend responses, we decided to take the Elliptics distributed file system. The data in it are grouped by case and type of test. For ease of management, we decided to store general information about the data in our internal wiki, so that the user of autotests can easily find out what is being checked and how to change something if necessary. In order for the service developer to easily reproduce and repair the bugs found, it was necessary to realize the ability to repeat the tests manually.
Using
With this approach, tests become completely independent of the backend, which speeds them up and makes them more stable. To reproduce a specific situation, it is enough to send the necessary answer to the frontend, which you can save in advance or form a pattern. However, integration with the current version of the backend is not checked, it will have to be tested separately, for example, using the approach described above.
There is no need to perform many preliminary actions before the tests. To check any cases, it is not necessary to create a new campaign, conduct it through a cycle of checks, provide it with a positive balance, and so on - simply create a suitable response to the backend. It becomes possible to check cases that simply cannot be reproduced, for example, time-dependent behavior.
The response format of the backend can vary, and this makes the tests potentially vulnerable. To solve this problem, we have provided the opportunity to take the actual answer of the backend and record it in the test data storage - then it will be used in subsequent runs of tests. But for some cases this method is not suitable. If the answer of the backend was edited to reproduce the complex case, then the current answer of the backend will not work. When changing the format of the response data of such cases will have to be updated, and this will take time. To correct the test answers of the backend, you need to know the features of the implementation of the service and have certain technical skills, which makes data support more costly.
Advantages and disadvantages of the method
Advantages:
- speed: tests do not wait for the backend to respond, so they work faster;
- stability: tests depend only on the performance of the frontend;
- flexibility: it is possible to easily reproduce complex cases.
Disadvantages:
- high implementation costs: you need to make changes to the service code or emulate a backend, make tools for managing data and reproducing errors.
Conclusion
It is easy to see: the disadvantages of one approach become advantages in another, so it is reasonable to combine these approaches. The first method is simpler, you can start with it, it will not require additional development and support. However, the second method is more flexible; it makes it possible to reproduce difficult situations. Raising two versions over a single backend, you can get an opportunity to estimate the number of complex cases, the test run time and their stability. This will make it possible to understand whether more advanced approaches should be implemented.
In both cases considered, we used the back-to-back approach to test the frontend. But limited to the front-end is not necessary. The main difficulty with back-to-back testing is to ensure that the data in different versions of the packages match. For most products, the data is stored in some kind of storage. Separating only storage as a common part, you can get the opportunity to test the backend logic without creating additional tests. In the same way, various APIs or other services that do not include frontend can be tested.
It is very convenient to apply the approach at the very beginning of product development, when there are no autotests or too little. By quickly covering the logic of calculating and displaying the results, you can focus on more complex functionality that cannot be verified in this way — for example, saving and modifying data. Due to the fact that the product is actively changing, the results of different versions often do not coincide, which can lead to false drops in back-to-back tests. Therefore, first of all, you should provide a good report that will allow you to easily analyze the results. Especially this problem is relevant at the very beginning of product development, since many new functionality constantly appears and the appearance of the service changes dramatically.
It is indicative that testing problems with screenshots can be easily solved by improving the environment, rather than by complicating the tests, so before developing tests it is reasonable to analyze what benefits the improvement of the environment will bring, and then you may not have to write complex tests at all.
Source: https://habr.com/ru/post/233455/
All Articles