URI - tricky about simple (Part 1)

Hi habr!
A certain amount of time appeared, and I decided to write this post, the idea of which had arisen a long time ago.
It will be connected with such a seemingly simple thing as a URI, to which a little attention is paid to a detailed review of which in RuNet.
')
“ Pff, the links are in Africa and links, what is there to understand? ” - you will say, then I ask the question:
What is what and where will lead us?
http://example.comwww.example.com//www.example.commailto:user@example.com
If you do not know a definite answer or you are just wondering
Before starting, I would like to indicate that there is a post on a similar topic, in which everything is indicated more simply and a little more clearly. The purpose of this post, I put a deeper study of the issue and the collection of information about the URI in one place, so as not to “lose”. Well, almost in one place, the article will be divided into two parts.
And for the convenience of Bachn, the table of contents, which works not without features URI, which we consider later in this article.
TABLE OF CONTENTS
Introduction
1. URI
Uniform Resource Identifier , in common - URI
The most recent description of what these notorious URIs are all the same dates back to January 2005, namely RFC3986 , written by Tim Benes-Lee himself, the ancestor of all of our beloved tyrnet .
Summarizing Clause 1.1, we can formulate the definition:
A URI is a sequence of characters that identifies a physical or abstract resource that does not need to be accessible through the Internet, and the type of resource to be accessed is determined by the context and / or mechanism.
For example:
- going to
http://example.com- we will get to the http-server of the resource identified asexample.com - at the same time,
ftp://example.comwill lead us to the ftp server of the same resource - or for example
http://localhost/- URI identifying the machine from where it is being accessed
In the modern Internet, two types of
URI are most often used - URL and URN .The main difference between them is in the tasks:
- URL - Uniform Resource Locator , helps to find any resource
- URN - Uniform Resource Name , helps to identify this resource.
Simplifying:
URL - answers the question: "Where and how to find something?", URN - answers the question: "How to identify something."A couple of interesting things about URI
Many of you have noticed that on different resources the links call the URL, the URI, and, probably, it became interesting - which of the options is correct?
The fact is that the URL saw the light and was documented in 1990, while the URI was documented only in 1994. And until 2002, before the release of RFC3305 , both naming options were appropriate, which sometimes confused.
RFC3305, clause 2, states that a term such as a URL is obsolete, applies to links, and that the URI naming will now be correct, since W3C uses the term URI in all documents. Based on this, applying the term URL to the corresponding links, you do not make a semantic error, but make it in terms of proper naming.
Also noteworthy is the moment that up until the release of RFC2396 , in 1997, the URI was decoded as a Universal Resource Identifier, which can be seen in RFC1630
The fact is that the URL saw the light and was documented in 1990, while the URI was documented only in 1994. And until 2002, before the release of RFC3305 , both naming options were appropriate, which sometimes confused.
RFC3305, clause 2, states that a term such as a URL is obsolete, applies to links, and that the URI naming will now be correct, since W3C uses the term URI in all documents. Based on this, applying the term URL to the corresponding links, you do not make a semantic error, but make it in terms of proper naming.
Also noteworthy is the moment that up until the release of RFC2396 , in 1997, the URI was decoded as a Universal Resource Identifier, which can be seen in RFC1630
Summarizing all sorts of options, the URI is as follows:

Looking ahead, it is worth noting that not all three components are strictly required. For a link to be considered a URI, you must have:
- or
scheme+authority+path, - either
sheme+path, - or only
path.
1.1. Syntax
According to RFC3986, clause 2:
A URI is made up of a limited set of characters consisting of numbers, letters, and several graphic characters, all of which fit into the US-ASCII (ASCII) encoding. The reserved subset of characters can be used to delimit the syntax components in a URI, while the remaining characters: not a reserved set and including those reserved characters that do not act as delimiters in a given URI component, identify each component's identification data.
Reserved characters
Reserved characters are divided into two types:- gen-delims , they are also the "main separators", i.e. characters dividing the URI into large components.
":", "/", "?", "#", "[", "]", "@" - Sub-delims , they are also “under delimiters” - symbols that divide the current large component into smaller components, they are different for each component, here’s a list of the most common:
"!", "$", "&", "'", "(", ")", "*", "+", ",", ";", "="
Unreserved characters
Based on the previous paragraph, non-reserved characters are symbols that are not included in thegen-delims , as well as sub-delims that are not significant for this component. But in general it is:For this case, according to ABNF :ALPHA, DIGIT, "-", ".", "_", "~"ALPHA- any letter of the upper and lower registers of the ASCII encoding (in regExp [A-Za-z])DIGIT- any digit (in regExp [0-9])HEXDIGis a hexadecimal digit (in regExp [0-9A-F])
Percent coding
If characters are used that are outside the limits of ASCII encoding, then a so-called mechanism is used. " Percentage Coding ". It is also used to transfer reserved characters in the data. Reserved characters, according to the rules, do not participate in percentage coding.The percentage-coded character is a character triplet consisting of the "%" sign and two hexadecimal numbers following it:
Thus,% 20, for example, means a space.pct-encoded = "%" HEXDIG HEXDIG
1.2. URI components
The following list contains descriptions of the major components that make up the URI:
- Scheme
Each URI begins with a schema name that refers to a specification for assigning identifiers in that schema. Also, the URI syntax is a unified and extensible naming system, and the specification of each schema can further restrict the syntax and semantics of identifiers using this schema.
The name of the scheme necessarily begins with a letter and can be continued further by any number of allowed symbols.
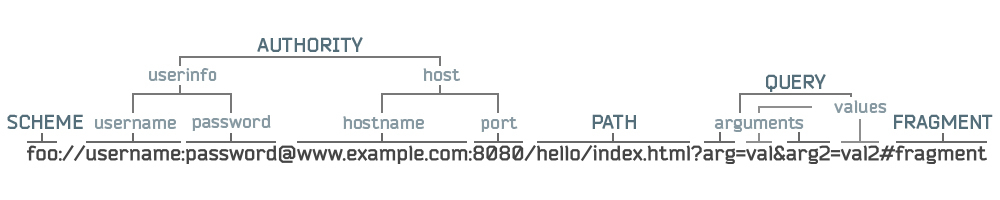
The allowed symbols for the scheme are:ALPHA, DIGIT, "+", "-", "." - Authority (to be honest, I don’t know how to translate a word into Russian, without losing the meaning)
The authority component begins with a double slash (//) and ends with the next slash (/), question mark (?) Or octotorpe (#) (yes, the “grid” is called that way =)) or the end of the URI
Authority consists of:
Each of the subcomponents, separately, we will look at later, in the section on the URL.
where in brackets are optional components[ userinfo "@" ] host [ ":" port ] - Path
A path component contains data, usually organized in a hierarchical form, which, together with the data in a non-hierarchical query component (Query), serves to identify a resource within the framework of a URI and authority scheme (if such a component is specified).
The path begins with a slash (/) and ends with a question mark (?), Octotor (#), or the end of a URI
Allowed characters for the path:, -, sub-delims, ":", "@" - Query (Query)
The request component contains data organized in a non-hierarchical form, which, together with the data in the hierarchical component of the path (Path), serves to identify the resource within the framework of the URI scheme and authority (if such a component is specified).
The request begins with the first question mark (?) And ends with an octotor (#) or the end of a URI
Allowed characters for query:
The request most often sends data in the key = value format (key = value), the value is recommended to be transmitted in percent-coded form, this is because the value can contain the character "&", which is used to separate key-value pairs, as a result of such an artifact, the further sequence of key-value pairs may be broken., -, sub-delims, ":", "@", "/", "?" - Fragment
Component fragment allows you to indirectly identify the secondary resource in relation to the first.
The semantics of a fragment are not limited in any way; the fragment begins with an octoterpe (#) and ends with the end of a URI, and it can consist of absolutely any character set.
An example of the use of fragments is the table of contents of this article. It consists of relative links.<a href="#someanchor"></a><anchor>someanchor</anchor>
By clicking on the link specified in the table of contents, the browser makes a transition to the secondary resource relative to this page, i.e. scroll down until the desired<anchor>
On this, perhaps, familiarity with the URI can be completed and begin to delve into the individual subspecies of the URI, namely
2. URL
The URL standard is documented in RFC1738 .
From item 2:
URLs are used to locate resources, providing abstract identification of the location of the resource. Having determined the location of the resource, the system can perform many operations on the resource, which can be characterized by such words as 'access', 'update', 'replacement', 'attribute search'. In general, only the access method must be defined for any URL scheme.So: A URL is designed to solve a wide range of tasks, starting from receiving and ending with changing data on a resource, and the required parameter for access is the method, that is, any full (absolute) URL can be reduced to the form:
<scheme>:< > 2.1. Structure
In general, the URL has a similar structure for all schemes, although for each individual scheme, the structure may differ from the general pattern.
Graphically, it can be expressed as:
And so, at about this moment, one can consider the differences between absolute (absolute) and relative (relative) URLs, these definitions apply not only to the URL, but also to the URI as a whole.
- A relative reference uses hierarchical syntax to express a URI reference relative to the namespace of another hierarchical URI.
Relative links are also divided into several subspecies:- Network path reference
It looks like:
This type of links is used infrequently, the point is to follow the link with the current scheme.//<authority> <path> [<query>] [<fragment>]
Ie: being, for example, onhttp://example.comand following the link//domain.com- we will get onhttp://domain.com
And if we follow the same link fromftp://example.com, weftp://domain.comget toftp://domain.com - Absolute path reference
It looks like:
This time we will stay within the current host, but we will get on the path in any case, no matter what path we are now./<path> [<query>] [<fragment>]
Ie: even being onhttp://example.com/just/some/long/pathand following the link/path, we will get tohttp://example.com/path - Relative path reference
It looks like:
Now, we will move within the current position.<path> [<query>] [<fragment>]
Ie: being onhttp://example.com/just/some/long/pathand following thepathlink, we will get tohttp://example.com/just/some/long/path/path - Link of the same document
In fact, these are links that consist only of the fragmentary part of the URI, or links, in which all components except the fragmentary ones coincide with the original one.
Those.#fragmentandhttp://habrahabr.ru/topic/232385/#fragmentare references of the same document.
- Network path reference
- Absolute Link - View Link
Applying absolute links, we will get to the resource we need, regardless of where we come from.<scheme> <authority> [<path>] [<query>] [<fragment>]
Ie: we are onhttp://example.com/just/some/long/pathorftp://example.com, by going tohttp://domain.com/path, we are anyway let's get onhttp://domain.com/path
After we figured out what are relative and absolute paths, you can answer the question asked at the beginning of the post:
- http://example.com - will open
http://example.com - www.example.com - in theory should open
http://habrahabr.ru/topic/232385/www.example.com, but habr itself corrects the link, although according to the standardswww.example.comis the relative path reference - //www.example.com - will open
www.example.comwith the scheme with which you are viewing the current page, i.e. likely to be openhttp://example.com - mailto: user@example.com - the browser settings already take effect here, he will offer you to open this link using the mail program and send an email to the recipient
user@example.com, and this is the absolute URL with themailtoscheme
We have already reviewed the major components, and now let's delve into the details of building a URL.
- Scheme - as mentioned earlier: the scheme determines the method of access to the resource. A list of current schemes can be found here .
- Userinfo is the authority sub-component used to authorize a user on a resource. It consists of a username and an optional password, separated from the rest of the authority by the "
@" symbol. Despite the fact that the password parameter is specified in the specification, its use is highly discouraged, since the password is actually transmitted to the username account, in unencrypted form.
Allowed characters:, -, sub-delims, ":"
An example is the following:
There is a test folder on LAN that is accessed by a couple of login-password. That is, going tohttp://localhost/test/, I will see the following: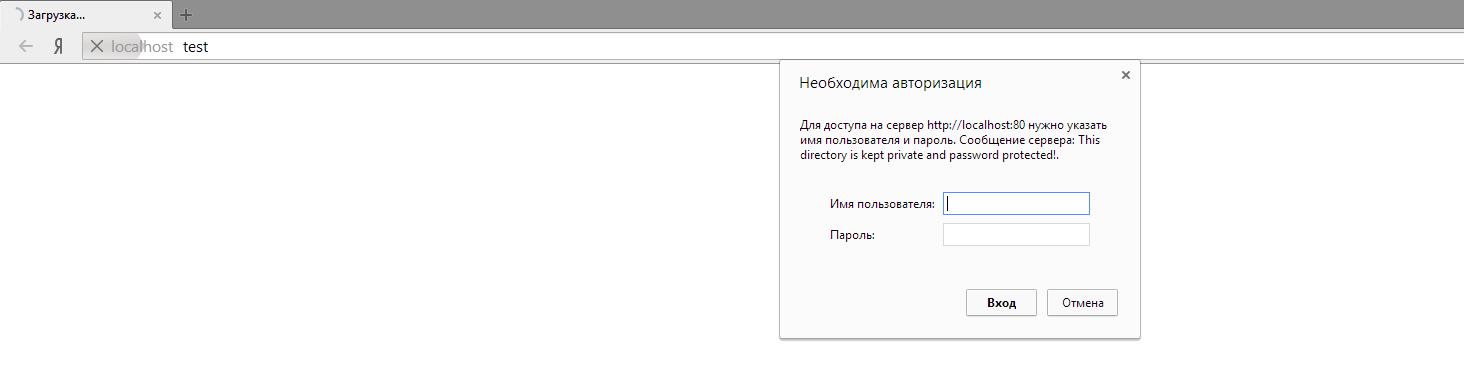
And if I follow the linkhttp://admin:admin@localhost/test/, then the authorization procedure will occur automatically, with the data specified in the userinfo block: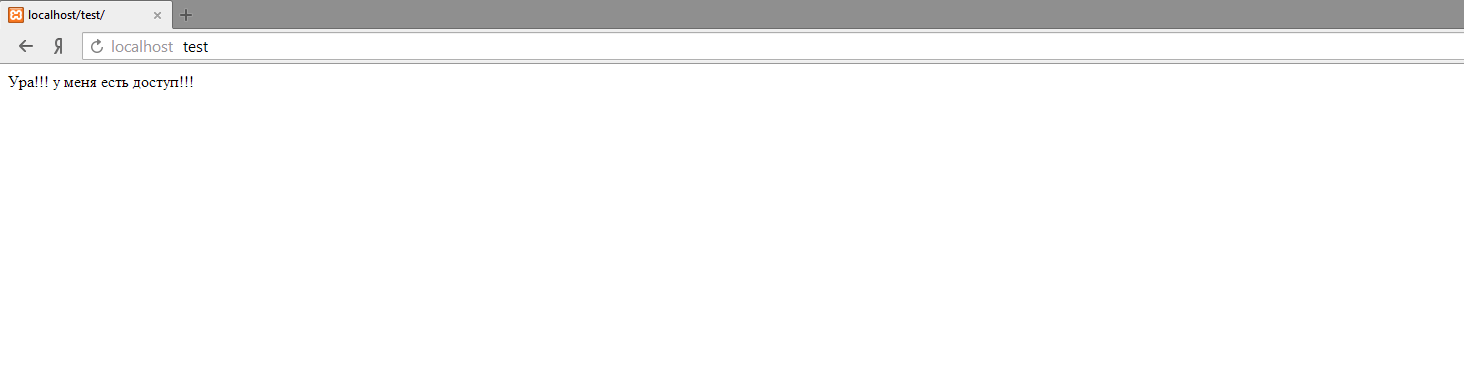
- Host is the authority component used to determine the target node (or a resource, if you like, but the concept of a “node” will be more precise), which can be located both on the Internet and outside it, depending on the specified scheme. This component is not case sensitive.
The host can be either an IP address or a registration name (reg-name) and, optionally, the next following port (port).
It provides for support for existing IP address formats (IPv4, IPv6), and all kinds of future ones that will be described later.
Registration name - familiar to us, so called. domain names are a sequence of characters, usually intended to be searched in a locally defined node or service name registry, although the schema-specific semantics of a URI may require that a specific registry (or fixed name table) be used instead.
The most common name registry mechanism is the Domain Name System (DNS).
The domain name used for DNS search consists of domain tags, separated by ".", Each domain tag may contain the following characters:
The registration name syntax allows the use of percent-encoded characters to represent non-ASCII characters in a single order, independent of name resolution technology. Non-ASCII characters must first be encoded in UTF-8, and then each octet of the UTF-8 sequence must be percent-coded., -, sub-delims
If the registration name with non-ASCII characters is a multilingual domain name resolvable through DNS, it must be converted to IDNA encoding ( RFC3490 ) before searching for the name and, as a result, by domain name registrars such registration names must be provided in IDNA encoding .
Port (Port) - the decimal port number, separated from the hostname by one colon ":", can consist only of numbers. The scheme can define the default port that will be used if the port is not specified. For example, for the HTTP scheme, the default port is 80, which corresponds to the port 80 / TCP reserved for it. The type of port, as well as the assigned port number, is determined by the scheme. - The components Query and Fragment are fully described previously.
3. URN
The URN standard is documented in RFC2141 .
From item 1:
Uniform Resource Names (URNs) are intended to serve as permanent, location-independent resource identifiers and are designed to simplify the mapping of other namespaces (which share URN properties) into a URN space. Thus, the URN syntax provides a means to encode character data in a form that can be sent using existing protocols, written using most keyboards, etc.That is, unlike the URL, which refers to a place where the document is stored, the URN refers to the document itself, and when you move the document to another location, the link does not change.
Due to the fact that the URN conceptually differs from the URL, then its name resolution system is different - DDDS , which converts the URN to URLs where you can find a resource / object or whatever the URN refers to.
3.1. Structure
The URN is as follows:
"urn:" <NID> ":" <NSS> - "Urn:" - mandatory, case-insensitive part of the URN
- NID - Namespace Identifier, this component defines the syntactic interpretation of the NSS component.
Minimum length - 2 characters, maximum - 32, allowed characters:
NID must begin with only a letter or number., , "-"
Also, the word “urn” for NID is reserved in order to avoid ambiguity in determining the URN as a whole.
List of officially registered NID can be found here. - NSS - Namespace Specific String, this component serves directly to transfer any data.
Allowed characters :
Reserved characters :, , -, "(", ")", "+", ",", "-", ".", ":", "=", "@", ";", "$", "_", "!", "*", "'"
Illegal characters must be percent coded. If the specified character is encountered explicitly, its position will be considered the end of the URN:"%", "/", "?", "#"0-32 (0-20 hex), "\", """, "&", "<", ">", "[", "]", "^", "`", "{", "|", "}", "~", 127-255 (7F-FF hex)
Self-identifying URN
Such URNs contain the name of the hash function in NID, and in NSS the value of the hash calculated for the identified object. Such links are used in magnet links and Gnutela2 p2p network headers.For example, URN from a magnet link from a single torrent tracker:
magnet:?xt=urn:btih:c68abc1ba9b8c7c4bc373862cad1a8c01d69e53d...With theory, everything, in the second part, we will consider what can and should be done with URIs if we process them, namely, normalization, parsing, etc.
I will take my leave for this, thanks for reading, I hope it was not boring, good luck!
Source: https://habr.com/ru/post/232385/
All Articles